ObjectGrid
- Overview
- Preparing our environment for ObjectGrid
- ObjectGrid basic concepts
- ObjectGrid
- BackingMap
- ObjectMap
- Session
- Using the ObjectGrid
- Configuring ObjectGrid
- Comparison with WAS Dynamic Cache Service
- ObjectGrid features
- Transaction support
- Security
- Object eviction
- TTL evictor (default)
- Pluggable evictors
- Keyword based object invalidation
- Loaders
- LogElement and LogSequence
- Locking strategies
- Copy modes
- Performance Monitoring Infrastructure interface
- ObjectGrid advanced features
- Transaction Callback plugin
- Optimistic Callback
- Event listeners
- ObjectGridEventListener
- MapEventListener
- Distributed Transaction Propagation
- ObjectTransformer
- ObjectGrid topologies
- Basic multiple independent cache topology
- Multiple independent cache topology with JMS listeners
- Multiple independent cache topology with JMS and transaction listeners
- New ObjectGrid features in WebSphere XD V6.0.1
- Clustering, replication, partitioning
- Basic ObjectGrid clustering concepts
- Illustrating ObjectGrid clustering concepts
- ObjectGrid client example
- Replication overview
- Checkpoint based replication
- Partitioning overview
- Server peer bootstrapping
- Client connect/bootstrapping
- Systems management (JMX)
- Systems management example
- Systems management security
- Security updates
- Indexing
- Dynamic proxy
- Persistence Manager Adapter
- HTTP session replication using servlet filter
- ObjectGrid usage scenarios
- Scenario 1: CMP customer requires advanced caching (V6.0.1)
- Scenario 2: WebSphere application requiring advanced caching
- Scenario 3: J2SE application requiring advanced caching
- Scenario 4: Providing HTTP session failover for Web applications (V6.0.1)
- Scenario 5: Applications using WebSphere Partition Facility in WebSphere XD (V6.0.1)
- Scenario 6: Applications using third-party object relational mappers
- Scenario 7: An object integration tier
Overview
ObjectGrid is a high performance distributed transactional cache for storing Java objects. It can be scaled from a single JVM to multiple distributed JVMs. Its transactional support ensures that operations can take place within the scope of a single transaction scope for consistency. It can be backed by a hardened store like a database. ObjectGrid supports a Java Map like API and is organized into sets of Maps holding key/value pairs. Security can be enabled using JAAS API. ObjectGrid has an extensible and customizable architecture and users can write their custom Java classes for loading the cache (from an external datasource), cache replacement (eviction) policies, and for various callbacks. These custom classes can be specified while configuring the ObjectGrid either programmatically (using the APIs) or through XML files.
Preparing our environment for ObjectGrid
ObjectGrid is supported in WebSphere Extended Deployment (XD) V6 or WAS 6.0.2 (and higher) runtime environments. However, the ObjectGrid libraries are only provided with WebSphere XD V6 and not with the WAS product. For WAS, include the ObjectGrid libraries in the application classpath.
To write and compile applications that make use of ObjectGrid, we can use the objectGrid.jar found in...
<WS_XD_Install_Root>/lib...and include it in the classpath of our development environment.
Specific details about setting up an Eclipse environment for ObjectGrid are found in the ObjectGrid Programming Model Guide, v6.0.x.
ObjectGrid basic concepts
The ObjectGrid programming model consists of the creation of the ObjectGrid itself, defining BackingMaps, and starting and committing sessions.
Figure 9-1 ObjectGrid usage - basic concepts
ObjectGrid
ObjectGrids contain one or more Map-like objects (BackingMaps/ObjectMaps). The application can create and reference one or more ObjectGrids. To cache objects using ObjectGrid, an application must create an ObjectGrid instance.
The ObjectGrid instance can be created programmatically or created based on configuration data stored in an XML file. Sample XML configuration files are provided with the WebSphere XD installation. The XML files define the ObjectGrid Java plug-in implementations that should be used and how they are associated with each other. All the public APIs required for using ObjectGrid are in the package...
com.ibm.websphere.objectgrid.*
BackingMap
The BackingMap contains the cached application data (Java objects) in the form of key/value pairs where the value part of the key/value pair is a Java object. The BackingMap contains the in-memory committed application data. The application can create one or more BackingMaps in an ObjectGrid. The BackingMap can be populated by the application itself or it can be loaded from a backend datasource by implementing a custom Cache Loader class.
ObjectMap
The ObjectMap contains either by reference or by copy data from the BackingMap. It logically contains uncommitted application data (that is, all the objects that are inserted/updated/deleted between a session start and a session commit) for a session. Objects are stored into and retrieved from an ObjectMap within the scope of a transaction using all of the usual Map-like operations, such as get(), put(), insert(), update(), and so on.
Session
All operations on the ObjectMaps in an ObjectGrid take place inside a Session. The application can have one active Session per ObjectGrid instance. Each thread running the application has its own Session and ObjectMap, but shares the ObjectGrid and the BackingMap with other threads. The application can access one or more ObjectMaps within a Session. The application at some point commits the ObjectMap data to the corresponding BackingMap by invoking "commit" on the Session.
Using the ObjectGrid
This section walks through some code to illustrate how to use the basic ObjectGrid features. An application that wants to make use of ObjectGrid is responsible for establishing and maintaining the ObjectGrid. For ObjectGrid, all configuration is done either programmatically or via an XML configuration file. There is no Administrative Console or JMX scripting support for the XML file.
The application must first create a singleton ObjectGridManager that it then uses to create the ObjectGrid itself:
ObjectGridManager ogm = ObjectGridManagerFactory.getObjectGridManager();As it creates the ObjectGrid, the application will assign it a name. The ObjectGrid represents the overall "grid" cache and comes out of the JVM heap:
ObjectGrid og = ogm.createObjectGrid(OG_NAME, true);The application can create one or more BackingMaps that are contained in the ObjectGrid. The application also names the BackingMap:
og.defineMap(MAP_NAME);The application can then create a session that represents a single transaction scope:
Session ogsession = og.getSession();The application can then create one or more ObjectMaps using the name for the BackingMap:
ObjectMap objectMap = ogsession.getMap(MAP_NAME);Then the application can start the session and start inserting/updating objects into the ObjectMap:
ogsession.begin();
objectMap.insert("some_key", some_object);When the application is done with insertion/updating objects it can then commit the session which commits the transaction scope represented by that session:
ogsession.commit();
Configuring ObjectGrid
ObjectGrid can be configured either programmatically through various APIs or by specifying these details in XML files. The configuration specifications that can be made via an XML file rather than programmatically include:
- ObjectGrid instances and ObjectGrid plugins
- BackingMap instances and BackingMap plugins
The XML file defines the Java implementations that should be used and how they are associated. To create an ObjectGrid using an XML file, specify the file name on the createObjectGrid method:
ObjectGridManager ogm = ObjectGridManagerFactory.getObjectGridManager();
ObjectGrid og = ogm.createObjectGrid("newGrid", "newGrid.xml");Sample configuration files are provided with the WebSphere XD installation.
