WebSphere eXtreme Scale v8.6 Overview
- Elastic scalability
- WXS with databases
- What's new in Version 8.6
- Release notes
- Hardware and software requirements
- Directory conventions
- WXS technical overview
- Caching overview
- Cache integration overview
- Spring cache provider
- Liberty profile
- OpenJPA level 2 (L2) and Hibernate cache plug-in
- HTTP session management
- Dynamic cache provider overview
- Deciding how to use WXS
- Decision tree for migrating existing dynamic cache applications
- Decision tree for choosing a cache provider for new applications
- Feature comparison
- Topology types
- Remote topology
- Dynamic cache engine and eXtreme Scale functional differences
- Dynamic cache statistics
- MBean calls
- Dynamic cache replication policy mapping
- Global index invalidation
- Security
- Near cache
- Additional information
- Database integration
- Serialization overview
- Scalability overview
- Availability overview
- High availability
- Heart beating
- Failures
- Process failure
- Loss of connectivity
- Host failure
- Islanding
- Container failures
- Container failure detection latency
- Catalog service failure
- Multiple container failures
- Replication for availability
- High availability catalog service
- Catalog server quorums
- Heartbeats and failure detection
- Container servers and core groups
- Catalog service domain heart-beating
- Failure detection
- Quorum behavior
- Reasons for quorum loss
- Quorum loss from JVM failure
- Quorum loss from network brownout
- Catalog service JVM cycling
- Consequences of lost quorum
- Quorum recovery
- Overriding quorum
- Container behavior during quorum loss
- Synchronous replica behavior
- Asynchronous replica behavior
- Client behavior during quorum loss
- Islanding
- Replicas and shards
- Shard types
- Minimum synchronous replica shards
- Replication and Loaders
- Primary side
- Replica side
- Replica side on failover
- Shard placement
- Scaling out
- Scaling in
- Lifecycle events
- Primary shard
- Recovery events
- Replica shard becomes a primary shard
- Replica shard recovery
- Failure events
- Too many register attempts
- Failure while entering peer mode
- Recovery after re-register or peer mode failure
- Map sets for replication
- Replica side
- Transaction processing
- Security overview
- REST data services overview
- High availability
Overview
WebSphere eXtreme Scale (WXS) is a data grid that caches application data across multiple servers, performing massive volumes of transaction processing with high efficiency and linear scalability.WXS can be used...
- As a cache
- As an in-memory database processing space to manage application state
- To build Extreme Transaction Processing (XTP) applications
eXtreme Scale splits data set into partitions. Each partition exists as a primary copy, or shard. A partition also contains replica shards for backing up the data.

WebSphere DataPower XC10 can be used with WebSphere Commerce Suite as an alternative caching mechanism for Dynamic Cache to reduce local memory. Commerce nodes can use the WebSphere eXtreme Scale dynamic cache provider to off load caching from local memory to XC10. All of the cached data is stored in on the XC10 Collective, providing availability of cache data and improved performance.

Elastic scalability
Elastic scalability is enabled using distributed object caching. The data grid monitors and manages itself, adding or removing servers from the topology, which increases memory, network throughput, and processing capacity as needed. Capacity is added to the data grid while it is running without requiring a restart. The data grid self-heals by automatically recovering from failures.
WXS with databases
Using the write-behind cache feature, eXtreme Scale can serve as a front-end cache for a database. WXS clients send and receive data from the data grid, which can be synchronized with a backend data store. The cache is coherent because all of the clients see the same data in the cache. Each piece of data is stored on exactly one writable server in the cache. Having one copy of each piece of data prevents wasteful copies of records that might contain different versions of the data. A coherent cache holds more data as more servers are added to the data grid, and scales linearly as the data grid grows in size. The data can also be optionally replicated for additional fault tolerance.
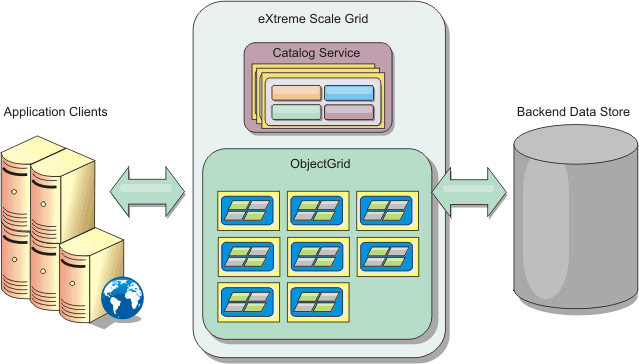
WXS container servers provide the in-memory data grid. Container servers can run...
- Inside WebSphere Application Server
- On a J2SE JVM
The data grid is not limited by, and does not have an impact on, the memory or address space of the application or the application server. The memory can be the sum of the memory of several hundred, or thousand, JVMs, running on many different physical servers.
As an in-memory database processing space, WXS can be backed by disk, database, or both.
While eXtreme Scale provides several Java APIs, many use cases require no user programming, just configuration and deployment in your WebSphere infrastructure.
Data grid overview
The simplest eXtreme Scale programming interface is the ObjectMap interface, a map interface that includes:
- map.put(key,value)
- map.get(key)
The fundamental data grid paradigm is a key-value pair, where the data grid stores values (Java objects), with an associated key (another Java object). The key is later used to retrieve the value. In eXtreme Scale, a map consists of entries of such key-value pairs.
WXS offers a number of data grid configurations, from a single, simple local cache, to a large distributed cache, using multiple JVMs or servers.
In addition to storing simple Java objects, we can store objects with relationships. Use a query language that is like SQL, with SELECT - FROM - WHERE statements to retrieve these objects. For example, an order object might have a customer object and multiple item objects associated with it. WXS supports one-to-one, one-to-many, many-to-one, and many-to-many relationships.
WXS also supports an EntityManager programming interface for storing entities in the cache. This programming interface is like entities in Java Enterprise Edition. Entity relationships can be automatically discovered from..
- entity descriptor XML file
- annotations in the Java classes
Retrieve entities from the cache by primary key using the find method on the EntityManager interface. Entities can be persisted to or removed from the data grid within a transaction boundary.
Consider a distributed example where the key is a simple alphabetic name. The cache might be split into four partitions by key: partition 1 for keys starting with A-E, partition 2 for keys starting with F-L, and so on. For availability, a partition has a primary shard and a replica shard. Changes to the cache data are made to the primary shard, and replicated to the replica shard. You configure the number of servers that contain the data grid data, and eXtreme Scale distributes the data into shards over these server instances. For availability, replica shards are placed in separate physical servers from primary shards.
WXS uses a catalog service to locate the primary shard for each key. It handles moving shards among eXtreme Scale servers when the physical servers fail and later recover. If the server containing a replica shard fails, eXtreme Scale allocates a new replica shard. If a server containing a primary shard fails, the replica shard is promoted to be the primary shard . As before, a new replica shard is constructed.
Release notes
Hardware and software requirements
Formally supported hardware and software options are available on the Systems Requirements page.
Install and deploy the product in Java EE and Java SE environments. We can also bundle the client component with Java EE applications directly without integrating with WebSphere Application Server.
Hardware requirements
WXS does not require a specific level of hardware. The hardware requirements are dependent on the supported hardware for the Java SE installation used to run WXS. If we are using eXtreme Scale with WebSphere Application Server or another JEE implementation, the hardware requirements of these platforms are sufficient for WXS.
Operating system requirements
Each Java SE and Java EE implementation requires different operating system levels or fixes for problems that are discovered during the testing of the Java implementation. The levels required by these implementations are sufficient for eXtreme Scale.
Installation Manager requirements
Before installing WXS, install Installation Manager using either...
- product media
- file obtained from the Passport Advantage site
- file containing the most current version of Installation Manager from the IBM Installation Manager download website
Web browser requirements
The web console supports the following Web browsers:
- Mozilla Firefox, version 3.5.x and later
- Microsoft Internet Explorer, version 7 and later
WebSphere Application Server requirements
- WebSphere Application Server Version 7.0.0.21 or later
- WebSphere Application Server Version 8.0.0.2 or later
Java requirements
Other Java EE implementations can use the WXS run time as a local instance or as a client to WXS servers. To implement Java SE, use Version 6 or later.
Directory conventions
- wxs_install_root
- Root directory where WXS product files are installed. Can be the directory in which the trial archive is extracted or the directory in which the WXS product is installed.
- Trial...
-
/opt/IBM/WebSphere/eXtremeScale
- WXS stand-alone directory...
-
/opt/IBM/eXtremeScale
C:\Program Files\IBM\WebSphere\eXtremeScale - WXS integrated WebSphere Application Server...
-
/opt/IBM/WebSphere/AppServer
- Trial...
- wxs_home
- Root directory of the WXS product libraries, samples, and components.
- Trial...
-
/opt/IBM/WebSphere/eXtremeScale
- WXS stand-alone directory...
-
/opt/IBM/eXtremeScale/ObjectGrid
wxs_install_root \ObjectGrid - WXS integrated with WebSphere Application Server...
/opt/IBM/WebSphere/AppServer/optionalLibraries/ObjectGrid
- Trial...
- was_root
- Root directory of a WebSphere Application Server installation:
-
/opt/IBM/WebSphere/AppServer
-

net_client_home
- Root directory of a .NET client installation.
-
C:\Program Files\IBM\WebSphere\eXtreme Scale .NET Client
- restservice_home
- WXS REST data service libraries and samples. Named restservice.
- Stand-alone deployments:
-
/opt/IBM/WebSphere/eXtremeScale/ObjectGrid/restservice
wxs_home\restservice - WebSphere Application Server integrated deployments:
-
/opt/IBM/WebSphere/AppServer/optionalLibraries/ObjectGrid/restservice
- Stand-alone deployments:
- tomcat_root
- Root directory of the Apache Tomcat installation.
-
/opt/tomcat5.5
- wasce_root
- Root directory of the WebSphere Application Server Community Edition installation.
-
/opt/IBM/WebSphere/AppServerCE
- java_home
- Root directory of a JRE installation...

/opt/IBM/WebSphere/eXtremeScale/java

wxs_install_root \java
wxs_home /samples
wxs_home \samples
-
dvd_root/docs/
-
/opt/equinox
c:\Documents and Settings\user_name
/home/user_name
WXS technical overview
The first steps to deploying a data grid are to...
- Start a core group and catalog service
- Start WXS server processes for the data grid to store and retrieve data
A local data grid is a simple, single-instance grid. To best use WXS as an in-memory database processing space, deploy a distributed data grid. Data is spread out over the various eXtreme Scale servers. Each server contains only some of the data, called a partition.
The catalog service locates the partition for a given datum based on its key. A server contains one or more partitions, limited only by the server's memory space.
Increasing the number of partitions increases the capacity of the data grid. The maximum capacity of a data grid is the number of partitions times the usable memory size of each server.
The data of a partition is stored in a shard. For availability, a data grid can be configured with synchronous or asynchronous replicas. Changes to the grid data are made to the primary shard, and replicated to the replica shards. The total memory used or required by a data grid is thus the size of the data grid times (1 (for the primary) + the number of replicas).
WXS distributes the shards of a data grid over the number of servers comprising the grid. These servers may be on the same or different physical servers. For availability, replica shards are placed in separate physical servers from primary shards.
WXS monitors the status of its servers and moves shards during shard or physical server failure and recovery. If the server containing a replica shard fails, WXS allocates a new replica shard, and replicates data from the primary to the new replica. If a server that contains a primary shard fails, the replica shard is promoted to be the primary shard, and, a new replica shard is constructed. If you start an additional server for the data grid, the shards are balanced over all servers. This rebalancing is called scale-out. Similarly, for scale-in, you might stop one of the servers to reduce the resources used by a data grid. As a result, the shards are balanced over the remaining servers.
Caching overview
Caching architecture: Maps, containers, clients, and catalogs
With WXS, your architecture can use either...
- local in-memory data caching
- distributed client-server data caching
WXS requires minimal additional infrastructure to operate. The infrastructure consists of scripts to install, start, and stop a JEE application on a server. Cached data is stored in the WXS server, and clients remotely connect to the server.
Distributed caches offer increased performance, availability and scalability and can be configured using dynamic topologies, in which servers are automatically balanced. We can also add additional servers without restarting your existing eXtreme Scale servers. We can create either simple deployments or large, terabyte-sized deployments in which thousands of servers are needed.
Catalog service
The catalog service...
- controls placement of shards
- discovers and monitors the health of container servers in the data grid
The catalog service hosts logic that should be idle and has little influence on scalability. It is built to service hundreds of container servers that become available simultaneously, and run services to manage the container servers.

The catalog server responsibilities consist of the following services:
- Location service
- Container servers register with the location service. Clients use the location service to search for container servers to host applications.
- Placement service
- Manages the placement of shards across available container servers. Runs as a One of N elected service in the cluster and in the data grid. which means that exactly one instance of the placement service is running. If an instance fails, another process is elected and takes over. For redundancy, the state of the catalog service is replicated across all the servers that are hosting the catalog service.
- Core group manager
-
Manages peer grouping for availability monitoring. Organizes container servers into small groups of servers. Automatically federates the groups of servers.
Uses the high availability manager (HA manager) to group processes together for availability monitoring. Each grouping of the processes is a core group. The core group manager dynamically groups the processes together. These processes are kept small to allow for scalability. Each core group elects a leader that is responsible for sending heartbeat messages to the core group manager. These messages detect if an individual member failed or is still available. The heartbeat mechanism is also used to detect if all the members of a group failed, which causes the communication with the leader to fail.
Responsible for organizing containers into small groups of servers that are loosely federated to make a data grid. When a container server first contacts the catalog service, it waits to be assigned to either a new or existing group. An eXtreme Scale deployment consists of many such groups, and this grouping is a key scalability enabler. Each group consists of JVMs. An elected leader uses the heartbeat mechanism to monitor the availability of the other groups. The leader relays availability information to the catalog service to allow for failure reaction by reallocation and route forwarding.
- Administration
- The catalog service hosts a Managed Bean (MBean) and provides JMX URLs for any of the servers that the catalog service is managing.
For high availability, configure a catalog service domain, which consists of multiple JVMs, including a master JVM and a number of backup JVMs.
Container servers, partitions, and shards
The container server stores application data for the data grid. This data is generally broken into parts, which are called partitions. Partitions are hosted across multiple shard containers. Each container server in turn hosts a subset of the complete data. A JVM might host one or more shard containers and each shard container can host multiple shards. Plan out the heap size for the container servers, which host all of your data. Configure heap settings accordingly.

Partitions host a subset of the data in the grid. WXS automatically places multiple partitions in a single shard container and spreads the partitions out as more container servers become available. Choose the number of partitions carefully before final deployment because the number of partitions cannot be changed dynamically. A hash mechanism is used to locate partitions in the network and eXtreme Scale cannot rehash the entire data set after it has been deployed. As a general rule, we can overestimate the number of partitions

Shards are instances of partitions and have one of two roles: primary or replica. The primary shard and its replicas make up the physical manifestation of the partition. Every partition has several shards that each host all of the data contained in that partition. One shard is the primary, and the others are replicas, which are redundant copies of the data in the primary shard . A primary shard is the only partition instance that allows transactions to write to the cache. A replica shard is a "mirrored" instance of the partition. It receives updates synchronously or asynchronously from the primary shard. The replica shard only allows transactions to read from the cache. Replicas are never hosted in the same container server as the primary and are not normally hosted on the same machine as the primary.

To increase the availability of the data, or increase persistence guarantees, replicate the data. However, replication adds cost to the transaction and trades performance in return for availability.
With eXtreme Scale, we can control the cost as both synchronous and asynchronous replication is supported, as well as hybrid replication models using both synchronous and asynchronous replication modes. A synchronous replica shard receives updates as part of the transaction of the primary shard to guarantee data consistency. A synchronous replica can double the response time because the transaction has to commit on both the primary and the synchronous replica before the transaction is complete. An asynchronous replica shard receives updates after the transaction commits to limit impact on performance, but introduces the possibility of data loss as the asynchronous replica can be several transactions behind the primary.

Maps
A map is a container for key-value pairs, which allows an application to store a value indexed by a key. Maps support indexes that can be added to index attributes on the key or value. These indexes are automatically used by the query runtime to determine the most efficient way to run a query.

A map set is a collection of maps with a common partitioning algorithm. The data within the maps are replicated based on the policy defined on the map set. A map set is only used for distributed topologies and is not needed for local topologies.

A map set can have a schema associated with it. A schema is the metadata that describes the relationships between each map when using homogeneous Object types or entities.
WXS can store serializable Java objects or XDF serialized objects in each of the maps using either...
- ObjectMap API for Java clients
- IGridMapAutoTx/IGridMapPessimisticTx API for .NET clients
A schema can be defined over the maps to identify the relationship between the objects in the maps where each map holds objects of a single type. Defining a schema for maps is required to query the contents of the map objects. WXS can have multiple map schemas defined.
WXS can also store entities using the EntityManager API . Each entity is associated with a map. The schema for an entity map set is automatically discovered using either...
- Entity descriptor XML file
- Annotated Java classes
Each entity has a set of key attributes and set of non-key attributes. An entity can also have relationships to other entities. WXS supports one to one, one to many, many to one and many to many relationships. Each entity is physically mapped to a single map in the map set. Entities allow applications to easily have complex object graphs that span multiple Maps. A distributed topology can have multiple entity schemas.
Clients
Clients...
- connect to a catalog service
- retrieve a description of the server topology
- communicate directly to each server as needed
When the server topology changes because new servers are added or existing servers have failed, the dynamic catalog service routes the client to the appropriate server that is hosting the data. Clients must examine the keys of application data to determine which partition to route the request. Clients can read data from multiple partitions in a single transaction. Clients can update only a single partition in a transaction. After the client updates some entries, the client transaction must use that partition for updates.
Use two types of clients:
- Java clients
- .NET clients
Java clients
Java client applications run on JVMs and connect to the catalog service and container servers.
- A catalog service exists in its own data grid of JVMs. A single catalog service can be used to manage multiple clients or container servers.
- A container server can be started in a JVM by itself or can be loaded into an arbitrary JVM with other containers for different data grids.
- A client can exist in any JVM and communicate with one or more data grids. A client can also exist in the same JVM as a container server.
.NET clients
NET clients work similarly to Java clients, but do not run in JVMs. .NET clients are installed remotely from the catalog and container servers. You connect to the catalog service from within the application. Use a .NET client application to connect to the same data grid as your Java clients.
Enterprise data grid overview
Enterprise data grids use the eXtremeIO transport mechanism and a new serialization format. With the new transport and serialization format, we can connect both Java and .NET clients to the same data grid.
With the enterprise data grid, we can create multiple types of applications, written in different programming languages, to access the same objects in the data grid. In prior releases, data grid applications had to be written in the Java programming language only. With the enterprise data grid function, we can write .NET applications that can create, retrieve, update, and delete objects from the same data grid as the Java application. data grid high-level overview

Object updates across different applications

- The .NET client saves data in its format to the data grid.
- The data is stored in a universal format, so that when the Java client requests this data it can be converted to Java format.
- The Java client updates and re-saves the data.
- The .NET client accesses the updated data, during which the data is converted to .NET format.
Transport mechanism
eXtremeIO (XIO) is a cross-platform transport protocol that replaces the Java-bound ORB. With the ORB, WXS is bound to Java native client applications. The XIO transport mechanism is specifically targeted for data caching, and enables client applications that are in different programming languages to connect to the data grid.
XDF
XDF is a cross-platform serialization format that replaces Java serialization. Enabled on maps with a copyMode attribute value of COPY_TO_BYTES in the ObjectGrid descriptor XML file. With XDF, performance is faster and data is more compact. In addition, the introduction of XDF enables client applications that are in different programming languages to connect to the same data grid.
Class evolution
XDF allows for class evolution. We can evolve class definitions used in the data grid without affecting older applications using previous versions of the class. Classes can function together when one of the classes has fewer fields than the other class.
XDF implementation scenarios:
- Multiple versions of the same object class
- In this scenario, you have a map in a sales application used tracking customers. This map has two different interfaces. One interface is for the web purchases. The second interface is for the phone purchases. In version 2 of this sales application, you decide to give discounts to web shoppers based on their purchasing habits. This discount is stored with the Customer object. The phone sales employees are still using version 1 of the application, which is unaware of the new discount field in the web version. You want Customer objects from version 2 of the application to work with Customer objects that were created with the version 1 application and vice versa.
- Multiple versions of a different object class
- In this scenario, you have a sales application that is written in Java that keeps a map of Customer objects. You also have another application that is written in C# and is used to manage the inventory in the warehouse and ship goods to customers. These classes are currently compatible based on the names of the classes, fields, and types. In your Java sales application, we want to add an option to the Customer record to associate the sales person with a customer account. However, you do not want to update the warehouse application to store this field because it is not needed in the warehouse.
- Multiple incompatible versions of the same class
- In this scenario, your sales and inventory applications both contain a Customer object. The inventory application uses an ID field that is a string and the sales application uses an ID field that is an integer. These types are not compatible. As a result, the objects are probably not stored in the same map. The objects must be handled by the XDF serialization and treated as two distinct types. While this scenario is not really class evolution, it is a consideration that must be part of your overall application design.
Determination for evolution
XDF attempts to evolve a class when the class names match and the field names do not have conflicting types. Using the ClassAlias and FieldAlias annotations are useful when we are trying to match classes between C# and Java applications where the names of the classes or fields are slightly different. We can put these annotations on either the Java and C# application, or both. However, the lookup for the class in the Java application can be less efficient than defining the ClassAlias on the C# application.
The effect of missing fields in serialized data
The constructor of the class is not invoked during deserialization, so any missing fields have a default that is assigned to it based on the language. The application that is adding new fields must be able to detect the missing fields and react when an older version of class is retrieved.
Updating the data is the only way for older applications to keep the newer fields
An application might run a fetch operation and update the map with an older version of the class that is missing some fields in the serialized value from the client. The server then merges the values on the server and determines whether any fields in the original version are merged into the new record. If an application runs a fetch operation, and then removes and inserts an entry, the fields from the original value are lost.
Merging capabilities
Objects within an array or collection are not merged by XDF. It is not always clear whether an update to an array or collection is intended to change the elements of that array or the type. If a merge occurs based on positioning, when an entry in the array is moved, XDF might merge fields that are not intended to be associated. As a result, XDF does not attempt to merge the contents of arrays or collections. However, if you add an array in a newer version of a class definition, the array gets merged back into the previous version of the class.
IBM eXtremeMemory
IBM eXtremeMemory enables objects to be stored in native memory instead of the Java heap. By moving objects off the Java heap, we can avoid garbage collection pauses, leading to more constant performance and predicable response times.
The JVM relies on usage heuristics to collect, compact, and expand process memory. The garbage collector completes these operations. However, running garbage collection has an associated cost. The cost of running garbage collection increases as the size of the Java heap and number of objects in the data grid increase. The JVM provides different heuristics for different use cases and goals: optimum throughput, optimum pause time, generational, balanced, and real-time garbage collection. No heuristic is perfect. A single heuristic cannot suit all possible configurations.
WXS uses data caching, with distributed maps that have entries with a well-known lifecycle. This lifecycle includes the following operations: GET, INSERT, DELETE, and UPDATE. By using these well-known map lifecycles, eXtremeMemory can manage memory usage for data grid objects in container servers more efficiently than the standard JVM garbage collector.
The following diagram shows how using eXtremeMemory leads to more consistent relative response times in the environment. As the relative response times reach the higher percentiles, the requests that are using eXtremeMemory have lower relative response times. The diagram shows the 95-100 percentiles. .

Zones
Zones give you control over shard placement. Zones are user-defined logical groupings of physical servers. The following are examples of different types of zones:
- Different blade servers
- Chassis of blade servers
- Floors of a building
- Buildings
- Different geographical locations in a multiple data center environment
- Virtualized environment where many server instances, each with a unique IP address, run on the same physical server
Zones defined between data centers
The classic example and use case for zones is when you have two or more geographically dispersed data centers. Dispersed data centers spread the data grid over different locations for recovery from data center failure. For example, you might want to ensure that you have a full set of asynchronous replica shards for the data grid in a remote data center. With this strategy, we can recover from the failure of the local data center transparently, with no loss of data. Data centers themselves have high speed, low latency networks. However, communication between one data center and another has higher latency. Synchronous replicas are used in each data center where the low latency minimizes the impact of replication on response times. Using asynchronous replication reduces impact on response time. The geographic distance provides availability in case of local data center failure.
In the following example, primary shards for the Chicago zone have replicas in the London zone. Primary shards for the London zone have replicas in the Chicago zone.

