Plan - WebSphere eXtreme Scale v8.6
- Overview
- Local in-memory cache
- Peer-replicated local cache
- Embedded cache
- Distributed cache
- Database integration
- Multiple data center topologies
- Multimaster replication
- Configuration considerations for multi-master topologies
- Loader considerations in a multi-master topology
- Preload conundrum
- Sparse cache conundrum
- Invalidations and eviction
- Multiple writers to a single logical database
- Mirroring data using multi-master replication
- Design considerations for multi-master replication
- Interoperability with other products
- Supported APIs and configurations by client type
- Plan for network ports
- Container servers
- Clients
- Ports in WAS
- Plan to use IBM eXtremeMemory
- Security
- Microsoft .NET
- Java SE
- Java EE
- Directory conventions
- Plan environment capacity
- Plan to develop WXS applications
Overview
See also: Best practices for building high performing WebSphere eXtreme Scale applications .
Data capacity considerations
| Number of systems and processors | |
| Number of JVMs (containers) | |
| Number of partitions | |
| Number of replicas | |
| Synchronous or asynchronous replication | |
| Heap sizes | |
Installation considerations
We can install WebSphere eXtreme Scale in a stand-alone environment, or we can integrate the installation with WAS.
If we are not using the XC10 appliance, for the best performance, catalog servers should run on different machines than the container servers. To run catalog servers and container servers on the same machine, use separate installations of WXS. This allows us to upgrade installations running the catalog server first.
Plan the topology
With WXS, the architecture can use...
We can also configure the topology to span multiple data centers.
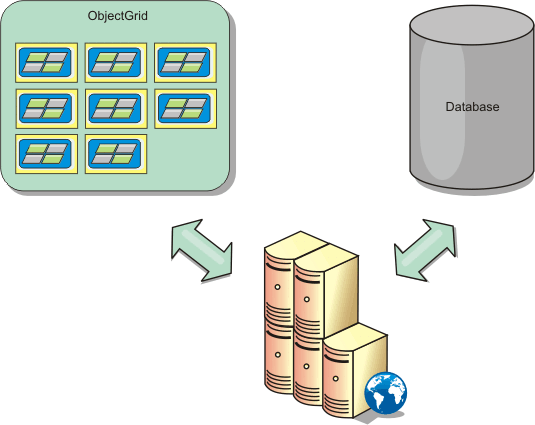
WXS requires minimal additional infrastructure to operate. The infrastructure consists of scripts to install, start, and stop a JEE application on a server. Cached data is stored in the container servers, and clients remotely connect to the server.
In-memory environments
When we deploy in a local, in-memory environment, WXS runs within a single JVM and is not replicated. To configure a local environment we can use an ObjectGrid XML file or the ObjectGrid APIs.
Distributed environments
When we deploy in a distributed environment, WXS runs across a set of JVMs, increasing the performance, availability and scalability. With this configuration, we can use data replication and partitioning . We can also add additional servers without restarting your existing eXtreme Scale servers. As with a local environment, an ObjectGrid XML file, or an equivalent programmatic configuration, is needed in a distributed environment. Also provide a deployment policy XML file with configuration details
We can create either simple deployments or large, terabyte-sized deployments in which thousands of servers are needed.
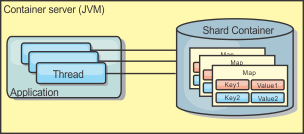
Local in-memory cache
In the simplest case, WXS can be used as a local (non-distributed) in-memory data grid cache. The local case can especially benefit high-concurrency applications where multiple threads need to access and modify transient data. The data kept in a local data grid can be indexed and retrieved using queries. Queries help you to work with large in memory data sets. The support provided with the Java virtual machine (JVM), although it is ready to use, has a limited data structure.
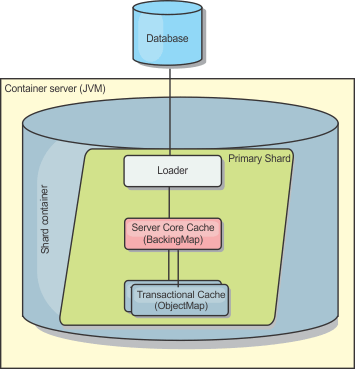
The local in-memory cache topology for WXS is used to provide consistent, transactional access to temporary data within a single JVM.
Advantages
| Simple setup | An ObjectGrid can be created programmatically or declaratively with the ObjectGrid deployment descriptor XML file or with other frameworks such as Spring. |
| Fast | Each BackingMap can be independently tuned for optimal memory utilization and concurrency. Ideal for single-JVM topologies with small dataset or for caching frequently accessed data. |
| Transactional | BackingMap updates can be grouped into a single unit of work and can be integrated as a last participant in 2-phase transactions such as JTA transactions. |
Disadvantages
- Not fault tolerant.
- The data is not replicated. In-memory caches are best for read-only reference data.
- Not scalable. The amount of memory required by the database might overwhelm the JVM.
- Problems occur when adding JVMs:
- Data cannot easily be partitioned
- Must manually replicate state between JVMs or each cache instance could have different versions of the same data.
- Invalidation is expensive.
- Each cache must be warmed up independently. The warm-up is the period of loading a set of data so that the cache gets populated with valid data.
When to use
The local, in-memory cache deployment topology should only be used when the amount of data to be cached is small (can fit into a single JVM) and is relatively stable. Stale data must be tolerated with this approach. Using evictors to keep most frequently or recently used data in the cache can help keep the cache size low and increase relevance of the data.
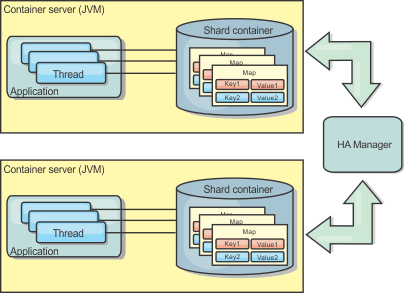
Peer-replicated local cache
Ensure the cache is synchronized if multiple processes with independent cache instances exist. To ensure that the cache instances are synchronized, enable a peer-replicated cache with Java Message Service (JMS).
WXS includes two plug-ins that automatically propagate transaction changes between peer ObjectGrid instances. The JMSObjectGridEventListener plug-in automatically propagates eXtreme Scale changes using JMS.

If we are running a WAS environment, the TranPropListener plug-in is also available. The TranPropListener plug-in uses the high availability (HA) manager to propagate the changes to each peer cache instance.
Figure 2. Peer-replicated cache with changes that are propagated with the high availability manager
Advantages
- The data is more valid because the data is updated more often.
- With the TranPropListener plug-in, like the local environment, the WXS can be created programmatically or declaratively with the WXS deployment descriptor XML file or with other frameworks such as Spring. Integration with the high availability manager is done automatically.
- Each BackingMap can be independently tuned for optimal memory utilization and concurrency.
- BackingMap updates can be grouped into a single unit of work and can be integrated as a last participant in 2-phase transactions such as JTA transactions.
- Ideal for few-JVM topologies with a reasonably small dataset or for caching frequently accessed data.
- Changes to the WXS are replicated to all peer eXtreme Scale instances. The changes are consistent as long as a durable subscription is used.
Disadvantages
- Configuration and maintenance for the JMSObjectGridEventListener can be complex. eXtreme Scale can be created programmatically or declaratively with the WXS deployment descriptor XML file or with other frameworks such as Spring.
- Not scalable: The amount of memory required by the database may overwhelm the JVM.
- Functions improperly when adding JVMs:
- Data cannot easily be partitioned
- Invalidation is expensive.
- Each cache must be warmed-up independently
When to use
Use deployment topology only when the amount of data to be cached is small, can fit into a single JVM, and is relatively stable.
Embedded cache
WXS grids can run within existing processes as embedded eXtreme Scale servers or we can manage them as external processes.
Embedded grids are useful when we are running in an application server, such as WAS. We can start eXtreme Scale servers that are not embedded by using command line scripts and run in a Java process.
Advantages
- Simplified administration since there are less processes to manage.
- Simplified application deployment since the grid is using the client application classloader.
- Supports partitioning and high availability.
Disadvantages
- Increased the memory footprint in client process since all of the data is collocated in the process.
- Increase CPU utilization for servicing client requests.
- More difficult to handle application upgrades since clients are using the same application Java archive files as the servers.
- Less flexible. Scaling of clients and grid servers cannot increase at the same rate. When servers are externally defined, we can have more flexibility in managing the number of processes.
When to use
Use embedded grids when there is plenty of memory free in the client process for grid data and potential failover data.
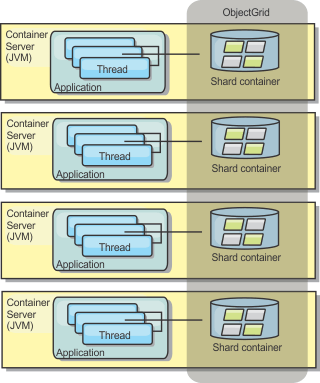
Distributed cache
WXS is most often used as a shared cache, to provide transactional access to data to multiple components where a traditional database would otherwise be used. The shared cache eliminates the need configure a database.
Coherency of the cache
The cache is coherent because all of the clients see the same data in the cache. Each piece of data is stored on exactly one server in the cache, preventing wasteful copies of records that could potentially contain different versions of the data. A coherent cache can also hold more data as more servers are added to the data grid, and scales linearly as the grid grows in size. Because clients access data from this data grid with remote procedural calls, it can also be known as a remote cache, or far cache. Through data partitioning, each process holds a unique subset of the total data set. Larger data grids can both hold more data and service more requests for that data. Coherency also eliminates the need to push invalidation data around the data grid because no stale data exists. The coherent cache only holds the latest copy of each piece of data.
If we are running a WAS environment, the TranPropListener plug-in is also available. The TranPropListener plug-in uses the high availability component (HA Manager) of WAS to propagate the changes to each peer ObjectGrid cache instance.

Near cache
Clients can optionally have a local, in-line cache when eXtreme Scale is used in a distributed topology. This optional cache is called a near cache, an independent ObjectGrid on each client, serving as a cache for the remote, server-side cache. The near cache is enabled by default when locking is configured as optimistic or none and cannot be used when configured as pessimistic.
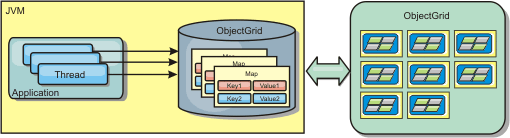
A near cache is very fast because it provides local in-memory access to a subset of the cached data normally stored remotely in the WXS servers. The near cache is not partitioned and contains data from any of the remote partitions.
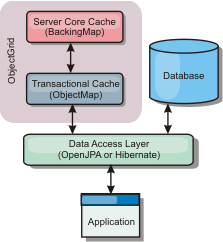
WXS can have up to three cache tiers...
- Transaction tier cache contains all changes for a single transaction.
The transaction cache contains a working copy of the data until the transaction is committed. When a client transaction requests data from an ObjectMap, the transaction is checked first.
- Near cache in the client tier contains a subset of the data from the server tier.
When the transaction tier does not have the data, the data is fetched from the client tier, if available and inserted into the transaction cache
- Data grid in the server tier contains the majority of the data and is shared among all clients.
The server tier can be partitioned, which allows a large amount of data to be cached. When the client near cache does not have the data, it is fetched from the server tier and inserted into the client cache. The server tier can also have a Loader plug-in. When the data grid does not have the requested data, the Loader is invoked and the resulting data is inserted from the backend data store into the grid.
Advantage
- Fast response time because all access to the data is local. Looking for the data in the near cache first saves a trip to the grid of servers, thus making even the remote data locally accessible.
Disadvantages
- Increases duration of stale data because the near cache at each tier may be out of synch with the current data in the data grid.
- Relies on an evictor to invalidate data to avoid running out of memory.
When to use
Use when response time is important and stale data can be tolerated.
Database integration: Write-behind, in-line, and side caching
WXS is used to front a traditional database and eliminate read activity normally pushed to the database. A coherent cache can be used with an application directly or indirectly using an object relational mapper. The coherent cache can then offload the database or backend from reads. In a slightly more complex scenario, such as transactional access to a data set where only some of the data requires traditional persistence guarantees, filtering can be used to offload even write transactions.
We can configure WXS to function as a highly flexible in-memory database processing space. However, WXS is not an object relational mapper (ORM). It does not know where the data in the data grid came from. An application or an ORM can place data in a WXS server.
It is the responsibility of the source of the data to make sure that it stays consistent with the database where data originated. This means eXtreme Scale cannot invalidate data that is pulled from a database automatically. The application or mapper must provide this function and manage the data stored in eXtreme Scale.
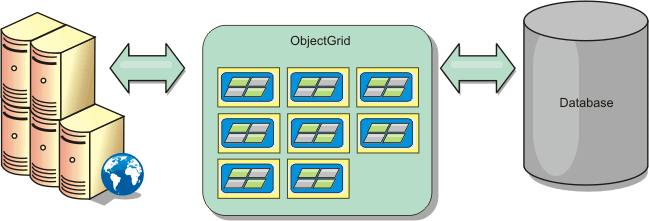
Figure 2. ObjectGrid as a side cache
Sparse and complete cache
WXS can be used as a sparse cache or a complete cache. A sparse cache only keeps a subset of the total data, while a complete cache keeps all of the data. and can be populated lazily, as the data is needed. Sparse caches are normally accessed using keys (instead of indexes or queries) because the data is only partially available.