Comparison with WAS Dynamic Cache Service
Here are some of the key differences between ObjectGrid caching and WAS dynamic caching:
ObjectGrid Dynamic caching Java Object level caching only Java Object level caching, plus Servlet/JSP and static content caching Available only with WebSphere XD Available with WAS (all editions) Can be transactional No transactional support ObjectGrid Performance Monitoring Infrastructure metrics viewed using Tivoli Performance Viewer Cache Monitor Application provided
ObjectGrid features
- Transaction support
- Security
- Object eviction
- Keyword based object invalidation
- Loaders
- LogElement and LogSequence
- Locking strategies
- Copy modes
- Performance Monitoring Infrastructure interface
Transaction support
An ObjectGrid transaction is defined as the duration between a Session.begin() and a Session.commit(). Sessions support the usual transactional methods, such as commit, rollback, and so on. Uncomitted changes made by the application to the BackingMap data (for example, operations on the ObjectMap) are stored in a special transaction cache. A commit operation applies the changes in the transaction cache to the BackingMap. A rollback operation discards the changes in the transaction cache. ObjectGrid supports 1-phase commit.
Security
ObjectGrid is a distributed caching system and the access to the cache data should be secured. Therefore we need to provide security to the ObjectGrid.
Since ObjectGrid in V6.0 only supports in-memory non-distributed access, ObjectGrid security only supports authorizations based on user principals.
Java Authentication and Authorization Service (JAAS) can be used to secure access to objects in the ObjectGrid. ObjectGrid relies on WAS or the application itself for authentication. The contract between an application and an ObjectGrid instance is the javax.security.auth.Subject object. After the client is authenticated by the application server or the application, the application can retrieve the authenticated javax.security.auth.Subject object and use this Subject object to get a session from the ObjectGrid instance by calling ObjectGrid.getSession(Subject).
ObjectGrid uses the authenticated Subject to authorize access to the map data. The Subjects contain one or more Principles. Authorization to objects in the ObjectGrid is specified in a policy file. The policy file identifies a Principle that has certain access privileges (read, insert, etc.) to certain ObjectGrid objects. If the authenticated Subject contains the Principle identified in the policy file, the user is granted the access privileges to the ObjectGrid objects. More infomation about ObjectGrid security can be found in the ObjectGrid Programming Model Guide, v6.0.x
Object eviction
The ObjectGrid cache size is controlled by evicting (removing) objects from the BackingMap when space is required.
TTL evictor (default)
ObjectGrid provides a default time to live (TTL) evictor for each BackingMap that purges an entry from the BackingMap when the expiration time for that entry is reached. The TTLType and the time to live attribute on the BackingMap is used to control how the TTL evictor computes the expiration time for each entry.
The TTLType attribute can be set to one of the following:
- None is the default and indicates that an entry in the BackingMap never expires.
- Creation Time indicates that the time an entry is created in the BackingMap should be used for calculating its expiration time.
- Last Access Time indicates that the time an entry was last accessed should be used for calculating its expiration time.
If the TTLType attribute is set to Creation Time or Last Access Time and the time to live attribute has a non zero value, then the expiration time is calculated by adding the value of the time to live attribute to the Creation Time or Last Access Time, respectively.
For example, to set a time to live of 10 minutes from the last accessed time:
BackingMap bm = og.defineMap("testMap"); bm.setTtlEvictorType( TTLType.LAST_ACCESS_TIME); bm.setTimeToLive(600 ) ;The above BackingMap attributes can't be changed once the ObjectGrid instance has been initialized and hence this code has to be executed before the call to initialize() on the ObjectGrid instance. When TTLType.LAST_ACCESS_TIME is used as the TTLType, the application can make use of a different time to live value for each entry in the ObjectMap. For details, refer to the ObjectGrid Programming Model Guide, v6.0.x
Pluggable evictors
Optional pluggable evictors are also provided which evict entries when the number of entries exceed a user specified maximum limit. Two types of optional evictors are provided - LRUEvictor that uses a least recently used algorithm and LFUEvictor that uses a least frequently used algorithm to decide which entries to evict, when the total number of entries exceed the specified maximum limit. Application developers can also implement their own eviction algorithms by writing custom evictor classes in Java. In order to do this, they have to implement the com.ibm.websphere.objectgrid.plugins.Evictor interface. Details can be found in the ObjectGrid Programming Model Guide, v6.0.x.
Keyword based object invalidation
Map entries can be associated with one of more explicit keywords. ObjectGrid supports a simple mechanism for grouping multiple entries by associating them with the same keyword. Keywords can be associated with another keyword. ObjectGrid implicitly associates map entries with the associated keyword. This is useful for creating nested groupings (parent/child relationship). The application can invalidate entries associated with a keyword including nested keywords. Invalidation of a parent also invalidates the child, while invalidation of the child has no effect on the parent. For more infomation about object invalidation, refer to the ObjectGrid Programming Model Guide, v6.0.x.
Loaders
The Cache Loader interface (com.ibm.websphere.objectgrid.plugins.Loader ) allows application developers to implement a custom Java class to load cache data from a backend store, and also to persist changed values back to the hardened store, independent of the state of the transaction. Data can optionally be preloaded synchronously or asynchronously from the data store at server startup. When requested data is not in the BackingMap, the request is passed to the data store using the Loader. A BackingMap also uses the Loader class to persist data to the data store. An expicit call to flush() pushes the data to the data store, but does not commit a transaction. The Cache Loader interface has the following methods:
List get(TxID txid, List keyList, boolean forUpdate) to fetch data from the backend datasource. void batchUpdate(TxID txid, LogSequence sequence) to persist changes back to the backend datasource. void preloadMap (Session session, BackingMap backingMap) to preload the cache from the backend datasource at server startup.
LogElement and LogSequence
A LogElement represents an operation on an entry during a transaction. If the application changes an entry in the map, there is a corresponding LogElement providing the details of the change. The most commonly used attributes of the LogElement object are the type and the current value:
type A log element type indicates what kind of operation this log element represents. It could be one of the constants defined in the LogElement interface: INSERT, UPDATE, DELETE, EVICT, FETCH, or TOUCH. current value The current value represents the new value for the operation INSERT, UPDATE or FETCH. If the operation is TOUCH, DELETE, or EVICT, the current value will be null. This value can be cast to ValueProxyInfo when a ValueInterface is in use. In most transactions there will be more than one operation to entries in a map, and thus multiple LogElement objects will be created. A LogSequence is a list of LogElement objects. When an application is making changes to a map during a transaction, a LogSequence object tracks all those changes.
LogElement and LogSequence are widely used in ObjectGrid and by ObjectGrid plugins written by users when operations are propagated from one component/server to another component/server. For example, a LogSequence object can be used by distributed ObjectGrid transaction propagation to propagate the changes to other servers, or it can be applied to the persistence store by the loader. Another example of their use is with Loaders. Loaders are given a LogSequence for a particular map whenever an application calls flush or commit to the transaction. The Loader iterates over the LogElements within the LogSequence and applies each LogElement to the backend. ObjectGridEventListeners registered with an ObjectGrid also make use of LogSequences. These listeners are given a LogSequence for each map in a committed transaction. Applications can use these listeners to wait for certain entries to change, like a trigger in a conventional database.
Locking strategies
Each BackingMap can be configured to use one of the following locking strategies:
Optimistic locking (default) Locks are only acquired during the actual update action. An exception is thrown if two threads try to update the same data simultaneously. It is useful for "read mostly" caches. Pessimistic locking Data is locked when a transaction gets data (during reads) from the BackingMap. The pessimistic lock is held until the application completes the transaction. This has a high performance impact. This strategy should therefore only be used when optimistic locking results in frequent collisions. None ObjectGrid does not manage concurrency and relies on the EJB persistence manager or on concurrency provided by a Loader.
