IBM WebSphere XD V6.0 Introduction
Overview
IBM WebSphere Extended Deployment (XD), V6.0 is an add-on to your existing WebSphere Network Deployment (ND) environment that addresses high availability and reliability.
WebSphere XD implements a virtualized environment by creating pools of resources that can be shared among applications. As resources are needed for expected and unexpected spikes in workload demand, application resources can be allocated to where they are needed most. Allocating resources on an on-demand basis enables better use of computing resources that we already own and, potentially, might allow us to run more applications on the machines that we already have in place.
XD offers...
- Resource management
Performance, throughput, scalability, prioritization, state management and overload protection provided through features like...
- Traffic management
Administration, traffic routing and control, application deployment control, health management and monitoring provided through features like...
- Infrastructure for compute intensive and Java batch applications.
Enable middleware to handle new types of applications including high-rate OLTP and long-running applications provided through features like...
XD v6.1 will not contain any new facilities. It is a refactoring release.
Application Placement
- Autonomic placement of cluster members (server instances) on nodes
- Starts/stops preconfigured cluster members
Configured via the Application Placement Controller
Dynamic Operations
- Support for On-Demand Autonomics for WebSphere Environments.
Service Policies for Workload and Resource Management
- Goal-based
- Differentiated Workloads
- Health Policies for early detection and automated correction of system problems
- Does not require any application changes (All on the operations side)o
High performance Computing (Partitioning/Object Grid)
Support for highly scalable, partitioned applications
- Requires applications changes for full benefits
- Enables high-available, linear scalability for applications
- Enables HA-managed singletons within applications
- Business grid for mixed workloads
- ObjectGrid for distributed cache access
Extended Manageability
Simplified admin for clustered environments
- Dynamic clusters
- server templates
- cluster level resources
- operational monitoring
- real-time views of system state, load, and goal attainment
Business Grid
- White space harvesting
- 2 types of long running applications
Extended capabilities
WebSphere XD capabilities can help us handle the IT scalability and performance challenges of on-demand operations. Leveraging the principles and concepts of proven IBM systems and years of IBM research and client experience, WebSphere XD enables:
- Dynamic operations
Allow our application environment to scale as needed with the virtualization of WebSphere resources and the use of a goals-directed infrastructure, helping us increase the speed at which our company can adapt to business demands.
WebSphere XD dynamic operations capabilities help increase responsiveness and flexibility. WebSphere XD is designed to deliver dynamic operations through two key capabilities: the virtualization of WebSphere environments and a goals-directed infrastructure. A virtualized WebSphere environment allows us to grow our solution as business needs dictate through the dynamic allocation of WebSphere resources.
- Extended manageability
Offers simpler and improved management of complex system operations with advanced, meaningful real-time visualization tools and gradual, controlled implementation of autonomic computing capabilities, helping us reduce the cost of managing IT resources.
- High performance computing
Enhances the quality of service of business-critical applications to support near linear scalability for high end transaction processing, helping us improve customer service levels.
Packaging
XD is provided in two packages
- Full license provides all of the features of XD and is intended for extending a WebSphere server environment. The full license prereqs a WebSphere server that contains ND 6.0.2 or higher
- WAS ND 6.0.2.x
- WebSphere Process Server 6.0.1
- WebSphere Portal Server 5.1.02 or higher
- WebSphere Commerce Server 5.6.1.1 or higher
- Mixed Server Enviornments (MSE) license is a subset of XD that supports non-WebSphere server envs and odes not have a prereq requirement
There are three primary installation scenarios for XD:
- XD as an extension to a WebSphere server env
- XD as an extension to a non-WebSphere server env
- XD ObjectGrid used standalone in any Java environment (server or non-server)
Installation is a simple delta to an exisitng env. Does not require migration or restructuring of current installation. Extends the WAS admin Console and wsadmin scripting environment.
Mixed Version Support
A WebSphere XD Version 6.0 cell can contain:
- WebSphere XD v6 nodes
- WAS v6 nodes
- WAS v5.1 nodes
WebSphere XD v6 cell can not contain WebSphere XD v5.1 nodes
Operational Modes
- Manual
- User controlled management of dynamic clusters
- Dynamic Cluster Manager (DCMgr) does not suggest or make automatic decisions
- Supervised
- User controlled provisioning of dynamic clusters, DCMgr guided
- DCMgr suggests provisioning actions to user
- Usage scenarios
- user accepts suggestion
- user denies suggestion
- future consecutive equivalent suggestions suppressed
- user manually executes suggestion
- user manually executes alternate action
- no action taken
- Automatic
- DCMgr controlled provisioning of dynamic clusters
- DCMgr initiated actions for execution
Resource sharing
Sharing resources among applications helps to optimize utilization and simplify deployment. WebSphere XD redefines the relationship between traditional J2EE constructs. Instead of deploying applications directly onto a server, we can map an application into a resource pool. This application can then be deployed on some subset of servers within that pool according to our configured business goals. The WebSphere XD virtualized infrastructure is predicated on two new constructs:
- node groups (which represent resource pools)
- dynamic clusters
Node groups
In WebSphere XD, the relationship between applications and the nodes on which they can be run is expressed as an intermediate construct called a node group. In concrete terms, a node group is nothing more than a set of machines. In a more abstract sense, a node group is a pool of machines with a common set of capabilities and properties such as connectivity to a given network or the capability to connect to a certain type of database. These characteristics are not explicitly defined; node group attributes are purely implicit in the WebSphere XD design.