Sparse cache
When a key is not present in a sparse cache, or the data is not available and a cache miss occurs, the next tier is invoked. The data is fetched, from a database for example, and is inserted into the data grid cache tier. If we are using a query or index, only the currently loaded values are accessed and the requests are not forwarded to the other tiers.
Complete cache
A complete cache contains all of the required data and can be accessed using non-key attributes with indexes or queries. A complete cache is preloaded with data from the database before the application tries to access the data. A complete cache can function as a database replacement after data is loaded. Because all of the data is available, queries and indexes can be used to find and aggregate data.
Side cache
When WXS is used as a side cache, the back end is used with the data grid.
We can configure the product as a side cache for the data access layer of an application. In this scenario, WXS is used to temporarily store objects that would normally be retrieved from a back-end database. Applications check to see if the data grid contains the data. If the data is in the data grid, the data is returned to the caller. If the data does not exist, the data is retrieved from the back-end database. The data is then inserted into the data grid so that the next request can use the cached copy. The following diagram illustrates how WXS can be used as a side-cache with an arbitrary data access layer such as OpenJPA or Hibernate.
Side cache plug-ins for Hibernate and OpenJPA
Cache plug-ins for both OpenJPA and Hibernate are included in WXS, so we can use the product as an automatic side-cache. Using WXS as a cache provider increases performance when reading and querying data and reduces load to the database. There are advantages that WXS has over built-in cache implementations because the cache is automatically replicated between all processes. When one client caches a value, all other clients can use the cached value.
In-line cache
We can configure in-line caching for a database back end or as a side cache for a database. In-line caching uses eXtreme Scale as the primary means for interacting with the data. When eXtreme Scale is used as an in-line cache, the application interacts with the back end using a Loader plug-in.
When used as an in-line cache, WXS interacts with the back end using a Loader plug-in. This scenario can simplify data access because applications can access the WXS APIs directly. Several different caching scenarios are supported in eXtreme Scale to make sure the data in the cache and the data in the back end are synchronized. The following diagram illustrates how an in-line cache interacts with the application and back end.

The in-line caching option simplifies data access because it allows applications to access the WXS APIs directly. WXS supports several in-line caching scenarios, as follows.
- Read-through
- Write-through
- Write-behind
Read-through caching scenario
A read-through cache is a sparse cache that lazily loads data entries by key as they are requested. This is done without requiring the caller to know how the entries are populated. If the data cannot be found in the WXS cache, eXtreme Scale will retrieve the missing data from the Loader plug-in, which loads the data from the back-end database and inserts the data into the cache. Subsequent requests for the same data key will be found in the cache until it is removed, invalidated or evicted.
Figure 2. Read-through caching

Write-through caching scenario
In a write-through cache, every write to the cache synchronously writes to the database using the Loader. This method provides consistency with the back end, but decreases write performance since the database operation is synchronous. Since the cache and database are both updated, subsequent reads for the same data will be found in the cache, avoiding the database call. A write-through cache is often used in conjunction with a read-through cache.
Figure 3. Write-through caching

Write-behind caching scenario
Database synchronization can be improved by writing changes asynchronously. This is known as a write-behind or write-back cache. Changes that would normally be written synchronously to the loader are instead buffered in eXtreme Scale and written to the database using a background thread. Write performance is significantly improved because the database operation is removed from the client transaction and the database writes can be compressed.
Figure 4. Write-behind caching
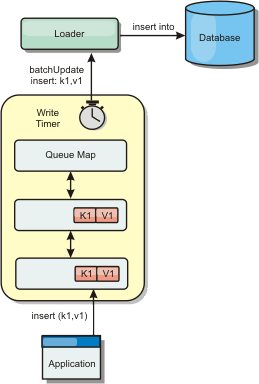
Write-behind caching
Use write-behind caching to reduce the overhead that occurs when updating a database we are using as a back end.
Write-behind caching asynchronously queues updates to the Loader plug-in. We can improve performance by disconnecting updates, inserts, and removes for a map, the overhead of updating the back-end database. The asynchronous update is performed after a time-based delay (for example, five minutes) or an entry-based delay (1000 entries).
The write-behind configuration on a BackingMap creates a thread between the loader and the map. The loader then delegates data requests through the thread according to the configuration settings in the BackingMap.setWriteBehind method. When a WXS transaction inserts, updates, or removes an entry from a map, a LogElement object is created for each of these records. These elements are sent to the write-behind loader and queued in a special ObjectMap called a queue map. Each backing map with the write-behind setting enabled has its own queue maps. A write-behind thread periodically removes the queued data from the queue maps and pushes them to the real back-end loader.
The write-behind loader only sends insert, update, and delete types of LogElement objects to the real loader. All other types of LogElement objects, for example, EVICT type, are ignored.
Write-behind support is an extension of the Loader plug-in, which you use to integrate eXtreme Scale with the database. For example, consult the Configuring JPA loaders information about configuring a JPA loader.
Benefits
Enabling write-behind support has the following benefits:
- Back end failure isolation: Write-behind caching provides an isolation layer from back end failures. When the back-end database fails, updates are queued in the queue map. The applications can continue driving transactions to WXS. When the back end recovers, the data in the queue map is pushed to the back-end.
- Reduced back end load: The write-behind loader merges the updates on a key basis so only one merged update per key exists in the queue map. This merge decreases the number of updates to the back-end database.
- Improved transaction performance: Individual eXtreme Scale transaction times are reduced because the transaction does not need to wait for the data to be synchronized with the back-end.
Loaders
With a Loader plug-in, a data grid map can behave as a memory cache for data that is typically kept in a persistent store on either the same system or another system. Typically, a database or file system is used as the persistent store. A remote Java virtual machine (JVM) can also be used as the source of data, allowing hub-based caches to be built using eXtreme Scale. A loader has the logic for reading and writing data to and from a persistent store.
Overview
Loaders are backing map plug-ins that are invoked when changes are made to the backing map or when the backing map is unable to satisfy a data request (a cache miss). The Loader is invoked when the cache is unable to satisfy a request for a key, providing read-through capability and lazy-population of the cache. A loader also allows updates to the database when cache values change. All changes within a transaction are grouped together to allow the number of database interactions to be minimized. A TransactionCallback plug-in is used in conjunction with the loader to trigger the demarcation of the backend transaction. Using this plug-in is important when multiple maps are included in a single transaction or when transaction data is flushed to the cache without committing.
The loader can also use overqualified updates to avoid keeping database locks. By storing a version attribute in the cache value, the loader can see the before and after image of the value as it is updated in the cache. This value can then be used when updating the database or back end to verify that the data has not been updated. A Loader can also be configured to preload the data grid when it is started. When partitioned, a Loader instance is associated with each partition. If the "Company" Map has ten partitions, there are ten Loader instances, one per primary partition. When the primary shard for the Map is activated, the preloadMap method for the loader is invoked synchronously or asynchronously which allows loading the map partition with data from the back-end to occur automatically. When invoked synchronously, all client transactions are blocked, preventing inconsistent access to the data grid. Alternatively, a client preloader can be used to load the entire data grid.
Two built-in loaders can greatly simplify integration with relational database back ends. The JPA loaders utilize the Object-Relational Mapping (ORM) capabilities of both the OpenJPA and Hibernate implementations of the JPA specification.
If we are using loaders in a multiple data center configuration, you must consider how revision data and cache consistency is maintained between the data grids.
Loader configuration
To add a Loader into the BackingMap configuration, we can use programmatic configuration or XML configuration. A loader has the following relationship with a backing map.
- A backing map can have only one loader.
- A client backing map (near cache ) cannot have a loader.
- A loader definition can be applied to multiple backing maps, but each backing map has its own loader instance.
Data pre-loading and warm-up
In many scenarios that incorporate the use of a loader, we can prepare the data grid by pre-loading it with data.
When used as a complete cache, the data grid must hold all of the data and must be loaded before any clients can connect to it. When we are using a sparse cache, we can warm up the cache with data so that clients can have immediate access to data when they connect.
Two approaches exist for pre-loading data into the data grid: Using a Loader plug-in or using a client loader, as described in the following sections.
Loader plug-in
The loader plug-in is associated with each map and is responsible for synchronizing a single primary partition shard with the database. The preloadMap method of the loader plug-in is invoked automatically when a shard is activated. For example, if you have 100 partitions, 100 loader instances exist, each loading the data for its partition. When run synchronously, all clients are blocked until the preload has completed.
Client loader
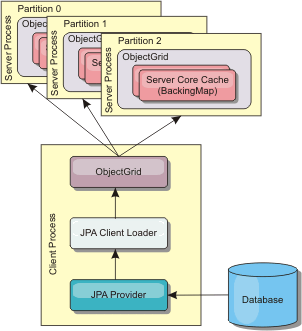
A client loader is a pattern for using one or more clients to load the grid with data. Using multiple clients to load grid data can be effective when the partition scheme is not stored in the database. We can invoke client loaders manually or automatically when the data grid starts. Client loaders can optionally use the StateManager to set the state of the data grid to pre-load mode, so that clients are not able to access the grid while it is pre-loading the data. WXS includes a JPA-based loader that we can use to automatically load the data grid with either the OpenJPA or Hibernate JPA providers.
Figure 2. Client loader
Database synchronization techniques
When WXS is used as a cache, applications must be written to tolerate stale data if the database can be updated independently from a WXS transaction. To serve as a synchronized in-memory database processing space, eXtreme Scale provides several ways of keeping the cache updated.
Database synchronization techniques
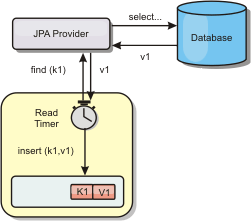
Periodic refresh
The cache can be automatically invalidated or updated periodically using the JPA time-based database updater.The updater periodically queries the database using a JPA provider for any updates or inserts that have occurred since the previous update. Any changes identified are automatically invalidated or updated when used with a sparse cache. If used with a complete cache, the entries can be discovered and inserted into the cache. Entries are never removed from the cache. Periodic refresh...
Sparse caches can utilize eviction policies to automatically remove data from the cache without affecting the database. There are three built-in policies included in eXtreme Scale: time-to-live, least-recently-used, and least-frequently-used. All three policies can optionally evict data more aggressively as memory becomes constrained by enabling the memory-based eviction option.
Event-based invalidation
Sparse and complete caches can be invalidated or updated using an event generator such as Java Message Service (JMS). Invalidation using JMS can be manually tied to any process that updates the back-end using a database trigger. A JMS ObjectGridEventListener plug-in is provided in eXtreme Scale that can notify clients when the server cache has any changes. This can decrease the amount of time the client can see stale data.
Programmatic invalidation
The eXtreme Scale APIs allow manual interaction of the near and server cache using the Session.beginNoWriteThrough(), ObjectMap.invalidate() and EntityManager.invalidate() API methods. If a client or server process no longer needs a portion of the data, the invalidate methods can be used to remove data from the near or server cache. The beginNoWriteThrough method applies any ObjectMap or EntityManager operation to the local cache without calling the loader. If invoked from a client, the operation applies only to the near cache (the remote loader is not invoked). If invoked on the server, the operation applies only to the server core cache without invoking the loader.
Data invalidation
To remove stale cache data, we can use invalidation mechanisms.
Administrative invalidation
Use the web console or the xscmd utility to invalidate data based on the key. We can filter the cache data with a regular expression and then invalidate the data based on the regular expression.
Event-based invalidation
Sparse and complete caches can be invalidated or updated using an event generator such as JMS) Invalidation using JMS can be manually tied to any process that updates the back-end using a database trigger. A JMS ObjectGridEventListener plug-in is provided in eXtreme Scale that can notify clients when the server cache changes. This type of notification decreases the amount of time the client can see stale data.
Event-based invalidation normally consists of the following three components.
- Event queue:
An event queue stores the data change events. It could be a JMS queue, a database, an in-memory FIFO queue, or any kind of manifest as long as it can manage the data change events.
- Event publisher:
An event publisher publishes the data change events to the event queue. An event publisher is usually an application you create or a WXS plug-in implementation. The event publisher knows when the data is changed or it changes the data itself. When a transaction commits, events are generated for the changed data and the event publisher publishes these events to the event queue.
- Event consumer:
An event consumer consumes data change events. The event consumer is usually an application to ensure the target grid data is updated with the latest change from other grids. This event consumer interacts with the event queue to get the latest data change and applies the data changes in the target grid. The event consumers can use eXtreme Scale APIs to invalidate stale data or update the grid with the latest data.
For example, JMSObjectGridEventListener has an option for a client-server model, in which the event queue is a designated JMS destination. All server processes are event publishers. When a transaction commits, the server gets the data changes and publishes them to the designated JMS destination. All the client processes are event consumers. They receive the data changes from the designated JMS destination and apply the changes to the client's near cache .
Programmatic invalidation
The WXS APIs allow manual interaction of the near and server cache using the Session.beginNoWriteThrough(), ObjectMap.invalidate() and EntityManager.invalidate() API methods. If a client or server process no longer needs a portion of the data, the invalidate methods can be used to remove data from the near or server cache. The beginNoWriteThrough method applies any ObjectMap or EntityManager operation to the local cache without calling the loader. If invoked from a client, the operation applies only to the near cache (the remote loader is not invoked). If invoked on the server, the operation applies only to the server core cache without invoking the loader.
Use programmatic invalidation with other techniques to determine when to invalidate the data. For example, this invalidation method uses event-based invalidation mechanisms to receive the data change events, and then uses APIs to invalidate the stale data.