Copy modes
The copy mode setting determines if and when copies of objects are made and given to the application code, as opposed to when objects are passed by reference. It is used to control performance versus data integrity tradeoffs between the application and the BackingMap. Each BackingMap can be configured to use one of the following copy modes:
COPY_ON_READ_AND_COMMIT (default) A copy of the object is made between the application and the BackingMap on every read and commit. It is the safest and provides best data integrity as the application never has direct references to objects in the BackingMap. Since a copy of the object is made on every read and commit by the application, it is also the slowest mode. COPY_ON_READ This mode provides better performance than COPY_ON_READ_AND_COMMIT as a copy is not made when a commit() operation is performed. To ensure data integrity, this mode requires that the application does not reuse objects after a transaction is committed. COPY_ON_WRITE This mode provides the best performance in "read-mostly" scenarios. A copy is made only if a set operation is invoked on the object. To maintain data integrity, object data must be accessed through a dynamic Java proxy. NO_COPY This mode is used in read-only scenarios. No copies are ever made and the objects are always passed by reference. The application must never modify the object to ensure data integrity. More details about the copy modes can be found in the ObjectGrid Programming Model Guide, v6.0.x.
Performance Monitoring Infrastructure interface
ObjectGrid exposes a Performance Monitoring Infrastructure (PMI) interface to allow users to monitor its activities. The WAS PMI can be configured to monitor the following ObjectGrid activities:
Transaction response time on the ObjectGrid level This statistic tracks the response time of a transaction. Transactions can be grouped by transaction types. Map hit rate This statistic tracks the current hit rate for a particular map. Number of Entries This statistic tracks the number of entries in the map. Loader batchupdate response time This statistic tracks the response time (current, min, max, counts) of the batchupdate call of the plugin Cache Loader. As with other PMI metrics, PMI configuration for ObjectGrid activities can be done using the WAS Administrative Console or using wsadmin. Similarly, PMI statistics can be retrieved using either the Tivoli Performance Viewer (TPV) or JMX/wsadmin scripts.
ObjectGrid advanced features
- Transaction Callback plugin
- Optimistic Callback
- Event listeners
- Distributed Transaction Propagation
- ObjectTransformer
Transaction Callback plugin
The main purpose of a Transaction Callback plugin is to map ObjectGrid transaction operations to platform level transaction operations and to perform those platform level transactional operations. ObjectGrid itself does not do this. So, when a commit is done to an ObjectGrid session, the ObjectGrid instance calls the Transaction Callback plugin's commit method to do the platform level commit. It is normally used with a Loader as the Loader does the data access and can perform those platform level transaction operations. The TransactionCallback interface consists of the following methods:
- void initialize (ObjectGrid): Called when the ObjectGrid instance is initialized.
- void begin (TxID id): Called when the ObjectGrid transaction starts.
- void commit (TxID id): Called when the ObjectGrid transaction is comitted.
- void rollback (TxID id): Called when the ObjectGrid transaction is rolled back.
The Transaction Callback plugin object is added to the ObjectGrid instance at initialization. At the initialize callback, the Transaction Callback plugin object should reserve slots on the ObjectGrid instance for the TxID object that it will need. Usually, it will reserve a slot (a slot is just an entry in an ArrayList) for each piece of state or Object that it wants to create in the begin method when a transaction starts. These objects can then be retrieved by calling getSlot() on the TxID objects which are passed along in subsequent callback methods (begin, commit, rollback). For more information and programming samples (including a scenario that uses JDBC for communicating to the backend datasource), refer to the ObjectGrid Programming Model Guide, v6.0.x
Optimistic Callback
The OptimisticCallback interface is used to provide optimistic comparison operations for the value of a map. This is typically needed when the Optimistic locking strategy is being used. The Optimistic Callback plugin object is accessed by a BackingMap or a Loader to obtain a "version" object in order to provide version identification of a cache entry. The version object can be either a field in the value object or a copy of the value object itself. When processing the commit, the BackingMap or Loader will first do a comparison using the version object returned from the Optimistic Callback object to make sure the value has not changed since the beginning of the transaction. If the BackingMap is doing the comparison and the comparison fails, an OptimisticCollisionException exception will be thrown. The OptimisticCallback interface has the following methods:
getVersionedObjectForValue Called whenever an object is associated with a transaction. updateVersionedObjectForValue Called whenever a transaction has updated a value and a new versioned object is needed. serializeVersionedValue Called for writing the versioned value to the specified stream. inflateVersionedValue Called for deserializing a versioned value into the actual versioned value object. ObjectGrid also provides a default OptimisticCallback implementation which is similar to a no operation function while doing the version comparison. Details can be found in the ObjectGrid Programming Model Guide, v6.0.x.
Event listeners
There are two types of listeners that applications can make use of - ObjectGridEventListener and MapEventListener. The ObjectGridEventListener is added to an ObjectGrid instance at initialization while a MapEventListener is added to a BackingMap.
ObjectGridEventListener
An ObjectGridEventListener is used to receive notifications when significant events occur on the ObjectGrid. These events include ObjectGrid initialization, beginning of a transaction, ending a transaction, and destroying an ObjectGrid. The ObjectGridEventListener interface consists of the following methods:
- void initialize (Session session)
- void transactionBegin (String txid, boolean isWriteThroughEnabled)
- void transactionEnd (String txid, boolean isWriteThroughEnabled, boolean commited, Collection changes)
- void destroy()
The ObjectGridEventListeners can be very useful in applications that need to track any changes made to the BackingMap. For example, if the ObjectGrid was working in distributed mode then an application may want to watch for incoming changes. Suppose the replicated entries were for latest stock prices. This listener could watch for these changes arriving and update a second Map that keeps the value of a position in a portfolio. The listener should make all changes using the Session provided to the listener in the ObjectGridEventListener#initialize method. The listener can distinguish between local changes and incoming remote changes usually by checking if the transaction is write through or not. Incoming changes from peer ObjectGrids are always write through.
MapEventListener
This is similar to the ObjectGridEventListener interface except that it is used to receive significant events about a BackingMap (and is therefore added to a BackingMap). These events include eviction of an entry from a BackingMap and completion of a BackingMap preload. The MapEventListener interface consists of the folowing methods:
- void entryEvicted(Object key, Object value)
- void preloadComleted( Throwable t )
Distributed Transaction Propagation
Distributed Transaction Propagation is provided through the TranPropListener built-in plugin. The TranPropListener is an implementation of ObjectGridEventListener. It allows ObjectGrid to propagate committed transactions to other WAS ObjectGrids having the same ObjectGrid name during ObjectGrid session transaction commit completion. Two configurable types of propagation are provided:
update Also referred to as push. On transaction commit completion, updated objects (keys and values) are propagated to other WAS ObjectGrids having the same name. invalidate On transaction commit completion, updated objects are invalidated in other WAS ObjectGrids having the same name. In addition to these, two conditional distribution modes are also provided - invalidate conditional, and update conditional (the default, also referred to as push conditional). The conditional distribution mode takes into account the versioned value data associated with each entry. Thus, before the invalidate or the update is performed, a comparison is done between the versioned value and the value currently in the receiving side ObjectMap. If the versioned value is older than the current value, then the invalidate or the update is not performed.
TranPropListener is added to the ObjectGrid instance at initialization.