Within a node group, one or more dynamic clusters are created. The computing power represented by a node group is divided among its member dynamic clusters. This distribution of resources is modified autonomically according to business goals to compensate for changing workload patterns.
Because a node group's set of common capabilities and properties is required by some suite of applications, a node group defines the collection of machines able to run a given application. Because the administrator now understands what is implied by participation in a given node group, he or she can ensure that applications are deployed into node groups where they can be accommodated. The resources in a given node group are dynamically allocated according to load and policy to deliver better resource utilization, leading to cost savings. Implementing virtualization using node groups breaks the tie between application clusters and machines, and enables them to be shared among applications, optimizing resource utilization and simplifying overall deployment.
Dynamic clusters
First, we choose a node group that satisfies application requirements, then we create a dynamic cluster.
Cluster applications (.ear files) are deployed into a dynamic cluster in much the same fashion as they are deployed into WebSphere ND static clusters. However, WebSphere XD supports autonomic expansion and contraction of a dynamic cluster within its parent node group. Thus, periodic spikes in demand for an application result in a corresponding increase in that application's resource for processing requests. The strategy for increasing these resources is dictated by operational policies that reflect business goals.
Operational policy
WebSphere XD can differentiate application service levels according to business requirements. User requests are classified, prioritized, queued and routed to servers based on application operational policies. Important applications get the highest priority access to our WebSphere resources.
WebSphere XD offers two types of operational policies: service policy and health policy.
Service policy
Through service policy, WebSphere XD introduces the capability to designate the performance goal and business importance of different request types. This allows an enterprise's performance to degrade in a controlled manner in periods of over-utilization. Service policies definitions are made up of two key items: goals and importance. The goal portion of the service policy defines how incoming work is evaluated and managed in order to ensure and detect if work is meeting its assigned service policy levels. The importance is used in times of resource contention in order to identify the most important work in the system, and give it the priority.
Service goal types
There are four performance goal types supported in IBM WebSphere XD V6.0:
- discretionary
- average response time
- percentile response time
- queue wait time (for long running applications)
Many unfavorable circumstances, including overutilization, constrained computing resources and error conditions, can impact our ability to meet performance goals. When response time increases, actions must be taken to correct the situation. In this respect, WebSphere XD operational policy facilities can act as an early warning mechanism.
Routing policies and work classes
Routing policies define how work should be routed to either an application edition, including the base edition, or a generic server cluster. A generic server cluster is a group of non-WebSphere HTTP endpoints that can access traffic from the ODR. Routing policies are defined at the ODR for the generic server clusters, or the application level for an application edition. Routing policies are comprised of work classes and routing rules.
Work classes are the mechanism to define from the application perspective or the ODR how work for an application or a generic server cluster, through the ODR, should be classified into the defined service policies as well as routing policy actions.
Health policy
WebSphere XD provides a health monitoring and management subsystem. This subsystem continuously monitors the operation of servers to detect functional degradation that is related to user application malfunctions. The health management subsystem consists of two main elements:
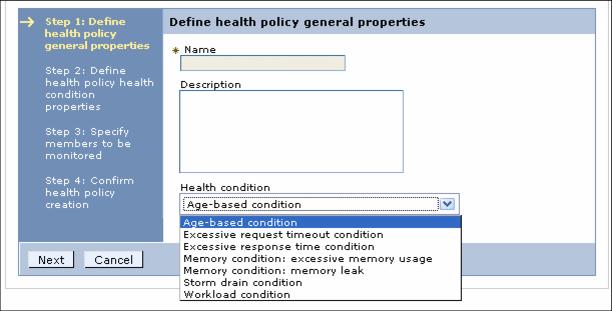
WebSphere XD supports the following health policies:
Age-based condition Monitors for servers that have been running longer than a configured time period. Excessive request time-out condition This health policy will detect, for each server that is a member of the policy, the percentage of requests directed at that server which have timed out (over an interval of time) after being routed from the ODR. Excessive response time-out condition Monitors for servers that appear to be hung due to requests taking an excessively long time period to complete. Workload condition Monitors for servers that have executed more than a configured number of requests. Memory condition, excessive memory usage Monitors for servers that appear to be consuming more memory than what the server has available. Memory condition, memory leak Profiles the Java Virtual Machine (JVM) heap size after a garbage collection has occurred and looks for trends of increased consumption. When an increasing trend is detected the condition is triggered. Storm drain condition Applies only to dynamic clusters and will detect, for each cluster member, a significant drop in the average response time for a member of the cluster coupled with changes to the dynamic workload manager (DWLM) weights for the cluster members. Health controller settings are global parameters. WebSphere XD provides a set of default values for these parameters. We can change these global parameters as needed.