Near cache invalidation
If we are using a near cache, we can configure an asynchronous invalidation that is triggered each time an update, delete, invalidation operation is run against the data grid. Because the operation is asynchronous, you might still see stale data in the data grid.
To enable near cache invalidation, set the nearCacheInvalidationEnabled attribute on the backing map in the ObjectGrid descriptor XML file.
Indexing
Use the MapIndexPlugin plug-in to build an index or several indexes on a BackingMap to support non-key data access.
Index types and configuration
The indexing feature is represented by the MapIndexPlugin plug-in or Index for short. The Index is a BackingMap plug-in. A BackingMap can have multiple Index plug-ins configured, as long as each one follows the Index configuration rules.
Use the indexing feature to build one or more indexes on a BackingMap. An index is built from an attribute or a list of attributes of an object in the BackingMap. This feature provides a way for applications to find certain objects more quickly. With the indexing feature, applications can find objects with a specific value or within a range of values of indexed attributes.
Two types of indexing are possible:
static and dynamic. With static indexing, configure the index plug-in on the BackingMap before initializing the ObjectGrid instance. We can do this configuration with XML or programmatic configuration of the BackingMap. Static indexing starts building an index during ObjectGrid initialization. The index is always synchronized with the BackingMap and ready for use. After the static indexing process starts, the maintenance of the index is part of the WXS transaction management process. When transactions commit changes, these changes also update the static index, and index changes are rolled back if the transaction is rolled back.
With dynamic indexing, we can create an index on a BackingMap before or after the initialization of the containing ObjectGrid instance. Applications have life cycle control over the dynamic indexing process so that we can remove a dynamic index when it is no longer needed. When an application creates a dynamic index, the index might not be ready for immediate use because of the time it takes to complete the index building process. Because the amount of time depends upon the amount of data indexed, the DynamicIndexCallback interface is provided for applications that want to receive notifications when certain indexing events occur. These events include ready, error, and destroy. Applications can implement this callback interface and register with the dynamic indexing process.
If a BackingMap has an index plug-in configured, we can obtain the application index proxy object from the corresponding ObjectMap. Calling the getIndex method on the ObjectMap and passing in the name of the index plug-in returns the index proxy object. Cast the index proxy object to an appropriate application index interface, such as MapIndex, MapRangeIndex, MapGlobalIndex, or a customized index interface. After obtaining the index proxy object, we can use methods defined in the application index interface to find cached objects.
The steps to use indexing are summarized in the following list:
- Add either static or dynamic index plug-ins into the BackingMap.
- Obtain an application index proxy object by issuing the getIndex method of the ObjectMap.
- Cast the index proxy object to an appropriate application index interface, such as MapIndex, MapRangeIndex, or a customized index interface.
- Use methods that are defined in application index interface to find cached objects.
The HashIndex class is the built-in index plug-in implementation that can support the following built-in application index interfaces:
- MapIndex
- MapRangeIndex
- MapGlobalIndex
You also can create your own indexes. We can add HashIndex as either a static or dynamic index into the BackingMap, obtain either the MapIndex, MapRangeIndex, or MapGlobalIndex index proxy object, and use the index proxy object to find cached objects.
Global index
Global index is an extension of the built-in HashIndex class that runs on shards in distributed, partitioned data grid environments. It tracks the location of indexed attributes and provides efficient ways to find partitions, keys, values, or entries using attributes in large, partitioned data grid environments.
If global index is enabled in the built-in HashIndex plug-in, then applications can cast an index proxy object to the MapGlobalIndex type, and use it to find data.
Default index
To iterate through the keys in a local map, we can use the default index . This index does not require any configuration, but it must be used against the shard, using an agent or an ObjectGrid instance retrieved from the ShardEvents.shardActivated(ObjectGrid shard) method.
Data quality consideration
The results of index query methods only represent a snapshot of data at a point of time. No locks against data entries are obtained after the results return to the application. Application has to be aware that data updates may occur on a returned data set. For example, the application obtains the key of a cached object by running the findAll method of MapIndex. This returned key object is associated with a data entry in the cache. The application should be able to run the get method on ObjectMap to find an object by providing the key object. If another transaction removes the data object from the cache just before the get method is called, the returned result will be null.
Indexing performance considerations
One of the main objectives of the indexing feature is to improve overall BackingMap performance. If indexing is not used properly, the performance of the application might be compromised. Consider the following factors before using this feature.
- The number of concurrent write transactions: Index processing can occur every time a transaction writes data into a BackingMap. Performance degrades if many transactions are writing data into the map concurrently when an application attempts index query operations.
- The size of the result set that is returned by a query operation: As the size of the resultset increases, the query performance declines. Performance tends to degrade when the size of the result set is 15% or more of the BackingMap.
- The number of indexes built over the same BackingMap: Each index consumes system resources. As the number of the indexes built over the BackingMap increases, performance decreases.
The indexing function can improve BackingMap performance drastically. Ideal cases are when the BackingMap has mostly read operations, the query result set is of a small percentage of the BackingMap entries, and only few indexes are built over the BackingMap.
Plan multiple data center topologies
Using multi-master asynchronous replication, two or more data grids can become exact copies of each other. Each data grid is hosted in an independent catalog service domain, with its own catalog service, container servers, and a unique name. With multi-master asynchronous replication, we can use links to connect a collection of catalog service domains. The catalog service domains are then synchronized using replication over the links. We can construct almost any topology through the definition of links between the catalog service domains.
 Improve response time and data availability with WXS multi-master capability
Improve response time and data availability with WXS multi-master capability
Topologies for multimaster replication
- Replication links connecting catalog service domains
A replication data grid infrastructure is a connected graph of catalog service domains with bidirectional links among them. With a link, two catalog service domains can communicate data changes. For example, the simplest topology is a pair of catalog service domains with a single link between them.

Links can cross wide area networks, spanning large distances. If the link is interrupted, we can still change data in either catalog service domain. The topology will reconcile changes when the link automatically reconnects. The goal is for each catalog service domain to be an exact mirror of every other catalog service domain connected by the links. The replication links copy changes to other catalog service domains.
- Line topologies
Although it is such a simple deployment, a line topology demonstrates some qualities of the links. First, it is not necessary for a catalog service domain to be connected directly to every other catalog service domain to receive changes. The catalog service domain B pulls changes from catalog service domain A. The catalog service domain C receives changes from catalog service domain A through catalog service domain B, which connects catalog service domains A and C. Similarly, catalog service domain D receives changes from the other catalog service domains through catalog service domain C. This ability spreads the load of distributing changes away from the source of the changes.

Notice that if catalog service domain C fails, the following actions would occur:
- catalog service domain D would be orphaned until catalog service domain C was restarted
- catalog service domain C would synchronize itself with catalog service domain B, which is a copy of catalog service domain A
- catalog service domain D would use catalog service domain C to synchronize itself with changes on catalog service domain A and B. These changes initially occurred while catalog service domain D was orphaned (while catalog service domain C was down).
Ultimately, catalog service domains A, B, C, and D would all become identical to one other again.
- Ring topologies
Ring topologies are resilient. If a collective fails, surviving collectives can still obtain changes. The collectives travel around the ring, away from the failure. Each collective has at most two links to other collectives, no matter how large the ring topology. Latency to propagate changes can be an issue if there are multiple links to traverse before all the collectives have the changes. A line topology has the same characteristic.

We can use a root catalog service domain at the center of the ring to function as the central point of reconciliation. The other catalog service domains act as remote points of reconciliation for changes occurring in the root catalog service domain, which can arbitrate changes among the catalog service domains. If a ring topology contains more than one ring around a root catalog service domain, the catalog service domain can only arbitrate changes among the innermost ring. However, the results of the arbitration spread throughout the catalog service domains in the other rings.
- Hub-and-spoke topologies
With a hub-and-spoke topology, changes travel through a hub catalog service domain. Because the hub is the only intermediate catalog service domain specified, hub-and-spoke topologies have lower latency. The hub catalog service domain is connected to every spoke catalog service domain through a link. The hub distributes changes among the catalog service domains. The hub acts as a point of reconciliation for collisions. In an environment with a high update rate, the hub might require run on more hardware than the spokes to remain synchronized. WXS is designed to scale linearly, meaning we can make the hub larger, as needed, without difficulty. However, if the hub fails, then changes are not distributed until the hub restarts. Any changes on the spoke catalog service domains will be distributed after the hub is reconnected.
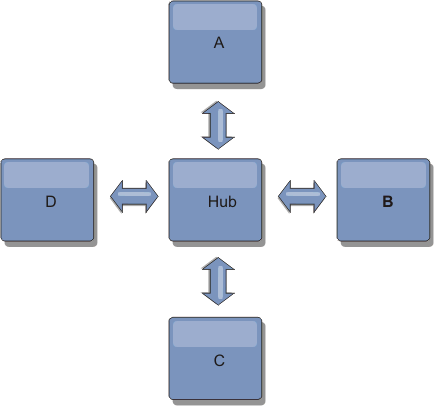
We can also use a strategy with fully replicated clients, a topology variation which uses a pair of servers running as a hub. Every client creates a self-contained single container data grid with a catalog in the client JVM. A client uses its data grid to connect to the hub catalog. This connection causes the client to synchronize with the hub as soon as the client obtains a connection to the hub.
Any changes made by the client are local to the client, and are replicated asynchronously to the hub. The hub acts as an arbitration catalog service domain, distributing changes to all connected clients. The fully replicated clients topology provides a reliable L2 cache for an object relational mapper, such as OpenJPA. Changes are distributed quickly among client JVMs through the hub. If the cache size can be contained within the available heap space, the topology is a reliable architecture for this style of L2.
Use multiple partitions to scale the hub catalog service domain on multiple JVMs, if necessary. Because all of the data still must fit in a single client JVM, multiple partitions increase the capacity of the hub to distribute and arbitrate changes. However, having multiple partitions does not change the capacity of a single catalog service domain.
- Tree topologies
We can also use an acyclic directed tree. An acyclic tree has no cycles or loops, and a directed setup limits links to existing only between parents and children. This configuration is useful for topologies that have many catalog service domains. In these topologies, it is not practical to have a central hub connected to every possible spoke. This type of topology can also be useful when add child catalog service domains without updating the root catalog service domain.
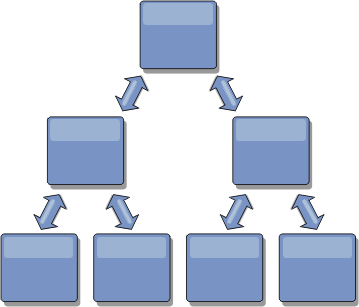
A tree topology can still have a central point of reconciliation in the root catalog service domain. The second level can still function as a remote point of reconciliation for changes occurring in the catalog service domain beneath them. The root catalog service domain can arbitrate changes between the catalog service domains on the second level only. We can also use N-ary trees, each of which have N children at each level. Each catalog service domain connects out to n links.
- Fully replicated clients
This topology variation involves a pair of servers running as a hub. Every client creates a self-contained single container data grid with a catalog in the client JVM. A client uses its data grid to connect to the hub catalog, causing the client to synchronize with the hub as soon as the client obtains a connection to the hub.
Any changes made by the client are local to the client, and are replicated asynchronously to the hub. The hub acts as an arbitration catalog service domain, distributing changes to all connected clients. The fully replicated clients topology provides a good L2 cache for an object relational mapper, such as OpenJPA. Changes are distributed quickly among client JVMs through the hub. As long as the cache size can be contained within the available heap space of the clients, this topology is a good architecture for this style of L2.
Use multiple partitions to scale the hub catalog service domain on multiple JVMs, if necessary. Because all of the data still must fit in a single client JVM, using multiple partitions increases the capacity of the hub to distribute and arbitrate changes, but it does not change the capacity of a single catalog service domain.
Configuration considerations for multi-master topologies
Consider the following issues when we are deciding whether and how to use multi-master replication topologies.
- Map set requirements
Map sets must have the following characteristics to replicate changes across catalog service domain links:
- The ObjectGrid name and map set name within a catalog service domain must match the ObjectGrid name and map set name of other catalog service domains. For example, ObjectGrid "og1" and map set "ms1" must be configured in catalog service domain A and catalog service domain B to replicate the data in the map set between the catalog service domains.
- Is a FIXED_PARTITION data grid. PER_CONTAINER data grids cannot be replicated.
- Has the same number of partitions in each catalog service domain. The map set might or might not have the same number and types of replicas.
- Has the same data types being replicated in each catalog service domain.
- Contains the same maps and dynamic map templates in each catalog service domain.
- Does not use entity manager. A map set containing an entity map is not replicated across catalog service domains.
- Does not use write-behind caching support. A map set containing a map configured with write-behind support is not replicated across catalog service domains.
Any map sets with the preceding characteristics begin to replicate after the catalog service domains in the topology have been started.
- Class loaders with multiple catalog service domains
Catalog service domains must have access to all classes used as keys and values. Any dependencies must be reflected in all class paths for data grid container JVMs for all domains. If a CollisionArbiter plug-in retrieves the value for a cache entry, then the classes for the values must be present for the domain that is starting the arbiter.
Loader considerations in a multi-master topology
When using loaders in a multi-master topology, you must consider the possible collision and revision information maintenance challenges. The data grid maintains revision information about the items in the data grid so that collisions can be detected when other primary shards in the configuration write entries to the data grid. When entries are added from a loader, this revision information is not included and the entry takes on a new revision. Because the revision of the entry seems to be a new insert, a false collision could occur if another primary shard also changes this state or pulls the same information in from a loader.