ObjectTransformer
ObjectTransformer is a key plugin when high performance is required. If an ObjectTransformer is not provided then 60-70% of the total CPU is spent serializing/copying the entries. ObjectTransformer is used to improve performance when ObjectGrid entries are copied. It allows the application to provide custom methods for the following:
- Serialize/deserialize key for an entry
- Serialize/deserialize value for an entry
- Copy either a key or a value for an entry
This copying occurs when an application looks up an object in a transaction for the first time. This copying can be avoided by setting the copy mode of the Map to NO_COPY or reduced by setting the copy mode to COPY_ON_READ. Regardless, the copy operation should be optimized when needed by the application by writing a custom copy method using the ObjectTransformer plugin. Such a plugin can reduce the copy overhead from 65-70% to 2-3% of the total CPU time.
Object serialization is also used directly when the ObjectGrid is running in distributed mode. The LogSequence uses the ObjectTransformer to help it serialize keys and values before transmitting the changes to peers in the ObjectGrid. Care needs to be taken when a custom serialization method is provided rather than using the built-in JDK serialization. Object versioning is a complex issue and we may run into problems with version compatibility if we do not ensure that our custom methods are designed for this. For more details and an example that illustrates ObjectTransformer usage, refer to the ObjectGrid Programming Model Guide, v6.0.x.
ObjectGrid topologies
This section describes some of the topologies in which ObjectGrid could be used. These are sample topologies that have been included for illustration purposes but naturally we can implement other topologies according to our requirements.
Basic multiple independent cache topology
The first topology shows multiple application servers loading data from the same database and caching it locally. In this scenario, each of the servers can have stale data in its local cache (if the other server changes a value), but optimistic locking is used to ensure that stale data does not get written back to the database. Figure 9-2 shows this topology.
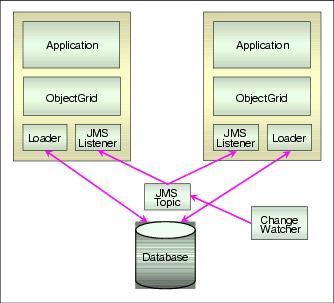
Multiple independent cache topology with JMS listeners
This topology as shown in Figure 9-3 is similar to the first topology, except that a change watcher is employed to alert the servers whenever a change is made to the database by some other process. A lightweight JMS system is used for notification, in which both servers subscribe to a JMS topic that receives messages from the change watcher. When they receive messages on this topic, the servers invalidate the specified data. Again, optimistic locking is used to ensure that stale data is not written back to the database.
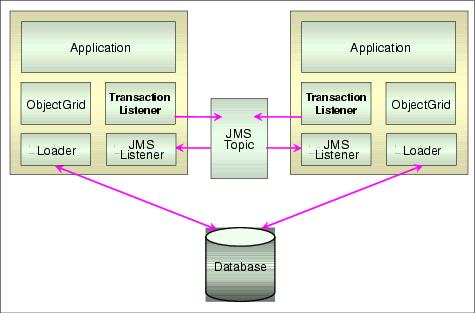
Multiple independent cache topology with JMS and transaction listeners
This topology assumes that all changes to the database occur through the application servers; no third party can update the database. When a server commits a transaction, it will place a message on the JMS topic, notifying all of the peer servers that the data is now stale and should be invalidated.
New ObjectGrid features in WebSphere XD V6.0.1
Even though this book is primarily about IBM WebSphere XD V6.0, we describe here several new features that have been added to the ObjectGrid in version 6.0.1.
Clustering, replication, partitioning
One important enhancement in V6.0.1 is the clustering support.
The primary goal of the WebSphere XD V6.0.1 ObjectGrid clustering enhancements is to provide a distributed middleware solution for enterprise caching. This extends the WebSphere XD V6.0 ObjectGrid solution which is primarily a programming model with some basic distributed capabilities if used within a WebSphere cluster or when leveraging a separate JMS provider.
Basic ObjectGrid clustering concepts
We first explain the basic concepts used by ObjectGrid clustering:
MapSet In the ObjectGrid programming model in the WebSphere XD V6.0 release, the key topology considerations when designing an application consists of an ObjectGrid (we could have any number of different ObjectGrids), each with 1...N maps. The clustered solution adds the concept of a MapSet, which allows some or all the maps in a specific ObjectGrid to be managed as a unit and appropriate to the application requirements. A MapSet cannot contain maps from more than one ObjectGrid but it can contain 1...N maps within one ObjectGrid. All maps that are to be accessible by clients from the ObjectGrid cluster must be in a MapSet. A single ObjectGrid can have as many MapSets as there are maps in the ObjectGrid. All maps in an ObjectGrid must be in a MapSet if any maps are.
MapSets indicate to the ObjectGrid middleware that the maps enumerated are cluster wide resources. "Local" ObjectGrids are possible, for example, they will only be instantiated in the ObjectGrid client application for special purposes. These ObjectGrids cannot have any MapSets. An ObjectGrid is either a cluster wide resource or locally used in a client application.
We can also define replication policy attributes for the MapSet. The replication policy attributes indicate whether synchronous or asynchronous replication is required, whether to allow read access to the replicas, and whether to use compression when sending replication data to the replica.
ObjectGrid server An ObjectGrid server is a single JVM and is a member of an ObjectGrid cluster. An ObjectGrid server (called server from this point on) can host 1...N ObjectGrid MapSets. The ObjectGrid clustering design is based on a set of loosely coupled servers. Each ObjectGrid server is loosely coupled to other servers in the ObjectGrid cluster depending on their functional capability. The objective is to ensure the entire cluster's scalability is large in terms of the number of servers that a ObjectGrid can contain. It is expected that hundreds of ObjectGrid servers can be included in an ObjectGrid cluster. An ObjectGrid client can also interact with one or more ObjectGrid clusters for enterprises where the use of the ObjectGrid middleware may vary within an organization. For example, a research group and development group may wish to share information to all clients inside the company in a uniform manner, but actually manage their own cluster. Java clients (a client JVM running a java program) can contact both clusters and use the data from those clusters concurrently.
Replication group member Each MapSet represented on the server is represented by a client/server and possibly a replication member service. For simplification, these two services are referred to as a replication group member. Each replication group member on a particular server has the capability to handle client/server requests and replication requests if replication is enabled for that ObjectGrid server's MapSet. Replication group In an ObjectGrid cluster, each MapSet correlates to a single replication group if it is not partitioned. Each replication group can have one or more replication group members. A replication group can consist of strictly a primary replication group member and no replication group member replicas. Even though the MapSet is not replicated in this case, it still supports client/server requests. A replication group consists of a set of replication group members, which are assigned to unique servers. A specific server can host many replication group members but it can house only one replication group member for a specific replication group. A replication group is responsible for coordinating distributed updates from a collection of maps on the primary replication group member (primary) to other servers hosting replication group members (replica) within that replication group.
The servers must run on a 32-bit or 64-bit J2SE 1.4.2 environment. The server can also run embedded inside an application server JVM such as WebSphere V6.0 so long as the JDK is at least 1.4.2.
An operationally active replication group consists of 1 primary, 0...X replicas and 0...Y standbys. A typical configuration consists of 1 primary, 2 replicas and no standbys, however we can select any combination that best suits our requirements. The number of replicas and standbys required in each replication group must be configured.