The On Demand Router component
The On Demand Router (ODR) is a component that sits in the front of the WebSphere XD implementation. It represents the entry point into a WebSphere XD topology and controls the flow of requests into the back end. Specifically, the On Demand Router handles the queuing and dispatching of requests according to operational policy. In optimizing queue lengths and dispatch rates, several factors are considered, including request concurrency (per node group), operational policy, service policy weights and load balancing.
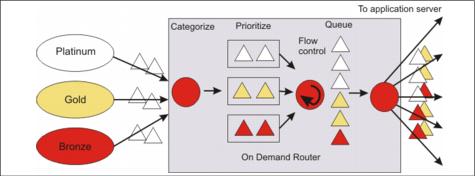
An equal amount of requests flow into the ODR, but after the work is categorized, prioritized, and queued, a larger volume of more important Platinum work is given a higher priority to be processed. A smaller volume of the less important Bronze work is sent to the application servers or even waits in the queue until the application servers are able to serve these requests.
Figure 1-3 On Demand Router architecture
Classification of requests
On Demand Routers accept incoming requests and distribute them to the WebSphere XD back end. This process involves the classification of requests into a finite set of request types, or transaction classes.
Class-based queuing of work
As soon as a request has been mapped to a transaction class, it is linked to that transaction class's service policy. Each service policy is assigned a separate queue. The request is then placed into the queue that corresponds to its service policy. An autonomic manager occasionally adjusts dispatching weights of each queue to achieve business goals based on measurements of arrival rates and service times.
Limiting concurrency
To protect against the prospect of an overloaded enterprise, the On Demand Router limits the number of requests being serviced concurrently in the WebSphere XD back end. Concurrency control also optimizes throughput. For example, we might get a higher throughput by executing 25 requests concurrently than if we executed 50 requests concurrently.
Concurrency limits are computed based on configured maximum thread-pool sizes. When these limits are reached, requests begin queuing up in the On Demand Router until demand subsides. If queues reach a (configurable) maximum length, subsequent requests can result in a message returned to the client indicating that the server is busy.
Autonomic managers
With WebSphere XD, we can introduce autonomic capabilities into our infrastructure at our own pace. WebSphere XD autonomic capabilities are delivered in a set of components known as autonomic managers. These components monitor performance and health statistics through a series of sensors, and turn various internal control knobs to optimize system performance.
This section describes each of the autonomic managers in a WebSphere XD topology.
Flow control manager
The flow controller oversees the dispatching of requests from the set of queues in the On Demand Router. It uses a weighted round-robin scheduling algorithm. The flow control manager modifies the weights of queues to align flow control with business goals. After work has been dispatched by the flow control manager, it is passed to the dynamic workload manager.
Dynamic workload manager
The dynamic workload manager (DWLM) handles load balancing of work across an enterprise back end by maintaining a table of servers to which it is delivering work. In this table, each server is dynamically assigned a weight corresponding to its relative capacity to perform work. In WebSphere XD terminology, the dynamic workload manager maintains a list of active server instances for each dynamic cluster, and assigns each a routing weight according to observed performance trends. Requests are then routed to candidate server instances to balance workloads on the nodes within a dynamic cluster based on a weighted least outstanding requests algorithm.
Autonomic request flow manager (ARFM)
The autonomic request flow manager exists in the ODR and monitors the performance of service classes on a continual basis. It adjusts the queue dispatching weights in the ODR, and modifies the weights to align flow control with business goals. The ARFM contains two parts: a controller and a gateway.
Scale beyond our defined environment
When demand distribution within a WebSphere XD enterprise shifts between node groups, the ability to compensate extends beyond the boundaries of WebSphere XD autonomic managers. By exploiting Tivoli® Intelligent Orchestrator and Tivoli Provisioning Manager, a WebSphere XD topology can acquire more physical computing resources from outside a node group.
Application Edition Manager
The Application Edition Manager (edition manager) of WebSphere XD helps us manage interruption-free production application deployments. Loss of service to users means loss of business to you. Using the Application Edition Manager, we can ensure that the users of our application experience no loss of service when we install an application update in our environment.
The edition manager also provides an application versioning model that supports multiple deployments of the same application in a WebSphere XD cell. We can choose which edition to activate on a WebSphere XD application server cluster, enabling us to either roll out an application update or revert to a previous level.
The edition manager interacts with both the On Demand Router (ODR) and dynamic workload balancing and application placement manager. This integration assures predictable application behavior when we apply application updates, ensuring a smooth transition from one application edition to another while the system continues to manage our application performance goals. The edition manager's edition control center provides control over the application update and rollout process, including edition activation across the application servers to which our application is deployed. Scripting APIs enable the integration of edition management functions with automated application deployment.
Extended manageability
WebSphere XD extends the Administrative Console to allow operators to see at a glance what is happening in their infrastructures and the relative health of the components. It also enhances the existing WAS Administrative Console by charting application performance against business goals. Alerts that notify we when intervention is required to deliver on business goals help decrease human-intensive monitoring and management.
View our infrastructure runtime status
To maintain ease-of-use in a product that lends itself to the management of complex deployments in an optionally fully automated fashion, WebSphere XD provides enhanced manageability features. These features include a visual console that provides a graphical representation of a dynamic WebSphere XD topology, reporting of performance statistics and implementation of administrative operations. These visualization functions are delivered as an extension to the WAS Administrative Console.