Replication changes invoke the get method on the loader with a list of the keys that are not already in the data grid but are going to be changed during the replication transaction. When the replication occurs, these entries are collision entries. When the collisions are arbitrated and the revision is applied then a batch update is called on the loader to apply the changes to the database. All of the maps that were changed in the revision window are updated in the same transaction.
Preload conundrum
Consider a two data center topology with data center A and data center B. Both data centers have independent databases, but only data center A is has a data grid running. When you establish a link between the data centers for a multi-master configuration, the data grids in data center A begin pushing data to the new data grids in data center B, causing a collision with every entry. Another major issue that occurs is with any data that is in the database in data center B but not in the database in data center A. These rows are not populated and arbitrated, resulting in inconsistencies that are not resolved.
Solution to the preload conundrum
Because data that resides only in the database cannot have revisions, always fully preload the data grid from the local database before establishing the multi-master link. Then, both data grids can revision and arbitrate the data, eventually reaching a consistent state.
Sparse cache conundrum
With a sparse cache, the application first attempts to find data in the data grid. If the data is not in the data grid, the data is searched for in the database using the loader. Entries are evicted from the data grid periodically to maintain a small cache size.
This cache type can be problematic in a multi-master configuration scenario because the entries within the data grid have revisioning metadata that help detect when collisions occur and which side has made changes. When links between the data centers are not working, one data center can update an entry and then eventually update the database and invalidate the entry in the data grid. When the link recovers, the data centers attempt to synchronize revisions with each other. However, because the database was updated and the data grid entry was invalidated, the change is lost from the perspective of the data center that went down. As a result, the two sides of the data grid are out of synch and are not consistent.
Solution to the sparse cache conundrum
Hub and spoke topology:We can run the loader only in the hub of a hub and spoke topology, maintaining consistency of the data while scaling out the data grid. However, if we are considering this deployment, note that the loaders can allow the data grid to be partially loaded, meaning that an evictor has been configured. If the spokes of the configuration are sparse caches but have no loader, then any cache misses have no way to retrieve data from the database. Because of this restriction, you should use a fully populated cache topology with a hub and spoke configuration.
Invalidations and eviction
Invalidation creates inconsistency between the data grid and the database. Data can be removed from the data grid either programmatically or with eviction. When you develop the application, you must be aware that revision handling does not replicate changes that are invalidated, resulting in inconsistencies between primary shards.
Invalidation events are not cache state changes and do not result in replication. Any configured evictors run independently from other evictors in the configuration. For example, you might have one evictor configured for a memory threshold in one catalog service domain, but a different type of less aggressive evictor in your other linked catalog service domain. When data grid entries are removed due to the memory threshold policy, the entries in the other catalog service domain are not affected.
Database updates and data grid invalidation
Problems occur when you update the database directly in the background while calling the invalidation on the data grid for the updated entries in a multi-master configuration. This problem occurs because the data grid cannot replicate the change to the other primary shards until some type of cache access moves the entry into the data grid.
Multiple writers to a single logical database
When we are using a single database with multiple primary shards that are connected through a loader, transactional conflicts result. Your loader implementation must specially handle these types of scenarios.
Mirroring data using multi-master replication
We can configure independent databases that are connected to independent catalog service domains. In this configuration, the loader can push changes from one data center to the other data center.
Design considerations for multi-master replication
When implementing multi-master replication, you must consider aspects in your design such as: arbitration, linking, and performance.
Arbitration considerations in topology design
Change collisions might occur if the same records can be changed simultaneously in two places. Set up each catalog service domain to have about the same amount of processor, memory, network resources. You might observe that catalog service domains performing change collision handling (arbitration) use more resources than other catalog service domains. Collisions are detected automatically. They are handled with one of two mechanisms:
| Default collision arbiter | The default protocol is to use the changes from the lexically lowest named catalog service domain. For example, if catalog service domain A and B generate a conflict for a record, then the change from catalog service domain B is ignored. Catalog service domain A keeps its version and the record in catalog service domain B is changed to match the record from catalog service domain A. This behavior applies as well for applications where users or sessions are normally bound or have affinity with one of the data grids. |
| Custom collision arbiter | Applications can provide a custom arbiter. When a catalog service domain detects a collision, it starts the arbiter. |
For topologies in which collisions are possible, consider implementing a hub-and-spoke topology or a tree topology. These two topologies are conducive to avoiding constant collisions, which can happen in the following scenarios:
- Multiple catalog service domains experience a collision
- Each catalog service domain handles the collision locally, producing revisions
- The revisions collide, resulting in revisions of revisions
To avoid collisions, choose a specific catalog service domain, called an arbitration catalog service domain as the collision arbiter for a subset of catalog service domains. For example, a hub-and-spoke topology might use the hub as the collision handler. The spoke collision handler ignores any collisions that are detected by the spoke catalog service domains. The hub catalog service domain creates revisions, preventing unexpected collision revisions. The catalog service domain that is assigned to handle collisions must link to all of the domains for which it is responsible for handling collisions. In a tree topology, any internal parent domains handle collisions for their immediate children. In contrast, if you use a ring topology, we cannot designate one catalog service domain in the ring as the arbiter.
The following table summarizes the arbitration approaches that are most compatible with various topologies.
| Topology | Application Arbitration? | Notes |
|---|---|---|
| A line of two catalog service domains | Yes | Choose one catalog service domain as the arbiter. |
| A line of three catalog service domains | Yes | The middle catalog service domain must be the arbiter. Think of the middle catalog service domain as the hub in a simple hub-and-spoke topology. |
| A line of more than three catalog service domains | No | Application arbitration is not supported. |
| A hub with N spokes | Yes | Hub with links to all spokes must be the arbitration catalog service domain. |
| A ring of N catalog service domains | No | Application arbitration is not supported. |
| An acyclic, directed tree (n-ary tree) | Yes | All root nodes must rate their direct descendants only. |
Linking considerations in topology design
Ideally, a topology includes the minimum number of links while optimizing trade-offs among change latency, fault tolerance, and performance characteristics.
- Change latency
Change latency is determined by the number of intermediate catalog service domains a change must go through before arriving at a specific catalog service domain.
A topology has the best change latency when it eliminates intermediate catalog service domains by linking every catalog service domain to every other catalog service domain. However, a catalog service domain must perform replication work in proportion to its number of links. For large topologies, the sheer number of links to be defined can cause an administrative burden.
The speed at which a change is copied to other catalog service domains depends on additional factors, such as:
- Processor and network bandwidth on the source catalog service domain
- The number of intermediate catalog service domains and links between the source and target catalog service domain
- The processor and network resources available to the source, target, and intermediate catalog service domains
- Fault tolerance
Fault tolerance is determined by how many paths exist between two catalog service domains for change replication.
If you have only one link between a given pair of catalog service domains, a link failure disallows propagation of changes. Similarly, changes are not propagated between catalog service domains if any of the intermediate domains experiences link failure. Your topology could have a single link from one catalog service domain to another such that the link passes through intermediate domains. If so, then changes are not propagated if any of the intermediate catalog service domains is down.
Consider the line topology with four catalog service domains A, B, C, and D:
If any of these conditions hold, Domain D does not see any changes from A:
- Domain A is up and B is down
- Domains A and B are up and C is down
- The link between A and B is down
- The link between B and C is down
- The link between C and D is down
In contrast, with a ring topology, each catalog service domain can receive changes from either direction.
For example, if a given catalog service in your ring topology is down, then the two adjacent domains can still pull changes directly from each other.
All changes are propagated through the hub. Thus, as opposed to the line and ring topologies, the hub-and-spoke design is susceptible to break drown if the hub fails.
A single catalog service domain is resilient to a certain amount of service loss. However, larger failures such as wide network outages or loss of links between physical data centers can disrupt any of the catalog service domains.
- Linking and performance
The number of links defined on a catalog service domain affects performance. More links use more resources and replication performance can drop as a result. The ability to retrieve changes for a domain A through other domains effectively offloads domain A from replicating its transactions everywhere. The change distribution load on a domain is limited by the number of links it uses, not how many domains are in the topology. This load property provides scalability, so the domains in the topology can share the burden of change distribution.
A catalog service domain can retrieve changes indirectly through other catalog service domains. Consider a line topology with five catalog service domains.
A <=> B <=> C <=> D <=> E
- A pulls changes from B, C, D, and E through B
- B pulls changes from A and C directly, and changes from D and E through C
- C pulls changes from B and D directly, and changes from A through B and E through D
- D pulls changes from C and E directly, and changes from A and B through C
- E pulls changes from D directly, and changes from A, B, and C through D
The distribution load on catalog service domains A and E is lowest, because they each have a link only to a single catalog service domain. Domains B, C, and D each have a link to two domains. Thus, the distribution load on domains B, C, and D is double the load on domains A and E. The workload depends on the number of links in each domain, not on the overall number of domains in the topology. Thus, the described distribution of loads would remain constant, even if the line contained 1000 domains.
Multi-master replication performance considerations
Take the following limitations into account when using multi-master replication topologies:
- Change distribution tuning, as discussed in the previous section.
- Replication link performance WXS creates a single TCP/IP socket between any pair of JVMs. All traffic between the JVMs occurs through the single socket, including traffic from multi-master replication. Catalog service domains are hosted on at least n container JVMs, providing at least n TCP links to peer catalog service domains. Thus, the catalog service domains with larger numbers of containers have higher replication performance levels. More containers require more processor and network resources.
- TCP sliding window tuning and RFC 1323 RFC 1323 support on both ends of a link yields more data for a round trip. This support results in higher throughput, expanding the capacity of the window by a factor of about 16,000.
Recall that TCP sockets use a sliding window mechanism to control the flow of bulk data. This mechanism typically limits the socket to 64 KB for a round-trip interval. If the round-trip interval is 100 ms, then the bandwidth is limited to 640 KB/second without additional tuning. Fully using the bandwidth available on a link might require tuning that is specific to an operating system. Most operating systems include tuning parameters, including RFC 1323 options, to enhance throughput over high-latency links.
Several factors can affect replication performance:
- The speed at which eXtreme Scale retrieves changes.
- The speed at which eXtreme Scale can service retrieve replication requests.
- The sliding window capacity.
- With network buffer tuning on both sides of a link, eXtreme Scale retrieves changes over the socket efficiently.
- Object Serialization All data must be serializable. If a catalog service domain is not using COPY_TO_BYTES, then the catalog service domain must use Java serialization or ObjectTransformers to optimize serialization performance.
- Compression WXS compresses all data sent between catalog service domains by default. Disabling compression is not currently available.
- Memory tuning The memory usage for a multi-master replication topology is largely independent of the number of catalog service domains in the topology.
Multi-master replication adds a fixed amount of processing per Map entry to handle versioning. Each container also tracks a fixed amount of data for each catalog service domain in the topology. A topology with two catalog service domains uses approximately the same memory as a topology with 50 catalog service domains. WXS does not use replay logs or similar queues in its implementation. Thus, there is no recovery structure ready in the case that a replication link is unavailable for a substantial period and later restarts.
Interoperability with other products
We can integrate WXS with other products, such as WAS and WAS Community Edition.
WAS
We can integrate WAS into various aspects of your WXS configuration. We can deploy data grid applications and use WAS to host container and catalog servers. Or, we can use a mixed environment that has WXS client installed in the WAS environment with stand-alone catalog and container servers . We can also use WAS security in your WXS environment.
WebSphere Business Process Management and Connectivity products
WebSphere Business Process Management and Connectivity products, including WebSphere Integration Developer, WebSphere Enterprise Service Bus, and WebSphere Process Server, integrate with back end systems, such as CICS, web services, databases, or JMS topics and queues. We can add WXS to the configuration to cache the output of these back end systems, increasing the overall performance of the configuration.
WebSphere Commerce
WebSphere Commerce can leverage WXS caching as a replacement to dynamic cache. By eliminating duplicate dynamic cache entries and the frequent invalidation processing necessary to keep the cache synchronized during high stress situations, we can improve performance, scaling, and high availability.
WebSphere Portal
We can persist HTTP sessions from WebSphere Portal into a data grid in WXS. In addition, IBM Web Content Manager in IBM WebSphere Portal can use dynamic cache instances to store rendered content retrieved from Web Content Manager when advanced caching is enabled. WXS offers an implementation of dynamic cache that stores cached content in an elastic data grid instead of using the default dynamic cache implementation.
WAS Community Edition
WAS Community Edition can share session state, but not in an efficient, scalable manner. WXS provides a high performance, distributed persistence layer that can be used to replicate state, but does not readily integrate with any application server outside of WAS. We can integrate these two products to provide a scalable session management solution.
WebSphere Real Time
With support for WebSphere Real Time, the industry-leading real-time Java offering, WXS enables Extreme Transaction Processing (XTP) applications to have more consistent and predictable response times.
Monitoring
WXS can be monitored using several popular enterprise monitoring solutions. Plug-in agents are included for IBM Tivoli Monitoring and Hyperic HQ, which monitor WXS using publicly accessible management beans. CA Wily Introscope uses Java method instrumentation to capture statistics.