Partitioned MapSets MapSets can also be partitioned, which means that for large data sets, the data can be partitioned across one or more replication groups. This is useful if the data set is huge, for example, several Gigabytes. In that case, a customer might want to partition the data into 1 Gigabyte per replication group. This enables large data sets to be managed inside a JVM with a 2 Gigabtye addressable memory limit for 32 bit machines. To partition a MapSet, we need to create a PartitionSet that has more than one partition. Each partitions objective is to hold 1/N of the entries in the particular map, where N is the number of partitions selected. A PartitionSet with one member is simply a non-partitioned replication group. All PartitionSets can be configured to enable replication or not. In addition, each partition in a PartitionSet can have a different replication strategy if so desired.
Illustrating ObjectGrid clustering concepts
To clarify the above, the following example should prove helpful. The sample illustrates a distributed cache application that supports three ObjectGrids.
The configuration for these ObjectGrids is done through two XML files (unlike a single file in version 6.0). The ObjectGrid XML file defines the ObjectGrid, its BackingMaps, and any associated plugins. The cluster XML file maps the ObjectGrid(s) defined in the ObjectGrid XML to a topology.
There can be possibly many cluster definitions that correlate to a single ObjectGrid definition. Typically, programmers focus on the ObjectGrid definition, as the attributes directly affect their programmatic use of the cache information. For flexibility, a separate cluster definition is provided to enable use of the ObjectGrid as required for developers, a quality assurance team member or for the administrator during production usage.
Example 9-1 is a basic ObjectGrid definition for this example:<?xml version="1.0" encoding="UTF-8"?> <objectGridConfig xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns="http://ibm.com/ws/objectgrid/config"> <objectGrids> <objectGrid name="accounting"> <backingMap name="payroll" readOnly="false" /> <backingMap name="employee" readOnly="false" /> <backingMap name="ledger" readOnly="false" /> </objectGrid> <objectGrid name="inventory"> <backingMap name="books" readOnly="false" /> <backingMap name="cds" readOnly="false" /> </objectGrid> <objectGrid name="parts"> <backingMap name="sku" readOnly="true" /> <backingMap name="image" readOnly="true" /> </objectGrid> </objectGrids> </objectGridConfig>
This enables programmers to encode their application to use the three specific ObjectGrids, each having two or more maps. Notice, there is no clustering information in this configuration file. To map this ObjectGrid definition to a cluster, a second file is required.
Example 9-2 shows a cluster XML file that places the ObjectGrids accounting and inventory within the cluster (note that "parts" is not a cluster wide ObjectGrid in this example, it is only "Local" to the client and hence does not appear in the cluster XML file). In this example, security is defined, but not enabled. Three servers are used, and each MapSet consists of only a primary as opposed to supporting a replicated and partitioned (described in the following replication and partitioning sections) solution.
Example 9-2 ObjectGrid cluster XML file
xml version="1.0" encoding="UTF-8"?> <cluster-config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ibm.com/ws/objectgrid/config/cluster ../objectGridCluster.xsd" xmlns="http://ibm.com/ws/objectgrid/config/cluster"> <cluster name="cluster1" securityEnabled="false" singleSignOnEnabled="true" loginSessionExpirationTime="300" statisticsEnabled="true" statisticsSpec="map.all=enabled"> <!-- call this a server --> <serverDefinition name="server1" host="localhost" clientAccessPort="12503" peerAccessPort="12500" workingDirectory="" traceSpec="ObjectGrid=all=enabled" systemStreamToFileEnabled="true" /> <serverDefinition name="server2" host="localhost" clientAccessPort="12504" peerAccessPort="12501" workingDirectory="" traceSpec="ObjectGrid=all=enabled" systemStreamToFileEnabled="true" /> <serverDefinition name="server3" host="localhost" clientAccessPort="12505" peerAccessPort="12502" workingDirectory="" traceSpec="ObjectGrid=all=enabled" systemStreamToFileEnabled="true" /> </cluster> <objectgridBinding ref="accounting"> <mapSet name="PayrollMSet" partitionSetRef="PayrollPSet"> <map ref="payroll" /> </mapSet> <mapSet name="EmployeeMSet" partitionSetRef="EmployeePSet"> <map ref="employee" /> </mapSet> <mapSet name="LedgerMSet" partitionSetRef="LedgerPSet"> <map ref="ledger" /> </mapSet> </objectgrid-binding> <objectgrid-binding ref="inventory"> <mapSet name="BooksMSet" partitionSetRef="BooksPSet"> <map ref="books" /> </mapSet> <mapSet name="CDsMSet" partitionSetRef="CDsPSet"> <map ref="cds" /> </mapSet> </objectgridBinding> <!-- in this scenario, the developer is not using partitioned MapSets, each map is a singleton--> <partitionSet id="PayrollPSet"> <partition name="1" replicationGroupRef="PayrollRGroup" /> </partitionSet> <partitionSet id="EmployeePSet"> <partition name="1" replicationGroupRef="EmployeeRGroup" /> </partitionSet> <partitionSet id="LedgerPSet"> <partition name="1" replicationGroupRef="LedgerRGroup" /> </partitionSet> <partitionSet id="BooksPSet"> <partition name="1" replicationGroupRef="BooksRGroup" /> </partitionSet> <partitionSet id="CDsPSet"> <partition name="1" replicationGroupRef="CDsRGroup" /> </partitionSet> <!-- what server will each replication group member be hosted upon--> <replicationGroup name="PayrollRGroup"> <replicationGroupMember serverRef="server1" priority="1" /> </replicationGroup> <replicationGroup name="EmployeeRGroup"> <replicationGroupMember serverRef="server2" priority="1" /> </replicationGroup> <replicationGroup name="LedgerRGroup"> <replicationGroupMember serverRef="server3" priority="1" /> </replicationGroup> <replicationGroup name="BooksRGroup"> <replicationGroupMember serverRef="server1" priority="1" /> </replicationGroup> <replicationGroup name="CDsRGroup"> <replicationGroupMember serverRef="server2" priority="1" /> </replicationGroup> </cluster-config>Conceptually, the server configuration would appear similar once the servers are initialized. Note that each server is a JVM.
Server1 Server2 Server3 1 2 3 4 5 Replication group member mapping to ObjectGrid cluster servers
In this example, the replication group member mapping is as follows:
1 - MapSet CDsMSet Replication Group Member 2 - MapSet PayrollMSet Replication Group Member 3 - MapSet EmployeeMSet Replication Group Member 4 - MapSet BooksMSet Replication Group Member 5 - MapSet LedgerMSet Replication Group MemberEach replication group contains only one member in this case (all primaries, no replication or partitioning is supported).
ObjectGrid client example
The client code would be able to contact the servers to boostrap itself and acquire an employee record:
// Contact the factory for this JVM ObjectGridManager mgr = ObjectGridManagerFactory.getObjectGridManager(); // Acquire a cluster context, require 1 for each cluster the client contacts, the // client can bootstrap against any particular server member. ClientClusterContext cluster1 = mgr.connect("MyCluster1Name", "localhost", "12503"); // refer // Use the cluster context to actually ObjectGrid og = mgr.getObjectGrid(cluster1,"accounting"); // Create a transacation to get the particular employee object Session session = og.getSession(); ObjectMap map = session.getMap("employee"); session.begin(); Integer ivKey = new Integer(1); Employee emp = (Employee) map.get(ivKey); session.commit(); // Detach from the cluster cluster1.disconnect();
In this example, the client initially bootstraps to any ObjectGrid server in the cluster using the connect(...) API call. This step dynamically downloads the ObjectGrid and ObjectGrid cluster configuration. The user will receive a cluster context back, which should be used in subsequent operations to acquire an ObjectGrid from the ObjectGrid cluster selected. Client programmers can contact 1 or more different clusters. Each cluster is a separately managed resource, but available to all clients if they can access and have the proper security credentials (if security is enabled).