The WebSphere XD Administrative Console contains several tools that help we visualize the inner workings of a WebSphere XD topology, so we can remain well-informed about the activities taking place within our environment. Operational views represent an intuitive, central distribution point of information pertaining to health, performance and, potentially, autonomic decisions.
Runtime topology
One such view is the runtime topology view, which is a depiction of the view, or the momentary state of a WebSphere XD environment. This view refreshes on a configurable interval to provide updated information.
The runtime topology contains many useful bits of information, including:
- Application-provisioning activity
- Deployment of dynamic cluster instances
- Processor usage (per node)
- Node-to-node group memberships
- Dynamic cluster-to-node group memberships
- Dynamic workload management weight (per application server instance)
- Process identification (per application server instance)
Charting
WebSphere XD charting presents administrators with customizable graphs of runtime data observed throughout a WebSphere XD environment. This view refreshes on the same configurable interval as the runtime topology view. With WebSphere XD, we can chart a wide variety of statistics in six styles of graphs.
Supported statistics include:
- Average response time
- Concurrent requests
- Average throughput
- Average queue wait time
- Average service time
- Average queue length
- Average drop rate
- And many more....
Charts can be constructed from several perspectives as well, which gives we flexibility in the scope of the statistics we observe. WebSphere XD supports charting from cell, node group, dynamic cluster, service policy, transaction class, J2EE module, and proxy (On Demand Router) perspectives.
The WebSphere XD charting facility also offers a brief historical log of statistical data. As new data points are added to the right side of a chart, old data is displayed until it scrolls off the left side of the chart. Of course, the length of the history visible on the chart at any point in time depends on the number of data points per sampling period, and the type of chart being viewed. In addition, there is a logging function available that can be used to store statistics for longer periods of time.
Runtime map
WebSphere XD provides an innovative visualization technique for displaying hierarchical data called a treemap. It is simply a rectangle that is recursively subdivided into smaller rectangles, each of which represents the collection of nodes at some level in the tree of data being depicted. The significance of each rectangle's size and color is purpose-specific.
The top-level rectangle below represents a cell. This rectangle is subdivided into rectangles that represent node groups in that cell. Each node group rectangle is subdivided into rectangles representing dynamic clusters, and so on. The size and color of rectangles correlate to the magnitude of some statistic, depending on which treemap is being viewed. Color is used typically to represent health or goal attainment, while size typically represents a quantity, such as concurrent requests, number of server instances and so on. By default, the treemap displays the entire WebSphere XD topology. However, we can drill down to more fine-grained scopes by simply clicking a nonroot rectangle in the treemap.
Figure 1-6 Treemap
The WebSphere XD treemap facility can be of particular interest to administrators of very large topologies, because it is well-suited to depicting large sets of data in a concise manner. For instance, the usage of a set of 1000 applications could be quickly observed by viewing a treemap of dynamic clusters and comparing the sizes of rectangles. We can view goal attainment of a set of many service policies by observing the color of rectangles in a map of service policies.
Runtime maps provide a robust search capability, which allows us to single out a subset of the data in an entire map (such as all application server instances in a single node), highlight the top 10 performing applications based on response time, or select the dynamic clusters that have the five lowest, concurrent request values.
Monitoring our environment
WebSphere XD extends the Administrative Console to notify we of decisions made by autonomic managers. Notifications can represent either planned or unplanned events.
Planned events
Planned events are those expected events for which the WebSphere XD run time has an action plan. An example of a planned event would be an average response time breaching its configured limit, which might trigger an increased dynamic cluster footprint. Depending on the configured level of automation, these events could be shown to we in one of several ways. If WebSphere XD is operating in on demand mode (or automatic mode), the action plan runs and a simple notification is shown to you. In supervisory mode, we are presented with the mode, and the action plan, and prompted for approval. In manual mode, WebSphere XD presents a plan, and we can either follow or ignore the advice.
Over time, as we grow more familiar with WebSphere XD and its behavior, such decisions and corresponding actions can happen automatically. With the three modes of operation provided by WebSphere XD, we can introduce autonomic capabilities into our IT infrastructure in a controlled and gradual way.
Unplanned events
Events that are not assigned action plans are displayed to we as warnings to let we know that something unexpected has happened. It is then up to us to develop a plan to correct the situation, if it is indeed problematic.
High performance computing
High performance computing is designed to support high volume transaction requirements reliably. To support ultra-high-end transaction processing requirements reliably within a unified WebSphere environment, WebSphere XD provides dynamic application partitioning and repartitioning, high end caching, workload management and autonomic high availability management.
Partitioning pattern
The partitioning pattern addresses bottlenecks that occur in high volume Online Transaction Processing (OLTP) applications that intensively read and write data to databases and require the utmost in data consistency and availability. Examples of such systems include trading, banking, reservation, and online auction systems. Today's J2EE servers have been optimized for read-mostly environments such as commerce systems, where data-caching capabilities can be used to offload the back end database systems. However, as systems observe increased data write (such as database insert, delete, create and update) ratios, these caching systems start to break down because of the ever-strenuous task of maintaining consistency between the cache and database. These schemes often quickly reach a point of diminishing returns and are better off sending all traffic back to the database and allowing the database to manage consistency. This strategy frequently leads to large and costly database configurations, often running on large symmetric multiprocessor (SMP) machines. In ultra-high-volume environments, these database servers inevitably become a cost and performance bottleneck.