Microsoft Visual Studio, IIS, and .NET environments
Configure WebSphere Commerce to use WXS for dynamic cache to improve performance and scale
WebSphere Business Process Management and Connectivity integration
Using WXS to enhance WebSphere Portal and IBM Web Content Manager performance
Supported APIs and configurations by client type
The available APIs and configuration features depend on the type of client that we are using. Use any of the following clients: Java client, REST data service client, REST gateway client, or .NET client.
| Client feature | Java Client ORB | Java Client XIO | Rest Data Service Client | Rest Gateway Client | .NET Client |
|---|---|---|---|---|---|
| ObjectMap API | Yes | Yes | No | Yes (indirect) | Yes (indirect) |
| ObjectQuery API | Yes | Yes | n/a | No | No |
| Single partition batch | Yes | Yes | n/a | No | Yes |
| create, retrieve, update, and delete | Yes | Yes | n/a | Yes | Yes |
| Null Values | Yes | Yes | n/a | No | Yes |
| Generics-based APIs | No | No | n/a | n/a | Yes |
| CopyMode configuration | |||||
| CopyMode.READ_AND_COMMIT | Yes | Yes | n/a | n/a | No |
| CopyMode.COMMIT | Yes | Yes | n/a | n/a | No |
| CopyMode.READ | Yes | Yes | n/a | n/a | No |
| CopyMode.NO_COPY | Yes | Yes | n/a | n/a | No |
| CopyMode.COPY_TO_BYTES (SerializationInfo) | Yes | Yes | n/a | n/a | Yes |
| CopyMode.COPY_TO_BYTES_RAW | Yes | Yes | n/a | n/a | No |
| DataGrid API | Yes | Yes | No | No | No |
| EntityManager API | Yes | Yes | Yes (indirect) | No | No |
| Index | |||||
| Client HashIndex | Yes | Yes | No | No | No |
| Client Inverse RangeIndex (8.6) | No | Yes | No | No | No |
| Dynamic Index | Yes | Yes | No | No | No |
| Global HashIndex (8.6) | No | Yes | No | No | No |
| Locking | |||||
| Locking - None | Yes | Yes | Yes | Yes | No |
| Locking - Pessimistic | Yes | Yes | Yes | Yes | Yes |
| Locking - Optimistic | Yes | Yes | Yes | Yes | No |
| Plug-ins, Listeners, and Extensions (Server)1 | |||||
| MapSerializerPlugin plug-in | Yes | Yes | No | No | No 1 |
| ObjectTransformer plug-in (deprecated) | Yes | Yes | No | No | No 1 |
| OptimisticCallback plug-in (deprecated) | Yes | Yes | No | No | No 1 |
| MapEventListener plug-in | Yes | Yes | Yes 2 | Yes2 | Yes1 |
| Loader plug-in | Yes | Yes | Yes | Yes | Yes1 |
| TransactionCallback plug-in | Yes | Yes | Yes2 | Yes2 | Yes1 |
| ObjectGridEventListener plug-in | Yes | Yes | Yes2 | Yes2 | Yes1 |
| Plug-ins, Listeners, and Extensions (Client) 1 | |||||
| MapSerializerPlugin plug-in | Yes | Yes | No | No | No |
| ObjectTransformer plug-in (deprecated) | Yes | Yes | No | No | No |
| OptimisticCallback plug-in (deprecated) | Yes | Yes | No | No | No |
| MapEventListener plug-in | Yes | Yes | Yes | No | No |
| TransactionCallback plug-in | Yes | Yes | Yes | No | No |
| ObjectGridEventListener plug-in | Yes | Yes | Yes | No | No |
| Routing | |||||
| PartitionManager API | Yes | Yes | No | No | Yes |
| PartitionableKey (key plug-in) | Yes | Yes | No | No | No |
| Declarative Partition Routing (8.6) | No | Yes | Yes | No | Yes |
| Per-container Routing (and SessionHandle) | Yes | Yes | No | No | No |
| Transactions | |||||
| Tx - AutoCommit | Yes | Yes | Yes | Yes | Yes |
| Tx - Single partition read/write | Yes | Yes | No | No | Yes |
| Tx - Multi-partition read | Yes | Yes | No | No | No |
| Tx - Multi-partition write XA (8.6) | Yes | No | No | No | |
| Tx - Mult-map | Yes | Yes | Yes | No | No |
| Client Cache (near cache ) | Yes | Yes | Yes | No | No |
| Eviction - time to live (TTL) | Yes | Yes | Yes | No | No |
| Eviction - least recently used (LRU) or least frequently used (LFU) plug-in | Yes | Yes | Yes | No | No |
| Eviction - custom | Yes | Yes | Yes | No | No |
| Eviction triggers | Yes | Yes | Yes | No | No |
| Near-cache invalidation (8.6) | No | Yes | Yes | No | No |
| Security | |||||
| CredentialGenerator / Credential | Yes | Yes | No | No | Yes |
| UserPasswordCredentialGenerator | Yes | Yes | Yes | Yes | Yes |
| WSTokenCredentialGenerator | Yes | Yes | No | No | No |
| SSL/TLS | Yes | Yes | Yes | Yes | Yes |
| Subject via Session | No | No | No | No | No |
| AccessbyCreator | Yes | Yes | Yes | Yes | Yes |
| Configuration | |||||
| ClientConfiguration override | Yes | Yes | Yes | No | Yes |
| Client ObjectGrid XML override | Yes | Yes | Yes | No | No |
| Client properties file | Yes | Yes | Yes | Yes | Yes |
| ClientProperties API | Yes | Yes | No | No | Yes 3 |
| Security properties file | Yes | Yes | Yes | No | Yes 4 |
| ClientSecurityConfiguration API | Yes | Yes | No | No | No |
1 The .NET client and REST clients do not include any client-side plug-ins. Server-side plug-ins are supported when they do not require any client-side plug-in counterparts. For example, an ObjectTransformer plug-in is required on both the server and client. When No is specified, the API does not support the plug-in on the server.
2 Server-side plug-ins that are applicable to clients are instantiated by the client by default and must be added to the class path. The REST Gateway does not currently allow an ObjectGrid client override XML file.
3 We can update or modify the SimpleClient sample application to use the available eXtreme Scale client for .NET APIs. The SimpleClient application is in the install_dir\sample\SimpleClient directory. Load this file into Visual Studio to view the sample application that uses simple create, retrieve, update, and delete operations. Use the SimpleClient application as a guide for accessing the data grid.
Plan for network ports
WXS is a distributed cache that requires opening ports to communicate among Java virtual machines. Plan and control your ports, especially in an environment that has a firewall, and when we are using a catalog service and containers on multiple ports.
When specifying port numbers, avoid setting ports that are in the ephemeral range for your operating system. If you use a port that is in the ephemeral range, port conflicts could occur.
Catalog service domain
A catalog service domain requires the following ports to be defined:
- peerPort
- Port for the high availability (HA) manager to communicate between peer catalog servers over a TCP stack. In WAS, this setting is inherited by the high availability manager port configuration.
- clientPort
- Port for catalog servers to access catalog service data. In WAS, this port is set through the catalog service domain configuration.
- listenerPort
- Port number to which the Object Request Broker (ORB) or eXtremeIO (XIO) transport binds. This setting configures containers and clients to communicate with the catalog service. In WAS, the listenerPort is inherited by the BOOTSTRAP_ADDRESS port (when we are using the ORB transport) or the XIO_address port (when we are using XIO transport) port configuration. This property applies to both the container server and the catalog service.
Default: 2809
- JMXConnectorPort
- Defines the SSL port to which the JMX service binds.
- JMXServicePort
- Port number on which the MBean server listens communication with JMX. The JMXServicePort property specifies the non-SSL port for JMX. You must use a different port number for each JVM in the configuration. To use JMX/RMI, explicitly specify the JMXServicePort and port number, even to use the default port value. This property applies to both the container server and the catalog service.
(Required for stand-alone environments only.)
Default: 1099 for catalog servers
- jvmArgs (optional)
- Specifies a list of JVM arguments. When security is enabled, use the following argument on the startOgServer or startXsServer script to configure the Secure Socket Layer (SSL) port:
-jvmArgs -Dcom.ibm.CSI.SSLPort=<sslPort>.
Container servers
The WXS container servers also require several ports to operate. By default, the WXS container server generates its HA manager port and listener port automatically with dynamic ports. For an environment that has a firewall, it is advantageous for you to plan and control ports. For container servers to start with specific ports, we can use the following options in the startOgServer or startXsServer command.
- haManagerPort
- Port number the high availability manager uses. If this property is not set, a free port is chosen. This property is ignored in WAS environments.
- listenerPort
- Port number to which the Object Request Broker (ORB) or eXtremeIO (XIO) transport binds. This setting configures containers and clients to communicate with the catalog service. In WAS, the listenerPort is inherited by the BOOTSTRAP_ADDRESS port (when we are using the ORB transport) or the XIO_address port (when we are using XIO transport) port configuration. This property applies to both the container server and the catalog service.
Default: 2809
- JMXConnectorPort
- Defines the SSL port to which the JMX service binds.
- JMXServicePort
- Port number on which the MBean server listens communication with JMX. The JMXServicePort property specifies the non-SSL port for JMX. You must use a different port number for each JVM in the configuration. To use JMX/RMI, explicitly specify the JMXServicePort and port number, even to use the default port value. This property applies to both the container server and the catalog service.
(Required for stand-alone environments only.)
Default: 1099 for catalog servers
- xioChannel.xioContainerTCPSecure.Port
-
 Deprecated: This property has been deprecated. The value specified by the listenerPort property is used.
SSL port number of eXtremeIO on the server. This property is used only when the transportType property is set to SSL-Supported or SSL-Required.
Deprecated: This property has been deprecated. The value specified by the listenerPort property is used.
SSL port number of eXtremeIO on the server. This property is used only when the transportType property is set to SSL-Supported or SSL-Required. - xioChannel.xioContainerTCPNonSecure.Port
-
Deprecated: This property has been deprecated. The value specified by the listenerPort property is used.
Non-secure listener port number of eXtremeIO on the server. If you do not set the value, an ephemeral port is used. This property is used only when the transportType property is set to TCP/IP.
Restriction: The xioChannel.xioContainerTCPNonSecure.Port property is not supported in the Liberty profile.
- jvmArgs (optional)
- Specifies a list of JVM arguments. When security is enabled, use the following argument on the startOgServer or startXsServer script to configure the Secure Socket Layer (SSL) port:
-jvmArgs -Dcom.ibm.CSI.SSLPort=<sslPort>.
Proper planning of port control is essential when hundreds of JVMs are started in a server. If a port conflict exists, container servers do not start.
Clients
WXS clients can receive callbacks from servers when we are using the DataGrid API or several other commands. Use the listenerPort property in the client properties file to specify the port in which the client listens for callbacks from the server.
- haManagerPort
- Port number the high availability manager uses. If this property is not set, a free port is chosen. This property is ignored in WAS environments.
- JVM arguments (optional)
- Specifies a list of JVM arguments. When security is enabled, use the following system property when starting the client process:
-jvmArgs -Dcom.ibm.CSI.SSLPort=<sslPort>.
- listenerPort
- Port number to which the Object Request Broker (ORB) or eXtremeIO (XIO) transport binds. This setting configures containers and clients to communicate with the catalog service. In WAS, the listenerPort is inherited by the BOOTSTRAP_ADDRESS port (when we are using the ORB transport) or the XIO_address port (when we are using XIO transport) port configuration. This property applies to both the container server and the catalog service.
Default: 2809
Ports in WAS
- The listenerPort value is inherited. The value is different depending on the type of transport we are using:
- If we are using the ORB transport, the BOOTSTRAP_ADDRESS value for each WAS application server is used.
- If we are using the IBM eXtremeIO transport, the XIO_ADDRESS value is used.
- The haManagerPort and peerPort values are inherited from the DCS_UNICAST_ADDRESS value for each WAS application server.
We can define a catalog service domain in the administrative console.
We can view the ports for a particular server by clicking one of the following paths in the administrative console:
-
Servers | Server Types | WASs | server_name | Ports | port_name
Port number settings in WAS versions
Plan to use IBM eXtremeMemory
By configuring eXtremeMemory, we can store objects in native memory instead of on the Java heap. When you configure eXtremeMemory, we can either...
- Allow the default amount of memory to be used
- Calculate the amount of memory to dedicate to eXtremeMemory.
You must be using map sets that have all the maps configured with COPY_TO_BYTES or COPY_TO_BYTES_RAW copy modes. If any maps within the map set are not using one of these copy modes, objects are stored on the Java heap.
 You must have the shared resource, libstdc++.so.5, installed. Use the package installer of your 64-bit Linux distribution to install the required resource file.
You must have the shared resource, libstdc++.so.5, installed. Use the package installer of your 64-bit Linux distribution to install the required resource file.
We cannot use eXtremeMemory in the following configuration scenarios:
- When using custom evictor plug-ins.
- When using composite indexes.
- When using dynamic indexes.
- When using built-in write-behind loaders.
You must have an existing data grid from which we can determine the total map sizes.
Ensure that all data grids have the same eXtremeMemory setting. This means that all containers are launched with either...
- enableXM=true
- enableXM=false
We cannot mix these settings.
By default, eXtremeMemory uses 25% of the total memory on the system. We can change this default with the maxXMSize property, which specifies the number of megabytes to dedicate for use by eXtremeMemory.
Optional: Plan the appropriate maxXMSize property value to use. This value sets the maximum amount of memory, in megabytes, used by the server for eXtremeMemory.
- In your existing configuration, determine the size per entry. Run the xscmd -c showMapSizes command to determine this size.
- Calculate the maxXMSize value. To get maximum total size of entries (maximum_total_size), multiply the size_per_entry * maximum_number_of_entries. Use no more than 60% of maxXMSize to account for metadata processing. Multiply maximum_total_size* 1.65 to get the maxXMSize value.
What to do next
Security overview
WXS can secure data access, including allowing for integration with external security providers.