Three configuration settings in eXtreme Scale control shard placement:
- Set the deployment file
- Group containers
- Specify rules
Disable development mode
To disable development mode, and to activate the first eXtreme Scale shard placement policy, in the deployment XML file, set...
-
developmentMode="false"
Policy 1: Primary and replica shards for partition are placed in separate physical servers
If a single physical server fails, no data is lost. Most efficient setting for production high availability.
Physical servers are defined by an IP address. The IP addresses used by container servers hosting the shards is set using the start script parameter...
-
-listenerHost
Policy 2: Primary and replica shards for the same partition are placed in separate zones
With this policy, we can control shard placement by defining zones. You choose your physical or logical boundary or grouping of interest. Then, choose a unique zone name for each group, and start the container servers in each of your zones with the name of the appropriate zone. Thus eXtreme Scale places shards so that shards for the same partition are placed in separate zones.
Container servers are assigned to zones with the zone parameter on the start server script. In a WAS environment, zones are defined through node groups with a specific name format:
ReplicationZone<Zone>
We can extend the example of a data grid with one replica shard by deploying it across two data centers. Define each data center as an independent zone. Use a zone name of DC1 for the container servers in the first data center, and DC2 for the container servers in the second data center. With this policy, the primary and replica shards for each partition would be in different data centers. If a data center fails, no data is lost. For each partition, either its primary or replica shard is in the other data center.
Zone rules
The finest level of control over shard placement is achieved using zone rules, specified in the zoneMetadata element of the WXS deployment policy descriptor XML. A zone rule defines a set of zones in which shards are placed. A shardMapping element assigns a shard to a zone rule. The shard attribute of the shardMapping element specifies the shard type:
| P | primary shard |
| S | replica shards |
| A | replica shards |
If more than one synchronous or asynchronous replica exist, provide shardMapping elements of the appropriate shard type. The exclusivePlacement attribute of the zoneRule element determines the placement of shards...
| true | Shards cannot be placed in the same zone as another shard from the same partition. Have at least as many zones in the rule as you have shards to ensure each shard can be in its own zone. false . |
| false | Shards from the same partition can be placed in the same zone. |
Shard placement strategies
Rolling upgrades
Consider a scenario in which we want to apply rolling upgrades to your physical servers, including maintenance that requires restarting the deployment. In this example, assume that you have a data grid spread across 20 physical servers, defined with one synchronous replica. You want to shut down 10 of the physical servers at a time for the maintenance.When you shut down groups of 10 physical servers, to assure no partition has both its primary and replica shards on the servers we are shutting down, define a third zone. Instead of two zones of 10 physical servers each, use three zones, two with seven physical servers, and one with six. Spreading the data across more zones allows for better failover for availability.
Rather than defining another zone, the other approach is to add a replica.
Upgrade eXtreme Scale
When upgrading eXtreme Scale software in a rolling manner with data grids that contain live data, the catalog service software version must be greater than or equal to the container server software versions. Upgrade all the catalog servers first with a rolling strategy.
Change data model
To change the data model or schema of objects that are stored in the data grid without causing downtime...
- Start a new data grid with the new schema
- Copy the data from the old data grid to the new data grid
- Shut down the old data grid
Each of these processes are disruptive and result in downtime. To change the data model without downtime, store the object in one of these formats:
- XML as the value
- blob made with Google protobuf
- JavaScript Object Notation (JSON)
Write serializers to go from plain old Java object (POJO) to one of these formats on the client side.
Virtualization
eXtreme Scale insures that two shards for the same partition are never placed on the same IP address, as described in Policy 1 . When deploying on virtual images, such as VMware, many server instances, each with a unique IP address, can be run on the same physical server. To ensure that replicas can only be placed on separate physical servers, group physical servers into zones, and use zone placement rules to keep primary and replica shards in separate zones.
Multiple buildings or data centers with slower network connections can lead to lower bandwidth and higher latency connections. The WXS catalog service organizes container servers into core groups that exchange heartbeats to detect container server failure. These core groups do not span zones. A leader within each core group pushes membership information to the catalog service which verifies reported failures before responding to membership information by heartbeating the container server in question. If the catalog service sees a false failure detection, the catalog service takes no action. The core group partition heals quickly. The catalog service also heartbeats core group leaders periodically at a slow rate to handle the case of core group isolation.
Evictors
Evictors remove data from the data grid. We can set either...
- A time-based evictor
- BackingMap that specifies the pluggable evictor
Evictor types
A default time to live TTL evictor is created for every backing map.
- None
-
Entries never expire and are never removed from the map.
- Creation time (CREATION_TIME ttlType)
- Entries are evicted when time from creation equals TimeToLive (TTL). If TTL is 10 seconds, the entry is automatically evicted ten seconds after it was inserted.
This evictor is best used when reasonably high amounts of additions to the cache exist that are only used for a set amount of time. With this strategy, anything that is created is removed after the set amount of time.
The CREATION_TIME ttlType is useful in scenarios such as refreshing stock quotes every 20 minutes or less. Suppose a Web application obtains stock quotes, and getting the most recent quotes is not critical. In this case, the stock quotes are cached in a data grid for 20 minutes. After 20 minutes, the map entries expire and are evicted. Every twenty minutes or so, the data grid uses the Loader plug-in to refresh the data with data from the database. The database is updated every 20 minutes with the most recent stock quotes.
- Last access time (LAST_ACCESS_TIME ttlType)
-
Entries are evicted depending upon when they were last accessed, whether they were read or updated.
- Last update time (LAST_UPDATE_TIME ttlType)
-
Entries are evicted depending upon when they were last updated.
If we are using LAST_ACCESS_TIME or LAST_UPDATE_TIME, set the TTL value to a lower number than if we are using CREATION_TIME. The TTL attributes for each are reset every time they are access. If the TTL attribute is equal to 15, and an entry has existed for 14 seconds but then gets accessed, it does not expire again for another 15 seconds. If you set the TTL value to a relatively high number, many entries might never be evicted. However, if you set the value to something like 15 seconds, entries might be removed when they are not often accessed.
LAST_ACCESS_TIME and LAST_UPDATE_TIME are useful in scenarios such as holding session data from a client, using a data grid map. Session data must be destroyed if the client does not use the session data for some period of time. For example, if an application's session data times out after 30 minutes of no activity by the client, using an evictor type of LAST_ACCESS_TIME or LAST_UPDATE_TIME with the TTL value set to 30 minutes is appropriate.
You may also write your own evictors
Pluggable evictor
Use an optional pluggable evictor to evict entries based on the number of entries in the BackingMap.
| LRUEvictor | Uses a least recently used (LRU) algorithm to decide which entries to evict when the BackingMap exceeds a maximum number of entries. |
| LFUEvictor | Uses a least frequently used (LFU) algorithm to decide which entries to evict when the BackingMap exceeds a maximum number of entries. |
The BackingMap informs an evictor as entries are created, modified, or removed in a transaction, keeping track of these entries and choosing when to evict entries.
A BackingMap instance has no configuration information for a maximum size. Instead, evictor properties are set to control the evictor behavior. Both the LRUEvictor and the LFUEvictor have a maximum size property used to cause the evictor to begin to evict entries after the maximum size is exceeded. Like the TTL evictor, the LRU and LFU evictors might not immediately evict an entry when the maximum number of entries is reached to minimize impact on performance. We can write your own custom evictors.
Memory-based eviction
Memory-based eviction is only supported on JEE v5 or later.
All built-in evictors support memory-based eviction that can be enabled on the BackingMap interface by setting the evictionTriggers attribute of BackingMap interface MEMORY_USAGE_THRESHOLD.
Memory-based eviction is based on heap usage threshold. When memory-based eviction is enabled on BackingMap and the BackingMap has any built-in evictor, the usage threshold is set to a default percentage of total memory if the threshold has not been previously set.
When using memory-based eviction, configure the garbage collection threshold to the same value as the target heap utilization. If the memory-based eviction threshold is set at 50 percent and the garbage collection threshold is at the default 70 percent level, the heap utilization can go as high as 70 percent because memory-based eviction is only triggered after a garbage collection cycle.
To change the default usage threshold percentage, set memoryThresholdPercentage. To set the target usage threshold on a client process, we can use the MemoryPoolMXBean.
The memory-based eviction algorithm used by WXS is sensitive to the behavior of the garbage collection algorithm in use. The best algorithm for memory-based eviction is the IBM default throughput collector. Generation garbage collection algorithms can cause undesired behavior, and so you should not use these algorithms with memory-based eviction.
To change the usage threshold percentage, set the memoryThresholdPercentage property on the container and server property files for eXtreme Scale server processes.
During runtime, if the memory usage exceeds the target usage threshold, memory-based evictors start evicting entries and try to keep memory usage below the target usage threshold. However, no guarantee exists that the eviction speed is fast enough to avoid a potential out of memory error if the system runtime continues to quickly consume memory.
OSGi framework overview
WXS OSGi support allows us to deploy WXS v8.6 in the Eclipse Equinox OSGi framework.
With the dynamic update capability that the OSGi framework provides, we can update the plug-in classes without restarting the JVM. These plug-ins are exported by user bundles as services. WXS accesses the service or services by looking them up the OSGi registry.
eXtreme Scale containers can be configured to start more dynamically using either...
- OSGi configuration admin service
- OSGi Blueprint
To deploy a new data grid with its placement strategy, create an OSGi configuration or deploy a bundle with WXS descriptor XML files. With OSGi support, application bundles containing WXS configuration data can be installed, started, stopped, updated, and uninstalled without restarting the whole system. With this capability, we can upgrade the application without disrupting the data grid.
Plug-in beans and services can be configured with custom shard scopes, allowing sophisticated integration options with other services running in the data grid. Each plug-in can use OSGi Blueprint rankings to verify that every instance of the plug-in is activated is at the correct version. An OSGi-managed bean (MBean) and xscmd utility are provided, allowing you to query the WXS plug-in OSGi services and their rankings.
This capability allows administrators to quickly recognize potential configuration and administration errors and upgrade the plug-in service rankings in use by eXtreme Scale .
OSGi bundles
To interact with and deploy plug-ins in the OSGi framework, use bundles. In the OSGi service platform, a bundle is a JAR file that contains Java code, resources, and a manifest that describes the bundle and its dependencies. The bundle is the unit of deployment for an application. The eXtreme Scale product supports the following bundle types:
- Server bundle
- The server bundle is the objectgrid.jar file and is installed with the WXS stand-alone server installation and is required for running eXtreme Scale servers and can also be used for running eXtreme Scale clients, or local, in-memory caches. The bundle ID for the objectgrid.jar file is com.ibm.websphere.xs.server_<version>, where the version is in the format: <Version>.<Release>.<Modification>. For example, the server bundle for eXtreme Scale version 7.1.1 is com.ibm.websphere.xs.server_7.1.1.
- Client bundle
- The client bundle is the ogclient.jar file and is installed with the WXS stand-alone and client installations and is used to run eXtreme Scale clients or local, in-memory caches. The bundle ID for the ogclient.jar file is com.ibm.websphere.xs.client_version, where the version is in the format: <Version>.<Release>.<Modification>. For example, the client bundle for eXtreme Scale version 7.1.1 is com.ibm.websphere.xs.client_7.1.1.
Limitations
We cannot restart the WXS bundle because we cannot restart the object request broker (ORB) or eXtremeIO (XIO). To restart the WXS server, restart the OSGi framework.
Cache integration overview
The crucial element that gives WXS the capability to perform with such versatility and reliability is its application of caching concepts to optimize the persistence and recollection of data in virtually any deployment environment.
Spring cache provider
Spring Framework Version 3.1 introduced a new cache abstraction. With this new abstraction, we can transparently add caching to an existing Spring application. Use WXS as the cache provider for the cache abstraction.
Liberty profile
The Liberty profile is a highly composable, fast-to-start, dynamic application server runtime environment.
You install the Liberty profile when you install WXS with WebSphere Application Server Version 8.5. Because the Liberty profile does not include a Java runtime environment (JRE), you have to install a JRE provided by either Oracle or IBM .
This server supports two models of application deployment:
- Deploy an application by dropping it into the dropins directory.
- Deploy an application by adding it to the server configuration.
The Liberty profile supports a subset of the following parts of the full WebSphere Application Server programming model:
- Web applications
- OSGi applications
- JPA
Associated services such as transactions and security are only supported as far as is required by these application types and by JPA.
Features are the units of capability by which you control the pieces of the runtime environment that are loaded into a particular server. The Liberty profile includes the following main features:
- Bean validation
- Blueprint
- Java API for RESTful Web Services
- Java Database Connectivity (JDBC)
- Java Naming and Directory Interface
- JPA
- JavaServer Faces (JSF)
- JavaServer Pages (JSP)
- Lightweight Directory Access Protocol (LDAP)
- Local connector (for JMX clients)
- Monitoring
- OSGi JPA (JPA support for OSGi applications)
- Remote connector (for JMX clients)
- SSL
- Security
- Servlet
- Session persistence
- Transaction
- Web application bundle (WAB)
- z/OS security
- z/OS transaction management
- z/OS workload management
We can work with the runtime environment directly, or using the WebSphere Application Server Developer Tools for Eclipse.
On distributed platforms, the Liberty profile provides both a development and an operations environment. On the Mac, it provides a development environment.
On z/OS systems, the Liberty profile provides an operations environment. We can work natively with this environment using the MVS. console. For application development, consider using the Eclipse-based developer tools on a separate distributed system, on Mac OS, or in a Linux shell on z/OS.
Run the Liberty profile with a third-party JRE
When you use a JRE that Oracle provides, special considerations must be taken to run WXS with the Liberty profile.
- Classloader deadlock
- You might experience a classloader deadlock which has been worked around using the following JVM_ARGS settings. If you experience a deadlock in BundleLoader logic, add the following arguments:
export JVM_ARGS="$JVM_ARGS -XX:+UnlockDiagnosticVMOptions -XX:+UnsyncloadClass"
- IBM ORB
- WXS requires that you use the IBM ORB, which is included in a WebSphere Application Server installation, but not in the Liberty profile. Set the endorsed directories using the Java system property, java.endorsed.dirs, to add the directory containing the IBM ORB JAR files. The IBM ORB JAR files are included in the WXS installation in the wlp\wxs\lib\endorsed directory.
WebSphere eXtreme Scale server features for the Liberty profile
Features are the units of capability by which you control the pieces of the runtime environment that are loaded into a particular server.
The following list contains information about the main available features. Including a feature in the configuration might cause one or more more features to be loaded automatically. Each feature includes a brief description and an example of how the feature is declared
Server feature
The server feature contains the capability for running a WXS server, both catalog and container. Add the server feature when we want to run a catalog server in the Liberty profile or when we want to deploy a grid application into the Liberty profile.
<wlp_install_root>/usr/server/wxsserver/server.xml file
<server description="WXS Server"><featureManager>
<feature>eXtremeScale.server-1.1</feature>
</featureManager>
<com.ibm.ws.xs.server.config /> </server>
Client feature
The client feature contains most of the programming model for eXtreme Scale. Add the client feature when you have an application running in the Liberty profile that is going to use eXtreme Scale APIs.
<wlp_install_root>/usr/server/wxsclient/server.xml file
<server description="WXS client"><featureManager>
<feature>eXtremeScale.client-1.1</feature>
</featureManager>
<com.ibm.ws.xs.client.config /> </server>
Web feature
Deprecated. Use the webapp feature when we want to replicate HTTP session data for fault tolerance.
The web feature contains the capability to extend the Liberty profile web application. Add the web feature when we want to replicate HTTP session data for fault tolerance.
<wlp_install_root>/usr/server/wxsweb/server.xml file
<server description="WXS enabled Web Server"><featureManager>
<feature>eXtremeScale.web-1.1</feature>
</featureManager>
<com.ibm.ws.xs.web.config /> </server>
WebApp feature
The webApp feature contains the capability to extend the Liberty profile web application. Add the webApp feature when we want to replicate HTTP session data for fault tolerance.
<wlp_install_root>/usr/server/wxswebapp/server.xml file
<wlp_install_root>/usr/server/wxswebapp/server.xml file <server description="WXS enabled Web Server"> <featureManager> <feature>eXtremeScale.webApp-1.1</feature> </featureManager> <com.ibm.ws.xs.webapp.config /> </server>
WebGrid feature
A Liberty profile server can host a data grid that caches data for applications to replicate HTTP session data for fault tolerance.
<wlp_install_root>/usr/server/wxswebgrid/server.xml file
<wlp_install_root>/usr/server/wxswebgrid/server.xml file <server description="WXS enabled Web Server"> <featureManager> <feature>eXtremeScale.webGrid-1.1</feature> </featureManager> <com.ibm.ws.xs.webgrid.config /> </server>
Dynamic cache feature
A Liberty profile server can host a data grid that caches data for applications that have dynamic cache enabled.
<wlp_install_root>/usr/server/wxsweb/server.xml file
<server description="WXS enabled Web Server"><featureManager>
<feature>eXtremeScale.dynacacheGrid-1.1</feature>
</featureManager>
<com.ibm.ws.xs.xsDynacacheGrid.config /> </server>
JPA feature
Use the JPA feature for the applications that use JPA in the Liberty profile.
<wlp_install_root>/usr/server/wxsjpa/server.xml file
<wlp_install_root>/usr/server/wxsjpa/server.xml file <server description="WXS enabled Web Server"> <featureManager> <feature>eXtremeScale.jpa-1.1</feature> </featureManager> <com.ibm.ws.xs.jpa.config /> </server>
REST feature
Access simple data grids hosted by a collective in the Liberty profile.
<wlp_install_root>/usr/server/wxsrest/server.xml file
<wlp_install_root>/usr/server/wxsrest/server.xml file <server description="WXS enabled Web Server"> <featureManager> <feature>eXtremeScale.rest-1.1</feature> </featureManager> <com.ibm.ws.xs.rest.config /> </server>
OpenJPA level 2 (L2) and Hibernate cache plug-in
WXS includes JPA L2 cache plug-ins for both OpenJPA and Hibernate JPA providers. When you use one of these plug-ins, the application uses the JPA API. A data grid is introduced between the application and the database, improving response times.
Using WXS as an L2 cache provider increases performance when we are reading and querying data and reduces load to the database. WXS has advantages over built-in cache implementations because the cache is automatically replicated between all processes. When one client caches a value, all other clients are able to use the cached value that is locally in-memory.
We can configure the topology and properties for the L2 cache provider in the persistence.xml file.
The JPA L2 cache plug-in requires an application that uses the JPA APIs. To use WXS APIs to access a JPA data source, use the JPA loader.
JPA L2 cache topology considerations
The following factors affect which type of topology to configure:- How much data do you expect to be cached?
- If the data can fit into a single JVM heap, use the Embedded topology or Intra-domain topology.
- If the data cannot fit into a single JVM heap, use the Embedded, partitioned topology, or Remote topology
- What is the expected read-to-write ratio?
The read-to-write ratio affects the performance of the L2 cache. Each topology handles read and write operations differently.
Embedded topology local read, remote write Intra-domain topology local read, local write Embedded, partitioned topology Partitioned: remote read, remote write Remote topology remote read, remote write. Applications that are mostly read-only should use embedded and intra-domain topologies when possible. Applications that do more writing should use intra-domain topologies.
- What is percentage of data is queried versus found by a key?
When enabled, query operations make use of the JPA query cache. Enable the JPA query cache for applications with high read to write ratios only, for example when we are approaching 99% read operations. If you use JPA query cache, use the Embedded topology or Intra-domain topology .
The find-by-key operation fetches a target entity if the target entity does not have any relationship. If the target entity has relationships with the EAGER fetch type, these relationships are fetched along with the target entity. In JPA data cache, fetching these relationships causes a few cache hits to get all the relationship data.
- What is the tolerated staleness level of the data?
In a system with few JVMs, data replication latency exists for write operations. The goal of the cache is to maintain an ultimate synchronized data view across all JVMs. When using the intra-domain topology, a data replication delay exists for write operations. Applications using this topology must be able to tolerate stale reads and simultaneous writes that might overwrite data.
Intra-domain topology
With an intra-domain topology, primary shards are placed on every container server in the topology. These primary shards contain the full set of data for the partition. Any of these primary shards can also complete cache write operations. This configuration eliminates the bottleneck in the embedded topology where all the cache write operations must go through a single primary shard .
In an intra-domain topology, no replica shards are created, even if you have defined replicas in the configuration files. Each redundant primary shard contains a full copy of the data, so each primary shard can also be considered as a replica shard. This configuration uses a single partition, similar to the embedded topology.

Related JPA cache configuration properties for the intra-domain topology:
- ObjectGridName=objectgrid_name,ObjectGridType=EMBEDDED,PlacementScope=CONTAINER_SCOPE,PlacementScopeTopology=HUB|RING
Advantages:
- Cache reads and updates are local.
- Simple to configure.
Limitations:
- This topology is best suited for when the container servers can contain the entire set of partition data.
- Replica shards, even if they are configured, are never placed because every container server hosts a primary shard . However, all the primary shards are replicating with the other primary shards, so these primary shards become replicas of each other.
Embedded topology
Consider using an intra-domain topology for the best performance.
An embedded topology creates a container server within the process space of each application. OpenJPA and Hibernate read the in-memory copy of the cache directly and write to all of the other copies. We can improve the write performance by using asynchronous replication. This default topology performs best when the amount of cached data is small enough to fit in a single process. With an embedded topology, create a single partition for the data.

Related JPA cache configuration properties for the embedded topology:
ObjectGridName=objectgrid_name,ObjectGridType=EMBEDDED,MaxNumberOfReplicas=num_replicas,ReplicaMode=SYNC | ASYNC | NONE
Advantages:
- All cache reads are fast, local accesses.
- Simple to configure.
Limitations:
- Amount of data is limited to the size of the process.
- All cache updates are sent through one primary shard, which creates a bottleneck.
Embedded, partitioned topology
Consider using an intra-domain topology for the best performance.
Do not use the JPA query cache with an embedded partitioned topology. The query cache stores query results that are a collection of entity keys. The query cache fetches all entity data from the data cache. Because the data cache is divided up between multiple processes, these additional calls can negate the benefits of the L2 cache.
When the cached data is too large to fit in a single process, we can use the embedded, partitioned topology. This topology divides the data over multiple processes. The data is divided between the primary shards, so each primary shard contains a subset of the data. We can still use this option when database latency is high.

Related JPA cache configuration properties for the embedded, partitioned topology:
ObjectGridName=objectgrid_name,ObjectGridType=EMBEDDED_PARTITION,ReplicaMode=SYNC | ASYNC | NONE, NumberOfPartitions=num_partitions,ReplicaReadEnabled=TRUE | FALSE
Advantages:
- Stores large amounts of data.
- Simple to configure
- Cache updates are spread over multiple processes.
Limitation:
- Most cache reads and updates are remote.
For example, to cache 10 GB of data with a maximum of 1 GB per JVM, 10 JVMs are required. The number of partitions must therefore be set to 10 or more. Ideally, the number of partitions must be set to a prime number where each shard stores a reasonable amount of memory. Usually, the numberOfPartitions setting is equal to the number of JVMs. With this setting, each JVM stores one partition. If you enable replication, you must increase the number of JVMs in the system. Otherwise, each JVM also stores one replica partition, which consumes as much memory as a primary partition.
Read about Sizing memory and partition count calculation to maximize the performance of your chosen configuration.
For example, in a system with four JVMs, and the numberOfPartitions setting value of
4, each JVM hosts a primary partition. A read operation has a 25 percent chance of fetching data from a locally available partition, which is much faster compared to getting data from a remote JVM. If a read operation, such as running a query, needs to fetch a collection of data that involves 4 partitions evenly, 75 percent of the calls are remote and 25 percent of the calls are local. If the ReplicaMode setting is set to either
SYNC or ASYNC and the ReplicaReadEnabled setting is set to true, then four replica partitions are created and spread across four JVMs. Each JVM hosts one primary partition and one replica partition. The chance that the read operation runs locally increases to 50 percent. The read operation that fetches a collection of data that involves four partitions evenly has 50 percent remote calls and 50 percent local calls. Local calls are much faster than remote calls. Whenever remote calls occur, the performance drops.
Remote topology
CAUTION:
Do not use the JPA query cache with a remote topology . The query cache stores query results that are a collection of entity keys. The query cache fetches all entity data from the data cache. Because the data cache is remote, these additional calls can negate the benefits of the L2 cache.
Consider using an intra-domain topology for the best performance.
A remote topology stores all of the cached data in one or more separate processes, reducing memory use of the application processes. We can take advantage of distributing your data over separate processes by deploying a partitioned, replicated eXtreme Scale data grid. As opposed to the embedded and embedded partitioned configurations described in the previous sections, if we want to manage the remote data grid, you must do so independent of the application and JPA provider.