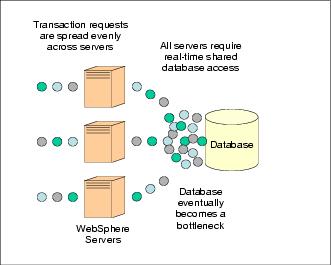
The partitioning pattern aims to offload the database by enabling the application server tier to act as a buffer. It also makes interactions with the database more productive. There are five key elements to the partitioning pattern.
Element WebSphere capability Partitioning WebSphere Partitioning Facility Partition-aware workload management WebSphere XD through the On Demand Router
EJB client through IIOP routing
JMS through pull model
Leveraging partitions
ObjectGrid caching
JDBC batching
Highly available partitions
High availability manager for highly available partitions
Rebalancing partitions
Partitioning facility management bean The following section describes the elements of the partitioning pattern and how they can be used in WebSphere XD to achieve significant improvement in J2EE application performance and scalability.
Partitioning
The WebSphere Partitioning Facility lets us create partitions in WebSphere XD.
A partition is a list of labels that can be created by applications (or metadata found in declarations within applications). For example, an application can set partition names to represent stocks...
- NOK
- IBM
- CSX
- KEA
Application partitioning
We can programmatically calculate partitions using an application-provided hashing function. For example, an application can apply a hash function to an arbitrary token (such as an HTTP header or cookie) to derive a number corresponding to a partition. When an application uses one of the aforementioned methods to create its partitions (typically at application startup or during a repartition operation), the WebSphere Partitioning Facility component assigns each partition to a server process in the WAS cluster. Partitions then are the foundations of the partitioning pattern.
ObjectGrid
There have been significant enhancements to the ObjectGrid in WebSphere XD V6.0.1, therefore IBM recommends to use this version and the content of this section applies to V6.0.1.
ObjectGrid is an extensible transactional object caching framework for J2SE and J2EE applications.
We can use the ObjectGrid API when developing our applications to retrieve, store, delete, and update objects in the ObjectGrid framework. We can also implement customized plug-ins that monitor updates to the cache, retrieve and store data with external data sources, manage eviction of entries from the cache, and handle background cache functionality for our own ObjectGrid application environment.
The ObjectGrid provides an API that is based on the Java Map interface. The API is extended to support the grouping of operations into transactional blocks. We can associate a set of keywords with a key and all the objects that are associated with a keyword can be evicted from the Map instance at any time. This interface is a super-set of the Map interface and adds support for batch operations, invalidation, keyword association, and explicit insert and update. Enhancements to Java Map allow us to use:
- Cache evictors fine-tune cache entry lifetimes.
- Transaction callback interfaces to carefully control transaction management and optionally integrate with the WebSphere transaction manager in J2EE environments.
- Loader implementations automatically retrieve and place data to and from a database when an application programmer uses the ObjectGrid Map get and put operations.
- Listener interfaces have the ability to provide information about all committed transactions as they occur and are applied towards the ObjectGrid framework as a whole or are applied for particular Map instances.
- Object transformer interfaces allow for more efficient copying and serializing of keys and values.
The ObjectGrid environment
We can use the ObjectGrid framework with or without WAS or WebSphere XD. When we use WAS support, additional distributed transaction support can be exploited. We can also exploit distributed transactional support if we use any environment that has a reliable publish and subscribe messaging system, such as a JMS provider.
In IBM WebSphere XD V6.0.1 and higher we can use the ObjectGrid framework by installing one of these offerings:
- ObjectGrid is integrated with IBM WebSphere XD V6.0.1 and is a part of the full installation.
- Standalone ObjectGrid is a part of the WebSphere XD for Mixed Server Environments (MSE) installation.
In both offerings, ObjectGrid supports client/server features. The server run time supports full clustering, replication, and partitioning of distributed object caches. The client run time supports the concept of a near cache and workload management routing logic to remote clusters. The client run time also supports local object map creation.
The level of support varies depending on if we are running the client run time, server run time, integrated ObjectGrid, or the standalone ObjectGrid.
ObjectGrid integrated with WebSphere XD
- Server run time: The server run time is integrated. Note that for WebSphere XD V6.0.1, the integrated run time is not supported on the z/OS® platform.
- Client run time: The client run time is supported on J2SE and J2EE at JDK level 1.3.1 and greater, including WAS V5.0.2 and later. The client run time is fully supported on the z/OS platform.
Standalone ObjectGrid
- Server run time: The server run time can run in standalone JVMs as a single server or as a cluster of servers. The standalone server is supported on most J2SE and J2EE platforms at JDK level 1.4.2 and greater. The standalone server is supported on WAS V6.0.2 and later. Note that the standalone server run time is not supported on the z/OS platform for WebSphere XD V6.0.1.