In an existing non-cached data store such as a database, you likely have built-in security features that you might not need to actively configure or enable. However, after you have cached your data with WXS, you must consider the important resulting situation that your backend security features are no longer in effect. We can configureeXtreme Scale security on necessary levels so that your new cached architecture for your data is also secured. A brief summary of eXtreme Scale security features follows.
Distributed security basics
Distributed eXtreme Scale security is based on three key concepts:
- Trustable authentication
- The ability to determine the identity of the requester. WXS supports both client-to-server and server-to-server authentication.
- Authorization
- The ability to give permissions to grant access rights to the requester. WXS supports different authorizations for various operations.
- Secure transport
- The safe transmission of data over a network. WXS supports the Transport Layer Security/Secure Sockets Layer (TLS/SSL) protocols.
Authentication
WXS supports a distributed client server framework. A client server security infrastructure is in place to secure access to WXS servers. For example, when authentication is required by the WXS server, a WXS client must provide credentials to authenticate to the server. These credentials can be a user name and password pair, a client certificate, a Kerberos ticket, or data that is presented in a format that is agreed upon by client and server.
Authorization
WXS authorizations are based on subjects and permissions. Use the Java Authentication and Authorization Services (JAAS) to authorize the access, or we can plug in a custom approach, such as Tivoli Access Manager (TAM), to handle the authorizations. The following authorizations can be given to a client or group:
- Map authorization
- Perform insert, read, update, evict, or delete operations on Maps.
- ObjectGrid authorization
- Perform object or entity queries on ObjectGrid objects.
- DataGrid agent authorization
- Allow DataGrid agents to be deployed to an ObjectGrid.
- Server side map authorization
- Replicate a server map to client side or create a dynamic index to the server map.
- Administration authorization
- Perform administration tasks.
Transport security
To secure the client server communication, WXS supports TLS/SSL. These protocols provide transport layer security with authenticity, integrity, and confidentiality for a secure connection between a WXS client and server.
Grid security
In a secure environment, a server must be able to check the authenticity of another server. WXS uses a shared secret key string mechanism for this purpose. This secret key mechanism is similar to a shared password. All the WXS servers agree on a shared secret string. When a server joins the data grid, the server is challenged to present the secret string. If the secret string of the joining server matches the one in the master server, then the joining server can join the grid. Otherwise, the join request is rejected.
Sending a clear text secret is not secure. The eXtreme Scale security infrastructure provides a SecureTokenManager plug-in to allow the server to secure this secret before sending it. We can choose how you implement the secure operation. WXS provides an implementation, in which the secure operation is implemented to encrypt and sign the secret.
JMX security in a dynamic deployment topology
JMX MBean security is supported in all versions of eXtreme Scale. Clients of catalog server MBeans and container server MBeans can be authenticated, and access to MBean operations can be enforced.
Local eXtreme Scale security
Local eXtreme Scale security is different from the distributed eXtreme Scale model because the application directly instantiates and uses an ObjectGrid instance. Your application and eXtreme Scale instances are in the same JVM. Because no client-server concept exists in this model, authentication is not supported. Your applications must manage their own authentication, and then pass the authenticated Subject object to the WXS. However, the authorization mechanism used for the local eXtreme Scale programming model is the same as what is used for the client-server model.
WAS: Securing applications and their environment
Hardware and software requirements
Browse an overview of hardware and operating system requirements. Although we are not required to use a specific level of hardware or operating system for WXS, formally supported hardware and software options are available on the Systems Requirements page of the product support site.
See the System Requirements page for the official set of hardware and software requirements .
We can install and deploy the product in Java EE and Java SE environments. We can also bundle the client component with Java EE applications directly without integrating with WAS.
Hardware requirements
WXS does not require a specific level of hardware. The hardware requirements are dependent on the supported hardware for the Java Platform, Standard Edition installation that you use to run WXS. If we are using eXtreme Scale with WAS or another Java Platform, Enterprise Edition implementation, the hardware requirements of these platforms are sufficient for WXS.
Operating system requirements
Each Java SE and Java EE implementation requires different operating system levels or fixes for problems that are discovered during the testing of the Java implementation. The levels required by these implementations are sufficient for eXtreme Scale.
Installation Manager requirements
Before we can install WXS, install Installation Manager. We can install Installation Manager using the product media, using a file obtained from the Passport Advantage site, or using a file containing the most current version of Installation Manager from the IBM Installation Manager download website .
Web browser requirements
The web console supports the following Web browsers:
- Mozilla Firefox, version 3.5.x and later
- Microsoft Internet Explorer, version 7 and later
WAS requirements
- WAS Version 7.0.0.21 or later
- WAS Version 8.0.0.2 or later
See the Recommended fixes for WAS for more information.
Java requirements
Other Java EE implementations can use the WXS run time as a local instance or as a client to WXS servers. To implement Java SE, use Version 6 or later.
Microsoft .NET considerations
Two .NET environments exist in WXS: the development environment and the runtime environment. These environments have specific sets of requirements.
Development environment requirements
- Microsoft .NET version
- .NET 3.5 and later versions are supported.
- Microsoft Visual studio
- Use one of the following versions of Visual Studio:
- Visual Studio 2008 SP1
- Visual Studio 2010 SP1
- Visual Studio 2012
- Windows
- Any Windows version that is supported by the release of Visual Studio that we are using is supported. See the following links for more information about the Windows requirements for Visual Studio:
- Visual Studio 2008 system requirements
- Visual Studio 2010 Professional system requirements
- Visual Studio 2012 Professional system requirements
- Memory
-
- 1 GB (applies to both 32-bit and 64-bit installations)
- Disk space
- WXS requires 50 MB of available disk space on top of any Visual Studio requirements.
Runtime environment
- Microsoft .NET version
- .NET 3.5 and later versions are supported, including running in a .NET 4.0 only environment.
- Windows
- Any Windows environment that meets the Microsoft .NET version requirements listed above.
- Memory
- 65 MB per process that accesses data stored in WXS servers.
- Disk space
- WXS requires 35 MB of available disk space. When tracing is enabled, additional disk space up to 2.5 GB is required.
- WXS runtime
- You must be using the eXtremeIO transport mechanism when we are using .NET client applications.
Planning to develop Microsoft .NET applications
Java SE considerations
WXS requires Java SE 6, or Java SE 7. In general, newer versions of Java SE have better functionality and performance.
Supported versions
Use WXS with Java SE 6, and Java SE 7. The version that you use must be currently supported by the JRE vendor. To use SSL, use an IBM Runtime Environment.
IBM Runtime Environment, Java Technology Edition Version 6, and Version 7 are supported for general use with the product. Version 6 Service Release 9 Fix Pack 2 is a fully supported JRE that is installed as a part of the stand-alone WXS and WXS client installations in the /path/to/java directory and is available to be used by both clients and servers. If we are installing WXS within WAS, we can use the JRE that is included in the WAS installation. For the web console, use IBM Runtime Environment, Java Technology Edition Version 6 Service Release 7 and later service releases only.
WXS takes advantage of Version 6, and Version 7 functionality as it becomes available. Generally, newer versions of the Java Development Kit (JDK) and Java SE have better performance and functionality.
WXS features that are dependent on Java SE
| Feature | Supported in Java SE 5 and later service releases. | Supported in Java SE Version 6, Version 7 and later service releases |
|---|---|---|
| EntityManager API annotations (Optional: We can also use XML files) | X | X |
| JPA: JPA loader, JPA client loader, and JPA time-based updater | X | X |
| Memory-based eviction (uses MemoryPoolMXBean) | X | X |
| Instrumentation agents:
| X | X |
| Web console for monitoring | X |
Upgrading the JDK in WXS
Common questions about the upgrade process for releases of WXS in both stand-alone and WAS environments follow:
- How do I upgrade the JDK that is included with WXS for WAS?
You need to use the JDK upgrade process that is made available by WAS.
- Which version of the JDK should I use when using WXS in a WAS environment?
Use any level of JDK that is supported by WAS, for the supported version of WAS.
Tuning the IBM virtual machine for Java
Java EE considerations
As you prepare to integrate WXS in a Java Platform, Enterprise Edition environment, consider certain items, such as versions, configuration options, requirements and limitations, and application deployment and management.
Run eXtreme Scale applications in a Java EE environment
A Java EE application can connect to a remote eXtreme Scale application. Additionally, the WAS environment supports starting a WXS server as an application starts in the application server.
If you use an XML file to create an ObjectGrid instance, and the XML file is in the module of the enterprise archive (EAR) file, access the file using the getClass().getClassLoader().getResource("META-INF/objGrid.xml") method to obtain a URL object to use to create an ObjectGrid instance. Substitute the name of the XML file that we are using in the method call.
Use startup beans for an application to bootstrap an ObjectGrid instance when the application starts, and to destroy the instance when the application stops. A startup bean is a stateless session bean with a com.ibm.websphere.startupservice.AppStartUpHome remote location and a com.ibm.websphere.startupservice.AppStartUp remote interface. The remote interface has two methods: the start method and the stop method. Use the start method to bootstrap the instance, and use the stop method to destroy the instance. The application uses the ObjectGridManager.getObjectGrid method to maintain a reference to the instance.
Use class loaders
When application modules that use different class loaders share a single ObjectGrid instance in a Java EE application, verify the objects that are stored in eXtreme Scale and the plug-ins for the product are in a common loader in the application.
Manage the life cycle of ObjectGrid instances in a servlet
To manage the life cycle of an ObjectGrid instance in a servlet, we can use the init method to create the instance and the destroy method to remove the instance. If the instance is cached, it is retrieved and manipulated in the servlet code.
Tuning the IBM virtual machine for Java
Directory conventions
The following directory conventions are used throughout the documentation to must reference special directories such as wxs_install_root and wxs_home . You access these directories during several different scenarios, including during installation and use of command-line tools.
- wxs_install_root
- The wxs_install_root directory is the root directory where WXS product files are installed. The wxs_install_root directory can be the directory in which the trial archive is extracted or the directory in which the WXS product is installed.
- Example when extracting the trial:
Example: /opt/IBM/WebSphere/eXtremeScale
- Example when WXS is installed to a stand-alone directory:
Example: /opt/IBM/eXtremeScale
Example: C:\Program Files\IBM\WebSphere\eXtremeScale
- Example when WXS is integrated with WAS:
Example: /opt/IBM/WebSphere/AppServer
- Example when extracting the trial:
- wxs_home
- The wxs_home directory is the root directory of the WXS product libraries, samples, and components. This directory is the same as the wxs_install_root directory when the trial is extracted. For stand-alone installations, the wxs_home directory is the ObjectGrid subdirectory within the wxs_install_root directory.
For installations that are integrated with WAS, this directory is the optionalLibraries/ObjectGrid directory within the wxs_install_root directory.
- Example when extracting the trial:
Example: /opt/IBM/WebSphere/eXtremeScale
- Example when WXS is installed to a stand-alone directory:
Example: /opt/IBM/eXtremeScale/ObjectGrid
Example: wxs_install_root \ObjectGrid
- Example when WXS is integrated with WAS:
Example: /opt/IBM/WebSphere/AppServer/optionalLibraries/ObjectGrid
- Example when extracting the trial:
- was_root
- The was_root directory is the root directory of a WAS installation:
Example: /opt/IBM/WebSphere/AppServer
- net_client_home
- The net_client_home directory is the root directory of a .NET client installation.
Example: C:\Program Files\IBM\WebSphere\eXtreme Scale .NET Client
- restservice_home
- The restservice_home directory is the directory in which the WXS REST data service libraries and samples are located. This directory is named restservice and is a subdirectory under the wxs_home directory.
- Example for stand-alone deployments:
Example: /opt/IBM/WebSphere/eXtremeScale/ObjectGrid/restservice
Example: wxs_home\restservice
- Example for WAS integrated deployments:
Example: /opt/IBM/WebSphere/AppServer/optionalLibraries/ObjectGrid/restservice
- Example for stand-alone deployments:
- tomcat_root
- The tomcat_root is the root directory of the Apache Tomcat installation.
Example: /opt/tomcat5.5
- wasce_root
- The wasce_root is the root directory of the WAS Community Edition installation.
Example: /opt/IBM/WebSphere/AppServerCE
- java_home
- The java_home is the root directory of a Java Runtime Environment (JRE) installation.
Example: /opt/IBM/WebSphere/eXtremeScale/java
Example: wxs_install_root \java
- samples_home
- The samples_home is the directory in which you extract the sample files used for tutorials.
Example: wxs_home /samples
Example: wxs_home\samples
- dvd_root
- The dvd_root directory is the root directory of the DVD that contains the product.
Example: dvd_root/docs/
- equinox_root
- The equinox_root directory is the root directory of the Eclipse Equinox OSGi framework installation.
Example:/opt/equinox
- $HOME
- The $HOME directory is the location where user files are stored, such as security profiles.
c:\Documents and Settings\user_name
/home/user_name
Plan environment capacity
If you have an initial data set size and a projected data set size, we can plan the capacity that you need to run WXS. By using these planning exercises, we can deploy WXS efficiently for future changes and maximize the elasticity of the data grid, which you would not have with a different scenario such as an in-memory database or other type of database.
Enable disk overflow
When disk overflow is enabled, we can extend the data grid capacity by moving cache entries out of memory and onto disk. Use the diskOverflowEnabled property in the server properties file to enable the disk overflow feature. When enabled, entries that do not fit into the available memory capacity of the container servers are stored on disk. The disk storage is not a persistent store. Entries that are written to disk are deleted when container servers restart, in the same way that cache entries that are stored in memory are lost during a container server restart.