Related JPA cache configuration properties for the remote topology :
ObjectGridName=objectgrid_name,ObjectGridType=REMOTE
The REMOTE ObjectGrid type does not require any property settings because the ObjectGrid and deployment policy is defined separately from the JPA application. The JPA cache plug-in remotely connects to an existing remote ObjectGrid.
Because all interaction with the ObjectGrid is remote, this topology has the slowest performance among all ObjectGrid types.
Advantages:
- Stores large amounts of data.
- Application process is free of cached data.
- Cache updates are spread over multiple processes.
- Flexible configuration options.
Limitation:
- All cache reads and updates are remote.
HTTP session management
The session replication manager that is shipped with WXS can work with the default session manager in WebSphere Application Server. Session data is replicated from one process to another process to support user session data high availability.
Features
The session manager has been designed so that it can run in any Java EE v 6 or later container. Because the session manager does not have any dependencies on WebSphere APIs, it can support various versions of WebSphere Application Server, as well as vendor application server environments.
The HTTP session manager provides session replication capabilities for an associated application. The session replication manager works with the session manager for the web container. Together, the session manager and web container create HTTP sessions and manage the life cycles of HTTP sessions that are associated with the application. These life cycle management activities include: the invalidation of sessions based on a timeout or an explicit servlet or JavaServer Pages (JSP) call and the invocation of session listeners that are associated with the session or the web application. The session manager persists its sessions in a fully replicated, clustered and partitioned data grid. The use of the WXS session manager enables the session manager to provide HTTP session failover support when application servers are shut down or end unexpectedly. The session manager can also work in environments that do not support affinity, when affinity is not enforced by a load balancer tier that sprays requests to the application server tier.
Usage scenarios
The session manager can be used in the following scenarios:
- In environments that use application servers at different versions of WebSphere Application Server, such as in a migration scenario.
- In deployments that use application servers from different vendors. For example, an application that is being developed on open source application servers and that is hosted on WebSphere Application Server. Another example is an application that is being promoted from staging to production. Seamless migration of these application server versions is possible while all HTTP sessions are live and being serviced.
- In environments that require the user to persist sessions with higher quality of service (QoS) levels. Session availability is better guaranteed during server failover than default WebSphere Application Server QoS levels.
- In an environment where session affinity cannot be guaranteed, or environments in which affinity is maintained by a vendor load balancer. With a vendor load balancer, the affinity mechanism must be customized to that load balancer.
- In any environment to offload the processing required for session management and storage to an external Java process.
- In multiple cells to enable session failover between cells.
- In multiple data centers or multiple zones.
How the session manager works
The session replication manager uses a session listener to listen on the changes of session data. The session replication manager persists the session data into an ObjectGrid instance either locally or remotely. We can add the session listener and servlet filter to every web module in the application with tooling that ships with WXS. We can also manually add these listeners and filters to the web deployment descriptor of the application.
This session replication manager works with each vendor web container session manager to replicate session data across JVMs. When the original server dies, users can retrieve session data from other servers.

Deployment topologies
The session manager can be configured using two different dynamic deployment scenarios:
- Embedded, network attached eXtreme Scale container servers
- In this scenario, the WXS servers are collocated in the same processes as the servlets. The session manager can communicate directly to the local ObjectGrid instance, avoiding costly network delays. This scenario is preferable when running with affinity and performance is critical.
- Remote, network attached eXtreme Scale container servers
- In this scenario, the WXS servers run in external processes from the process in which the servlets run. The session manager communicates with a remote eXtreme Scale server grid. This scenario is preferable when the web container tier does not have the memory to store the session data. The session data is offloaded to a separate tier, which results in lower memory usage on the web container tier. Higher latency occurs because the data is in a remote location.
Generic embedded container startup
eXtreme Scale automatically starts an embedded ObjectGrid container inside any application-server process when the web container initializes the session listener or servlet filter, if the objectGridType property is set to EMBEDDED.
You are not required to package an ObjectGrid.xml file and objectGridDeployment.xml file into your web application WAR or EAR file. The default ObjectGrid.xml and objectGridDeployment.xml files are packaged in the product JAR file. Dynamic maps are created for various web application contexts by default. Static eXtreme Scale maps continue to be supported.
This approach for starting embedded ObjectGrid containers applies to any type of application server. The approaches involving a WebSphere Application Server component or WebSphere Application Server Community Edition GBean are deprecated.
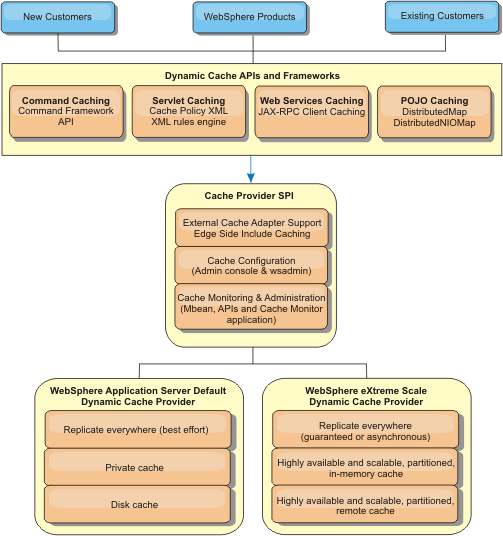
Dynamic cache provider overview
The WebSphere Application Server provides a Dynamic Cache service that is available to deployed Java EE applications. This service is used to cache data such as output from servlet, JSP or commands, as well as object data progamatically specified within an enterprise application using the DistributedMap APIs.
Initially, the only service provider for the Dynamic Cache service was the default dynamic cache engine that is built into WebSphere Application Server. Today customers can also specify WXS to be the cache provider for any given cache instance. By setting up this capability, we can enable applications that use the Dynamic Cache service, to use the features and performance capabilities of WXS.
We can install and configure the dynamic cache provider
Deciding how to use WXS
The available features in WXS significantly increase the distributed capabilities of the Dynamic Cache service beyond what is offered by the default dynamic cache provider and data replication service. With eXtreme Scale, we can create caches that are truly distributed between multiple servers, rather than just replicated and synchronized between the servers. Also, eXtreme Scale caches are transactional and highly available, ensuring that each server sees the same contents for the dynamic cache service. WXS offers a higher quality of service for cache replication provided via DRS.
However, these advantages do not mean that the WXS dynamic cache provider is the right choice for every application. Use the decision trees and feature comparison matrix below to determine what technology fits the application best.
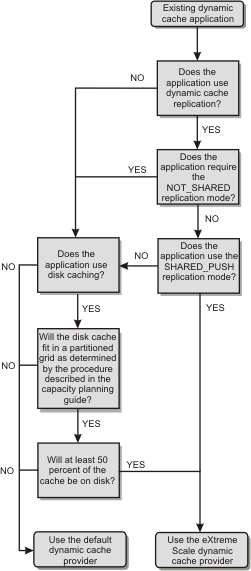
Decision tree for migrating existing dynamic cache applications
Decision tree for choosing a cache provider for new applications

Feature comparison
| Feature | DynaCache | WXS provider | WXS API |
|---|---|---|---|
| Local, in-memory caching | Yes | via Near-cache capability | via Near-cache capability |
| Distributed caching | via DRS | Yes | Yes |
| Linearly scalable | No | Yes | Yes |
| Reliable replication (synchronous) | No | Yes | Yes |
| Disk overflow | Yes | N/A | N/A |
| Eviction | LRU/TTL/heap-based | LRU/TTL (per partition) | LRU/TTL (per partition) |
| Invalidation | Yes | Yes | Yes |
| Relationships | Dependency / template ID relationships | Yes | No (other relationships are possible) |
| Non-key lookups | No | No | via Query and index |
| Back-end integration | No | No | via Loaders |
| Transactional | No | Yes | Yes |
| Key-based storage | Yes | Yes | Yes |
| Events and listeners | Yes | No | Yes |
| WebSphere Application Server integration | Single cell only | Multiple cell | Cell independent |
| Java Standard Edition support | No | Yes | Yes |
| Monitoring and statistics | Yes | Yes | Yes |
| Security | Yes | Yes | Yes |
An eXtreme Scale distributed cache can only store entries where the key and the value both implement the java.io.Serializable interface.
Topology types
Deprecated: The local, embedded, and embedded-partitioned topology types are deprecated.
A dynamic cache service created with WXS as the provider can be deployed in a remote topology .
Remote topology
The remote topology eliminates the need for a disk cache. All of the cache data is stored outside of WebSphere Application Server processes.
WXS supports standalone container processes for cache data. These container processes have a lower overhead than a WebSphere Application Server process and are also not limited to using a particular JVM. For example, the data for a dynamic cache service being accessed by a 32-bit WebSphere Application Server process could be located in a WXS container process running on a 64-bit JVM. This allows users to use the increased memory capacity of 64-bit processes for caching, without incurring the additional overhead of 64-bit for application server processes. The remote topology is shown in the following image:

Dynamic cache engine and eXtreme Scale functional differences
Users should not notice a functional difference between the two caches except that the WXS backed caches do not support disk offload or statistics and operations related to the size of the cache in memory.
There will be no appreciable difference in the results returned by most Dynamic Cache API calls, regardless of whether the customer is using the default dynamic cache provider or the WXS cache provider. For some operations we cannot emulate the behavior of the dynamic cache engine using eXtreme Scale.
Dynamic cache statistics
Statistical data for a WXS dynamic cache can be retrieved using the WXS monitoring tooling.
MBean calls
The WXS dynamic cache provider does not support disk caching. Any MBean calls relating to disk caching will not work.
Dynamic cache replication policy mapping
The WXS dynamic cache provider's remote topology supports a replication policy that most closely matches the SHARED_PULL and SHARED_PUSH_PULL policy (using the terminology used by the default WebSphere Application Server dynamic cache provider). In a WXS dynamic cache, the distributed state of the cache is completely consistent between all the servers.
Global index invalidation
Use a global index to improve invalidation efficiency in large partitioned environments; for example, more than 40 partitions. Without the global index feature, the dynamic cache template and dependency invalidation processing must send remote agent requests to all partitions, which results in slower performance. When configuring a global index, invalidation agents are sent only to applicable partitions that contain cache entries related to the Template or Dependency ID. The potential performance improvement will be greater in environments with large numbers of partitions configured. We can configure a global index using the Dependency ID and Template ID indexes, which are available in the example dynamic cache objectGrid descriptor XML files.
Security
When a cache is running in a remote topology, it is possible for a standaloneeXtreme Scale client to connect to the cache and affect the contents of the dynamic cache instance. It is therefore important WXS servers containing the dynamic cache instances reside in an internal network, behind what is typically known as the network DMZ.
Near cache
A dynamic cache instance can be configured to create a maintain a near cache, which will reside locally within the application server JVM and will contain a subset of the entries contained within the remote dynamic cache instance. We can configure a near cache instance using file...
-
dynacache-nearCache-ObjectGrid.xml
Database integration
WXS is used to front a traditional database and eliminate read activity normally pushed to the database. A coherent cache can be used with an application directly or indirectly using an object relational mapper. The coherent cache can then offload the database or backend from reads. In a slightly more complex scenario, such as transactional access to a data set where only some of the data requires traditional persistence guarantees, filtering can be used to offload even write transactions.
We can configure WXS to function as a highly flexible in-memory database processing space. However, WXS is not an object relational mapper (ORM). It does not know where the data in the data grid came from. An application or an ORM can place data in a WXS server.
It is the responsibility of the source of the data to make sure that it stays consistent with the database where data originated. This means WXS cannot invalidate data that is pulled from a database automatically. The application or mapper must provide this function and manage the data stored in WXS.
ObjectGrid as a database buffer
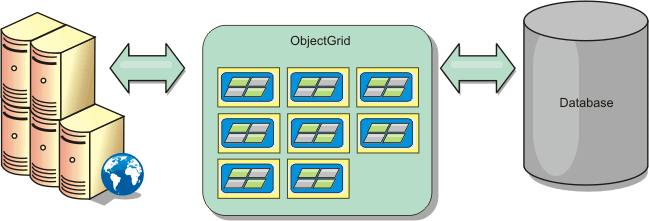
ObjectGrid as a side cache
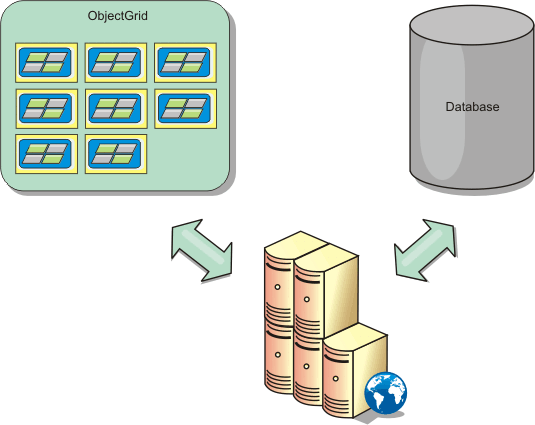
Sparse and complete cache
WXS can be used as a sparse cache or a complete cache. A sparse cache only keeps a subset of the total data, while a complete cache keeps all of the data. and can be populated lazily, as the data is needed. Sparse caches are normally accessed using keys (instead of indexes or queries) because the data is only partially available.
When a key is not present in a sparse cache, or the data is not available and a cache miss occurs, the next tier is invoked. The data is fetched, from a database for example, and is inserted into the data grid cache tier. If we are using a query or index, only the currently loaded values are accessed and the requests are not forwarded to the other tiers.
A complete cache contains all of the required data and can be accessed using non-key attributes with indexes or queries. A complete cache is preloaded with data from the database before the application tries to access the data. A complete cache can function as a database replacement after data is loaded. Because all of the data is available, queries and indexes can be used to find and aggregate data.
Side cache
With a side cache, WXS is used to temporarily store objects that would normally be retrieved from a back-end database. Applications check to see if the data grid contains the data. If the data is in the data grid, the data is returned to the caller. If the data does not exist, the data is retrieved from the back-end database. The data is then inserted into the data grid so that the next request can use the cached copy.
Side cache plug-ins for Hibernate and OpenJPA
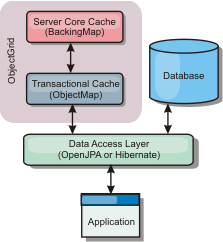
WXS can be used as a side-cache for OpenJPA and Hibernate by installing the bundled plug-ins. Because the cache is automatically replicated between all processes, when one client caches a value, all other clients can use the cached value.
In-line cache
In-line caching uses WXS as the primary means for interacting with the data. We can configure in-line caching for a database back end or as a side cache for a database. When used as an in-line cache, WXS interacts with the back end using a Loader plug-in. Applications can access the WXS APIs directly. Several different caching scenarios are supported in WXS to synchronize the data in the cache and the data in the back end.

In-line caching allows applications to access the WXS APIs directly. WXS supports several in-line caching scenarios...
- Read-through caching scenario
A read-through cache is a sparse cache that lazily loads data entries by key as they are requested. This is done without requiring the caller to know how the entries are populated. If the data cannot be found in the WXS cache, WXS will retrieve the missing data from the Loader plug-in, which loads the data from the back-end database and inserts the data into the cache. Subsequent requests for the same data key will be found in the cache until it is removed, invalidated or evicted.

- Write-through caching scenario
Every write to the cache synchronously writes to the database using the Loader. This method provides consistency with the back end, but decreases write performance since the database operation is synchronous. Since the cache and database are both updated, subsequent reads for the same data will be found in the cache, avoiding the database call. A write-through cache is often used in conjunction with a read-through cache.

- Write-behind caching scenario
Database synchronization can be improved by writing changes asynchronously. This is known as a write-behind or write-back cache. Changes that would normally be written synchronously to the loader are instead buffered in WXS and written to the database using a background thread. Write performance is significantly improved because the database operation is removed from the client transaction and the database writes can be compressed.
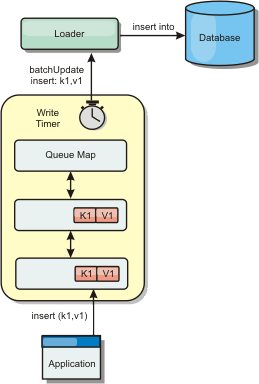
Write-behind caching
Use write-behind caching to reduce the overhead that occurs when updating a database we are using as a back end.
Write-behind caching asynchronously queues updates to the Loader plug-in. We can improve performance by disconnecting updates, inserts, and removes for a map, the overhead of updating the back-end database. The asynchronous update is performed after a time-based delay (for example, five minutes) or an entry-based delay (1000 entries).
The write-behind configuration on a BackingMap creates a thread between the loader and the map. The loader then delegates data requests through the thread according to the configuration settings in the BackingMap.setWriteBehind method. When a WXS transaction inserts, updates, or removes an entry from a map, a LogElement object is created for each of these records. These elements are sent to the write-behind loader and queued in a special ObjectMap called a queue map. Each backing map with the write-behind setting enabled has its own queue maps. A write-behind thread periodically removes the queued data from the queue maps and pushes them to the real back-end loader.
The write-behind loader only sends insert, update, and delete types of LogElement objects to the real loader. All other types of LogElement objects, for example, EVICT type, are ignored.
Write-behind support is an extension of the Loader plug-in, which you use to integrate WXS with the database.
Benefits
Enabling write-behind support has the following benefits:
| Back end failure isolation | Write-behind caching provides an isolation layer from back end failures. When the back-end database fails, updates are queued in the queue map. The applications can continue driving transactions to WXS. When the back end recovers, the data in the queue map is pushed to the back-end. |
| Reduced back end load | The write-behind loader merges the updates on a key basis so only one merged update per key exists in the queue map. This merge decreases the number of updates to the back-end database. |
| Improved transaction performance | Individual WXS transaction times are reduced because the transaction does not need to wait for the data to be synchronized with the back-end. |
Loaders
With a Loader plug-in, a data grid map can behave as a memory cache for data that is typically kept in a persistent store on either the same system or another system. Typically, a database or file system is used as the persistent store. A remote JVM can also be used as the source of data, allowing hub-based caches to be built using eXtreme Scale. A loader has the logic for reading and writing data to and from a persistent store.
Loaders are backing map plug-ins that are invoked when changes are made to the backing map or when the backing map is unable to satisfy a data request (a cache miss). The Loader is invoked when the cache is unable to satisfy a request for a key, providing read-through capability and lazy-population of the cache. A loader also allows updates to the database when cache values change. All changes within a transaction are grouped together to allow the number of database interactions to be minimized.
A TransactionCallback plug-in is used in conjunction with the loader to trigger the demarcation of the backend transaction. Using this plug-in is important when multiple maps are included in a single transaction or when transaction data is flushed to the cache without committing.
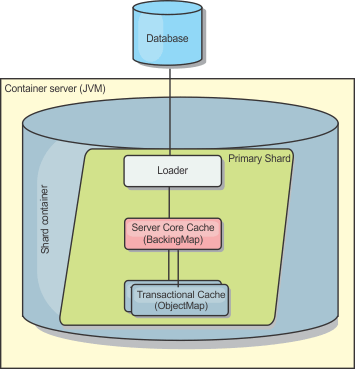
The loader can also use overqualified updates to avoid keeping database locks. By storing a version attribute in the cache value, the loader can see the before and after image of the value as it is updated in the cache. This value can then be used when updating the database or back end to verify that the data has not been updated.
A Loader can also be configured to preload the data grid when it is started. When partitioned, a Loader instance is associated with each partition. If the "Company" Map has ten partitions, there are ten Loader instances, one per primary partition. When the primary shard for the Map is activated, the preloadMap method for the loader is invoked synchronously or asynchronously which allows loading the map partition with data from the back-end to occur automatically. When invoked synchronously, all client transactions are blocked, preventing inconsistent access to the data grid. Alternatively, a client preloader can be used to load the entire data grid.
Two built-in loaders can simplify integration with relational database back ends.
The JPA loaders utilize the Object-Relational Mapping (ORM) capabilities of both the OpenJPA and Hibernate implementations of the JPA specification.
If we are using loaders in a multiple data center configuration, you must consider how revision data and cache consistency is maintained between the data grids.
Loader configuration
To add a Loader into the BackingMap configuration, we can use either...
- programmatic configuration
- XML configuration
A loader has the following relationship with a backing map.
- A backing map can have only one loader.
- A client backing map (near cache) cannot have a loader.
- A loader definition can be applied to multiple backing maps, but each backing map has its own loader instance.
Data pre-loading and warm-up
We can prepare data grids by pre-loading them with data. Complete cache data grids, must hold all data before any clients can connect to it. Sparse cache data grids can be warmed up so that clients can have immediate access to the data.
Two approaches exist for pre-loading data into the data grid:
- Loader plug-in
Synchronizes a single primary partition shard with the database. The preloadMap method of the loader plug-in is invoked automatically when a shard is activated. For example, if you have 100 partitions, 100 loader instances exist, each loading the data for its partition. When run synchronously, all clients are blocked until the preload has completed.
- Client loader
Use multiple clients to load the grid with data. Effective when the partition scheme is not stored in the database. We can invoke client loaders manually or automatically when the data grid starts. Client loaders can optionally use the StateManager to set the state of the data grid to pre-load mode, so that clients are not able to access the grid while it is pre-loading the data. WXS includes a JPA-based loader that automatically loads the data grid with either OpenJPA or Hibernate JPA providers.
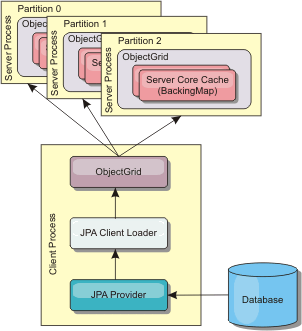
Database synchronization techniques
When WXS is used as a cache, applications must be written to tolerate stale data if the database can be updated independently from a WXS transaction. To serve as a synchronized in-memory database processing space, eXtreme Scale provides several ways of keeping the cache updated.
Periodic refresh
The cache can be automatically invalidated or updated periodically using the JPA time-based database updater.The updater periodically queries the database using a JPA provider for any updates or inserts that have occurred since the previous update. Any changes identified are automatically invalidated or updated when used with a sparse cache . If used with a complete cache, the entries can be discovered and inserted into the cache. Entries are never removed from the cache.
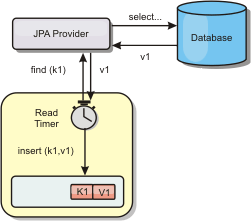
Eviction
Sparse caches can utilize eviction policies to automatically remove data from the cache without affecting the database. There are three built-in policies included in eXtreme Scale: time-to-live, least-recently-used, and least-frequently-used. All three policies can optionally evict data more aggressively as memory becomes constrained by enabling the memory-based eviction option.
Event-based invalidation
Sparse and complete caches can be invalidated or updated using an event generator such as Java Message Service (JMS). Invalidation using JMS can be manually tied to any process that updates the back-end using a database trigger. A JMS ObjectGridEventListener plug-in is provided in eXtreme Scale that can notify clients when the server cache has any changes. This can decrease the amount of time the client can see stale data.
Programmatic invalidation
The eXtreme Scale APIs allow manual interaction of the near and server cache using...
- Session.beginNoWriteThrough()
- ObjectMap.invalidate()
- EntityManager.invalidate()
If a client or server process no longer needs a portion of the data, the invalidate methods can be used to remove data from the near or server cache. The beginNoWriteThrough method applies any ObjectMap or EntityManager operation to the local cache without calling the loader. If invoked from a client, the operation applies only to the near cache (the remote loader is not invoked). If invoked on the server, the operation applies only to the server core cache without invoking the loader.
Data invalidation
To remove stale cache data, we can use invalidation mechanisms.
Administrative invalidation
Use the web console or the xscmd utility to invalidate data based on the key. We can filter the cache data with a regular expression and then invalidate the data based on the regular expression.
Event-based invalidation
Sparse and complete caches can be invalidated or updated using an event generator such as Java Message Service (JMS). Invalidation using JMS can be manually tied to any process that updates the back-end using a database trigger. A JMS ObjectGridEventListener plug-in is provided in eXtreme Scale that can notify clients when the server cache changes. This type of notification decreases the amount of time the client can see stale data.
Event-based invalidation normally consists of the following three components.
| Event queue | Store the data change events. It could be a JMS queue, a database, an in-memory FIFO queue, or any kind of manifest as long as it can manage the data change events. |
| Event publisher | Publish the data change events to the event queue. Usually an application you create or a WXS plug-in implementation. The event publisher knows when the data is changed or it changes the data itself. When a transaction commits, events are generated for the changed data and the event publisher publishes these events to the event queue. |
| Event consumer | Consume data change events. Usually an application to ensure the target grid data is updated with the latest change from other grids. This event consumer interacts with the event queue to get the latest data change and applies the data changes in the target grid. The event consumers can use eXtreme Scale APIs to invalidate stale data or update the grid with the latest data. |
For example, JMSObjectGridEventListener has an option for a client-server model, in which the event queue is a designated JMS destination. All server processes are event publishers. When a transaction commits, the server gets the data changes and publishes them to the designated JMS destination. All the client processes are event consumers. They receive the data changes from the designated JMS destination and apply the changes to the client's near cache .
Programmatic invalidation
The WXS APIs allow manual interaction of the near and server cache using...
- Session.beginNoWriteThrough()
- ObjectMap.invalidate()
- EntityManager.invalidate()
If a client or server process no longer needs a portion of the data, the invalidate methods can be used to remove data from the near or server cache. The beginNoWriteThrough method applies any ObjectMap or EntityManager operation to the local cache without calling the loader. If invoked from a client, the operation applies only to the near cache (the remote loader is not invoked). If invoked on the server, the operation applies only to the server core cache without invoking the loader.
Use programmatic invalidation with other techniques to determine when to invalidate the data. For example, this invalidation method uses event-based invalidation mechanisms to receive the data change events, and then uses APIs to invalidate the stale data.
Near cache invalidation
If we are using a near cache, we can configure an asynchronous invalidation that is triggered each time an update, delete, invalidation operation is run against the data grid. Because the operation is asynchronous, you might still see stale data in the data grid.
To enable near cache invalidation, set the nearCacheInvalidationEnabled attribute on the backing map in the ObjectGrid descriptor XML file.
Indexing
Index types and configuration
The indexing feature is represented by the MapIndexPlugin plug-in or Index for short. The Index is a BackingMap plug-in. A BackingMap can have multiple Index plug-ins configured, as long as each one follows the Index configuration rules.
Use the indexing feature to build one or more indexes on a BackingMap. An index is built from an attribute or a list of attributes of an object in the BackingMap. This feature provides a way for applications to find certain objects more quickly. With the indexing feature, applications can find objects with a specific value or within a range of values of indexed attributes.
Two types of indexing are possible: static and dynamic.
With static indexing, configure the index plug-in on the BackingMap before initializing the ObjectGrid instance. We can do this configuration with XML or programmatic configuration of the BackingMap. Static indexing starts building an index during ObjectGrid initialization. The index is always synchronized with the BackingMap and ready for use. After the static indexing process starts, the maintenance of the index is part of the WXS transaction management process. When transactions commit changes, these changes also update the static index, and index changes are rolled back if the transaction is rolled back.
With dynamic indexing, we can create an index on a BackingMap before or after the initialization of the containing ObjectGrid instance. Applications have life cycle control over the dynamic indexing process so that we can remove a dynamic index when it is no longer needed. When an application creates a dynamic index, the index might not be ready for immediate use because of the time it takes to complete the index building process. Because the amount of time depends upon the amount of data indexed, the DynamicIndexCallback interface is provided for applications that want to receive notifications when certain indexing events occur. These events include ready, error, and destroy. Applications can implement this callback interface and register with the dynamic indexing process.
If a BackingMap has an index plug-in configured, we can obtain the application index proxy object from the corresponding ObjectMap. Calling the getIndex method on the ObjectMap and passing in the name of the index plug-in returns the index proxy object. Cast the index proxy object to an appropriate application index interface, such as MapIndex, MapRangeIndex, MapGlobalIndex, or a customized index interface. After obtaining the index proxy object, we can use methods defined in the application index interface to find cached objects.
Indexing setup summary...
- Add either static or dynamic index plug-ins into the BackingMap.
- Obtain an application index proxy object by issuing the getIndex method of the ObjectMap.
- Cast the index proxy object to an appropriate application index interface, such as MapIndex, MapRangeIndex, or a customized index interface.
- Use methods that are defined in application index interface to find cached objects.
The HashIndex class is the built-in index plug-in implementation that can support the following built-in application index interfaces:
- MapIndex
- MapRangeIndex
- MapGlobalIndex
You also can create your own indexes. We can add HashIndex as either a static or dynamic index into the BackingMap, obtain either the MapIndex, MapRangeIndex, or MapGlobalIndex index proxy object, and use the index proxy object to find cached objects.
Global index
Global index is an extension of the built-in HashIndex class that runs on shards in distributed, partitioned data grid environments. It tracks the location of indexed attributes and provides efficient ways to find partitions, keys, values, or entries using attributes in large, partitioned data grid environments.
If global index is enabled in the built-in HashIndex plug-in, then applications can cast an index proxy object MapGlobalIndex type, and use it to find data.
Default index
To iterate through the keys in a local map, we can use the default index . This index does not require any configuration, but it must be used against the shard, using an agent or an ObjectGrid instance retrieved from the method...
-
ShardEvents.shardActivated(ObjectGrid shard)
Indexing data quality consideration
The results of index query methods only represent a snapshot of data at a point of time. No locks against data entries are obtained after the results return to the application. Data updates may occur on a returned data set. For example, the application obtains the key of a cached object by running the findAll method of MapIndex. This returned key object is associated with a data entry in the cache. The application should be able to run the get method on ObjectMap to find an object by providing the key object. If another transaction removes the data object from the cache just before the get method is called, the returned result will be null.
Indexing performance considerations
If indexing is not used properly, application performance may suffer. Consider the following factors...
- The number of concurrent write transactions
Index processing can occur every time a transaction writes data into a BackingMap. Performance degrades if many transactions are writing data into the map concurrently when an application attempts index query operations.
- The size of the result set that is returned by a query operation
As the size of the resultset increases, the query performance declines. Performance tends to degrade when the size of the result set is 15% or more of the BackingMap.
- The number of indexes built over the same BackingMap
Each index consumes system resources. As the number of the indexes built over the BackingMap increases, performance decreases.
The indexing function can improve BackingMap performance drastically. Ideal cases are when the BackingMap has mostly read operations, the query result set is of a small percentage of the BackingMap entries, and only few indexes are built over the BackingMap.
JPA Loaders
The JPA specification maps Java objects to relational databases.
JPA contains a full object-relational mapping (ORM) specification using Java language metadata annotations, XML descriptors, or both to define the mapping between Java objects and a relational database. A number of open-source and commercial implementations are available.
Use a JPA loader plug-in implementation with WXS to interact with any database supported by your chosen loader. To use JPA, you must have...
- Supported JPA provider, such as OpenJPA or Hibernate
- JAR files
- META-INF/persistence.xml file in the class path
The JPALoader plug-in...
-
com.ibm.websphere.objectgrid.jpa.JPALoader
...and the JPAEntityLoader plug-in...
-
com.ibm.websphere.objectgrid.jpa.JPAEntityLoader plug
...synchronize the ObjectGrid maps with a database. A JPA implementation, such as Hibernate or OpenJPA, is required. The database can be any back end that is supported by the chosen JPA provider.
- Use JPALoader plug-in to store data using the ObjectMap API
- Use JPAEntityLoader plug-in to store data using the EntityManager API
JPA loader architecture
The JPA Loader is used for eXtreme Scale maps that store plain old Java objects (POJO).