The remainder of the sample, with the exception of the final ClusterContext disconnect() call is normal ObjectGrid APIs as described in the WebSphere XD V6.0 release.
Replication overview
Replication enables high availability within an ObjectGrid cluster. To further enhance the previous example, we now add replication targets for a subset of the replication groups. A replication group can have an attached policy which advises the run time how to enforce the replication configuration. Among other things, the policy attributes can control the following:
- The number of replicas that are replicated to at any given time.
- How many replicas have to be up or the replication group should become inactive.
- How many standby's are required for recovery or maintenance purposes. A standby server is simply a replica that is not yet receiving replica updates. Once a replica failure is detected, the replication logic will select one standby to be a replication target from the primary and reset the failing replica.
To enable replication for each replication group, the only change required is to augment the replication group members listed for each replication group that correlates to a given partition set of a specific MapSet. Thus, in the example below we assume that the MapSets for Books and CDs do not need to be replicated as the content is probably read-mostly and illustrates some diversity in the example. Furthermore, we assume that Employees, Ledger and Payroll should have at least 1 replica to failover to in case the primary fails, and for this example we will give Ledger 2 replicas.
<replicationGroup name="PayrollRGroup"> <server ref="server1" priority="1" /> <replicationGroupMember serverRef="server2" priority="2" /> </replicationGroup> <replicationGroup name="EmployeeRGroup"> <replicationGroupMember serverRef="server2" priority="1" /> <replicationGroupMember serverRef="server3" priority="2" /> </replicationGroup> <replicationGroup name="LedgerRGroup"> <replicationGroupMember serverRef="server3" priority="1" /> <replicationGroupMember serverRef="server1" priority="2" /> <replicationGroupMember serverRef="server2" priority="3" /> </replicationGroup> <replicationGroup name="BooksRGroup"> <replicationGroupMember serverRef="server1" priority="1" /> </replicationGroup> <replicationGroup name="CDsRGroup"> <replicationGroupMember serverRef="server2" priority="1" /> </replicationGroup>
Server1 Server2 Server3 1 2-1 2-2 3-1 3-2 4 5-3 5-2 5-1 Replication group member mapping to ObjectGrid cluster servers
The replication group member mapping is as follows:
1 - CDsMSet Replication Group Member 2 - PayrollMSet Replication Group Member 3 - EmployeeMSet Replication Group Member 4 - BooksMSet Replication Group Member 5 - LedgerMSet Replication Group MemberFor each replication group configured with more than 1 server, the Y (in the X-Y format) indicates the server that hosts a member of that replication group (note that this does not indicate primary or replicas which is determined dynamically at run time).
In this configuration, upon server start, the replication group for MapSet LedgerMSet (#5) would have replication group members on server1, server2 and server3. Dynamically, the primary and replicas will be determined. If only 1 replica is specified in the policy, one of the three would become the standby. Upon a primary or replica failure, the replica logic will determine which of the LedgerMSet replication group members will become the new primary. Depending on the policy, it may also turn out that the replication group will be deactivated. For example, if the policy states that 2 active replicas are required, and there are only two members, the replica group will be inactive until the third server is restarted. To avoid this, a fourth server could be added to the replication group so there would be one primary, two replicas and one standby. In the event of one replica failing, the standby will be targeted as a new replica. It will take some time to get the standby populated with the data (as standby's are not populated during transaction commits to the primary), but the policy will be honored and give the administrator time to correct the failing server.
Checkpoint based replication
The server holding the primary slice replicates the data slice to the replicas using a checkpoint based system. The primary server maintains a checkpoint and a log. The log holds all changes made on the server since the checkpoint was created. If a new replica server starts, then the checkpoint is sent first and afterwards the log is sent using a heavily optimized format to minimize the time it takes to bring a replica up to date. The checkpoint on the primary is periodically rolled up to the latest level. The more recent the checkpoint is, the faster a replica can be brought up to date.
Partitioning overview
ObjectGrid supports the concept of partitioning an ObjectGrid MapSet. This function primarily helps with scalability, and addresses challenges customers often face when a particular data set is large.
For example, 32-bit JVMs have a maximum heap addressability of 2 Gigabytes. If we are concerned that our 1 Gigabyte data set could grow to 2 or more Gigabytes, we would need to partition our data into two different maps and put each into different servers. This could be done by creating a second map, and placing on two different servers (replicas for each, and so on). However, this does add complexity to the client programs.
Another scenario is that a large dataset is read mostly (updated once per week or month, for example) but is heavily used during the week. An example for this is historical stock information that is rendered via technical analysis charting services. If the data is large in quantity, say 5 Gigabytes, it may be helpful to spread the data across 10 servers to share the load required to yield that data. In this example, each server would serve about 1/2 Gigabyte of information. This sounds interesting, but partitioning benefits also come with careful planning and implementing "partitionable" client side software practices.
To separate one table into two or more to handle the data will directly impact the client programming. With ObjectGrid, the data can be partitioned by ObjectGrid looking at the key for the data, and hashing it to a given server in the set. With this approach, the radical step of separating the data into separate maps and possibly databases is not required for reasons of scalability alone.
ObjectGrid will partition based upon the hashcode of the individual keys used in the ObjectGrid APIs (and server side for preloading, etc...). In addition, we can have our keys implement a PartitionableKey interface if the default implementation is not hashing evenly or too basic for the particular solution (for example, compound key value to partition id). This interface will be consulted when inserting a key and will execute an algorithm such as
hashcode(key) mod the number of partitionsin the configured PartitionSet for that MapSet entry. Fundamentally, the partition id for each partitionable Mapset is an integer whose value is between 0 to n-1, corresponding to the partitioning defined in the PartitionSet specification for the Mapset.
Server peer bootstrapping
Server peer bootstrapping refers to how servers become aware of the ObjectGrid map set definitions and cluster topology configuration. The servers can be configured to read the same configuration files (ObjectGrid definition and cluster definition) that provides the initial configuration. This approach is required for the first server starting up in the cluster. Subsequent servers could also read from the files, but the preferred approach is to receive the most current configuration data from an already running server.
To peer bootstrap a server, the administrator provides the host and client access port of a running server. When a new server starts up, it will contact the running server, the running server will then send back the serialized configuration object, via TCP, to the requesting client (or server, in this case).
It is important that within a single cluster this configuration is the same. What this really means is that all servers have the same configuration and know each others' configurations as well. This helps in correctly routing requests to servers that are hosting the BackingMaps. For instance, if a BackingMap is a replicated read-only map, then the requests can span multiple servers, unknown to the user. If a server goes down/restarts, this configuration update is shared among the servers and request routing is handled appropriately. For secure installations, provisions are available to ensure a secure network bootstrap is possible. Currently, there is no support for the multicast protocol for bootstrapping, so it is necessary to supply host and port information when bootstrapping.
Client connect/bootstrapping
Just as a server can bootstrap itself, a client can connect itself to a server within a cluster. The process is to download the configuration object to the client, similar to the server, as described above. This client process is then aware of the server configuration. It then connects to the correct server for ObjectGrid operations.