- Client run time: The client run time is supported on J2SE and J2EE platforms at JDK level 1.3.1 and greater, including WAS V5.0.2 and later.
Session management
A fully distributed HTTP session management implementation is provided that stores HTTP session objects in the ObjectGrid.
Transactional changes
All changes are made in the context of a transaction to ensure a robust programmatic interface. The transaction can either be explicitly controlled within the application, or the application can use the automatic commit programming mode. These transactional changes can be replicated across an ObjectGrid cluster in asynchronous and synchronous modes to provide scalable and fault tolerant access.
We can scale ObjectGrid from a simple grid running in a single Java Virtual Machine (JVM) to a grid that involves one or more ObjectGrid clusters of JVMs. These servers make data available through the Map APIs to a large set of ObjectGrid-enabled clients. The ObjectGrid clients use the basic Java Map APIs. However, the application developer does not need to develop Java TCP/IP and remote method invocation (RMI) APIs because the ObjectGrid client can reach the other ObjectGrid servers that are holding information across the network. If our data set is too large for a single JVM, we can use ObjectGrid to partition the data.
ObjectGrid also offers our application solution added high availability capabilities. The object sharing is based on a replication model where a primary server, one or more replication servers, and one or more standby servers exist. This cluster of replication servers is referred to as a replication group. If the access to the replication group is a write operation, then the request is routed to the primary server. If the access is a read operation, or if the map is a read-only map, the request can route to the primary or replication servers. The standby servers are defined as potential replication servers if a server fails. If a primary server fails, then a replication server becomes the primary server to minimize any outage. This behavior is configurable and extensible based on our needs.
If we want to use a simpler object propagation approach, a lower quality of service peer to peer model is also available, as it was in WebSphere XD V6.0. With this simpler distributed transactional support, peers can be notified of changes by using a message transport. The message transport is built in if we are running WAS V6.0.2 or later. If we are not running WAS V6.0.2 or later, another message transport must be supplied, such as a JMS provider.
Extensible architecture
We can extend most elements of the ObjectGrid framework by developing plug-ins. We can tune the ObjectGrid to allow an application to make trade-off decisions between consistency and performance. Plug-in customized code can also support application-specific behaviors, such as:
- Listening to an ObjectGrid instance events for initialization, transaction begin, transaction end, and destroy.
- Invoking transaction callbacks to enable transaction-specific processing.
- Implementing specific common transaction policies with generic ObjectGrid transactions.
- Using loaders for transparent and common entry and exit points to external data stores and other information repositories.
- Handle non-serializable objects in a specific way with ObjectTransformer interfaces.
We can implement each of these behaviors without affecting the use of the basic ObjectGrid cache API interfaces. With this transparency, applications that are using the cache infrastructure can have data stores and transaction processing greatly changed without affecting these applications.
Using ObjectGrid as a primary API or second-level cache
The ObjectGrid APIs can be used directly by the application as a lookaside cache or as a write through cache. In write through mode, the application plugs in a Loader object so that the ObjectGrid can apply changes and fetch data directly and transparently to the application.
ObjectGrid can also be used as a second-level cache for popular object relational mappers by writing an adapter. The cache is invisible to the application in this mode because the application uses the APIs from the object relational mapper as the primary API for accessing the data.
Business grid
The J2EE applications that are typically hosted by WAS perform short, lightweight, transactional units of work. In most cases, an individual request can be satisfied with a few seconds of CPU time and relatively little memory. Many applications, however, need to perform long-running, resource-intensive work that does not fit this transactional paradigm. These applications need business grid.
The business grid function in WebSphere XD extends WAS to accommodate applications that need to perform long-running work alongside transactional applications. Long-running work might take hours or even days to complete and consume large amounts of memory or processing power while it runs.
Resources are virtualized in a common pool so that they can be shared amongst multiple transactional applications. Workloads are prioritized, queued and routed according to established business goals and relative app importance
App resources are dynamically adjusted based on actual demand using autonomic managers
WebSphere XD uses jobs to express units of long-running work. A job describes the work, which application is needed to perform the work, and can include additional information to help WAS handle the work effectively and efficiently. Jobs are specified in an XML dialect called xJCL and can be submitted programmatically or through a command-line interface. As part of a job submission, the job is persisted in an external database and given to the long-running scheduler component of WebSphere XD. The long-running scheduler pairs waiting jobs with available capacity in the cell and distributes the jobs to execution environments to run. WebSphere XD provides two types of execution environments: compute-intensive and batch. The distinction between the two lies in the programming model provided to the application by the container.
The compute-intensive execution environment
This environment supports long-running applications that expect to consume large amounts of CPU. This execution environment provides a relatively simple programming model that is based on asynchronous beans.
The long-running execution environment
The long-running execution environment supports batch-oriented applications. These applications are expected to perform processing similar to more traditional J2EE applications, but are driven by batch inputs rather than interactive users. This environment builds on familiar J2EE entity beans to provide batch applications a rich programming model that supports container-managed restartable processing and the ability to pause and cancel jobs that are running.