When an ObjectMap.get(Object key) method is called, the WXS run time first checks whether the entry is contained in the ObjectMap layer. If not, the run time delegates the request to the JPA Loader. Upon request of loading the key, to find the data from the JPA layer, the JPALoader calls the method...
-
JPA EntityManager.find(Object key)
If the data is contained in the JPA entity manager, it is returned; otherwise, the JPA provider interacts with the database to get the value.
When an update to ObjectMap occurs, for example, using the method...
-
ObjectMap.update(Object key, Object value)
...the WXS run time creates a LogElement for this update and sends it to the JPALoader.
To update the value to the database the JPALoader calls the method...
-
JPA EntityManager.merge(Object value)
For the JPAEntityLoader, the same four layers are involved. However, because the JPAEntityLoader plug-in is used for maps that store WXS entities, relations among entities could complicate the usage scenario. An WXS entity is distinguished from JPA entity.
Methods
Loaders provide three main methods:
| get | Return a list of values corresponding to the list of keys passed in by retrieving the data using JPA. The method uses JPA to find the entities in the database. For the JPALoader plug-in, the returned list contains a list of JPA entities directly from the find operation. For the JPAEntityLoader plug-in, the returned list contains WXS entity value tuples that are converted from the JPA entities. |
| batchUpdate | Write the data from ObjectGrid maps to the database. Depending on different operation types (insert, update, or delete), the loader uses the JPA persist, merge, and remove operations to update the data to the database. For the JPALoader, the objects in the map are directly used as JPA entities. For the JPAEntityLoader, the entity tuples in the map are converted into objects which are used as JPA entities. |
| preloadMap | Preload the map using ClientLoader.load. For partitioned maps, the preloadMap method is only called in one partition. The partition is specified the preloadPartition property of the JPALoader or JPAEntityLoader class. If the preloadPartition value is set to less than zero, or greater than (total_number_of_partitions - 1), preload is disabled. |
Both JPALoader and JPAEntityLoader plug-ins work with the JPATxCallback class to coordinate the WXS transactions and JPA transactions. JPATxCallback must be configured in the ObjectGrid instance to use these two loaders.
Serialization overview
Data is always expressed, but not necessarily stored, as Java objects in the data grid. WXS uses multiple Java processes to serialize the data, by converting the Java object instances to bytes and back to objects again, as needed, to move the data between client and server processes.
Data is serialized, meaning it is converted into a data stream for transmission over a network, in the following situations:
- When clients communicate with servers, and those servers send information back to the client
- When servers replicate data from one server to another
Alternatively, you might decide to forgo the serialization process through WXS and store raw data as byte arrays, which are much cheaper to store in memory since the JVM has fewer objects to search for during garbage collection, and they can be deserialized only when needed. Only use byte arrays if you do not need to access the objects using queries or indexes. Since the data is stored as bytes, WXS has no metadata for describing attributes to query.
To serialize data in WXS, we can use...
- Java serialization
- ObjectTransformer plug-in
- DataSerializer plug-in
To optimize serialization with any of these options, we can use the COPY_TO_BYTES mode to improve performance up to 70 percent because the data is serialized when transactions commit, which means that serialization happens only once. The serialized data is sent unchanged from the client to the server or from the server to replicated server. By using the COPY_TO_BYTES mode, we can reduce the memory footprint that a large graph of objects can consume.
Serialization using Java
Java serialization refers to either...
- Default serialization
To use default serialization, implement the java.io.Serializable interface, which includes the API that converts objects into bytes, which are later deserialized. Use the java.io.ObjectOutputStream class to persist the object. Then, call the ObjectOutputStream.writeObject() method to initiate serialization and flatten the Java object.
- Custom serialization
Some cases exist where objects must be modified to use custom serialization, such as implementing the interface java.io.Externalizable or by implementing the methods writeObject and readObject for classes implementing the interface java.io.Serializable interface. Custom serialization techniques should be employed when the objects are serialized using mechanisms other than the ObjectGrid API or EntityManager API methods. For example, when objects or entities are stored as instance data in a DataGrid API agent or the agent returns objects or entities, those objects are not transformed using an ObjectTransformer. The agent, will however, automatically use the ObjectTransformer when using EntityMixin interface.
ObjectTransformer plug-in
With the ObjectTransformer plug-in, we can serialize, deserialize, and copy objects in the cache for increased performance.
The ObjectTransformer interface has been replaced by the DataSerializer plug-ins, which we can use to efficiently store arbitrary data in WXS so that existing product APIs can efficiently interact with your data.
If you see performance issues with processor usage, add an ObjectTransformer plug-in to each map. If you do not provide an ObjectTransformer plug-in, up to 60-70 percent of the total processor time is spent serializing and copying entries.
With the ObjectTransformer plug-in, the applications can provide custom methods for the following operations:
- Serialize or deserialize the key for an entry
- Serialize or deserialize the value for an entry
- Copy a key or value for an entry
If no ObjectTransformer plug-in is provided, you must be able to serialize the keys and values because the ObjectGrid uses a serialize and deserialize sequence to copy the objects. This method is expensive, so use an ObjectTransformer plug-in when performance is critical. The copying occurs when an application looks up an object in a transaction for the first time. We can avoid this copying by setting the copy mode of the Map to NO_COPY or reduce the copying by setting the copy mode to COPY_ON_READ. Optimize the copy operation when needed by the application by providing a custom copy method on this plug-in. Such a plug-in can reduce the copy overhead from 65.70 percent to 2/3 percent of total processor time.
The default copyKey and copyValue method implementations first attempt to use the clone method, if the method is provided. If no clone method implementation is provided, the implementation defaults to serialization.
Object serialization is also used directly when the WXS is running in distributed mode. The LogSequence uses the ObjectTransformer plug-in to help serialize keys and values before transmitting the changes to peers in the ObjectGrid. You must take care when providing a custom serialization method instead of using the built-in Java developer kit serialization. Object versioning is a complex issue and you might encounter problems with version compatibility if you do not ensure that your custom methods are designed for versioning.
The following list describes how the WXS tries to serialize both keys and values:
- If a custom ObjectTransformer plug-in is written and plugged in, WXS calls methods in the ObjectTransformer interface to serialize keys and values and get copies of object keys and values.
- If a custom ObjectTransformer plug-in is not used, WXS serializes and deserializes values according to the default. If the default plug-in is used, each object is implemented as externalizable or is implemented as serializable.
- If the object supports the Externalizable interface, the writeExternal method is called. Objects that are implemented as externalizable lead to better performance.
- If the object does not support the Externalizable interface and does implement the Serializable interface, the object is saved using the ObjectOutputStream method.
Use the ObjectTransformer interface
An ObjectTransformer object must implement the ObjectTransformer interface and follow the common ObjectGrid plug-in conventions.
Two approaches, programmatic configuration and XML configuration, are used to add an ObjectTransformer object into the BackingMap configuration as follows.
Programmatically plug in an ObjectTransformer object
The following code snippet creates the custom ObjectTransformer object and adds it to a BackingMap:
ObjectGridManager objectGridManager = ObjectGridManagerFactory.getObjectGridManager();
ObjectGrid myGrid = objectGridManager.createObjectGrid("myGrid", false);
BackingMap backingMap = myGrid.getMap("myMap");
MyObjectTransformer myObjectTransformer = new MyObjectTransformer();
backingMap.setObjectTransformer(myObjectTransformer);
XML configuration approach to plug in an ObjectTransformer
Assume that the class name of the ObjectTransformer implementation is the com.company.org.MyObjectTransformer class. This class implements the ObjectTransformer interface. An ObjectTransformer implementation can be configured using the following XML:
<?xml version="1.0" encoding="UTF-8"?> <objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://ibm.com/ws/objectgrid/config ../objectGrid.xsd"
xmlns="http://ibm.com/ws/objectgrid/config">
<objectGrid name="myGrid">
<backingMap name="myMap" pluginCollectionRef="myMap" />
</objectGrid>
</objectGrids>
<backingMapPluginCollection id="myMap">
<bean id="ObjectTransformer" className="com.company.org.MyObjectTransformer" />
</backingMapPluginCollection>
</backingMapPluginCollections> </objectGridConfig>
ObjectTransformer usage scenarios
We can use the ObjectTransformer plug-in in the following situations:
- Non-serializable object
- Serializable object but improve serialization performance
- Key or value copy
In the following example, ObjectGrid is used to store the Stock class:
/**
* Stock object for ObjectGrid demo
*/
public class Stock implements Cloneable
{
String ticket;
double price;
String company;
String description;
int serialNumber;
long lastTransactionTime;
/**
* @return Return the description.
*/
public String getDescription()
{
return description;
}
/**
* @param description The description to set.
*/
public void setDescription(String description)
{
this.description = description;
}
/**
* @return Return the lastTransactionTime.
*/
public long getLastTransactionTime()
{
return lastTransactionTime;
}
/**
* @param lastTransactionTime The lastTransactionTime to set.
*/
public void setLastTransactionTime(long lastTransactionTime)
{
this.lastTransactionTime = lastTransactionTime;
}
/**
* @return Return the price.
*/
public double getPrice()
{
return price;
}
/**
* @param price The price to set.
*/
public void setPrice(double price)
{
this.price = price;
}
/**
* @return Return the serialNumber.
*/
public int getSerialNumber()
{
return serialNumber;
}
/**
* @param serialNumber The serialNumber to set.
*/
public void setSerialNumber(int serialNumber)
{
this.serialNumber = serialNumber;
}
/**
* @return Return the ticket.
*/
public String getTicket()
{
return ticket;
}
/**
* @param ticket The ticket to set.
*/
public void setTicket(String ticket)
{
this.ticket = ticket;
}
/**
* @return Return the company.
*/
public String getCompany()
{
return company;
}
/**
* @param company The company to set.
*/
public void setCompany(String company)
{
this.company = company;
}
//clone
public Object clone() throws CloneNotSupportedException
{
return super.clone();
}
}
We can write a custom object transformer class for the Stock class:
/**
* Custom implementation of ObjectGrid ObjectTransformer for stock object
*
*/
public class MyStockObjectTransformer implements ObjectTransformer
{
/* (non.Javadoc)
* @see
* com.ibm.websphere.objectgrid.plugins.ObjectTransformer#serializeKey
* (java.lang.Object, * java.io.ObjectOutputStream)
*/
public void serializeKey(Object key, ObjectOutputStream stream) throws IOException
{
String ticket= (String) key;
stream.writeUTF(ticket);}
/* (non.Javadoc)
* @see com.ibm.websphere.objectgrid.plugins.
ObjectTransformer#serializeValue(java.lang.Object, java.io.ObjectOutputStream)
*/
public void serializeValue(Object value, ObjectOutputStream stream) throws IOException
{
Stock stock= (Stock) value;
stream.writeUTF(stock.getTicket());
stream.writeUTF(stock.getCompany());
stream.writeUTF(stock.getDescription());
stream.writeDouble(stock.getPrice());
stream.writeLong(stock.getLastTransactionTime());
stream.writeInt(stock.getSerialNumber());}
/* (non.Javadoc)
* @see com.ibm.websphere.objectgrid.plugins.
ObjectTransformer#inflateKey(java.io.ObjectInputStream)
*/
public Object inflateKey(ObjectInputStream stream) throws IOException, ClassNotFoundException
{
String ticket=stream.readUTF();
return ticket;}
/* (non.Javadoc)
* @see com.ibm.websphere.objectgrid.plugins.
ObjectTransformer#inflateValue(java.io.ObjectInputStream)
*/
public Object inflateValue(ObjectInputStream stream) throws IOException, ClassNotFoundException
{
Stock stock=new Stock();
stock.setTicket(stream.readUTF());
stock.setCompany(stream.readUTF());
stock.setDescription(stream.readUTF());
stock.setPrice(stream.readDouble());
stock.setLastTransactionTime(stream.readLong());
stock.setSerialNumber(stream.readInt());
return stock;}
/* (non.Javadoc)
* @see com.ibm.websphere.objectgrid.plugins.
ObjectTransformer#copyValue(java.lang.Object)
*/
public Object copyValue(Object value)
{
Stock stock = (Stock) value;
try
{
return stock.clone();
}
catch (CloneNotSupportedException e)
{
// display exception message
}
}
/* (non.Javadoc)
* @see com.ibm.websphere.objectgrid.plugins.
ObjectTransformer#copyKey(java.lang.Object)
*/
public Object copyKey(Object key)
{
String ticket=(String) key;
String ticketCopy= new String (ticket);
return ticketCopy;
}
}
Then, plug in this custom MyStockObjectTransformer class into the BackingMap:
ObjectGridManager ogf=ObjectGridManagerFactory.getObjectGridManager();
ObjectGrid og = ogf.getObjectGrid("NYSE");
BackingMap bm = og.defineMap("NYSEStocks");
MyStockObjectTransformer ot = new MyStockObjectTransformer();
bm.setObjectTransformer(ot);
Serialization using the DataSerializer plug-ins
Use the DataSerializer plug-ins to efficiently store arbitrary data in WebSphere eXtreme Scale so that existing product APIs can efficiently interact with your data.
Serialization methods such as Java serialization and the ObjectTransformer plug-in allow data to be marshalled over the network. In addition, when you use these serialization options with the COPY_TO_BYTES copy mode, moving data between clients and servers becomes less expensive and performance is improved. However, these options do not solve the following issues that can exist:
- Keys are not stored in bytes; they are still Java objects.
- Server-side code must still inflate the object; for example, query and index still use reflection and must inflate the object. Additionally, agents, listeners, and plug-ins still need the object form.
- Classes still need to be in the server classpath.
- Data is still in Java serialization form (ObjectOutputStream).
The DataSerializer plug-ins introduce an efficient way of solving these problems. Specifically, the DataSerializer plug-in gives you a way to describe your serialization format, or byte array, to WXS so that the product can interrogate the byte array without requiring a specific object format. The public DataSerializer plug-in classes and interfaces are in the package...
-
com.ibm.websphere.objectgrid.plugins.io
Entity Java objects are not stored directly into the BackingMaps when you use the EntityManager API. The EntityManager API converts the entity object to Tuple objects. Entity maps are automatically associated with a highly optimized ObjectTransformer. Whenever the ObjectMap API or EntityManager API is used to interact with entity maps, the ObjectTransformer entity is invoked. Therefore, when you use entities, no work is required for serialization because the product automatically completes this process for you.
See also Oracle Java Serialization API
Scalability overview
WXS is scalable through the use of partitioned data, and can scale to thousands of containers if required because each container is independent from other containers.
WXS divides data sets into distinct partitions that can be moved between processes or even between physical servers at run time. We can, for example, start with a deployment of four servers and then expand to a deployment with 10 servers as the demands on the cache grow. Just as we can add more physical servers and processing units for vertical scalability, we can extend the elastic scaling capability horizontally with partitioning. Horizontal scaling is a major advantage to using WXS over an in-memory database. In-memory databases can only scale vertically.
With WXS, we can also use a set of APIs to gain transactional access this partitioned and distributed data. The choices you make for interacting with the cache are as significant as the functions to manage the cache for availability from a performance perspective.
Scalability is not available when containers communicate with one another. The availability management, or core grouping, protocol is an O(N2) heartbeat and view maintenance algorithm, but is mitigated by keeping the number of core group members under 20. Only peer to peer replication between shards exists.
Distributed clients
The WXS client protocol supports very large numbers of clients. The partitioning strategy offers assistance by assuming that all clients are not always interested in all partitions because connections can be spread across multiple containers. Clients are connected directly to the partitions so latency is limited to one transferred connection.
Data grids, partitions, and shards
A data grid is divided into partitions. A partition holds an exclusive subset of the data. A partition contains one or more shards: a primary shard and replica shards. Replica shards are not necessary in a partition, but we can use replica shards to provide high availability. Whether the deployment is an independent in-memory data grid or an in-memory database processing space, data access in WXS relies heavily on shards.
The data for a partition is stored in a set of shards at run time. This set of shards includes a primary shared and possibly one or more replica shards. A shard is the smallest unit that WXS can add or remove from a JVM.
Two placement strategies exist: fixed partition placement (default) and per container placement. The following discussion focuses on the usage of the fixed partition placement strategy.
Total number of shards
If your environment includes 10 partitions that hold 1 million objects with no replicas, then 10 shards would exist that each store 100,000 objects. If you add a replica to this scenario, then an extra shard exists in each partition. In this case, 20 shards exist: 10 primary shards and 10 replica shards. Each one of these shards store 100,000 objects. Each partition consists of a primary shard and one or more (N) replica shards. Determining the optimal shard count is critical. If you configure few shards, data is not distributed evenly among the shards, resulting in out of memory errors and processor overloading issues. You must have at least 10 shards for each JVM as you scale. When initially deploying the data grid, you would potentially use many partitions.
Number of shards per JVM scenarios
Scenario: Small number of shards for each JVM
Data is added and removed from a JVM using shard units. Shards are never split into pieces. If 10 GB of data existed, and 20 shards exist to hold this data, then each shard holds 500 MB of data on average. If nine JVMs host the data grid, then on average each JVM has two shards. Because 20 is not evenly divisible by 9, a few JVMs have three shards, in the following distribution:
- Seven JVMs with two shards
- Two JVMs with three shards
Because each shard holds 500 MB of data, the distribution of data is unequal. The seven JVMs with two shards each host 1 GB of data. The two JVMs with three shards have 50% more data, or 1.5 GB, which is a much larger memory burden. Because the two JVMs are hosting three shards, they also receive 50% more requests for their data. As a result, having few shards for each JVM causes imbalance. To increase the performance, you increase the number of shards for each JVM.
Scenario: Increased number of shards per JVM
In this scenario, consider a much larger number of shards. In this scenario, there are 101 shards with nine JVMs hosting 10 GB of data. In this case, each shard holds 99 MB of data. The JVMs have the following distribution of shards:
- Seven JVMs with 11 shards
- Two JVMs with 12 shards
The two JVMs with 12 shards now have just 99 MB more data than the other shards, which is a 9% difference. This scenario is much more evenly distributed than the 50% difference in the scenario with few shards. From a processor use perspective, only 9% more work exists for the two JVMs with the 12 shards compared to the seven JVMs that have 11 shards. By increasing the number of shards in each JVM, the data and processor use is distributed in a fair and even way.
When creating your system, use 10 shards for each JVM in its maximally sized scenario, or when the system is running its maximum number of JVMs in your planning horizon.
Additional placement factors
The number of partitions, the placement strategy, and number and type of replicas are set in the deployment policy. The number of shards placed depend on the deployment policy that you define. The minSyncReplicas, developmentMode, maxSyncReplicas, and maxAsyncReplicas attributes affect where partitions and replicas are placed.
The following factors affect when shards can be placed:
- xscmd -c suspendBalancing
xscmd -c resumeBalancing - Server properties file
placementDeferralInterval defines number of milliseconds before shards are placed on the container servers.
- Deployment policy
numInitialContainers attribute
If the maximum number of replicas are not placed during the initial startup, additional replicas might be placed if you start additional servers later. When planning the number of shards per JVM, the maximum number of primary and replica shards is dependent on having enough JVMs started to support the configured maximum number of replicas. A replica is never placed in the same process as its primary. If a process is lost, both the primary and the replica are lost. When the developmentMode attribute is set to false, the primary and replicas are not placed on the same physical server.
Partitioning
Use partitioning to scale out an application. We can define the number of partitions in the deployment policy.
Partitioning is not like Redundant Array of Independent Disks (RAID) striping, which slices each instance across all stripes. Each partition hosts the complete data for individual entries. Partitioning is a very effective means for scaling, but is not applicable to all applications. Applications that require transactional guarantees across large sets of data do not scale and cannot be partitioned effectively. WXS does not currently support two-phase commit across partitions.
The number of partitions defined in the deployment policy affects the number of container servers to which an application can scale. Each partition is made up of a primary shard and the configured number of replica shards.
For a data grid with four containers, an unreasonable configuration is 2000 partitions, each with two shards, running on four containers. This configuration results in 4000 shards placed on four containers or 1000 shards per container.
A better configuration would be under 5 partitions (10 shards) for each expected container. This configuration still gives the possibility of allowing for elastic scaling that is ten times the initial configuration while keeping a reasonable number of shards per container.
Consider this scaling example: 60 containers on 30 physical servers. With four shards per container, total shards would be 240. If partitions contain a primary shard and one replica shard, you would want 120 partitions.
ObjectMap and partitioning
With the default FIXED_PARTITION placement strategy, maps are split across partitions and keys hash to different partitions. The client does not need to know to which partition the keys belong. If a mapSet has multiple maps, the maps should be committed in separate transactions.
Entities and partitioning
Entity manager entities have an optimization that helps clients working with entities on a server. The entity schema on the server for the map set can specify a single root entity. The client accesses all entities through the root entity. The entity manager can then find related entities from that root in the same partition without requiring the related maps to have a common key. The root entity establishes affinity with a single partition. This partition is used for all entity fetches within the transaction after affinity is established. This affinity can save memory because the related maps do not require a common key. The root entity must be specified with a modified entity annotation as shown in the following example:- @Entity(schemaRoot=true)
Use the entity to find the root of the object graph. The object graph defines the relationships between one or more entities. Each linked entity must resolve to the same partition. All child entities are assumed to be in the same partition as the root. The child entities in the object graph are only accessible from a client from the root entity. Root entities are always required in partitioned environments when using a WXS client to communicate to the server. Only one root entity type can be defined per client. Root entities are not required when using Extreme Transaction Processing (XTP) style ObjectGrids, because all communication to the partition is accomplished through direct, local access and not through the client and server mechanism.
Placement and partitions
You have two placement strategies available for WXS: fixed partition and per-container.
Fixed partition placement
The default placement strategy is fixed-partition placement, enabled with the FIXED_PARTITION setting in the deployment policy XML file. The number of primary shards placed across the available containers is equal to the number of partitions configured (numberOfPartitions).
If you have configured replicas, the minimum total number of shards placed...
- ((1 primary shard + minimum synchronous shards) * partitions defined)
The maximum total number of shards placed...
- ((1 primary shard + maximum synchronous shards + maximum asynchronous shards) * partitions)
Your WXS deployment spreads these shards over the available containers. The keys of each map are hashed into assigned partitions based on the total partitions you have defined. They keys hash to the same partition even if the partition moves because of failover or server changes.
If the numberPartitions value is 6 and the minSync value is 1 for MapSet1, the total shards for that map set is 12 because each of the 6 partitions requires a synchronous replica. If three containers are started, WXS places four shards per container for MapSet1.
Per-container placement
The alternate placement strategy is per-container placement, which is enabled with the PER_CONTAINER setting for the placementStrategy attribute in the map set element in the deployment XML file. With this strategy, the number of primary shards placed on each new container is equal to the number of partitions, P, configured. The WXS deployment environment places P replicas of each partition for each remaining container. The numInitialContainers setting is ignored when we are using per-container placement. The partitions get larger as the containers grow. The keys for maps are not fixed to a certain partition in this strategy. The client routes to a partition and uses a random primary. If a client wants to reconnect to the same session that it used to find a key again, it must use a session handle.
For failover or stopped servers, the WXS environment moves the primary shards in the per-container placement strategy if they still contain data. If the shards are empty, they are discarded. In the per-container strategy, old primary shards are not kept because new primary shards are placed for every container.
WXS allows per-container placement as an alternative to what could be termed the "typical" placement strategy, a fixed-partition approach with the key of a Map hashed to one of those partitions. In a per-container case (which you set with PER_CONTAINER), the deployment places the partitions on the set of online container servers and automatically scales them out or in as containers are added or removed from the server data grid. A data grid with the fixed-partition approach works well for key-based grids, where the application uses a key object to locate data in the grid. The following discusses the alternative.
Example of a per-container data grid
PER_CONTAINER data grids are different. You specify that the data grid uses the PER_CONTAINER placement strategy with the placementStrategy attribute in the deployment XML file. Instead of configuring how many partitions total we want in the data grid, you specify how many partitions we want per container that you start.
For example, if you set five partitions per container, five new anonymous partition primaries are created when you start that container server, and the necessary replicas are created on the other deployed container servers.
The following is a potential sequence in a per-container environment as the data grid grows.
- Start container C0 hosting 5 primaries (P0 - P4).
- C0 hosts: P0, P1, P2, P3, P4.
- Start container C1 hosting 5 more primaries (P5 - P9). Replicas are balanced on the containers.
- C0 hosts: P0, P1, P2, P3, P4, R5, R6, R7, R8, R9.
- C1 hosts: P5, P6, P7, P8, P9, R0, R1, R2, R3, R4.
- Start container C2 hosting 5 more primaries (P10 - P14). Replicas are balanced further.
- C0 hosts: P0, P1, P2, P3, P4, R7, R8, R9, R10, R11, R12.
- C1 hosts: P5, P6, P7, P8, P9, R2, R3, R4, R13, R14.
- C2 hosts: P10, P11, P12, P13, P14, R5, R6, R0, R1.
The pattern continues as more containers are started, creating five new primary partitions each time and rebalancing replicas on the available containers in the data grid.
WXS does not move primary shards when using the PER_CONTAINER strategy, only replicas.
Remember that the partition numbers are arbitrary and have nothing to do with keys, so we cannot use key-based routing. If a container stops then the partition IDs created for that container are no longer used, so there is a gap in the partition IDs. In the example, there would no longer be partitions P5 - P9 if the container C1 failed, leaving only P0 - P4 and P10 - P14, so key-based hashing is impossible.
Use numbers like five or even more likely 10 for how many partitions per container works best if you consider the consequences of a container failure. To spread the load of hosting shards evenly across the data grid, you need more than just one partition for each container. If we had a single partition per container, then when a container fails, only one container (the one hosting the corresponding replica shard) must bear the full load of the lost primary. In this case, the load is immediately doubled for the container. However, if you have five partitions per container, then five containers pick up the load of the lost container, lowering impact on each by 80 percent. Using multiple partitions per container generally lowers the potential impact on each container substantially. More directly, consider a case in which a container spikes unexpectedly.the replication load of that container is spread over 5 containers rather than only one.
Use the per-container policy
Several scenarios make the per-container strategy an ideal configuration, such as with HTTP session replication or application session state. In such a case, an HTTP router assigns a session to a servlet container. The servlet container needs to create an HTTP session and chooses one of the 5 local partition primaries for the session. The "ID" of the partition chosen is then stored in a cookie. The servlet container now has local access to the session state which means zero latency access to the data for this request as long as you maintain session affinity. And WXS replicates any changes to the partition.
In practice, remember the repercussions of a case in which you have multiple partitions per container (say 5 again). Of course, with each new container started, you have 5 more partition primaries and 5 more replicas. Over time, more partitions should be created and they should not move or be destroyed. But this is not how the containers would actually behave. When a container starts, it hosts 5 primary shards, which can be called "home" primaries, existing on the respective containers that created them. If the container fails, the replicas become primaries and WXS creates 5 more replicas to maintain high availability (unless you disabled auto repair). The new primaries are in a different container than the one that created them, which can be called "foreign" primaries. The application should never place new state or sessions in a foreign primary. Eventually, the foreign primary has no entries and WXS automatically deletes it and its associated replicas. The foreign primaries' purpose is to allow existing sessions to still be available (but not new sessions).
A client can still interact with a data grid that does not rely on keys. The client just begins a transaction and stores data in the data grid independent of any keys. It asks the Session for a SessionHandle object, a serializable handle allowing the client to interact with the same partition when necessary. WXS chooses a partition for the client from the list of home partition primaries. It does not return a foreign primary partition. The SessionHandle can be serialized in an HTTP cookie, for example, and later convert the cookie back into a SessionHandle. Then the WXS APIs can obtain a Session bound to the same partition again, using the SessionHandle.
We cannot use agents to interact with a PER_CONTAINER data grid.
Advantages
The previous description is different from a normal FIXED_PARTITION or hash data grid because the per-container client stores data in a place in the grid, gets a handle to it and uses the handle to access it again. There is no application-supplied key as there is in the fixed-partition case.
Your deployment does not make a new partition for each Session. So in a per-container deployment, the keys used to store data in the partition must be unique within that partition. For example, you may have your client generate a unique SessionID and then use it as the key to find information in Maps in that partition. Multiple client sessions then interact with the same partition so the application needs to use unique keys to store session data in each given partition.
The previous examples used 5 partitions, but the numberOfPartitions parameter in the objectgrid XML file can be used to specify the partitions as required. Instead of per data grid, the setting is per container. (The number of replicas is specified in the same way as with the fixed-partition policy.)
The per-container policy can also be used with multiple zones. If possible, WXS returns a SessionHandle to a partition whose primary is located in the same zone as that client. The client can specify the zone as a parameter to the container or by using an API. The client zone ID can be set using serverproperties or clientproperties.
The PER_CONTAINER strategy for a data grid suits applications storing conversational type state rather than database-oriented data. The key to access the data would be a conversation ID and is not related to a specific database record. It provides higher performance (because the partition primaries can be collocated with the servlets for example) and easier configuration (without having to calculate partitions and containers).
Single-partition and cross-data-grid transactions
The major distinction between WXS and traditional data storage solutions like relational databases or in-memory databases is the use of partitioning, which allows the cache to scale linearly. The important types of transactions to consider are single-partition and every-partition (cross-data-grid) transactions.
In general, interactions with the cache can be categorized as single-partition transactions or cross-data-grid transactions, as discussed in the following section.
Single-partition transactions
Single-partition transactions are the preferable method for interacting with caches hosted by WXS.
When a transaction is limited to a single partition, then by default it is limited to a single JVM, and therefore a single server computer. A server can complete M number of these transactions per second, and if you have N computers, we can complete M*N transactions per second. If your business increases and you need to perform twice as many of these transactions per second, we can double N by buying more computers. Then we can meet capacity demands without changing the application, upgrading hardware, or even taking the application offline.
In addition to letting the cache scale so significantly, single-partition transactions also maximize the availability of the cache. Each transaction only depends on one computer. Any of the other (N-1) computers can fail without affecting the success or response time of the transaction. So if we are running 100 computers and one of them fails, only 1 percent of the transactions in flight at the moment that server failed are rolled back. After the server fails, WXS relocates the partitions hosted by the failed server to the other 99 computers. During this brief period, before the operation completes, the other 99 computers can still complete transactions. Only the transactions that would involve the partitions that are being relocated are blocked. After the failover process is complete, the cache can continue running, fully operational, at 99 percent of its original throughput capacity. After the failed server is replaced and returned to the data grid, the cache returns to 100 percent throughput capacity.
Cross-data-grid transactions
In terms of performance, availability and scalability, cross-data-grid transactions are the opposite of single-partition transactions . Cross-data-grid transactions access every partition and therefore every computer in the configuration. Each computer in the data grid is asked to look up some data and then return the result. The transaction cannot complete until every computer has responded, and therefore the throughput of the entire data grid is limited by the slowest computer. Adding computers does not make the slowest computer faster and therefore does not improve the throughput of the cache.
Cross-data-grid transactions have a similar effect on availability. Extending the previous example, if we are running 100 servers and one server fails, then 100 percent of the transactions that are in progress at the moment that server failed are rolled back. After the server fails, WXS starts to relocate the partitions hosted by that server to the other 99 computers.
During this time, before the failover process completes, the data grid cannot process any of these transactions. After the failover process is complete, the cache can continue running, but at reduced capacity. If each computer in the data grid serviced 10 partitions, then 10 of the remaining 99 computers receive at least one extra partition as part of the failover process. Adding an extra partition increases the workload of that computer by at least 10 percent. Because the throughput of the data grid is limited to the throughput of the slowest computer in a cross-data-grid transaction, on average, the throughput is reduced by 10 percent.
Single-partition transactions are preferable to cross-data-grid transactions for scaling out with a distributed, highly available, object cache like WXS. Maximizing the performance of these kinds of systems requires the use of techniques that are different from traditional relational methodologies, but we can turn cross-data-grid transactions into scalable single-partition transactions .
Best practices for building scalable data models
The best practices for building scalable applications with products like WXS include two categories: foundational principles and implementation tips. Foundational principles are core ideas that need to be captured in the design of the data itself. An application that does not observe these principles is unlikely to scale well, even for its mainline transactions. Implementation tips are applied for problematic transactions in an otherwise well-designed application that observes the general principles for scalable data models.
Foundational principles
Some of the important means of optimizing scalability are basic concepts or principles to keep in mind.
- Duplicate instead of normalizing
-
The key thing to remember about products like WXS is that they are designed to spread data across a large number of computers. If the goal is to make most or all transactions complete on a single partition, then the data model design needs to ensure that all the data the transaction might need is located in the partition. Most of the time, the only way to achieve this is by duplicating data.
For example, consider an application like a message board. Two very important transactions for a message board are showing all the posts from a given user and all the posts on a given topic. First consider how these transactions would work with a normalized data model that contains a user record, a topic record, and a post record that contains the actual text. If posts are partitioned with user records, then displaying the topic becomes a cross-grid transaction, and vice versa. Topics and users cannot be partitioned together because they have a many-to-many relationship.
The best way to make this message board scale is to duplicate the posts, storing one copy with the topic record and one copy with the user record. Then, displaying the posts from a user is a single-partition transaction, displaying the posts on a topic is a single-partition transaction, and updating or deleting a post is a two-partition transaction.
All three of these transactions will scale linearly as the number of computers in the data grid increases.
- Scalability rather than resources
-
The biggest obstacle to overcome when considering denormalized data models is the impact that these models have on resources. Keeping two, three, or more copies of some data can seem to use too many resources to be practical. When confronted with this scenario, remember the following facts: Hardware resources get cheaper every year. Second, and more importantly, WXS eliminates most hidden costs associated with deploying more resources.
Measure resources in terms of cost rather than computer terms such as megabytes and processors. Data stores that work with normalized relational data generally need to be located on the same computer. This required collocation means that a single larger enterprise computer needs to be purchased rather than several smaller computers. With enterprise hardware, it is not uncommon for one computer to be capable of completing one million transactions per second to cost much more than the combined cost of 10 computers capable of doing 100,000 transactions per second each.
A business cost in adding resources also exists. A growing business eventually runs out of capacity. When we run out of capacity, you either need to shut down while moving to a bigger, faster computer, or create a second production environment to which we can switch.
Either way, additional costs will come in the form of lost business or maintaining almost twice the capacity needed during the transition period.
With WXS, the application does not need to be shut down to add capacity. If your business projects that you need 10 percent more capacity for the coming year, then increase the number of computers in the data grid by 10 percent. We can increase this percentage without application downtime and without purchasing excess capacity.
- Avoid data transformations
-
When using WXS, data should be stored in a format that is directly consumable by the business logic. Breaking the data down into a more primitive form is costly. The transformation needs to be done when the data is written and when the data is read. With relational databases this transformation is done out of necessity, because the data is ultimately persisted to disk quite frequently, but with WXS, you do not need to perform these transformations. For the most part data is stored in memory and can therefore be stored in the exact form that the application needs.
Observing this simple rule helps denormalize your data in accordance with the first principle. The most common type of transformation for business data is the JOIN operations that are necessary to turn normalized data into a result set that fits the needs of the application.
Storing the data in the correct format implicitly avoids performing these JOIN operations and produces a denormalized data model.
- Eliminate unbounded queries
-
No matter how well you structure your data, unbounded queries do not scale well. For example, do not have a transaction that asks for a list of all items sorted by value. This transaction might work at first when the total number of items is 1000, but when the total number of items reaches 10 million, the transaction returns all 10 million items. If we run this transaction, the two most likely outcomes are the transaction timing out, or the client encountering an out-of-memory error.
The best option is to alter the business logic so that only the top 10 or 20 items can be returned. This logic alteration keeps the size of the transaction manageable no matter how many items are in the cache.
- Define schema
-
The main advantage of normalizing data is that the database system can take care of data consistency behind the scenes. When data is denormalized for scalability, this automatic data consistency management no longer exists. Implement a data model that can work in the application layer or as a plug-in to the distributed data grid to guarantee data consistency.
Consider the message board example.
If a transaction removes a post from a topic, then the duplicate post on the user record needs to be removed. Without a data model, it is possible a developer would write the application code to remove the post from the topic and forget to remove the post from the user record. However, if the developer were using a data model instead of interacting with the cache directly, the removePost method on the data model could pull the user ID from the post, look up the user record, and remove the duplicate post behind the scenes.
Alternately, we can implement a listener that runs on the actual partition that detects the change to the topic and automatically adjusts the user record. A listener might be beneficial because the adjustment to the user record could happen locally if the partition happens to have the user record, or even if the user record is on a different partition, the transaction takes place between servers instead of between the client and server. The network connection between servers is likely to be faster than the network connection between the client and the server.
- Avoid contention
-
Avoid scenarios such as having a global counter. The data grid will not scale if a single record is being used a disproportionate number of times compared to the rest of the records. The performance of the data grid will be limited by the performance of the computer that holds the given record.
In these situations, try to break the record up so it is managed per partition. For example consider a transaction that returns the total number of entries in the distributed cache. Instead of having every insert and remove operation access a single record that increments, have a listener on each partition track the insert and remove operations. With this listener tracking, insert and remove can become single-partition operations.