Systems management (JMX)
In order to facilitate easy-to-use systems management functions, there are two options for executing system management commands. First, we can call any command through the client/server infrastructure currently in place using the ObjectGridAdministrator interface. The second choice is to use JMX to call these same commands, with the ObjectGrid MBean acting as a wrapper to the ObjectGridAdministrator.
The ObjectGrid JMX and MBean administration model was created to take advantage of the various JMX consoles that are available for administering JMX environments. We can put together dashboards using the JMX console of our choice. Consoles can be attached to the MBeans running on the ManagementGateway Java virtual machine (JVM) and dashboards can be assembled using these MBeans. Consoles offer graphical histories or charts of numerical and string values.
To access the ObjectGrid Management MBean, a ManagementGateway process needs to be started. The ManagementGateway is a standalone process that acts as a server for a client process that wants to make JMX calls, but also as an ObjectGrid client to the cluster to which the user wants to connect. The ManagementGateway takes three user-defined parameters when starting up:
- Port number on which the JMX Connector service is available
- Host which has a server in the ObjectGrid cluster
- Port number of one of the servers in the ObjectGrid cluster
Once the ManagementGateway is started, a connection is established to the cluster and the JMX Connector service becomes available. We can then access the JMX Connector service through MX4J or J2SE 5 APIs.
Systems management example
Here is a detailed example scenario of how a user could use JMX and the ManagementGateway to stop all of the servers in a particular cluster.
A cluster of three servers is already started on system myhost and one of the servers has client access port 15000. The first step is to start the ManagementGateway process. The com.ibm.ws.objectgrid.gateway.ManagementGateway class has a main() method, so assuming the classpath contains the proper ObjectGrid and MX4J jars and that we want to start the JMX Connector service on port 1199, the command is
java com.ibm.ws.objectgrid.gateway.ManagamentGateway -connectorPort 1199 -objectGridHost myhost -objectGridPort 15000Starting the ManagementGateway does the following:
- Makes a client connection to the cluster
- Gets the ObjectGridAdministrator object and creates a Management MBean
- Starts the JMX Connector service and makes it available on port 1199
Now we have to write a small client program using MX4J or J2SE 5 to get access to the MBean...
MXServiceURL url = new JMXServiceURL("service:jmx:rmi://myhost/jndi/rmi://myhost:1199/jmxconnector"); JMXConnector c = JMXConnectorFactory.connect(url); MBeanServerConnection mbsc = c.getMBeanServerConnection(); Iterator it = mbsc.queryMBeans(new ObjectName("ObjectGrid:type=ObjectGrid"),null).iterator(); ObjectInstance oi = (ObjectInstance)it.next(); boolean stop = ((Boolean)mbsc.invoke(oi.getObjectName(),"stopCluster",new Object[]{},new String[]{});This code gets the Management MBean, then invokes the stopCluster() method on the com.ibm.ws.objectgrid.management.Management class. This in turn calls the ObjectGridAdministrator's stopCluster() method. The ObjectGridAdministratorImpl sets up a system of queues between the client and each server. A message is sent to each server informing it to stop.
Other MBean functions can be called in a similar matter. These are the available functions:
- Map-level statistics including hit rate, number of entries in map, and response time of batch update
- ObjectGrid-level statistics including transaction response time
- stopServer
- stopCluster
- ReplicationGroup status including which ReplicationGroupMembers are primary/replica/standby
- ReplicationGroupMember status including how many transactions have yet to be processed and whether the member is available
- Server status including whether the server is running and accepting transactions
- setServerTrace
Systems management security
The full path from client to ManagementGateway to ObjectGrid server will be secured using SSL, the typical ObjectGrid client/server security mechanism, and JMX security. When a client JVM communicates with the ManagementGateway, the JMX security APIs will be used. When the ManagementGateway acts as a client to the ObjectGrid cluster in order to get statistics, status, or perform administrative functions, the client/server security mechanism is used. The credentials are passed end-to-end - transparently to the end user.
Security updates
In the ObjectGrid programming model in the WebSphere XD V6.0 release, security mainly consisted of the JAAS authentication and authorization mechanism to authorize client access to ObjectGrid maps and administration. We can use the JAAS authorization mechanism or plug in our own authorization mechanism to authorize accesses. In version 6.0.1, the security mechanisms have been extended to include:
Client/server communication Client/server communication can be secured using SSL. The client is authenticated on the server side. ObjectGrid provides basic authentication (user ID and password) and client certificate authentication. Single sign-on (SSO) capability is also provided so that only one authentication is required if a client connects to multiple servers. In addition, we can also plug in our own authentication mechanism. Server-server communication To allow only certain servers to bootstrap to a running ObjectGrid cluster, authentication among servers is provided. The authentication credential is a user-configured string agreed by all servers. It is encrypted and signed as a byte array before being sent out, and is verified and decrypted on the receiving side. Gateway security ObjectGrid provides a ManagementGateway to serve as the central point to manage the ObjectGrid infrastructure and query the status, statistics, etc. The full path from client to ManagementGateway uses JMX security, and the path from the ManagementGateway to the ObjectGrid server uses the client/server security model. Client identity is propagated from the ManagementGateway to the server.
Indexing
The indexing feature is used to build an index against the BackingMap based on one attribute of the stored object. This feature provides a faster way for applications to find wanted objects. Without the index, applications have to locate objects by their keys. The indexing feature allows applications to find objects by a specific value or a range of values. This is similar to EJB Query that can locate EJB objects by a query that specifies criteria. The advantages for applications are not only the convenience to find objects, but also the performance improvement in the locating objects process.
Two types of index are provided in version 6.0.1: static and dynamic.
- Static indexing requires that the index configuration has been added into the BackingMap before ObjectGrid initialization, either through XML configuration or programmatically configuring the BackingMap. Static indexing starts building the index during ObjectGrid initialization, is always in synchronization with the BackingMap and is thus always ready for use. After the static indexing process started, it is always running against the BackingMap. Applications have no control of the static indexing process.
- Dynamic indexing requires index configuration been added into the BackingMap after ObjectGrid initialization. Applications have life cycle control over the dynamic indexing process. The dynamic indexing process can be created anytime and removed when it is no longer needed. After the application creates and starts the dynamic indexing process, the index might not be ready for use right away because it might take a while to complete the index building process. Because of this, dynamic indexing provides a callback interface. If applications wish to get notification at the event of ready, error, or destroy, they can implement the callback interface and register with the dynamic indexing process.
In WebSphere XD V6.0.1, the scope of indexing is the local JVM, not the cluster if the BackingMap is partitioned and located in multiple servers.
Dynamic proxy
The proxy object creation mechanism is required to support the COPY_ON_WRITE copy mode configuration of the BackingMap. In WebSphere XD V6.0, the ValueProxyInterface approach is provided, which requires applications to provide a ValueProxyInterface per Object type that wants to be stored in the BackingMap configured with COPY_ON_WRITE copy mode. In WebSphere XD V6.0.1, the CGLIB will be used as the default proxy object creation mechanism, if the CGLIB is in the classpath.
CGLIB is a proxy generator. It can extend any non-final class and implement interfaces at run time. It is a more sophisticated implementation of the java introspection framework. For example, it provides facilities to generate dynamic subclasses to enable method interception allowing features such as runtime instrumentation of code. See Class Enhancer.
With CGLIB, there is no need of the valueInterfaceClassName which can simplify the programming model. We can simply configure the BackingMap with COPY_ON_WRITE copy mode without the need to provide the ValueProxyInterface class name. If we provide the ValueProxyInterface class information, it will be ignored.