Business grid autonomic functions
As with the dynamic operations function, the business grid has autonomic management functions to dynamically adapt our environment to changing workload. The business grid provides the following autonomic functions:
Long-running placement The long-running placement controller is analogous to the application placement controller that starts and stops instances of transactional applications. The long-running placement controller starts and stops instances of long-running applications in response to the jobs in the system. Balancer Because of the nature of long-running work, co-locating it on the same system with transactional work can have an adverse impact on the transactional work for certain systems. The balancer makes decisions about which systems perform transactional work and which can be used for long-running work. These decisions are based on a number of factors, including how well the service policies for the two types of work are met. Because the z/OS system is specifically equipped to handle diverse workloads, the balancer is able to share a z/OS system with the transactional work request manager.
The compute-intensive execution environment
This environment supports long-running applications that expect to consume large amounts of CPU. This execution environment provides a relatively simple programming model that is based on asynchronous beans.
The long-running execution environment
The long-running execution environment supports batch-oriented applications. These applications are expected to perform processing similar to more traditional J2EE applications, but are driven by batch inputs rather than interactive users. This environment builds on familiar J2EE entity beans to provide batch applications a rich programming model that supports container-managed restartable processing and the ability to pause and cancel jobs that are running.
Business grid autonomic functions
As with the dynamic operations function, the business grid has autonomic management functions to dynamically adapt your environment to changing workload. The business grid provides the following autonomic functions:
- Long-running placement: The long-running placement controller is analogous to the application placement controller that starts and stops instances of transactional applications. The long-running placement controller starts and stops instances of long-running applications in response to the jobs in the system.
- Balancer: Because of the nature of long-running work, co-locating it on the same system with transactional work can have an adverse impact on the transactional work for certain systems. The balancer makes decisions about which systems perform transactional work and which can be used for long-running work. These decisions are based on a number of factors, including how well the service policies for the two types of work are met. Because the z/OS system is specifically equipped to handle diverse workloads, the balancer is able to share a z/OS system with the transactional work request manager.
Scale-out topologies
Support for scale-out in IBM WebSphere XD V6.0 includes non-WAS quality of service (QOS) extensions and administrative extensions.
QOS extensions outside of WebSphere
QOS extensions from IBM WebSphere XD V6.0 can be applied to non-WebSphere XD server environments. They are provided in a package called WebSphere XD for Mixed Server Environments. They include ObjectGrid and support for ODRs routing traffic to HTTP endpoints that are not WebSphere XD servers, both described in the following paragraphs.
ObjectGrid
WebSphere Extended Deployment for Mixed Server Environments provides support for the ObjectGrid features to be used in a non-WebSphere server environment. We can use this to run the server components of ObjectGrid in a J2SE 1.4.2 JVM, including other J2EE server stacks. It also includes support for running the ObjectGrid clients in any J2SE 1.4.1 JVM, including other vendor J2EE servers and non-J2EE server client programs.
Routing traffic from On Demand Routers to HTTP endpoints
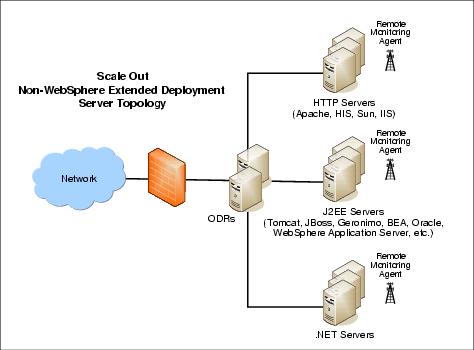
If we have a mixed environment, such as our topology contains WebSphere Extended Deployment servers as well as servers that do not have WebSphere Extended Deployment installed, we can build a single workload routing layer to handle all HTTP traffic flowing into that set of servers. The visualization and service policy features of IBM WebSphere Extended Deployment V6.0 support this workload routing layer. This QOS extension lets we attain the benefit of autonomic workload management even when our backend servers are not WebSphere Extended Deployment servers.
To route traffic to nodes that do not have WebSphere Extended Deployment installed, we need to configure a generic server cluster. The generic server cluster contains the HTTP transport end points that can be used as a target for an ODR routing rule.
Generally speaking, we can add any server to the generic server cluster that can be reached using the HTTP(S) protocol. This could be a standalone WAS (no matter which version) that is not part of our WebSphere Extended Deployment cell or HTTP servers, other vendors' J2EE application servers (such as JBoss, Apache Geronimo, BEA), and.NET servers.
WebSphere Extended Deployment for Mixed Server Environments provides a remote monitoring agent which can be installed on these servers to retrieve additional system information (such as CPU utilization) and forward it to the ODRs for dynamic workload distribution.
ObjectGrid
WebSphere XD for Mixed Server Environments provides support for the ObjectGrid features to be used in a non-WebSphere server environment. We can use this to run the server components of ObjectGrid in a J2SE 1.4.2 JVM, including other J2EE server stacks. It also includes support for running the ObjectGrid clients in any J2SE 1.4.1 JVM, including other vendor J2EE servers and non-J2EE server client programs.