Enable eXtreme memory for this feature to work.
When disk overflow is enabled, it attempts to keep the most recently used cache entries in memory. Disk overflow moves cache entries to disk only when the number of entries in memory exceed the maximum memory allocation, as defined by the maxXMSize server property. If more entries exist than can fit in memory, the least recently used entries are moved to disk. As a result, operations that access entries that are on disk are slower than the response time for entries that are in memory. After the initial access, the item stays in memory unless it becomes a least recently used entry again. When an entry is least recently used, it is moved disk in favor of some other entry.
- Stop the container server on which we want to enable disk overflow.
- Set the following properties in the server properties file:
- diskOverflowEnabled
- Enables the native overflow disk feature.
Enable eXtreme Memory for this feature to work.
Default: false
- diskOverflowCapBytes
- Maximum amount of disk space used by this server for disk overflow, in bytes. The default value specifies that there is no limit on how much is stored on disk.
Default: Long.MAX_VALUE
- diskStoragePath
- Absolute path to a directory location used for storing overflow content.
- diskOverflowMinDiskSpaceBytes
- Entries will not be moved to disk if there is less than this amount of space free in diskStoragePath, in bytes.
Default: 0
- Restart your container servers .
Sizing memory and partition count calculation
We can calculate the amount of memory and partitions needed for your specific configuration.
This topic applies when we are not using the COPY_TO_BYTES copy mode. If we are using the COPY_TO_BYTES mode, then the memory size is much less and the calculation procedure is different.
WXS stores data within the address space of Java virtual machines (JVM). Each JVM provides processor space for servicing create, retrieve, update, and delete calls for the data that is stored in the JVM. In addition, each JVM provides memory space for data entries and replicas. Java objects vary in size, therefore make a measurement to make an estimate of how much memory you need.
To size the memory that you need, load the application data into a single JVM. When the heap usage reaches 60%, note the number of objects used. This number is the maximum recommended object count for each of your JVMs. To get the most accurate sizing, use realistic data and include any defined indexes in your sizing because indexes also consume memory. The best way to size memory use is to run garbage collection verbosegc output because this output gives you the numbers after garbage collection. We can query the heap usage at any given point through MBeans or programmatically, but those queries give you only a current snapshot of the heap. This snapshot might include uncollected garbage, so using that method is not an accurate indication of the consumed memory.
Scaling up the configuration
Number of shards per partition (numShardsPerPartition value)
To calculate the number of shards per partition, or the numShardsPerPartition value, add 1 for the primary shard plus the total number of replica shards we want.
- numShardsPerPartition = 1 + total_number_of_replicas
Number of JVMs (minNumJVMs value)
To scale up the configuration, first decide on the maximum number of objects that need to be stored in total. To determine the number of JVMs you need, use the following formula:
- minNumJVMS=(numShardsPerPartition * numObjs) / numObjsPerJVM
Round this value up to the nearest integer value.
Number of shards (numShards value) At the final growth size, use 10 shards for each JVM. As described before, each JVM has one primary shard and (N-1) shards for the replicas, or in this case, nine replicas. Because you already have a number of JVMs to store the data, we can multiply the number of JVMs by 10 to determine the number of shards:
- numShards = minNumJVMs * 10 shards/JVM
Number of partitions If a partition has one primary shard and one replica shard, then the partition has two shards (primary and replica). The number of partitions is the shard count divided by 2, rounded up to the nearest prime number. If the partition has a primary and two replicas, then the number of partitions is the shard count divided by 3, rounded up to the nearest prime number.
- numPartitions = numShards / numShardsPerPartition
Example of scaling
In this example, the number of entries begins at 250 million. Each year, the number of entries grows about 14%. After seven years, the total number of entries is 500 million, so you must plan your capacity accordingly. For high availability, a single replica is needed. With a replica, the number of entries doubles, or 1,000,000,000 entries. As a test, 2 million entries can be stored in each JVM. Using the calculations in this scenario the following configuration is needed:
- 500 JVMs to store the final number of entries.
- 5000 shards, calculated by multiplying 500 JVMs by 10.
- 2500 partitions, or 2503 as the next highest prime number, calculated by taking the 5000 shards, divided by two for primary and replica shards.
Starting configuration Based on the previous calculations, start with 250 JVMs and grow toward 500 JVMs over five years. With this configuration, we can manage incremental growth until you arrive at the final number of entries.
In this configuration, about 200,000 entries are stored per partition (500 million entries divided by 2503 partitions).
When the maximum number of JVMs is reached When you reach your maximum number of 500 JVMs, we can still grow the data grid. As the number of JVMs grows beyond 500, the shard count begins to drop below 10 for each JVM, which is below the recommended number. The shards start to become larger, which can cause problems. Repeat the sizing process considering future growth again, and reset the partition count. This practice requires a full data grid restart, or an outage of the data grid.
Number of servers
Do not use paging on a server under any circumstances. A single JVM uses more memory than the heap size. For example, 1 GB of heap for a JVM actually uses 1.4 GB of real memory. Determine the available free RAM on the server. Divide the amount of RAM by the memory per JVM to get the maximum number of JVMs on the server.
Sizing CPU per partition for transactions
Although a major functionality of eXtreme Scale is its ability for elastic scaling, it is also important to consider sizing and to adjust the ideal number of CPUs to scale up.
Processor costs include:
- Cost of servicing create, retrieve, update, and delete operations from clients
- Cost of replication from other Java virtual machines
- Cost of invalidation
- Cost of eviction policy
- Cost of garbage collection
- Cost of application logic
- Cost of serialization
JVMs per server
Use two servers and start the maximum JVM count per server. Use the calculated partition counts from the previous section. Then, preload the JVMs with enough data to fit on these two computers only. Use a separate server as a client. Run a realistic transaction simulation against this data grid of two servers.
To calculate the baseline, try to saturate the processor usage. If we cannot saturate the processor, then it is likely that the network is saturated. If the network is saturated, add more network cards and round robin the JVMs over the multiple network cards.
Run the computers at 60% processor usage, and measure the create, retrieve, update, and delete transaction rate. This measurement provides the throughput on two servers. This number doubles with four servers, doubles again at 8 servers, and so on. This scaling assumes that the network capacity and client capacity is also able to scale.
As a result, eXtreme Scale response time should be stable as the number of servers is scaled up. The transaction throughput should scale linearly as computers are added to the data grid.
Sizing CPUs for parallel transactions
Single-partition transactions have throughput scaling linearly as the data grid grows. Parallel transactions are different from single-partition transactions because they touch a set of the servers (this can be all of the servers).
If a transaction touches all of the servers, then the throughput is limited to the throughput of the client that initiates the transaction or the slowest server touched. Larger data grids spread the data out more and provide more processor space, memory, network, and so on. However, the client must wait for the slowest server to respond, and the client must consume the results of the transaction.
When a transaction touches a subset of the servers, M out of N servers get a request. The throughput is then N divided by M times faster than the throughput of the slowest server. For example, if you have 20 servers and a transaction that touches 5 servers, then the throughput is 4 times the throughput of the slowest server in the data grid.
When a parallel transaction completes, the results are sent to the client thread that started the transaction. This client must then aggregate the results single threaded. This aggregation time increases as the number of servers touched for the transaction grows. However, this time depends on the application because it is possible that each server returns a smaller result as the data grid grows.
Typically, parallel transactions touch all of the servers in the data grid because partitions are uniformly distributed over the grid. In this case, throughput is limited to the first case.
Summary
With this sizing, you have three metrics, as follows.
- Number of partitions.
- Number of servers that are needed for the memory that is required.
- Number of servers that are needed for the required throughput.
If you need 10 servers for memory requirements, but we are getting only 50% of the needed throughput because of the processor saturation, then you need twice as many servers.
For the highest stability, you should run your servers at 60% processor loading and JVM heaps at 60% heap loading. Spikes can then drive the processor usage to 80.90%, but do not regularly run your servers higher than these levels.
Plan to develop WXS applications
Set up your development environment and learn where to find details about available programming interfaces.
When you have an enterprise data grid configured, we can create both Java and Microsoft .NET applications that access the same data grid. These development environments have different prerequisites and requirements to investigate before you begin developing the applications.
Planning to develop Microsoft .NET applications
Java API overview
WXS provides several features that are accessed programmatically using the Java programming language through application programming interfaces (APIs) and system programming interfaces.
WXS APIs
When we are using eXtreme Scale APIs, you must distinguish between transactional and non-transactional operations. A transactional operation is an operation that is performed within a transaction. ObjectMap, EntityManager, Query, and DataGrid API are transactional APIs that are contained inside the Session that is a transactional container. Non-transactional operations have nothing to do with a transaction, such as configuration operations.
The ObjectGrid, BackingMap, and plug-in APIs are non-transactional. The ObjectGrid, BackingMap, and other configuration APIs are categorized as ObjectGrid Core API. Plug-ins are for customizing the cache to achieve the functions that we want, and are categorized as the System Programming API. A plug-in in eXtreme Scale is a component that provides a certain type of function to the pluggable eXtreme Scale components that include ObjectGrid and BackingMap. A feature represents a specific function or characteristic of a WXS component, including ObjectGrid, Session, BackingMap, ObjectMap, and so on. Typically, features are configurable with configuration APIs. Plug-ins can be built-in, but might require that you develop your own plug-ins in some situations.
We can normally configure the ObjectGrid and BackingMap to meet the application requirements. When the application has special requirements, consider using specialized plug-ins. WXS might have built-in plug-ins that meet your requirements. For example, if you need a peer-to-peer replication model between two local ObjectGrid instances or two distributed eXtreme Scale grids, the built-in JMSObjectGridEventListener is available. If none of the built-in plug-ins can solve your business problems, refer to the System Programming API to provide your own plug-ins.
ObjectMap is a simple map-based API. If the cached objects are simple and no relationship is involved, the ObjectMap API is ideal for the application. If object relationships are involved, use the EntityManager API, which supports graph-like relationships.
Query is a powerful mechanism for finding data in the ObjectGrid. Both Session and EntityManager provide the traditional query capability.
The DataGrid API is a powerful computing capability in a distributed eXtreme Scale environment that involves many machines, replicas, and partitions. Applications can run business logic in parallel in all of the nodes in the distributed eXtreme Scale environment. The application can obtain the DataGrid API through the ObjectMap API.
The WXS REST data service is a Java HTTP service that is compatible with Microsoft WCF Data Services (formally ADO.NET Data Services) and implements the Open Data Protocol (OData). The REST data service allows any HTTP client to access a WXS grid. It is compatible with the WCF Data Services support that is supplied with the Microsoft .NET Framework 3.5 SP1. RESTful applications can be developed with the rich tooling provided by Microsoft Visual Studio 2008 SP1. For more details, refer to the eXtreme Scale REST data service user guide .
Java plug-ins overview
A WXS plug-in is a component that provides a certain type of function to the pluggable components that include ObjectGrid and BackingMap. WXS provides several plug points to allow applications and cache providers to integrate with various data stores, alternative client APIs and to improve overall performance of the cache. The product ships with several default, prebuilt plug-ins, but we can also build custom plug-ins with the application.
All plug-ins are concrete classes that implement one or more eXtreme Scale plug-in interfaces. These classes are then instantiated and invoked by the ObjectGrid at appropriate times. The ObjectGrid and BackingMaps each allow custom plug-ins to be registered.
ObjectGrid plug-ins
The following plug-ins are available for an ObjectGrid instance. If the plug-in is server side only, the plug-ins are removed on the client ObjectGrid and BackingMap instances. The ObjectGrid and BackingMap instances are only on the server.
| TransactionCallback | A TransactionCallback plug-in provides transaction life cycle events. If the TransactionCallback plug-in is the built-in JPATxCallback (com.ibm.websphere.objectgrid.jpa.JPATxCallback) class implementation, then the plug-in is server side only. However, the subclasses of the JPATxCallback class are not server side only. |
| ObjectGridEventListener | An ObjectGridEventListener plug-in provides ObjectGrid life cycle events for the ObjectGrid, shards, and transactions. |
| ObjectGridLifecycleListener | An ObjectGridLifecycleListener plug-in provides ObjectGrid life cycle events for the ObjectGrid instance. The ObjectGridLifecycleListener plug-in can be used as an optional mixin interface for all other ObjectGrid plug-ins. |
| ObjectGridPlugin | An ObjectGridPlugin is an optional mix-in interface that provides extended life cycle management events for all other ObjectGrid plug-ins. |
| SubjectSource, ObjectGridAuthorization, SubjectValidation | eXtreme Scale provides several security endpoints to allow custom authentication mechanisms to be integrated with WXS. (Server side only) |
Common ObjectGrid plug-in requirements
The ObjectGrid instantiates and initializes plug-in instances using JavaBeans conventions. All of the previous plug-in implementations have the following requirements:
- The plug-in class must be a top-level public class.
- The plug-in class must provide a public, no-argument constructor.
- The plug-in class must be available in the class path for both servers and clients (as appropriate).
- Attributes must be set using the JavaBeans style property methods.
- Plug-ins, unless specifically noted, are registered before ObjectGrid initializes and cannot be changed after the ObjectGrid is initialized.