Reading the counter will become a cross-data-grid operation, but for the most part, it was already as inefficient as a cross-data-grid operation because its performance was tied to the performance of the computer hosting the record.
Implementation tips
We can also consider the following tips to achieve the best scalability.
- Use reverse-lookup indexes
-
Consider a properly denormalized data model where customer records are partitioned based on the customer ID number. This partitioning method is the logical choice because nearly every business operation performed with the customer record uses the customer ID number. However, an important transaction that does not use the customer ID number is the login transaction. It is more common to have user names or e-mail addresses for login instead of customer ID numbers.
The simple approach to the login scenario is to use a cross-data-grid transaction to find the customer record. As explained previously, this approach does not scale.
The next option might be to partition on user name or e-mail. This option is not practical because all the customer ID based operations become cross-data-grid transactions.
Also, the customers on your site might want to change their user name or e-mail address. Products like WXS need the value used to partition the data to remain constant.
The correct solution is to use a reverse lookup index. With WXS, a cache can be created in the same distributed grid as the cache that holds all the user records. This cache is highly available, partitioned and scalable.
This cache can be used to map a user name or e-mail address to a customer ID. This cache turns login into a two partition operation instead of a cross-grid operation. This scenario is not as good as a single-partition transaction, but the throughput still scales linearly as the number of computers increases.
- Compute at write time
-
Commonly calculated values like averages or totals can be expensive to produce because these operations usually require reading a large number of entries. Because reads are more common than writes in most applications, it is efficient to compute these values at write time and then store the result in the cache. This practice makes read operations both faster and more scalable.
- Optional fields
-
Consider a user record that holds a business, home, and telephone number. A user could have all, none or any combination of these numbers defined. If the data were normalized then a user table and a telephone number table would exist. The telephone numbers for a given user could be found using a JOIN operation between the two tables.
De-normalizing this record does not require data duplication, because most users do not share telephone numbers. Instead, empty slots in the user record must be allowed. Instead of having a telephone number table, add three attributes to each user record, one for each telephone number type. This addition of attributes eliminates the JOIN operation and makes a telephone number lookup for a user a single-partition operation.
- Placement of many-to-many relationships
-
Consider an application that tracks products and the stores in which the products are sold. A single product is sold in many stores, and a single store sells many products. Assume that this application tracks 50 large retailers. Each product is sold in a maximum of 50 stores, with each store selling thousands of products.
Keep a list of stores inside the product entity (arrangement A), instead of keeping a list of products inside each store entity (arrangement B). Looking at some of the transactions this application would have to perform illustrates why arrangement A is more scalable.
First look at updates. With arrangement A, removing a product from the inventory of a store locks the product entity. If the data grid holds 10000 products, only 1/10000 of the grid needs to be locked to perform the update. With arrangement B, the data grid only contains 50 stores, so 1/50 of the grid must be locked to complete the update. So even though both of these could be considered single-partition operations, arrangement A scales out more efficiently.
Now, considering reads with arrangement A, looking up the stores at which a product is sold is a single-partition transaction that scales and is fast because the transaction only transmits a small amount of data. With arrangement B, this transaction becomes an cross-data-grid transaction because each store entity must be accessed to see if the product is sold at that store, which reveals an enormous performance advantage for arrangement A.
- Scaling with normalized data
-
One legitimate use of cross-data-grid transactions is to scale data processing. If a data grid has 5 computers and a cross-data-grid transaction is dispatched that sorts through about 100,000 records on each computer, then that transaction sorts through 500,000 records.
If the slowest computer in the data grid can perform 10 of these transactions per second, then the data grid is capable of sorting through 5,000,000 records per second. If the data in the grid doubles, then each computer must sort through 200,000 records, and each transaction sorts through 1,000,000 records. This data increase decreases the throughput of the slowest computer to 5 transactions per second, thereby reducing the throughput of the data grid to 5 transactions per second. Still, the data grid sorts through 5,000,000 records per second.
In this scenario, doubling the number of computer allows each computer to return to its previous load of sorting through 100,000 records, allowing the slowest computer to process 10 of these transactions per second. The throughput of the data grid stays the same at 10 requests per second, but now each transaction processes 1,000,000 records, so the grid has doubled its capacity in terms of processing records to 10,000,000 per second.
Applications such as a search engine that need to scale both in terms of data processing to accommodate the increasing size of the Internet and throughput to accommodate growth in the number of users, you must create multiple data grids, with a round robin of the requests between the grids. If you need to scale up the throughput, add computers and add another data grid to service requests. If data processing needs to be scaled up, add more computers and keep the number of data grids constant.
Scaling in units or pods
Although we can deploy a data grid over thousands of JVMs, you might consider splitting the data grid into units or pods to increase the reliability and ease of testing of the configuration. A pod is a group of servers running the same set of applications.
Deploy a large single data grid
Testing has verified that eXtreme Scale can scale out to over 1000 JVMs. Such testing encourages building applications to deploy single data grids on large numbers of boxes. Although it is possible to do this, it is not recommended, for several reasons:
- Budget concerns: Your environment cannot realistically test a 1000-server data grid. However, it can test a much smaller data grid considering budget reasons, so you do not need to buy twice the hardware, especially for such a large number of servers.
- Different application versions: Requiring a large number of boxes for each testing thread is not practical. The risk is that we are not testing the same factors as you would in a production environment.
- Data loss: Running a database on a single hard drive is unreliable. Any problem with the hard drive causes you to lose data. Running a growing application on a single data grid is similar. You will likely have bugs in your environment and in the applications. So placing all of the data on a single large system will often lead to a loss of large amounts of data.
Splitting the data grid
Splitting the application data grid into pods (units) is a more reliable option. A pod is a group of servers running a homogenous application stack. Pods can be of any size, but ideally they should consist of about 20 physical servers. Instead of having 500 physical servers in a single data grid, we can have 25 pods of 20 physical servers. A single version of an application stack should run on a given pod, but different pods can have their own versions of an application stack.
Generally, an application stack considers levels of the following components.
- Operating system
- Hardware
- JVM
- WXS version
- Application
- Other necessary components
A pod is a conveniently sized deployment unit for testing. Instead of having hundreds of servers for testing, it is more practical to have 20 servers. In this case, we are still testing the same configuration as you would have in production. Production uses grids with a maximum size of 20 servers, constituting a pod. We can stress-test a single pod and determine its capacity, number of users, amount of data, and transaction throughput. This makes planning easier and follows the standard of having predictable scaling at predictable cost.
Set up a pod-based environment
In different cases, the pod does not necessarily have to have 20 servers. The purpose of the pod size is for practical testing. The size of a pod should be small enough that if a pod encounters problems in production, the fraction of transactions affected is tolerable.
Ideally, any bug impacts a single pod. A bug would only have an impact on four percent of the application transactions rather than 100 percent. In addition, upgrades are easier because they can be rolled out one pod at a time. As a result, if an upgrade to a pod creates problems, the user can switch that pod back to the prior level. Upgrades include any changes to the application, the application stack, or system updates. As much as possible, upgrades should only change a single element of the stack at a time to make problem diagnosis more precise.
To implement an environment with pods, you need a routing layer above the pods that is forwards and backwards compatible if pods get software upgrades. Also, you should create a directory that includes information about which pod has what data. Use another WXS data grid for this with a database behind it, preferably using the write-behind scenario.) This yields a two-tier solution. Tier 1 is the directory and is used to locate which pod handles a specific transaction. Tier 2 is composed of the pods themselves. When tier 1 identifies a pod, the setup routes each transaction to the correct server in the pod, which is usually the server holding the partition for the data used by the transaction. Optionally, we can also use a near cache on tier 1 to lower the impact associated with looking up the correct pod.
Use pods is slightly more complex than having a single data grid, but the operational, testing, and reliability improvements make it a crucial part of scalability testing.
High availability
With high availability, WXS provides reliable data redundancy and detection of failures.
WXS self-organizes data grids of JVMs into a loosely federated tree. The catalog service at the root and core groups holding containers are at the leaves of the tree.
Each core group is automatically created by the catalog service into groups of about 20 servers. The core group members provide health monitoring for other members of the group. Also, each core group elects a member to be the leader for communicating group information to the catalog service. Limiting the core group size allows for good health monitoring and a highly scalable environment.
In a WebSphere Application Server environment, in which core group size can be altered, WXS does not support more than 50 members per core group.
Heart beating
- Sockets are kept open between JVMs, and if a socket closes unexpectedly, this unexpected closure is detected as a failure of the peer JVM. This detection catches failure cases such as the JVM exiting very quickly. Such detection also allows recovery from these types of failures typically in less than a second.
- Other types of failures include: an operating system panic, physical server failure, or network failure. These failures are discovered through heart beating .
Heartbeats are sent periodically between pairs of processes: When a fixed number of heartbeats are missed, a failure is assumed. This approach detects failures in N*M seconds. N is the number of missed heart beats and M is the heartbeat interval. Directly specifying M and N is not supported. A slider mechanism is used to allow a range of tested M and N combinations to be used.
Failures
There are several ways that a process can fail. The process could fail because some resource limit was reached, such as maximum heap size, or some process control logic terminated a process. The operating system could fail, causing all of the processes running on the system to be lost. Hardware can fail, though less frequently, like the network interface card (NIC), causing the operating system to be disconnected from the network. Many more points of failure can occur, causing the process to be unavailable. In this context, all of these failures can be categorized into one of two types: process failure and loss of connectivity.
Process failure
WXS reacts to process failures quickly. When a process fails, the operating system is responsible for cleaning up any left over resources that the process was using. This cleanup includes port allocation and connectivity. When a process fails, a signal is sent over the connections that were being used by that process to close each connection. With these signals, a process failure can be instantly detected by any other process connected to the failed process.
Loss of connectivity
Loss of connectivity occurs when the operating system becomes disconnected. As a result, the operating system cannot send signals to other processes. There are several reasons that loss of connectivity can occur, but they can be split into two categories: host failure and islanding .
Host failure
If the machine is unplugged from the power outlet, then it is gone instantly.
Islanding
This scenario presents the most complicated failure condition for software to handle correctly because the process is presumed to be unavailable, though it is not. Essentially, a server or other process appears to the system to have failed while it is actually running properly.
Container failures
Container failures are generally discovered by peer containers through the core group mechanism. When a container or set of containers fails, the catalog service migrates the shards that were hosted on that container or containers. The catalog service looks for a synchronous replica first before migrating to an asynchronous replica. After the primary shards are migrated to new host containers, the catalog service looks for new host containers for the replicas that are now missing.
Container islanding - The catalog service migrates shards off containers when the container is discovered to be unavailable. If those containers then become available, the catalog service considers the containers eligible for placement just like in the normal startup flow.
Container failure detection latency
Failures can be categorized into soft and hard failures. Soft failures are typically caused when a process fails. Such failures are detected by the operating system, which can recover used resources, such as network sockets, quickly. Typical failure detection for soft failures is less than one second. Hard failures might take up to 200 seconds to detect with the default heart beat tuning. Such failures include: physical machine crashes, network cable disconnects, or operating system failures. The run time relies on heart beating to detect hard failures which can be configured.
Catalog service failure
Because the catalog service grid is a WXS grid, it also uses the core grouping mechanism in the same way as the container failure process. The primary difference is that the catalog service domain uses a peer election process for defining the primary shard instead of the catalog service algorithm used for the containers.
The placement service and the core grouping service are One of N services. A One of N service runs in one member of the high availability group. The location service and administration run in all of the members of the high availability group. The placement service and core grouping service are singletons because they are responsible for laying out the system. The location service and administration are read-only services and exist everywhere to provide scalability.
The catalog service uses replication to make itself fault tolerant. If a catalog service process fails, then the service restarts to restore the system to the wanted level of availability. If all of the processes that are hosting the catalog service fail, the data grid has a loss of critical data. This failure results in a required restart of all the container servers. Because the catalog service can run on many processes, this failure is an unlikely event. However, if we are running all of the processes on a single box, within a single blade chassis, or from a single network switch, a failure is more likely to occur. Try to remove common failure modes from boxes that are hosting the catalog service to reduce the possibility of failure.
Multiple container failures
A replica is never placed in the same process as its primary because if the process is lost, it would result in a loss of both the primary and the replica. In a development environment on a single machine, you might want to have two containers and replicate between them. We can define the development mode attribute in the deployment policy to configure a replica to be placed on the same machine as a primary. However, in production, using a single machine is not sufficient because loss of that host results in the loss of both container servers. To change between development mode on a single machine and a production mode with multiple machines, disable development mode in the deployment policy configuration file.
| Discovery detection mechanism | Recovery method | |
|---|---|---|
| Process loss | I/O | Restart |
| Server loss | Heartbeat | Restart |
| Network outage | Heartbeat | Reestablish network and connection |
| Server-side hang | Heartbeat | Stop and restart server |
| Server busy | Heartbeat | Wait until server is available |
Replication for availability
Replication provides fault tolerance and increases performance for a distributed WXS topology. Replication is enabled by associating backing maps with a map set.
About map sets
A map set is a collection of maps that are categorized by a partition-key. This partition-key is derived from the key on the individual map by taking its hash modulo the number of partitions. If one group of maps within the map set has partition-key X, those maps are stored in a corresponding partition X in the data grid. If another group has partition-key Y, all of the maps are stored in partition Y, and so on. The data within the maps is replicated based on the policy defined on the map set. Replication occurs on distributed topologies.
Map sets are assigned the number of partitions and a replication policy. The map set replication configuration identifies the number of synchronous and asynchronous replica shards for the map set must in addition to the primary shard . For example, if one synchronous and one asynchronous replica exist, all of the BackingMaps that are assigned to the map set each have a replica shard distributed automatically within the set of available container server s for the data grid. The replication configuration can also enable clients to read data from synchronously replicated servers. This can spread the load for read requests over additional servers in the WXS. Replication has a programming model impact only when preloading the backing maps.
Map preloading
Maps can be associated with Loaders. A loader is used to fetch objects when they cannot be found in the map (a cache miss) and also to write changes to a back-end when a transaction commits. Loaders can also be used for preloading data into a map. The preloadMap method of the Loader interface is called on each map when its corresponding partition in the map set becomes a primary. The preloadMap method is not called on replicas. It attempts to load all the intended referenced data from the back-end into the map using the provided session. The relevant map is identified by the BackingMap argument that is passed to the preloadMap method.
void preloadMap(Session session, BackingMap backingMap) throws LoaderException;
Preloading in partitioned map set
Maps can be partitioned into N partitions. Maps can therefore be striped across multiple servers, with each entry identified by a key that is stored only on one of those servers. Very large maps can be held in a WXS because the application is no longer limited by the heap size of a single JVM to hold all the entries of a Map. Applications that want to preload with the preloadMap method of the Loader interface must identify the subset of the data that it preloads. A fixed number of partitions always exists. We can determine this number using the following code example:
int numPartitions = backingMap.getPartitionManager().getNumOfPartitions(); int myPartition = backingMap.getPartitionId();This code example shows that an application can identify the subset of the data to preload from the database. Applications must always use these methods even when the map is not initially partitioned. These methods allow flexibility: If the map is later partitioned by the administrators, then the loader continues to work correctly.
The application must issue queries to retrieve the myPartition subset from the backend. If a database is used, then it might be easier to have a column with the partition identifier for a given record unless there is some natural query that allows the data in the table to partition easily.
Performance
The preload implementation copies data from the back-end into the map by storing multiple objects in the map in a single transaction. The optimal number of records to store per transaction depends on several factors, including complexity and size. For example, after the transaction includes blocks of more than 100 entries, the performance benefit decreases as you increase the number of entries. To determine the optimal number, begin with 100 entries and then increase the number until the performance benefit decreases to none. Larger transactions result in better replication performance. Remember, only the primary runs the preload code. The preloaded data is replicated from the primary to any replicas that are online.
Preloading map sets
If the application uses a map set with multiple maps then each map has its own loader. Each loader has a preload method. Each map is loaded serially by the WXS. It might be more efficient to preload all the maps by designating a single map as the preloading map. This process is an application convention. For example, two maps, department and employee, might use the department Loader to preload both the department and the employee maps. This procedure ensures that, transactionally, if an application wants a department then the employees for that department are in the cache. When the department Loader preloads a department from the back-end, it also fetches the employees for that department. The department object and its associated employee objects are then added to the map using a single transaction.
Recoverable preloading
Some customers have very large data sets that need caching. Preloading this data can be very time consuming. Sometimes, the preloading must complete before the application can go online. We can benefit from making preloading recoverable. Suppose there are a million records to preload. The primary is preloading them and fails at the 800,000th record. Normally, the replica chosen to be the new primary clears any replicated state and starts from the beginning. WXS can use a ReplicaPreloadController interface. The loader for the application would also need to implement the ReplicaPreloadController interface.
This example adds a single method to the Loader:
<>ul> Status checkPreloadStatus(Session session, BackingMap bmap);
This method is called by the WXS run time before the preload method of the Loader interface is normally called. WXS tests the result of this method (Status) to determine its behavior whenever a replica is promoted to a primary.
| WXS response | |
|---|---|
| Status.PRELOADED_ALREADY | WXS does not call the preload method at all because this status value indicates that the map is fully preloaded. |
| Status.FULL_PRELOAD_NEEDED | WXS clears the map and calls the preload method normally. |
| Status.PARTIAL_PRELOAD_NEEDED | WXS leaves the map as-is and calls preload. This strategy allows the application loader to continue preloading from that point onwards. |
Clearly, while a primary is preloading the map, it must leave some state in a map in the map set that is being replicated so that the replica determines what status to return. Use an extra map named, for example, RecoveryMap. This RecoveryMap must be part of the same map set that is being preloaded to ensure that the map is replicated consistently with the data being preloaded. A suggested implementation follows.
As the preload commits each block of records, the process also updates a counter or value in the RecoveryMap as part of that transaction. The preloaded data and the RecoveryMap data are replicated atomically to the replicas. When the replica is promoted to primary, it can now check the RecoveryMap to see what has happened.
The RecoveryMap can hold a single entry with the state key. If no object exists for this key then you need a full preload (checkPreloadStatus returns FULL_PRELOAD_NEEDED). If an object exists for this state key and the value is COMPLETE, the preload completes, and the checkPreloadStatus method returns PRELOADED_ALREADY. Otherwise, the value object indicates where the preload restarts and the checkPreloadStatus method returns: PARTIAL_PRELOAD_NEEDED. The loader can store the recovery point in an instance variable for the loader so that when preload is called, the loader knows the starting point. The RecoveryMap can also hold an entry per map if each map is preloaded independently.
Handling recovery in synchronous replication mode with a Loader
The WXS run time is designed not to lose committed data when the primary fails. The following section shows the algorithms used. These algorithms apply only when a replication group uses synchronous replication. A loader is optional.
The WXS run time can be configured to replicate all changes from a primary to the replicas synchronously. When a synchronous replica is placed, it receives a copy of the existing data on the primary shard . During this time, the primary continues to receive transactions and copies them to the replica asynchronously. The replica is not considered to be online at this time.
After the replica catches up the primary, the replica enters peer mode and synchronous replication begins. Every transaction committed on the primary is sent to the synchronous replicas and the primary waits for a response from each replica. A synchronous commit sequence with a Loader on the primary looks like the following set of steps:
| Step with loader | Step without loader |
|---|---|
| Get locks for entries | same |
| Flush changes to the loader | no-op |
| Save changes to the cache | same |
| Send changes to replicas and wait for acknowledgment | same |
| Commit to the loader through the TransactionCallback plug-in | Plug-in commit called, but does nothing |
| Release locks for entries | same |
Notice that the changes are sent to the replica before they are committed to the loader. To determine when the changes are committed on the replica, revise this sequence: At initialize time, initialize the tx lists on the primary as below.
CommitedTx = {}, RolledBackTx = {}
During synchronous commit processing, use the following sequence:
| Step with loader | Step without loader |
|---|---|
| Get locks for entries | same |
| Flush changes to the loader | no-op |
| Save changes to the cache | same |
| Send changes with a committed transaction, roll back transaction to replica, and wait for acknowledgment | same |
| Clear list of committed transactions and rolled back transactions | same |
| Commit the loader through the TransactionCallBack plug-in | TransactionCallBack plug-in commit is still called, but typically does not do anything |
| If commit succeeds, add the transaction to the committed transactions, otherwise add to the rolled back transactions | no-op |
| Release locks for entries | same |
For replica processing, use the following sequence:
- Receive changes
- Commit all received transactions in the committed transaction list
- Roll back all received transactions in the rolled back transaction list
- Start a transaction or session
- Apply changes to the transaction or session
- Save the transaction or session to the pending list
- Send back reply
Notice that on the replica, no loader interactions occur while the replica is in replica mode. The primary must push all changes through the Loader. The replica does not push any changes. A side effect of this algorithm is that the replica always has the transactions, but they are not committed until the next primary transaction sends the commit status of those transactions. The transactions are then committed or rolled back on the replica. Until then, the transactions are not committed. We can add a timer on the primary that sends the transaction outcome after a small period (a few seconds). This timer limits, but does not eliminate, any staleness to that time window. This staleness is only a problem when using replica read mode. Otherwise, the staleness does not have an impact on the application.
When the primary fails, it is likely that a few transactions were committed or rolled back on the primary, but the message never made it to the replica with these outcomes. When a replica is promoted to the new primary, one of the first actions is to handle this condition. Each pending transaction is reprocessed against the new primary's set of maps. If there is a Loader, then each transaction is given to the Loader. These transactions are applied in strict first in first out (FIFO) order. If a transaction fails, it is ignored. If three transactions are pending, A, B, and C, then A might commit, B might rollback, and C might also commit. No one transaction has any impact on the others. Assume that they are independent.
A loader might want to use slightly different logic when it is in failover recovery mode versus normal mode. The loader can easily know when it is in failover recovery mode by implementing the ReplicaPreloadController interface. The checkPreloadStatus method is only called when failover recovery completes. Therefore, if the apply method of the Loader interface is called before the checkPreloadStatus method, then it is a recovery transaction. After the checkPreloadStatus method is called, the failover recovery is complete.
Load balancing across replicas
The WXS, unless configured otherwise, sends all read and write requests to the primary server for a given replication group. The primary must service all requests from clients. You might want to allow read requests to be sent to replicas of the primary. Sending read requests to the replicas allows the load of the read requests to be shared by multiple JVMs. However, using replicas for read requests can result in inconsistent responses.
Load balancing across replicas is typically used only when clients are caching data that is changing all the time or when the clients are using pessimistic locking .
If the data is continually changing and then being invalidated in client near caches, the primary should see a relatively high get request rate from clients as a result. Likewise, in pessimistic locking mode, no local cache exists, so all requests are sent to the primary.
If the data is relatively static or if pessimistic mode is not used, then sending read requests to the replica does not have a large impact on performance. The frequency of get requests from clients with caches that are full of data is not high.
When a client first starts, its near cache is empty. Cache requests to the empty cache are forwarded to the primary. The client cache gets data over time, causing the request load to drop. If many clients start concurrently, then the load might be significant and replica read might be an appropriate performance choice.
Client-side replication
With WXS, we can replicate a server map to one or more clients by using asynchronous replication. A client can request a local read-only copy of a server side map using the ClientReplicableMap.enableClientReplication method.
- void enableClientReplication(Mode mode, int[] partitions, ReplicationMapListener listener) throws ObjectGridException;
The first parameter is the replication mode. This mode can be a continuous replication or a snapshot replication. The second parameter is an array of partition IDs that represent the partitions from which to replicate the data. If the value is null or an empty array, the data is replicated from all the partitions. The last parameter is a listener to receive client replication events. See ClientReplicableMap and ReplicationMapListener in the API documentation for details.
After the replication is enabled, then the server starts to replicate the map to the client. The client is eventually only a few transactions behind the server at any point in time.
High availability catalog service
A catalog service domain is the data grid of catalog servers we are using, which retain topology information for all of the container servers in your WXS environment. The catalog service controls balancing and routing for all clients.
Figure 1. Catalog service domain
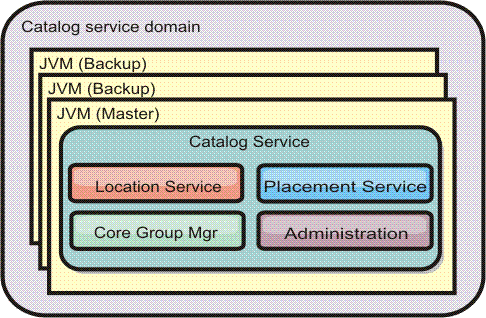
When multiple catalog servers start, one of the servers is elected as the master catalog server that accepts heartbeats and handles system data changes in response to any catalog service or container changes.
Configure at least three catalog servers in the catalog service domain. Catalog servers must be installed on separate nodes or separate installation images from your container servers to ensure that we can seamlessly upgrade your servers at a later date. If the configuration has zones, we can configure one catalog server per zone.
When a container server contacts one of the catalog servers, the routing table for the catalog service domain is also propagated to the catalog server and container server through the CORBA service context. Furthermore, if the contacted catalog server is not currently the master catalog server, the request is automatically rerouted to the current master catalog server and the routing table for the catalog server is updated.
A catalog service domain and the container server data grid are very different. The catalog service domain is for high availability of your system data. The container server data grid is for your data high availability, scalability, and workload management. Therefore, two different routing tables exist: the routing table for the catalog service domain and the routing table for the container server data grid shards.
Catalog server quorums
When the quorum mechanism is enabled, all the catalog servers in the quorum must be available for placement operations to occur in the data grid.
| Heartbeat | Signal sent between servers to convey that they are running. |
| Quorum | Group of catalog servers that communicate and conduct placement operations in the data grid. Groups contain all catalog servers in the grid, unless you manually override the quorum mechanism with administrative actions. |
| Brownout | Temporary loss of connectivity between one or more servers. |
| Blackout | Permanent loss of connectivity between one or more servers. |
| Data center | Geographically located group of servers. Generally connected with a LAN. |
| Zone | Group servers together that share some physical characteristic. For example, data centers, area networks, buildings, or floors. |
Heartbeats and failure detection
Container servers and core groups
The catalog service places container servers into core groups of a limited size. A core group tries to detect the failure of its members. A single member of a core group is elected to be the core group leader. The core group leader periodically tells the catalog service that the core group is alive and reports any membership changes to the catalog service. A membership change can be a JVM failing or a newly added JVM that joins the core group.
If a JVM socket is closed, that JVM is regarded as being no longer available. Each core group member also heart beats over these sockets at a rate determined by configuration. If a JVM does not respond to these heartbeats within a configured maximum time period, then the JVM is considered to be no longer available, which triggers a failure detection.
If the catalog service marks a container (JVM) as failed and the container server is later reported as being available, the container is told to shut down the WXS container servers. A in this state is not visible in xscmd utility command queries. Messages in the logs of the container indicate that the container has failed. You must manually restart these JVMs.
If the core group leader cannot contact any member, it continues to retry contacting the member.
The complete failure of all members of a core group is also a possibility. If the entire core group has failed, it is the responsibility of the catalog service to detect this loss.
Catalog service domain heart-beating
The catalog service domain looks like a private core group with a static membership and a quorum mechanism. It detects failures the same way as a normal core group. However, the behavior is modified to include quorum logic. The catalog service also uses a less aggressive heart-beating configuration.
Failure detection
WXS detects when processes terminate through abnormal socket closure events. The catalog service is notified immediately when a process terminates.
Quorum behavior
Normally, the members of the catalog service have full connectivity. The catalog service domain is a static set of JVMs. WXS expects all members of the catalog service to be online. When all the members are online, the catalog service has quorum. The catalog service responds to container events only while the catalog service has quorum.
Reasons for quorum loss
WXS expects to lose quorum for the following scenarios:
- A catalog service JVM member fails
- Network brown out occurs
- Data center loss occurs
WXS does not lose quorum in the following scenario:
- Stopping a catalog server instance with the stopOgServer command or any other administrative actions. The system knows that the server instance has stopped, which is different from a JVM failure or brownout.
If the catalog service loses a quorum, it waits for quorum to be reestablished. While the catalog service does not have a quorum, it ignores events from container servers. Container servers continue to try any requests that are rejected by the catalog server during this time. Heart-beating is suspended until a quorum is reestablished.
Quorum loss from JVM failure
A catalog server that fails causes quorum to be lost. If a JVM fails, quorum can be reestablished by either overriding quorum or by restarting the failed catalog server.
loss from network brownout
WXS is designed to expect the possibility of brownouts. A brownout is when a temporary loss of connectivity occurs between data centers. Brown outs are usually transient and clear within seconds or minutes. While WXS tries to maintain normal operation during the brownout period, a brownout is regarded as a single failure event. The failure is expected to be fixed and then normal operation resumes with no actions necessary.
A long duration brown out can be classified as a blackout only through user intervention.
Overriding quorum on one side of the brownout is required in order for the event to be classified as a blackout.
Catalog service JVM cycling
If a catalog server is stopped using the stopOgServer command, then the quorum drops to one less server. The remaining servers still have quorum. Restarting the catalog server sets quorum back to the previous number.
Consequences of lost quorum
If a container JVM was to fail while quorum is lost, recovery does not occur until the brownout recovers. In a blackout scenario, the recovery does not occur until we run the override quorum command. Quorum loss and a container failure as are considered a double failure, which is a rare event. Because of the double failure, applications might lose write access to data that was stored on the failed JVM. When quorum is restored, the normal recovery occurs.
Similarly, if you attempt to start a container during a quorum loss event, the container does not start.
Full client connectivity is allowed during quorum loss. If no container failures or connectivity issues happen during the quorum loss event then clients can still fully interact with the container servers.
If a brownout occurs, then some clients might not have access to primary or replica copies of the data until the brownout clears.
New clients can be started because a catalog service JVM must exist in each data center. Therefore, at least one catalog server can be reached by a client even during a brownout event.
Quorum recovery
If quorum is lost for any reason, when quorum is reestablished, a recovery protocol is run. When the quorum loss event occurs, all liveness checking for core groups is suspended and failure reports are also ignored. After quorum is back, then the catalog service checks all the core groups to immediately determine their membership. Any shards previously hosted on container JVMs reported as failed are recovered. If primary shards were lost, then surviving replicas are promoted to being primary shards. If replica shards were lost then additional replicas shards are created on the survivors.
Overriding quorum
Override quorum only when a data center failure has occurred. Quorum loss due to a catalog service JVM failure or a network brownout recovers automatically after the catalog service JVM is restarted or the network brownout ends.
Administrators are the only ones with knowledge of a data center failure. WXS treats a brownout and a blackout similarly. Inform the WXS environment of such failures with the xscmd -c overrideQuorum command. This command tells the catalog service to assume that quorum is achieved with the current membership, and full recovery takes place. When issuing an override quorum command, we are guaranteeing that the JVMs in the failed data center have truly failed and do not have a chance of recovering.
The following list considers some scenarios for overriding quorum. In this scenario, you have three catalog servers: A, B, and C.
| Brown out | The C catalog server is isolated temporarily. The catalog service loses quorum and waits for the brownout to complete. After the brownout is over, the C catalog server rejoins the catalog service domain and quorum is reestablished. Your application sees no problems during this time. |
| Temporary failure | During a temporary failure, the C catalog server fails and the catalog service loses quorum. You must override quorum. After quorum is reestablished, we can restart the C catalog server. The C catalog server joins the catalog service domain again when it restarts. Your application sees no problems during this time. |
| Data center failure | You verify that the data center has failed and that it has been isolated on the network. Then you issue the xscmd -c overrideQuorum command. The surviving two data centers run a full recovery by replacing shards that were hosted in the failed data center. The catalog service is now running with a full quorum of the A and B catalog servers. The application might see delays or exceptions during the interval between the start of the blackout and when quorum is overridden. After quorum is overridden, the data grid recovers and normal operation is resumed. |
| Data center recovery | The surviving data centers are already running with quorum overridden. When the data center that contains the C catalog server is restarted, all JVMs in the data center must be restarted. Then the C catalog server joins the existing catalog service domain again and the quorum setting reverts to the normal situation with no user intervention. |
| Data center failure and brownout | The data center that contains the C catalog server fails. Quorum is overridden and recovered on the remaining data centers. If a brownout between the A and B catalog servers occurs, the normal brownout recovery rules apply. After the brownout clears, quorum is reestablished and necessary recovery from the quorum loss occurs. |
Container behavior during quorum loss
Containers host one or more shards. Shards are either primaries or replicas for a specific partition. The catalog service assigns shards to a container and the container server uses that assignment until new instructions arrive from the catalog service. For example, a primary shard continues to try communication with its replica shards during network brownouts, until the catalog service provides further instructions to the primary shard .
Synchronous replica behavior
The primary shard can accept new transactions while the connection is broken if the number of replicas online are at least at the minsync property value for the map set. If any new transactions are processed on the primary shard while the link to the synchronous replica is broken, the replica is resynchronized with the current state of the primary when the link is reestablished.
Do not configure synchronous replication between data centers or over a WAN-style link.
Asynchronous replica behavior
While the connection is broken, the primary shard can accept new transactions. The primary shard buffers the changes up to a limit. If the connection with the replica is reestablished before that limit is reached then the replica is updated with the buffered changes. If the limit is reached, then the primary destroys the buffered list and when the replica reattaches then it is cleared and resynchronized.
Client behavior during quorum loss
Clients are always able to connect to the catalog server to bootstrap to the data grid whether the catalog service domain has quorum or not. The client tries to connect to any catalog server instance to obtain a route table and then interact with the data grid. Network connectivity might prevent the client from interacting with some partitions due to network setup. The client might connect to local replicas for remote data if it has been configured to do so. Clients cannot update data if the primary partition for that data is not available.
Replicas and shards
With WXS, an in-memory database or shard can be replicated from one JVM to another. A shard represents a partition that is placed on a container. Multiple shards that represent different partitions can exist on a single container. Each partition has an instance that is a primary shard and a configurable number of replica shards. The replica shards are either synchronous or asynchronous. The types and placement of replica shards are determined by WXS using a deployment policy, which specifies the minimum and maximum number of synchronous and asynchronous shards.
Shard types
Replication uses three types of shards:
- Primary
- Synchronous replica
- Asynchronous replica
The primary shard receives all insert, update and remove operations. The primary shard adds and removes replicas, replicates data to the replicas, and manages commits and rollbacks of transactions.
Synchronous replicas maintain the same state as the primary. When a primary replicates data to a synchronous replica, the transaction is not committed until it commits on the synchronous replica.
Asynchronous replicas might or might not be at the same state as the primary. When a primary replicates data to an asynchronous replica, the primary does not wait for the asynchronous replica to commit.
Figure 1. Communication path between a primary shard and replica shards