If the CGLib is not in the classpath, the ValueProxyInterface approach will be used and we have to provide the ValueProxyInterface class name, otherwise, an IllegalArgumentException will be thrown.
Persistence Manager Adapter
WAS V6.0.2.3 and higher provides an API to allow third party vendors to plug their own cache products for Container Managed Persistence beans (CMP EJB's). ObjectGrid's PMAdapter, implements both API's, that is, the API for pluggable cache products and the ObjectGrid API, to be a "layer"/Adapter to allow plugging of an WebSphere XD ObjectGrid as an external cache instead of a built-in, as provided by the WebSphere Persistence Engine. Currently this adapter only supports local semantics of ObjectGrid and does not support remote ObjectGrid connectivity.
HTTP session replication using servlet filter
This consists of the ObjectGrid core together with a servlet filter that can be added to any WAR file. The filter first intercepts requests and provides HTTP session management in place of whatever session management exists in the underlying Web container.
The filter also provides HTTP session persistency by writing the session to the ObjectGrid and the ObjectGrid can be configured to make this data highly available through it's replication mechanisms. The style of persistence depends on how the ObjectGrid is configured. A normal configuration would be a local cache fronting a partitioned/replicated cache cluster - probably using keyword based partitioning. Other useful configurations would include N replicas being held at a time of the session. The servlet filter can be attached to any J2SE 1.4 based servlet container.
The mechanism by which this session management functionality is provided involves introducing a servlet filter into the request processing path, via a filter declaration in the Web deployment descriptor that accompanies any Web application. The session manager will derive its configuration settings from the servlet context init parameters that are set on the Web application. This filter declaration and servlet context init parameters can be hand-edited into the Web deployment descriptor or they can be spliced into an enterprise application via the use of a filter splicer utility that is packaged with ObjectGrid.
The filter wraps the incoming request object with a custom wrapper, that satisfies all session related method calls that a servlet/JSP may invoke on the request object using the ObjectGrid based session manager. It should be noted that support for filters was introduced in version 2.3 of the servlet specification and then expanded to include forwarded and included servlet requests in 2.4 of the specification.
In order to be able to support both versions of the specification, this session manager only introduces a filter into the request handling path that is, not in the forwards/includes handling path. This way, even if a request is forwarded between servlets from disparate Web modules, or if it includes servlets from different Web modules, at any given point in time there will only exist one ObjectGrid session manager related custom wrapper around the incoming request. The request wrapper queries the current servlet context path to determine the Web module that its methods are being invoked in, and provides visibility to attributes only accessible in that Web module.
This also allows single server WebSphere JVMs (that is, Network Deployment is not required) to be clustered together so that HTTP session failover works for these single servers. These servers will need a load balancer such as an IP sprayer or dedicated HTTP sprayer in front of the cluster in order to spray incoming HTTP requests over this virtual cluster.
ObjectGrid usage scenarios
This section describes a variety of ObjectGrid usage scenarios such as:
- A CMP customer requiring advanced caching (needs V6.0.1)
- WebSphere application requiring advanced caching
- J2SE application requiring advanced caching
- Providing HTTP session failover for Web applications (requires V6.0.1)
- Applications using WebSphere Partition Facility in WebSphere XD (requires V6.0.1)
- Applications using third party object relational mapper
- An object integration tier
Scenario 1: CMP customer requires advanced caching (V6.0.1)
Customers using at least WAS V6.0.2 and WebSphere XD V6.0.1 can replace the built-in option C CMP cache with the ObjectGrid. This allows them to use the more advanced caching capabilities provided by the ObjectGrid in the application. The ObjectGrid can be custom configured using an XML file to use the correct caching model required by the application. The application can also use the persistence manager APIs to interact directly with the ObjectGrid. This is necessary to use some features such as:
- Keyword association with the transaction
- Eviction based on keywords
- Keyword based partitioning
If the application doesn't need to use these features then the ObjectGrid is transparent to the application.
CMP integration with ObjectGrid is available only in IBM WebSphere XD version 6.0.1.
Scenario 2: WebSphere application requiring advanced caching
J2EE applications on WebSphere 5.0.2 or higher can take advantage of the ObjectGrid directly and use it as a cache for application data. The cache can be used as a look-a-side cache where the application is responsible for handling cache misses and placing them in the cache or a Loader can be plugged in and then the Loader is responsible for handling cache misses. The cache can be configured in this case using either APIs, XML or using third party frameworks such as Spring.
This scenario refers to using the ObjectGrid core for a side cache. The ObjectGrid server and clustering features require WebSphere XD version 6.0.1.
Scenario 3: J2SE application requiring advanced caching
A J2SE application can also use the ObjectGrid directly to provide caching. This is very similar to the WebSphere application scenario. Examples of J2SE environments include the following:
- A WebSphere thick client
- A WebSphere thin client
- A J2SE application
- A Web application using standalone Tomcat
- Any competitive environment running on at least a J2SE 1.4 JDK
Scenario 4: Providing HTTP session failover for Web applications (V6.0.1)
HTTP session replication using ObjectGrid is available only in IBM WebSphere XD version 6.0.1.
Scenario 5: Applications using WebSphere Partition Facility in WebSphere XD (V6.0.1)
Currently, the application needs to use some workarounds to be functional when using caching. A typical WPF application uses a combination of option A and option C with cache CMPs. The integration of ObjectGrid with CMP allows these applications to use a much more acceptable model using only option C with cache beans. The application can then interact with the cache using understood APIs rather than the current approaches documented in the WPF guide.
CMP integration with ObjectGrid is available only in IBM WebSphere XD version 6.0.1.
Scenario 6: Applications using third-party object relational mappers
A lot of customers currently use third party components to provide their applications persistence needs. The ObjectGrid can be plugged in to these third party products as a second level cache as can the competitive cache products such as the open source ones and commercial ones. This allows customers going down this route to still benefit from the ObjectGrid technology even when the application using a third party object relational mapper isn't deployed on a WebSphere application server.
Scenario 7: An object integration tier
Some customers have large quantities of data obtained from a variety of sources. The volume of this data can be large, from 1-100 GB in size. These objects are expensive to construct and thus many customers want to cache them. Applications with these requirements could be products such as DB2 Information Integrator to gather the data and then store it in a partitioned ObjectGrid cluster. Applications can then use the objects directly. Customers could also write a Loader that obtains the data. Or they can also use async beans with application partitioning to write daemons that gather any changes to the data and keep the cache cluster up to date. Such applications may opt to use a local cache in front of the cluster if they expect any data locality. But, some applications will not look up the same object frequently and a local cache may not be useful. However, even in that scenario, the cache is still useful as once the object is in the cache then it's cheap to obtain from the cache versus constructing it from the raw data sources again. Plus, obtaining the data from the cache cluster provides reasonable and predictable response times versus constructing from raw. Once the data is kept in the cache cluster then many applications can leverage this resource so long as they share the same data access layer. Large numbers of these objects can be stored in the ObjectGrid because it can be partitioned if required. This lets the ObjectGrid scale linearly with the amount of member in the members of the cluster. Application downtime due to a cache server failure can also be avoided through the use of replicating cache servers. This replication to avoid downtime can be important as preloading a cache server can be very time consuming. The application cannot afford the performance impact of fetching the data from the raw sources during this time and also cannot afford the downtime of waiting for a preload to complete.