BackingMap plug-ins
The following plug-ins are available for a BackingMap:
| Evictor | An evictor plug-in is a default mechanism is provided for evicting cache entries and a plug-in for creating custom evictors . The built in time-to-live evictor uses a time-based algorithm to decide when an entry in BackingMap must be evicted. Some applications might need to use a different algorithm for deciding when a cache entry needs to be evicted. The Evictor plug-in makes a custom designed Evictor available to the BackingMap to use. The Evictor plug-in is in addition to the built in time-to-live evictor. Use the provided custom Evictor plug-in that implements well-known algorithms such as "least recently used" or "least frequently used". Applications can either plug-in one of the provided Evictor plug-ins or it can provide its own Evictor plug-in. |
| ObjectTransformer
| An ObjectTransformer plug-in allows us to serialize, deserialize, and copy objects in the cache. The ObjectTransformer interface has been replaced by the DataSerializer plug-ins, which we can use to efficiently store arbitrary data in WXS so that existing product APIs can efficiently interact with your data. |
| OptimisticCallback
| An OptimisticCallback plug-in allows us to customize versioning and comparison operations of cache objects when we are using the optimistic lock strategy. The OptimisticCallback plug-in has been replaced by the ValueDataSerializer.Versionable interface, which we can implement when you use the DataSerializer plug-in with the COPY_TO_BYTES copy mode or when you use the @Version annotation with the EntityManager API. |
| MapEventListener | A MapEventListener plug-in provides callback notifications and significant cache state changes that occur for a BackingMap. An application might want to know about BackingMap events such as a map entry eviction or a preload of a BackingMap completion. A BackingMap calls methods on the MapEventListener plug-in to notify an application of BackingMap events. An application can receive notification of various BackingMap events using the setMapEventListener method to provide one or more custom designed MapEventListener plug-ins to the BackingMap. The application can modify the listed MapEventListener objects using the addMapEventListener method or the removeMapEventListener method. |
| BackingMapLifecycleListener | A BackingMapLifecycleListener plug-in provides BackingMap life cycle events for the BackingMap instance. The BackingMapLifecycleListener plug-in can be used as an optional mix-in interface for all other BackingMap plug-ins. |
| BackingMapPlugin | A BackingMapPlugin is an optional mix-in interface that provides extended life cycle management events for all other BackingMap plug-ins. |
| Indexing | Use the indexing feature, which is represented by the MapIndexplug-in plug-in, to build an index or several indexes on a BackingMap map to support non-key data access. |
| Loader | A Loader plug-in on an ObjectGrid map acts as a memory cache for data that is typically kept in a persistent store on either the same system or some other system. (Server side only) For example, a Java database connectivity (JDBC) Loader can be used to move data in and out of a BackingMap and one or more relational tables of a relational database. A relational database does not need to be used as the persistent store for a BackingMap. The Loader can also be used to moved data between a BackingMap and a file, between a BackingMap and a Hibernate map, between a BackingMap and a Java 2 Platform, Enterprise Edition (JEE) entity bean, between a BackingMap and another application server, and so on. The application must provide a custom-designed Loader plug-in to move data between the BackingMap and the persistent store for every technology used. If a Loader is not provided, the BackingMap becomes a simple in-memory cache. |
| MapSerializerPlugin | A MapSerializerPlugin allows us to serialize and inflate Java objects and non-Java data in the cache. It is used with the DataSerializer mix-in interfaces, allowing robust and flexible options for high-performance applications. |
REST data services overview
The WXS REST data service is a Java HTTP service that is compatible with Microsoft WCF Data Services (formally ADO.NET Data Services) and implements the Open Data Protocol (OData). Microsoft WCF Data Services is compatible with this specification when using Visual Studio 2008 SP1 and the .NET Framework 3.5 SP1.
Compatibility requirements
The REST data service allows any HTTP client to access a data grid. The REST data service is compatible with the WCF Data Services support supplied with the Microsoft .NET Framework 3.5 SP1. RESTful applications can be developed with the rich tooling provided by Microsoft Visual Studio 2008 SP1. The figure provides an overview of how WCF Data Services interacts with clients and databases.
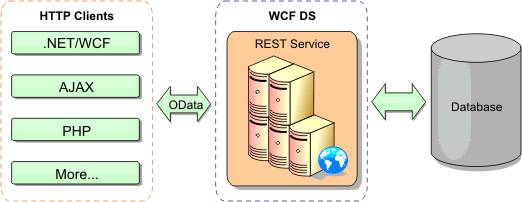
WXS includes a function-rich API set for Java clients. As shown in the following figure, the REST data service is a gateway between HTTP clients and the WXS data grid, communicating with the grid through an WXS client. The REST data service is a Java servlet, which allows flexible deployments for common Java Platform, Enterprise Edition (JEE) platforms, such as WAS. The REST data service communicates with the WXS data grid using the WXS Java APIs. It allows WCF Data Services clients or any other client that can communicate with HTTP and XML.
Figure 2. WXS REST data service
Refer to the Configuring REST data services, or use the following links to learn more about WCF Data Services.
- Microsoft WCF Data Services Developer Center
- ADO.NET Data Services overview on MSDN
- Whitepaper: Using ADO.NET Data Services
- Atom Publish Protocol: Data Services URI and Payload Extensions
- Conceptual Schema Definition File Format
- Entity Data Model for Data Services Packaging Format
- Open Data Protocol
- Open Data Protocol FAQ
Features
This version of the WXS REST data service supports the following features:
- Automatic modeling of eXtreme Scale EntityManager API entities as WCF Data Services entities, which includes the following support:
- Java data type to Entity Data Model type conversion
- Entity association support
- Schema root and key association support, which is required for partitioned data grids
- Atom Publish Protocol (AtomPub or APP) XML and JavaScript Object Notation (JSON) data payload format.
- Create, Read, Update and Delete (CRUD) operations using the respective HTTP request methods: POST, GET, PUT and DELETE. In addition, the Microsoft extension: MERGE
is supported.
Note: The upsert and upsertAll methods replace the ObjectMap put and putAll methods.
Use the upsert method to tell the BackingMap and loader that an entry in the data grid needs to place the key and value into the grid. The BackingMap and loader does either an insert or an update to place the value into the grid and loader. If we run the upsert API within the applications, then the loader gets an UPSERT LogElement type, which allows loaders to do database merge or upsert calls instead of using insert or update.
- Simple queries, using filters
- Batch retrieval and change set requests
- Partitioned data grid support for high availability
- Interoperability with WXS EntityManager API clients
- Support for standard JEE Web servers
- Optimistic concurrency
- User authorization and authentication between the REST data service and the WXS data grid
Known problems and limitations
- Tunneled requests are not supported.
Spring framework overview
Spring is a framework for developing Java applications. WXS provides support to allow Spring to manage transactions and configure the clients and servers comprising your deployed in-memory data grid.
Spring cache provider
Spring Framework Version 3.1 introduced a new cache abstraction. With this new abstraction, we can transparently add caching to an existing Spring application. Use WXS as the cache provider for the cache abstraction.
Spring managed native transactions
Spring provides container-managed transactions that are similar to a Java Platform, Enterprise Edition application server. However, the Spring mechanism can use different implementations. WXS provides transaction manager integration which allows Spring to manage the ObjectGrid transaction life cycles.
Spring managed extension beans and namespace support
Also, eXtreme Scale integrates with Spring to allow Spring-style beans defined for extension points or plug-ins. This feature provides more sophisticated configurations and more flexibility for configuring the extension points.
In addition to Spring managed extension beans, eXtreme Scale provides a Spring namespace called "objectgrid". Beans and built-in implementations are pre-defined in this namespace, which makes it easier for users to configure eXtreme Scale.
Shard scope support
With the traditional style Spring configuration, an ObjectGrid bean can either be a singleton type or prototype type. ObjectGrid also supports a new scope called the "shard" scope. If a bean is defined as shard scope, then only one bean is created per shard. All requests for beans with an ID or IDs matching that bean definition in the same shard results in that one specific bean instance being returned by the Spring container.
The following example shows that a com.ibm.ws.objectgrid.jpa.plugins.JPAPropFactoryImpl bean is defined with scope set to shard. Therefore, only one instance of the JPAPropFactoryImpl class is created per shard.
- <bean id="jpaPropFactory" class="com.ibm.ws.objectgrid.jpa.plugins.JPAPropFactoryImpl" scope="shard" />
Spring Web Flow
Spring Web Flow stores its session state in an HTTP session by default. If a web application uses eXtreme Scale for session management, then Spring automatically stores state with WXS. Also, fault tolerance is enabled in the same manner as the session.
Packaging
The eXtreme Scale Spring extensions are in the ogspring.jar file. This JAR file must be on the class path for Spring support to work. If a Java EE application running in a WebSphere Extended Deployment augmented WAS Network Deployment, put the spring.jar file and its associated files in the enterprise archive (EAR) modules. Also place the ogspring.jar file in the same location.
Java class loader and classpath considerations
Because WXS stores Java objects in the cache by default, you must define classes on the classpath wherever the data is accessed.
Specifically, WXS client and container processes must include the classes or JAR files in the classpath when starting the process. When we are designing an application for use with WXS, separate out any business logic from the persistent data objects.
Relationship management
Object-oriented languages such as Java., and relational databases support relationships or associations. Relationships decrease the amount of storage through the use of object references or foreign keys.
When using relationships in a data grid, the data must be organized in a constrained tree. One root type must exist in the tree and all children must be associated to only one root. For example: Department can have many Employees and an Employee can have many Projects. But a Project cannot have many Employees that belong to different departments. Once a root is defined, all access to that root object and its descendants are managed through the root. WXS uses the hash code of the root object's key to choose a partition. For example:
- partition = (hashCode MOD numPartitions)
When all of the data for a relationship is tied to a single object instance, the entire tree can be collocated in a single partition and can be accessed very efficiently using one transaction. If the data spans multiple relationships, then multiple partitions must be involved which involves additional remote calls, which can lead to performance bottlenecks.
Reference data
Some relationships include look-up or reference data such as: CountryName. For look-up or reference data, the data must exist in every partition. The data can be accessed by any root key and the same result is returned. Reference data such as this should only be used in cases where the data is fairly static. Updating this data can be expensive because the data needs to be updated in every partition. The DataGrid API is a common technique to keeping reference data up-to-date.
Costs and benefits of normalization
Normalizing the data using relationships can help reduce the amount of memory used by the data grid since duplication of data is decreased. However, in general, the more relational data that is added, the less it will scale out. When data is grouped together, it becomes more expensive to maintain the relationships and to keep the sizes manageable. Since the grid partitions data based on the key of the root of the tree, the size of the tree isn't taken into account. Therefore, if you have a lot of relationships for one tree instance, the data grid may become unbalanced, causing one partition to hold more data than the others.
When the data is denormalized or flattened, the data that would normally be shared between two objects is instead duplicated and each table can be partitioned independently, providing a much more balanced data grid. Although this increases the amount of memory used, it allows the application to scale since a single row of data can be accessed that has all of the necessary data. This is ideal for read-mostly grids since maintaining the data becomes more expensive.
For more information, see Classifying XTP systems and scaling .
Manage relationships using the data access APIs
The ObjectMap API is the fastest, most flexible and granular of the data access APIs, providing a transactional, session-based approach at accessing data in the grid of maps. The ObjectMap API allows clients to use common CRUD (create, read, update and delete) operations to manage key-value pairs of objects in the distributed data grid.
When using the ObjectMap API, object relationships must be expressed by embedding the foreign key for all relationships in the parent object.
An example follows.
public class Department {
Collection<String> employeeIds;}
The EntityManager API simplifies relationship management by extracting the persistent data from the objects including the foreign keys. When the object is later retrieved from the data grid, the relationship graph is rebuilt, as in the following example.
@Entity public class Department {
Collection<String> employees;}
The EntityManager API is very similar to other Java object persistence technologies such as JPA and Hibernate in that it synchronizes a graph of managed Java object instances with the persistent store. In this case, the persistent store is a WXS data grid, where each entity is represented as a map and the map contains the entity data rather than the object instances.
Cache key considerations
WXS uses hash maps to store data in the grid, where a Java object is used for the key.
Guidelines
When choosing a key, consider the following requirements:
- Keys can never change. If a portion of the key needs to change, then the cache entry should be removed and reinserted.
- Keys should be small. Since keys are used in every data access operation, it's a good idea to keep the key small so that it can be serialized efficiently and use less memory.
- Implement a good hash and equals algorithm. The hashCode and equals(Object o) methods must always be overridden for each key object.
- Cache the key's hashCode. If possible, cache the hash code in the key object instance to speed up hashCode() calculations. Since the key is immutable, the hashCode should be cacheable.
- Avoid duplicating the key in the value. When using the ObjectMap API, it is convenient to store the key inside the value object. When this is done, the key data is duplicated in memory.
Data for different time zones
When inserting data with calendar, java.util.Date, and timestamp attributes into an ObjectGrid, you must ensure these date time attributes are created based on same time zone, especially when deployed into multiple servers in various time zones. Using the same time zone based date time objects can ensure the application is time-zone safe and data can be queried by calendar, java.util.Date and timestamp predicates.
Without explicitly specifying a time zone when creating date time objects, Java uses the local time zone and may cause inconsistent date time values in clients and servers.
Consider an example in a distributed deployment in which client1 is in time zone [GMT-0] and client2 is in [GMT-6] and both want to create a java.util.Date object with value '1999-12-31 06:00:00'. Then client1 will create java.util.Date object with value '1999-12-31 06:00:00 [GMT-0]' and client2 will create java.util.Date object with value '1999-12-31 06:00:00 [GMT-6]'. Both java.util.Date objects are not equal because the time zone is different. A similar problem occurs when preloading data into partitions residing in servers in different time zones if local time zone is used to create date time objects.
To avoid the described problem, the application can choose a time zone such as [GMT-0] as the base time zone for creating calendar, java.util.Date, and timestamp objects.