Minimum synchronous replica shards
When a primary prepares to commit data, it checks how many synchronous replica shards voted to commit the transaction. If the transaction processes normally on the replica, it votes to commit. If something went wrong on the synchronous replica, it votes not to commit. Before a primary commits, the number of synchronous replica shards that are voting to commit must meet the minSyncReplica setting from the deployment policy. When the number of synchronous replica shards that are voting to commit is too low, the primary does not commit the transaction and an error results. This action ensures that the required number of synchronous replicas are available with the correct data. Synchronous replicas that encountered errors reregister to fix their state.
The primary throws a ReplicationVotedToRollbackTransactionException error if too few synchronous replicas voted to commit.
Replication and Loaders
Normally, a primary shard writes changes synchronously through the Loader to a database. The Loader and database are always in sync. When the primary fails over to a replica shard, the database and Loader might not be in synch. For example:
- The primary can send the transaction to the replica and then fail before committing to the database.
- The primary can commit to the database and then fail before sending to the replica.
Either approach leads to either the replica being one transaction in front of or behind the database. This situation is not acceptable. WXS uses a special protocol and a contract with the Loader implementation to solve this issue without two phase commit. The protocol follows:
Primary side
- Send the transaction along with the previous transaction outcomes.
- Write to the database and try to commit the transaction.
- If the database commits, then commit on WXS. If the database does not commit, then roll back the transaction.
- Record the outcome.
Replica side
- Receive a transaction and buffer it.
- For all outcomes, send with the transaction, commit any buffered transactions and discard any rolled back transactions.
Replica side
on failover
- For all buffered transactions, provide the transactions to the Loader and the Loader attempts to commit the transactions.
- The Loader needs to be written to make each transaction is idempotent.
- If the transaction is already in the database, then the Loader performs no operation.
- If the transaction is not in the database, then the Loader applies the transaction.
- After all transactions are processed, then the new primary can begin to serve requests.
This protocol ensures that the database is at the same level as the new primary state.
Shard placement
The catalog service is responsible for placing shards. Each ObjectGrid has a number of partitions, each of which has a primary shard and an optional set of replica shards. The catalog service allocates the shards by balancing them so that they are evenly distributed over the available container servers. Replica and primary shards for the same partition are never placed on the same container server or the same IP address, unless the configuration is in development mode.
If a new container server starts, then WXS retrieves shards from relatively overloaded container servers to the new empty container server. This movement of shards enables horizontal scaling.
Scaling out
Scaling out means that when extra container servers are added to a data grid, WXS tries to move existing shards, primaries or replicas, from the old set of container servers to the new set. This movement expands the data grid to take advantage of the processor, network and memory of the newly added container servers. The movement also balances the data grid and tries to ensure that each JVM in the data grid hosts the same amount of data. As the data grid expands, each server hosts a smaller subset of the total grid. WXS assumes that data is distributed evenly among the partitions. This expansion enables scaling out .
Scaling in
Scaling in means that if a JVM fails, then WXS tries to repair the damage. If the failed JVM had a replica, then WXS replaces the lost replica by creating a new replica on a surviving JVM. If the failed JVM had a primary, then WXS finds the best replica on the survivors and promotes the replica to be the new primary. WXS then replaces the promoted replica with a new replica that is created on the remaining servers. To maintain scalability, WXS preserves the replica count for partitions as servers fail.
Figure 1. Placement of an ObjectGrid map set with a deployment policy of 3 partitions with a minSyncReplicas value of 1, a maxSyncReplicas value of 1, and a maxAsyncReplicas value of 1