Routing traffic from On Demand Routers to HTTP endpoints
If you have a mixed environment, such as your topology contains WebSphere XD servers as well as servers that do not have WebSphere XD installed, we can build a single workload routing layer to handle all HTTP traffic flowing into that set of servers. The visualization and service policy features of IBM WebSphere XD V6.0 support this workload routing layer. This QOS extension lets you attain the benefit of autonomic workload management even when your backend servers are not WebSphere XD servers.
To route traffic to nodes that do not have WebSphere XD installed, we need to configure a generic server cluster. The generic server cluster contains the HTTP transport end points that can be used as a target for an ODR routing rule.
Generally speaking, we can add any server to the generic server cluster that can be reached using the HTTP(S) protocol. This could be a standalone WebSphere Application Server (no matter which version) that is not part of your WebSphere XD cell or HTTP servers, other vendors' J2EE application servers (such as JBoss, Apache Geronimo, BEA), and .NET servers.
WebSphere XD for Mixed Server Environments provides a remote monitoring agent which can be installed on these servers to retrieve additional system information (such as CPU utilization) and forward it to the ODRs for dynamic workload distribution.
Scale-out administration
The scale-out administration features provided in IBM WebSphere XD V6.0 improve systems by increasing the availability of the WebSphere administrative function, and helping to improve error correction through a configuration repository checkpoint and restore function.
The scale-out administration support supports the following functions:
- High availability Deployment Manager
- Repository checkpoint/restore
The high availability Deployment Manager
The highly available Deployment Manager function provides high availability for the Deployment Manager server by using a hot-standby model. With this support, two or more Deployment Manager peers can be defined and started in the same cell. One is primary, while the others are backups in standby mode. In standby mode, the Deployment Manager cannot be used to perform administrative functions. However, if the primary Deployment Manager is stopped or fails, a standby Deployment Manager automatically assumes the role of the primary Deployment Manager.
Repository checkpoint/restore
The repository checkpoint/restore function enables creation of backup copies of files from the master configuration repository. These backups can be used to restore the configuration to a previous state in case an administrator makes configuration changes that cause operational problems.
The high availability Deployment Manager
The highly available Deployment Manager function provides high availability for the Deployment Manager server by using a hot-standby model. With this support, two or more Deployment Manager peers can be defined and started in the same cell. One is primary, while the others are backups in standby mode. In standby mode, the Deployment Manager cannot be used to perform administrative functions. However, if the primary Deployment Manager is stopped or fails, a standby Deployment Manager automatically assumes the role of the primary Deployment Manager.
Repository checkpoint/restore
The repository checkpoint/restore function enables creation of backup copies of files from the master configuration repository. These backups can be used to restore the configuration to a previous state in case an administrator makes configuration changes that cause operational problems.
Integration with other IBM software
There are several other IBM software products that can complement or integrate with WebSphere XD. These are, for example:
- Tivoli Intelligent Orchestrator
- Tivoli Provisioning Manager
- Enterprise Workload Manager - EWLM
- Other monitoring solutions such as WebSphere Studio Application Monitor or IBM Tivoli OMEGAMON®
In cases where the functionality of these products overlaps with WebSphere XD functionality, it is recommended that we use WebSphere XD to manage the WebSphere environment and then allow the interaction between XD and the other products to govern the higher level enterprise goals.
Tivoli Intelligent Orchestrator/Tivoli Provisioning Manager
When demand exceeds the total capacity of the WebSphere XD node group, the ability to compensate extends beyond the boundaries of WebSphere XD autonomic managers. By optionally exploiting Tivoli Intelligent Orchestrator/Provisioning Manager, a WebSphere XD topology is able to acquire additional physical computing resources from outside a node group.
Tivoli Intelligent Orchestrator/Provisioning Manager is the IBM standard tool for provisioning. Generally, it monitors and manages a set of disparate resource pools (such as WAS, WebSphere MQ, SAP, and e-mail) to ensure processing power (in the form of machines, LPARs, CPUs, and so on) is allocated in accordance with business goals. In a specific application such as as WebSphere XD's provisioning engine, Tivoli Intelligent Orchestrator/Provisioning Manager is provided with information that it can use to compute optimum allocations of available resources within the scope of a WebSphere XD topology. It then modifies distributions of physical resources among candidate node groups.
For more information see:
Enterprise Workload Manager
If we must coordinate workload management decisions between tier and between heterogeneous systems (WAS and database and CICS®, and so on), WebSphere XD provides out-of-the-box integration with Enterprise Workload Manager (EWLM). This enables EWLM and WebSphere XD to collaborate to ensure the enterprise-wide workload management policy is enforced across tiers.
For more information
- WebSphere XD home page:
- WebSphere XD InfoCenter:
- developerWorks® WebSphere home page:
- developerWorks WebSphere XD forum
- developerWorks Inside WebSphere XD blog
Lazy application start
The lazy application start feature in IBM WebSphere XD V6.0 optimizes server resource allocation during times of inactivity. When a request for that application is received by the On Demand Router (ODR), the application is started automatically on any node in the node group.
Vertical stacking
IBM WebSphere XD V6.0 introduces a new feature called vertical stacking. Because not all applications are scalable, vertical stacking allows multiple instances of an application to be started on the same physical node in order to enable more throughput on that application and better consumption of the node.