Reading from replicas
We can configure map sets such that a client is permitted to read from a replica rather than being restricted to primary shards only.
It can often be advantageous to allow replicas to serve as more than simply potential primaries in the case of failures. For example, map sets can be configured to allow read operations to be routed to replicas by setting the replicaReadEnabled option on the MapSet to true. The default setting is false.
Enable reading of replicas can improve performance by spreading read requests to more JVMs. If the option is not enabled, all read requests such as the ObjectMap.get or the Query.getResultIterator methods are routed to the primary. When replicaReadEnabled is set to true, some get requests might return stale data, so an application using this option must be able to tolerate this possibility. However, a cache miss will not occur. If the data is not on the replica, the get request is redirected to the primary and tried again.
The replicaReadEnabled option can be used with both synchronous and asynchronous replication.
Load balancing across replicas
Load balancing across replicas is typically used only when clients are caching data that is changing all the time or when the clients are using pessimistic locking .
The WXS, unless configured otherwise, sends all read and write requests to the primary server for a given replication group. The primary must service all requests from clients. You might want to allow read requests to be sent to replicas of the primary. Sending read requests to the replicas allows the load of the read requests to be shared by multiple JVM. However, using replicas for read requests can result in inconsistent responses.
Load balancing across replicas is typically used only when clients are caching data that is changing all the time or when the clients are using pessimistic locking .
If the data is continually changing and then being invalidated in client near caches, the primary should see a relatively high get request rate from clients as a result. Likewise, in pessimistic locking mode, no local cache exists, so all requests are sent to the primary.
If the data is relatively static or if pessimistic mode is not used, then sending read requests to the replica does not have a big impact on performance. The frequency of get requests from clients with caches that are full of data is not high.
When a client first starts, its near cache is empty. Cache requests to the empty cache are forwarded to the primary. The client cache gets data over time, causing the request load to drop. If a large number of clients start concurrently, then the load might be significant and replica read might be an appropriate performance choice.
Shard lifecycles
Shards go through different states and events to support replication. The lifecycle of a shard includes coming online, run time, shut down, fail over and error handling. Shards can be promoted from a replica shard to a primary shard to handle server state changes.
Lifecycle events
When primary and replica shards are placed and started, they go through a series of events to bring themselves online and into listening mode.
Primary shard
The catalog service places a primary shard for a partition. The catalog service also does the work of balancing primary shard locations and initiating failover for primary shards.
When a shard becomes a primary shard, it receives a list of replicas from the catalog service. The new primary shard creates a replica group and registers all the replicas.
When the primary is ready, an open for business message displays in the SystemOut.log file for the container on which it is running. The open message, or the CWOBJ1511I message, lists the map name, map set name, and partition number of the primary shard that started.
- CWOBJ1511I: mapName:mapSetName:partitionNumber (primary) is open for business.
Replica shard
Replica shards are mainly controlled by the primary shard unless the replica shard detects a problem. During a normal lifecycle, the primary shard places, registers, and de-registers a replica shard.
When the primary shard initializes a replica shard, a message displays the log that describes where the replica runs to indicate that the replica shard is available. The open message, or the CWOBJ1511I message, lists the map name, map set name, and partition number of the replica shard. This message follows:
- CWOBJ1511I: mapName:mapSetName:partitionNumber (synchronous replica) is open for business.
...or...
- CWOBJ1511I: mapName:mapSetName:partitionNumber (asynchronous replica) is open for business.
Asynchronous replica shard
An asynchronous replica shard polls the primary for data. The replica automatically will adjust the poll timing if it does not receive data from the primary, which indicates that it is caught up with the primary. It also will adjust if it receives an error that might indicate that the primary has failed, or if there is a network problem.
When the asynchronous replica starts replicating, it prints the following message to the SystemOut.log file for the replica. This message might print more than one time per CWOBJ1511 message. It will print again if the replica connects to a different primary or if template maps are added.
CWOBJ1543I: The asynchronous replica objectGridName:mapsetName:partitionNumber started or continued replicating from the primary. Replicating for maps: [mapName]
Synchronous replica shard
When the synchronous replica shard first starts, it is not yet in peer mode. When a replica shard is in peer mode, it receives data from the primary as data comes into the primary. Before entering peer mode, the replica shard needs a copy of all of the existing data on the primary shard .
The synchronous replica copies data from the primary shard similar to an asynchronous replica by polling for data. When it copies the existing data from the primary, it switches to peer mode and begins to receive data as the primary receives the data.
When a replica shard reaches peer mode, it prints a message to the SystemOut.log file for the replica. The time refers to the amount of time that it took the replica shard to get all of its initial data from the primary shard . The time might display as zero or very low if the primary shard does not have any existing data to replicate. This message may print more than one time per CWOBJ1511 message. It will print again if the replica connects to a different primary or if template maps are added.
- CWOBJ1526I: Replica objectGridName:mapsetName:partitionNumber:mapName entering peer mode after X seconds.
When the synchronous replica shard is in peer mode, the primary shard must replicate transactions to all peer mode synchronous replicas. The synchronous replica shard data remains at the same level as the primary shard data. If a minimum number of synchronous replicas or minSync is set in the deployment policy, that number of synchronous replicas must vote to commit before the transaction can successfully commit on the primary.
Recovery events
Replication is designed to recover from failure and error events. If a primary shard fails, another replica takes over. If errors are on the replica shards, the replica shard attempts to recover. The catalog service controls the placement and transactions of new primary shards or new replica shards.
Replica shard becomes a primary shard
A replica shard becomes a primary shard for two reasons. Either the primary shard stopped or failed, or a balance decision was made to move the previous primary shard to a new location.
The catalog service selects a new primary shard from the existing synchronous replica shards. If a primary move needs to take place and there are no replicas, a temporary replica will be placed to complete the transition. The new primary shard registers all of the existing replicas and accepts transactions as the new primary shard . If the existing replica shards have the correct level of data, the current data is preserved as the replica shards register with the new primary shard. Asynchronous replicas will poll against the new primary.
Figure 1. Example placement of an ObjectGrid map set for the partition0 partition. The deployment policy has a minSyncReplicas value of 1, a maxSyncReplicas value of 2, and a maxAsyncReplicas value of 1.

Figure 2. The container for the primary shard fails

Figure 3. The synchronous replica shard on ObjectGrid container 2 becomes the primary shard

Figure 4. Machine B contains the primary shard . Depending on how automatic repair mode is set and the availability of the containers, a new synchronous replica shard might or might not be placed on a machine.
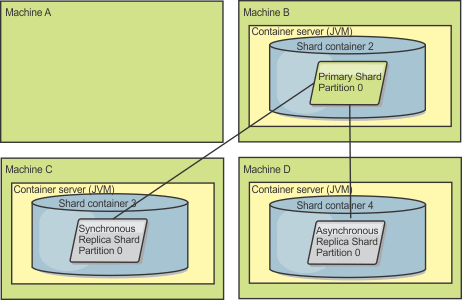
Replica shard recovery
A synchronous replica shard is controlled by the primary shard . However, if a replica shard detects a problem, it can trigger a reregister event to correct the state of the data. The replica clears the current data and gets a fresh copy from the primary.
When a replica shard initiates a reregister event, the replica prints a log message.
-
CWOBJ1524I: Replica listener objectGridName:mapSetName:partition must re-register with the primary. Reason: Exception listed
If a transaction causes an error on a replica shard during processing, then the replica shard is in an unknown state. The transaction successfully processed on the primary shard, but something went wrong on the replica. To correct this situation, the replica initiates a reregister event. With a new copy of data from the primary, the replica shard can continue. If the same problem reoccurs, the replica shard does not continuously reregister.
Failure events
A replica can stop replicating data if it encounters error situations for which the replica cannot recover.
Too many register attempts
If a replica triggers a reregister multiple times without successfully committing data, the replica stops. Stopping prevents a replica from entering an endless reregister loop. By default, a replica shard tries to reregister three times in a row before stopping.
If a replica shard reregisters too many times, it prints the following message to the log.
- CWOBJ1537E: objectGridName:mapSetName:partition exceeded the maximum number
of times to reregister (timesAllowed) without successful transactions..
If the replica is unable to recover by reregistering, a pervasive problem might exist with the transactions that are relative to the replica shard. A possible problem could be missing resources on the classpath if an error occurs while inflating the keys or values from the transaction.
Failure while entering peer mode
If a replica attempts to enter peer mode and experiences an error processing the bulk existing data from the primary (the checkpoint data), the replica shuts down. Shutting down prevents a replica from starting with incorrect initial data. Because it receives the same data from the primary if it reregisters, the replica does not retry.
If a replica shard fails to enter peer mode, it prints the following message to the log:
CWOBJ1527W Replica objectGridName:mapSetName:partition:mapName failed to enter peer mode after numSeconds seconds.An additional message displays in the log that explains why the replica failed to enter peer mode.
Recovery after re-register or peer mode failure
If a replica fails to re-register or enter peer mode, the replica is in an inactive state until a new placement event occurs. A new placement event might be a new server starting or stopping. We can also start a placement event using the triggerPlacement method on the PlacementServiceMBean Mbean.
Map sets for replication
Replication is enabled by associating BackingMaps with a map set.
A map set is a collection of maps that are categorized by partition-key. This partition-key is derived from the individual map's key by taking its hash modulo the number of partitions. If one group of maps within the map set has partition-key X, those maps will be stored in a corresponding partition X in the data grid. If another group has partition-key Y, all of the maps will be stored in partition Y, and so on. Also, the data within the maps is replicated based on the policy defined on the map set, which is only used for distributed WXS topologies (unnecessary for local instances).
Map sets are assigned what number of partitions they will have and a replication policy. The map set replication configuration simply identifies the number of synchronous and asynchronous replica shards a map set should have in addition to the primary shard . If there is to be 1 synchronous and 1 asynchronous replica, all of the BackingMaps assigned to the map set will each have a replica shard distributed automatically within the set of available containers for the WXS. The replication configuration can also enable clients to read data from synchronously replicated servers. This can spread the load for read requests over additional servers in the WXS.
Replication only has a programming model impact when preloading the BackingMaps.
Transaction processing
WXS uses transactions as its mechanism for interaction with data.
To interact with data, the thread in the application needs its own session. To obtain a session, call...
- ObjectGrid.getSession
With the session, the application can work with data that is stored in the ObjectGrid maps.
A transaction begins and commits or begins and rolls back using the begin, commit, and rollback methods on the Session object. Applications can also work in auto-commit mode, in which the Session automatically begins and commits a transaction whenever an operation is performed on the map. Auto-commit mode cannot group multiple operations into a single transaction, so it is the slower option for grouping multiple operations into a single transaction. However, for transactions that contain only one operation, auto-commit is faster.
When the application is finished with the Session, use the optional Session.close() method to close the session. Closing the Session releases it from the heap and allows subsequent calls to the getSession() method to be reused, improving performance.
Transactions
Use transactions to...
- Protect the data grid from concurrent changes
- Apply multiple changes as a concurrent unit
- Replicate data
- Implement a lifecycle for locks on changes
When a transaction starts, WXS allocates a difference map to hold copies of key/value pairs used by the transaction. The difference map tracks changes for operations such as insert, update, get, remove, and so on. If an ObjectTransformer object is specified, this object is used for copying the value. If the transaction is using optimistic locking, then "before" images of the values are tracked for comparison when the transaction commits.
If a transaction is rolled back, the difference map information is discarded, and locks on entries are released. When a transaction commits, the changes are applied to the maps and locks are released. If optimistic locking is being used, then WXS compares the before image versions of the values with the values that are in the map. These values must match for the transaction to commit. This comparison enables a multiple version locking scheme, but at a cost of two copies being made when the transaction accesses the entry. All values are copied again and the new copy is stored in the map. WXS performs this copy to protect itself against the application changing the application reference to the value after a commit.
We can avoid using several copies of the information. The application can save a copy by using pessimistic locking instead of optimistic locking as the cost of limiting concurrency. The copy of the value at commit time can also be avoided if the application agrees not to change a value after a commit.
Advantages of transactions
By using transactions, we can:
- Roll back changes if an exception occurs or business logic needs to undo state changes.
- To apply multiple changes as an atomic unit at commit time.
- Hold and release locks on data to apply multiple changes as an atomic unit at commit time.
- Protect a thread from concurrent changes.
- Implement a lifecycle for locks on changes.
- Produce an atomic unit of replication.
Transaction size
Larger transactions are more efficient, especially for replication. However, larger transactions can adversely impact concurrency because the locks on entries are held for a longer period of time. If you use larger transactions, we can increase replication performance. This performance increase is important when we are pre-loading a Map. Experiment with different batch sizes to determine what works best for your scenario.Larger transactions also help with loaders. If a loader is being used that can perform SQL batching, then significant performance gains are possible depending on the transaction and significant load reductions on the database side. This performance gain depends on the Loader implementation.
Automatic commit mode
If no transaction is actively started, then when an application interacts with an ObjectMap object, an automatic begin and commit operation is done on behalf of the application. This automatic begin and commit operation works, but prevents rollback and locking from working effectively. Synchronous replication speed is impacted because of the very small transaction size. If we are using an entity manager application, then do not use automatic commit mode because objects that are looked up with the EntityManager.find method immediately become unmanaged on the method return and become unusable.
External transaction coordinators
Typically, transactions begin with the session.begin method and end with the session.commit method. However, when WXS is embedded, the transactions might be started and ended by an external transaction coordinator. If we are using an external transaction coordinator, you do not need to call the session.begin method and end with the session.commit method. If we are using WebSphere Application Server, we can use the WebSphereTranscationCallback plug-in.
Java EE transaction integration
WXS includes a Java Connector Architecture (JCA) 1.5 compliant resource adapter that supports both client connections to a remote data grid and local transaction management. JEE (Java EE) applications such as servlets, JavaServer Pages (JSP) files and Enterprise JavaBeans (EJB) components can demarcate WXS transactions using the standard javax.resource.cci.LocalTransaction interface or the WXS session interface.When the running in WebSphere Application Server with last participant support enabled in the application, we can enlist the WXS transaction in a global transaction with other two-phase commit transactional resources.
Transaction processing in Java EE applications
WXS provides its own resource adapter that we can use to connect applications to the data grid and process local transactions.
Through support from the WXS resource adapter, Java EE applications can look up WXS client connections and demarcate local transactions using Java EE local transactions or using the WXS APIs. When the resource adapter is configured, we can complete the following actions with your Java EE applications:
- Look up or inject WXS resource adapter connection factories within a Java EE application component.
- Obtain standard connection handles to the WXS client and share them between application components using Java EE conventions.
- Demarcate WXS transactions using either...
- javax.resource.cci.LocalTransaction API
- com.ibm.websphere.objectgrid.Session
- Use the entire WXS client API, such as the ObjectMap API and EntityManager API.
The following additional capabilities are available with WebSphere Application Server:
- Enlist WXS connections with a global transaction as a last participant with other two-phase commit resources. The WXS resource adapter provides local transaction support, with a single-phase commit resource. With WebSphere Application Server, the applications can enlist one, single-phase commit resource into a global transaction through last participant support.
- Automatic resource adapter installation when the profile is augmented.
- Automatic security principal propagation.
Administrator responsibilities
The WXS resource adapter is installed into the Java EE application server or embedded with the application. After you install the resource adapter, the administrator creates one or more resource adapter connection factories for each catalog service domain and optionally each data grid instance. The connection factory identifies the properties that are required to communicate with the data grid.
Applications reference the connection factory, which establishes the connection to the remote data grid. Each connection factory hosts a single WXS client connection that is reused for all application components.
Because the WXS client connection might include a near cache, applications must not share a connection. A connection factory must exist for a single application instance to avoid problems sharing objects between applications.
The connection factory hosts a WXS client connection, which is shared between all referencing application components. Use a managed bean (MBean) to access information about the client connection or to reset the connection when it is no longer needed.
Application developer responsibilities
An application developer creates resource references for managed connection factories in the application deployment descriptor or with annotations. Each resource reference includes a local reference for the WXS connection factory, as well as the resource-sharing scope.
Enabling resource sharing is important because it allows the local transaction to be shared between application components.
Applications can inject the connection factory into the Java EE application component, or it can look up the connection factory using Java Naming Directory Interface (JNDI). The connection factory is used to obtain connection handles to the WXS client connection.
The eXtreme Scale client connection is managed independently from the resource adapter connection and is established on first use, and reused for all subsequent connections.
After finding the connection, the application retrieves a WXS session reference. With the WXS session reference, the application can use the entire eXtreme Scale client APIs and features.
We can demarcate transactions in one of the following ways:
- Use the com.ibm.websphere.objectgrid.Session transaction demarcation methods.
- Use the javax.resource.cci.LocalTransaction local transaction.
- Use a global transaction, when you use WebSphere Application Server with last participant support enabled. When you select this approach for demarcation, you must:
- Use an application-managed global transaction with the javax.transaction.UserTransaction.
- Use a container-managed transaction.
Application deployer responsibilities
The application deployer binds the local reference to the resource adapter connection factory that the application developer defines to the resource adapter connection factories that the administrator defines. The application deployer must assign the correct connection factory type and scope to the application and ensure that the connection factory is not shared between applications to avoid Java object sharing. The application deployer is also responsible for configuring and mapping other appropriate configuration information that is common to all connection factories.
CopyMode attribute
We can tune the number of copies by defining the CopyMode attribute of the BackingMap or ObjectMap objects. The copy mode has the following values:
- COPY_ON_READ_AND_COMMIT
- COPY_ON_READ
- NO_COPY
- COPY_ON_WRITE
- COPY_TO_BYTES
- COPY_TO_BYTES_RAW
The COPY_ON_READ_AND_COMMIT value is the default. The COPY_ON_READ value copies on the initial data retrieved, but does not copy at commit time. This mode is safe if the application does not modify a value after committing a transaction. The NO_COPY value does not copy data, which is only safe for read-only data. If the data never changes then you do not need to copy it for isolation reasons.
Be careful when you use the NO_COPY attribute value with maps that can be updated. WXS uses the copy on first touch to allow the transaction rollback. The application only changed the copy, and as a result, eXtreme Scale discards the copy. If the NO_COPY attribute value is used, and the application modifies the committed value, completing a rollback is not possible. Modifying the committed value leads to problems with indexes, replication, and so on because the indexes and replicas update when the transaction commits. If you modify committed data and then roll back the transaction, which does not actually roll back at all, then the indexes are not updated and replication does not take place. Other threads can see the uncommitted changes immediately, even if they have locks. Use the NO_COPY attribute value for read-only maps or for applications that complete the appropriate copy before modifying the value. If you use the NO_COPY attribute value and call IBM support with a data integrity problem, we are asked to reproduce the problem with the copy mode set to COPY_ON_READ_AND_COMMIT.
The COPY_TO_BYTES value stores values in the map in a serialized form. At read time, eXtreme Scale inflates the value from a serialized form and at commit time it stores the value to a serialized form. With this method, a copy occurs at both read and commit time.
Restriction:
When you use optimistic locking with COPY_TO_BYTES, you might experience ClassNotFoundException exceptions during common operations, such as invalidating cache entries.
These exceptions occur because the optimistic locking mechanism must call the "equals(...)" method of the cache object to detect any changes before the transaction is committed. To call the equals(...) method, the WXS server must be able to deserialize the cached object, which means that eXtreme Scale must load the object class.
To resolve these exceptions, we can package the cached object classes so that the WXS server can load the classes in stand-alone environments. Therefore, you must put the classes in the classpath.
If your environment includes the OSGi framework, then package the classes into a fragment of the objectgrid.jar bundle. If we are running eXtreme Scale servers in the Liberty profile, package the classes as an OSGi bundle, and export the Java packages for those classes. Then, install the bundle by copying it into the grids directory.
In WebSphere Application Server, package the classes in the application or in a shared library that the application can access.
Alternatively, we can use custom serializers that can compare the byte arrays that are stored in eXtreme Scale to detect any changes.
The default copy mode for a map can be configured on the BackingMap object. We can also change the copy mode on maps before you start a transaction using the ObjectMap.setCopyMode method.
An example of a backing map snippet from an objectgrid.xml file that shows how to set the copy mode for a given backing map follows. This example assumes that we are using cc as the objectgrid/config namespace.
<cc:backingMap name="RuntimeLifespan" copyMode="NO_COPY"/>
Lock manager
When you configure a locking strategy, a lock manager is created for the backing map to maintain cache entry consistency.
Lock manager configuration
When either a PESSIMISTIC or an OPTIMISTIC lock strategy is used, a lock manager is created for the BackingMap. The lock manager uses a hash map to track entries that are locked by one or more transactions. If many map entries exist in the hash map, more lock buckets can result in better performance. The risk of Java synchronization collisions is lower as the number of buckets grows. More lock buckets also lead to more concurrency. The previous examples show how an application can set the number of lock buckets to use for a given BackingMap instance.
To avoid a java.lang.IllegalStateException exception, the setNumberOfLockBuckets method must be called before calling the initialize or getSession methods on the ObjectGrid instance. The setNumberOfLockBuckets method parameter is a Java primitive integer that specifies the number of lock buckets to use. Using a prime number can allow for a uniform distribution of map entries over the lock buckets. A good starting point for best performance is to set the number of lock buckets to about 10 percent of the expected number of BackingMap entries.
Locking strategies
Locking strategies include pessimistic, optimistic and none. To choose a locking strategy, you must consider issues such as the percentage of each type of operations you have, whether or not you use a loader and so on.
Locks are bound by transactions. We can specify the following locking settings:
- No locking: Running without the locking setting is the fastest. If we are using read-only data, then you might not need locking.
- Pessimistic locking: Acquires locks on entries, then and holds the locks until commit time. This locking strategy provides good consistency at the expense of throughput.
- Optimistic locking: Takes a before image of every record that the transaction touches and compares the image to the current entry values when the transaction commits. If the entry values change, then the transaction rolls back. No locks are held until commit time. This locking strategy provides better concurrency than the pessimistic strategy, at the risk of the transaction rolling back and the memory cost of making the extra copy of the entry.
Set the locking strategy on the BackingMap. We cannot change the locking strategy for each transaction. An example XML snippet that shows how to set the locking mode on a map using the XML file follows, assuming
cc is the namespace for the objectgrid/config namespace:
<cc:backingMap name="RuntimeLifespan" lockStrategy="PESSIMISTIC" />
Pessimistic locking
When an ObjectGrid map is configured to use the pessimistic locking strategy, a pessimistic transaction lock for a map entry is obtained when a transaction first gets the entry from the BackingMap. The pessimistic lock is held until the application completes the transaction. Typically, the pessimistic locking strategy is used in the following situations:
- BackingMap is configured, with or without a loader, and versioning information is not available.
- BackingMap is used directly by an application that needs help from the WXS for concurrency control.
- Versioning information is available, but update transactions frequently collide on the backing entries, resulting in optimistic update failures.
Because the pessimistic locking strategy has the greatest impact on performance and scalability, this strategy should only be used for read and write maps when other locking strategies are not viable. For example, these situations might include when optimistic update failures occur frequently, or when recovery from optimistic failure is difficult for an application to handle.
When using pessimistic locking, we can use the lock method to lock data, or keys, without returning any data values. With the lock method, we can lock the key in the grid or lock the key and determine whether the value exists in the grid. In previous releases, you used the get and getForUpdate APIs to lock keys in the data grid. However, if you did not need data from the client, performance is degraded retrieving potentially large value objects to the client. Additionally, containsKey does not currently hold any locks, so you were forced do use get and getForUpdate to get appropriate locks when using pessimistic locking.
The lock API now gives you a containsKey semantics while holding the lock.
- boolean ObjectMap.lock(Object key, LockMode lockMode);
Locks the key in the map, returning true if the key exists, and returning false if the key does not exist.
- List<Boolean> ObjectMap.lockAll(List keys, LockMode lockMode);
Locks a list of keys in the map, returning a list of true or false values; returning true if the key exists, and returning false if the key does not exist.
LockMode is an enum with possible values SHARED, UPGRADABLE, and EXCLUSIVE, where we can specify the keys to lock. See the following table to understand the relationship between these lock mode values and the behavior of existing methods:
LockMode values and existing method equivalents...
| Lock mode | Method equivalent |
|---|---|
| SHARED | get() |
| UPGRADABLE | getForUpdate() |
| EXCLUSIVE | getNextKey() and commit() |
See the following example code of the LockMode parameter:
session.begin(); map.lock(key, LockMode.UPGRADABLE); map.upsert(); session.commit()
Optimistic locking
The optimistic locking strategy assumes that no two transactions might attempt to update the same map entry while running concurrently. Because of this belief, the lock mode does not need to be held for the life cycle of the transaction because it is unlikely that more than one transaction might update the map entry concurrently.
The optimistic locking strategy is typically used in the following situations:
- A BackingMap is configured with or without a loader and versioning information is available.
- A BackingMap has mostly transactions that perform read operations. Insert, update, or remove operations on map entries do not occur often on the BackingMap.
- A BackingMap is inserted, updated, or removed more frequently than it is read, but transactions rarely collide on the same map entry.
Like the pessimistic locking strategy, the methods on the ObjectMap interface determine how eXtreme Scale automatically attempts to acquire a lock mode for the map entry that is being accessed. However, the following differences between the pessimistic and optimistic strategies exist:
- Like the pessimistic locking strategy, an S lock mode is acquired by the get and getAll methods when the method is invoked. However, with optimistic locking, the S lock mode is not held until the transaction is completed. Instead, the S lock mode is released before the method returns to the application. The purpose of acquiring the lock mode is so that eXtreme Scale can ensure that only committed data from other transactions is visible to the current transaction. After eXtreme Scale has verified that the data is committed, the S lock mode is released. At commit time, an optimistic versioning check is performed to ensure that no other transaction has changed the map entry after the current transaction released its S lock mode. If an entry is not fetched from the map before it is updated, invalidated, or deleted, the WXS run time implicitly fetches the entry from the map. This implicit get operation is performed to get the current value at the time the entry was requested to be modified.
- Unlike pessimistic locking strategy, the getForUpdate and getAllForUpdate methods are handled exactly like the get and getAll methods when the optimistic locking strategy is used. That is, an S lock mode is acquired at the start of the method and the S lock mode is released before returning to the application.
All other ObjectMap methods are handled exactly like they are handled for the pessimistic locking strategy. That is, when the commit method is invoked, an X lock mode is obtained for any map entry that is inserted, updated, removed, touched, or invalidated and the X lock mode is held until the transaction completes commit processing. The optimistic locking strategy assumes that no concurrently running transactions attempt to update the same map entry. Because of this assumption, the lock mode does not need to be held for the life of the transaction because it is unlikely that more than one transaction might update the map entry concurrently. However, because a lock mode was not held, another concurrent transaction might potentially update the map entry after the current transaction has released its S lock mode.
To handle this possibility, eXtreme Scale gets an X lock at commit time and performs an optimistic versioning check to verify that no other transaction has changed the map entry after the current transaction read the map entry from the BackingMap. If another transaction changes the map entry, the version check fails and an OptimisticCollisionException exception occurs. This exception forces the current transaction to be rolled back and the application must try the entire transaction again. The optimistic locking strategy is very useful when a map is mostly read and it is unlikely that updates for the same map entry might occur.
Restriction:
When you use optimistic locking with COPY_TO_BYTES, you might experience ClassNotFoundException exceptions during common operations, such as invalidating cache entries. These exceptions occur because the optimistic locking mechanism must call the "equals(...)" method of the cache object to detect any changes before the transaction is committed.
To call the equals(...) method, the WXS server must be able to deserialize the cached object, which means that eXtreme Scale must load the object class.
To resolve these exceptions, we can package the cached object classes so that the WXS server can load the classes in stand-alone environments. Therefore, you must put the classes in the classpath.
If your environment includes the OSGi framework, then package the classes into a fragment of the objectgrid.jar bundle. If we are running eXtreme Scale servers in the Liberty profile, package the classes as an OSGi bundle, and export the Java packages for those classes. Then, install the bundle by copying it into the grids directory.
In WebSphere Application Server, package the classes in the application or in a shared library that the application can access.
Alternatively, we can use custom serializers that can compare the byte arrays that are stored in eXtreme Scale to detect any changes.
No locking
When a BackingMap is configured to use no locking strategy, no transaction locks for a map entry are obtained. BackingMaps configured to use a no locking strategy cannot participate in a multi-partition transaction.Use no locking strategy is useful when an application is a persistence manager such as an Enterprise JavaBeans (EJB) container or when an application uses Hibernate to obtain persistent data. In this scenario, the BackingMap is configured without a loader and the persistence manager uses the BackingMap as a data cache. In this scenario, the persistence manager provides concurrency control between transactions that are accessing the same Map entries.
WXS does not need to obtain any transaction locks for the purpose of concurrency control. This situation assumes that the persistence manager does not release its transaction locks before updating the ObjectGrid map with committed changes. If the persistence manager releases its locks, then a pessimistic or optimistic lock strategy must be used. For example, suppose that the persistence manager of an EJB container is updating an ObjectGrid map with data that was committed in the EJB container-managed transaction. If the update of the ObjectGrid map occurs before the persistence manager transaction locks are released, then we can use the no lock strategy. If the ObjectGrid map update occurs after the persistence manager transaction locks are released, then use either the optimistic or pessimistic lock strategy.
Another scenario where no locking strategy can be used is when the application uses a BackingMap directly and a Loader is configured for the map. In this scenario, the loader uses the concurrency control support that is provided by a relational database management system (RDBMS) by using either...
- JDBC
- Hibernate
...to access data in a relational database. The loader implementation can use either an optimistic or pessimistic approach. A loader that uses an optimistic locking or versioning approach helps to achieve the greatest amount of concurrency and performance. See OptimisticCallback
If we are using a loader that uses pessimistic locking support of an underlying backend, you might want to use the forUpdate parameter that is passed on the get method of the Loader interface. Set this parameter to true if the getForUpdate method of the ObjectMap interface was used by the application to get the data. The loader can use this parameter to determine whether to request an upgradeable lock on the row that is being read. For example, DB2 obtains an upgradeable lock when an SQL select statement contains a FOR UPDATE clause. This approach offers the same deadlock prevention that is described in Pessimistic locking.
Distributing transactions
Use Java Message Service (JMS) for distributed transaction changes between different tiers or in environments on mixed platforms.
JMS is an ideal protocol for distributed changes between different tiers or in environments on mixed platforms. For example, some applications that use eXtreme Scale might be deployed on IBM WebSphere Application Server Community Edition, Apache Geronimo, or Apache Tomcat, whereas other applications might run on WebSphere Application Server Version 6.x. JMS is ideal for distributed changes between eXtreme Scale peers in these different environments. The high availability manager message transport is very fast, but can only distribute changes to JVMs that are in a single core group. JMS is slower, but allows larger and more diverse sets of application clients to share an ObjectGrid. JMS is ideal when sharing data in an ObjectGrid between a fat Swing client and an application deployed on WebSphere Extended Deployment.
The built-in Client Invalidation Mechanism and Peer-to-Peer Replication are examples of JMS-based transactional changes distribution.
Implementing JMS
JMS is implemented for distributing transaction changes by using a Java object that behaves as an ObjectGridEventListener. This object can propagate the state in the following four ways:
| Invalidate | Any entry that is evicted, updated or deleted is removed on all peer JVMs when they receive the message. |
| Invalidate conditional | The entry is evicted only if the local version is the same or older than the version on the publisher. |
| Push | Any entry that was evicted, updated, deleted or inserted is added or overwritten on all peer JVMs when they receive the JMS message. |
| Push conditional | The entry is only updated or added on the receive side if the local entry is less recent than the version that is being published. |
Listen for changes for publishing
The plug-in implements the ObjectGridEventListener interface to intercept the transactionEnd event. When eXtreme Scale invokes this method, the plug-in attempts to convert the LogSequence list for each map that is touched by the transaction to a JMS message and then publish it. The plug-in can be configured to publish changes for all maps or a subset of maps. LogSequence objects are processed for the maps that have publishing enabled. The LogSequenceTransformer ObjectGrid class serializes a filtered LogSequence for each map to a stream. After all LogSequences are serialized to the stream, then a JMS ObjectMessage is created and published to a well-known topic.
Listen for JMS messages and apply them to the local ObjectGrid
The same plug-in also starts a thread that spins in a loop, receiving all messages that are published to the well known topic. When a message arrives, it passes the message contents to the LogSequenceTransformer class where it is converted to a set of LogSequence objects. Then, a no-write-through transaction is started. Each LogSequence object is provided to the Session.processLogSequence method, which updates the local Maps with the changes. The processLogSequence method understands the distribution mode. The transaction is committed and the local cache now reflects the changes.
Develop applications that update multiple partitions in a single transaction
If your data is distributed across multiple partitions in the data grid, we can read and update several partitions in a single transaction. This type of transaction is called a multi-partition transaction and uses the two-phase commit protocol to coordinate and recover the transaction in case of failure.
Security overview
WXS can secure data access, including allowing for integration with external security providers.
In an existing non-cached data store such as a database, you likely have built-in security features that you might not need to actively configure or enable. However, after you have cached your data with WXS, you must consider the important resulting situation that your backend security features are no longer in effect. We can configureeXtreme Scale security on necessary levels so that your new cached architecture for your data is also secured. A brief summary of eXtreme Scale security features follows. For more detailed information about configuring security see the Administration Guide and the Programming Guide.
Distributed security basics
Distributed eXtreme Scale security is based on three key concepts:
| Trustable authentication | Determine the identity of the requester. WXS supports both client-to-server and server-to-server authentication. |
| Authorization | Give permissions to grant access rights to the requester. WXS supports different authorizations for various operations. |
| Secure transport | Safe transmission of data over a network. WXS supports the Transport Layer Security/Secure Sockets Layer (TLS/SSL) protocols. |
Authentication
WXS supports a distributed client server framework. A client server security infrastructure is in place to secure access to WXS servers. For example, when authentication is required by the WXS server, a WXS client must provide credentials to authenticate to the server. These credentials can be a user name and password pair, a client certificate, a Kerberos ticket, or data that is presented in a format that is agreed upon by client and server.
Authorization
WXS authorizations are based on subjects and permissions. Use the Java Authentication and Authorization Services (JAAS) to authorize the access, or we can plug in a custom approach, such as Tivoli Access Manager (TAM), to handle the authorizations. The following authorizations can be given to a client or group:
| Map authorization | Perform insert, read, update, evict, or delete operations on Maps. |
| ObjectGrid authorization | Perform object or entity queries on ObjectGrid objects. |
| DataGrid agent authorization | Allow DataGrid agents to be deployed to an ObjectGrid. |
| Server side map authorization | Replicate a server map to client side or create a dynamic index to the server map. |
| Administration authorization | Perform administration tasks. |
Transport security
To secure the client server communication, WXS supports TLS/SSL. These protocols provide transport layer security with authenticity, integrity, and confidentiality for a secure connection between a WXS client and server.
Grid security
In a secure environment, a server must be able to check the authenticity of another server. WXS uses a shared secret key string mechanism for this purpose. This secret key mechanism is similar to a shared password. All the WXS servers agree on a shared secret string. When a server joins the data grid, the server is challenged to present the secret string. If the secret string of the joining server matches the one in the master server, then the joining server can join the grid. Otherwise, the join request is rejected.
Sending a clear text secret is not secure. The eXtreme Scale security infrastructure provides a SecureTokenManager plug-in to allow the server to secure this secret before sending it. We can choose how you implement the secure operation. WXS provides an implementation, in which the secure operation is implemented to encrypt and sign the secret.
JMX security in a dynamic deployment topology
JMX MBean security is supported in all versions of eXtreme Scale. Clients of catalog server MBeans and container server MBeans can be authenticated, and access to MBean operations can be enforced.
Local eXtreme Scale security
Local eXtreme Scale security is different from the distributed eXtreme Scale model because the application directly instantiates and uses an ObjectGrid instance. Your application and eXtreme Scale instances are in the same JVM. Because no client-server concept exists in this model, authentication is not supported. Your applications must manage their own authentication, and then pass the authenticated Subject object to the WXS. However, the authorization mechanism used for the local eXtreme Scale programming model is the same as what is used for the client-server model.REST data services overview
The WXS REST data service is a Java HTTP service that is compatible with Microsoft WCF Data Services (formally ADO.NET Data Services) and implements the Open Data Protocol (OData). Microsoft WCF Data Services is compatible with this specification when using Visual Studio 2008 SP1 and the .NET Framework 3.5 SP1.
Compatibility requirements
The REST data service allows any HTTP client to access a data grid. The REST data service is compatible with the WCF Data Services support supplied with the Microsoft .NET Framework 3.5 SP1. RESTful applications can be developed with the rich tooling provided by Microsoft Visual Studio 2008 SP1.
Microsoft WCF Data Services
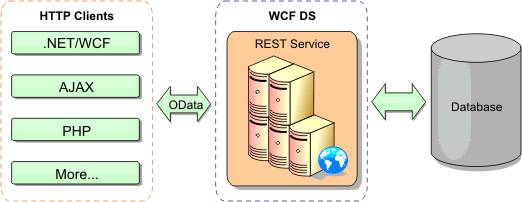
WXS includes a function-rich API set for Java clients. As shown in the following figure, the REST data service is a gateway between HTTP clients and the WXS data grid, communicating with the grid through an WXS client. The REST data service is a Java servlet, which allows flexible deployments for common JEE (JEE) platforms, such as WebSphere Application Server. The REST data service communicates with the WXS data grid using the WXS Java APIs. It allows WCF Data Services clients or any other client that can communicate with HTTP and XML.
Figure 2. WXS REST data service
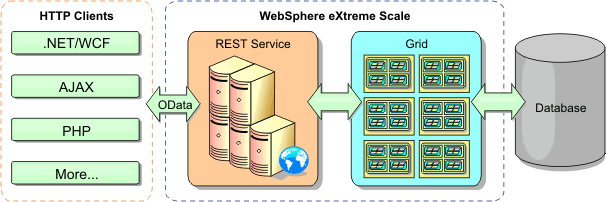
Features
This version of the WXS REST data service supports the following features:
- Automatic modeling of eXtreme Scale EntityManager API entities as WCF Data Services entities, which includes the following support:
- Java data type to Entity Data Model type conversion
- Entity association support
- Schema root and key association support, which is required for partitioned data grids
- Atom Publish Protocol (AtomPub or APP) XML and JavaScript Object Notation (JSON) data payload format.
- Create, Read, Update and Delete (CRUD) operations using the respective HTTP request methods: POST, GET, PUT and DELETE. In addition, the Microsoft extension: MERGE
is supported.
The upsert and upsertAll methods replace the ObjectMap put and putAll methods. Use the upsert method to tell the BackingMap and loader that an entry in the data grid needs to place the key and value into the grid. The BackingMap and loader does either an insert or an update to place the value into the grid and loader. If we run the upsert API within the applications, then the loader gets an UPSERT LogElement type, which allows loaders to do database merge or upsert calls instead of using insert or update.
- Simple queries, using filters
- Batch retrieval and change set requests
- Partitioned data grid support for high availability
- Interoperability with WXS EntityManager API clients
- Support for standard JEE Web servers
- Optimistic concurrency
- User authorization and authentication between the REST data service and the WXS data grid
Known problems and limitations
- Tunneled requests are not supported.