WebSphere Partitioning Facility
- Overview
- Partitioning patterns
- Data partitioning pattern
- Singleton pattern
- Partitioning
- J2EE application partitioning
- Partitioned stateless session bean
- EJB workload partitioning
- IIOP routing to a partition
- Database partitioning
- Proxy DataSource
- HTTP partitioning
- The role of the On Demand Router
- Partition life cycle
- Partition alias
- Partition grouping
- Partition grouping structure
- Usage scenarios
- WebSphere Partitioning Facility operations
- Verifying the application is started
- Balancing partitions
- Moving partitions
- Enabling performance monitoring
- Monitoring transaction performance statistics
- Monitoring WebSphere Partitioning Facility partitions
using the Administrative Console- Partitioning facility management
- HAManager
- Core group
- Core group coordinator
- Policy
- HAManager quorum attribute
- Highly available partitions
- Partition scope
- Cluster-scoped partitions
- Node-scoped partitions
- Partition layout strategies
- Default configuration
- Startup scenario in default configuration
- HA groups and partition naming
- HAManager policy matching algorithm for partitions
- How do HA groups for partitions map to policies?
- All partitions within an application
- All partitions within a specific application class and application
- A specific partition which isn't in an application class
- A specific partition which is in an application class
- Static partition scenario
- Preferred server with failback scenario
- Disable a partition from running on a single JVM
- Disable a partition from being activated at all
- Disable all partitions for an application
- Managing policies
- Management script (wpfadmin)
- listActive
- list
- move
- balance
- disablePartition
- enablePartition
- enableWPFPMI
- subscribeWPFPMI
- disableWPFPMI
- listPolicies
- Performance monitoring
- Enabling WebSphere Partioning Facility PMI
- Enabling WPFPMI using the wpfadmin command
- Enabling WPFPMI using the Administrative Console
- WebSphere Partitioning Facility PMI path
- WebSphere Partitioning Facility PMI data aggregation
- WebSphere Partitioning Facility PMI statistics subscription
- WPF programming
- Partition stateless session bean (PSSB)
- PSSB <Bean>_PartitionKey routing class
- Updating the PSSB bean generated stub
- Partition routable session bean (PRSB)
- Facade interface for a partitioned stateless session bean
- PSSB local interfaces
- Partition router object (<EJBName>_PartitionKey class)
- Partition names
- Cluster scoped partition names
- Node scoped partition names
- Designing our environment for partitioning facility
- Scalability considerations
- Partition design
- Policies design
- Cluster member memory usage for active partitions
- Defining more than one core group coordinator
- Configuring preferred servers for core group coordinators
- Asychronous delivery using Async Bean
- Application hosting on nodes and cluster members
- Working with partitions
- Mixing application types
- Option A CMPs
- Lazy EJB startup
- Problem resolution
- Core group coordinator JVM trace files
- Core group runtime view
- Tracing
Overview
The WebSphere Partitional Facility is a programming framework and runtime environment that enables high transaction volume applications to scale linearly. Applications are partitioned to uniquely addressable endpoints within a cluster, where requests for certain EJBs or data are always routed. Partitioning reduces data contention and the overhead of replicating shared data, like caches or state information.A series of design patterns has emerged over the past years to enable high performance computing. These patterns have been identified and documented as a series of new capabilities introduced in WebSphere Extended Deployment (XD). The first design pattern that XD provides is the partitioning pattern, which introduces the concept of application partitioning. This pattern is further broken down to the data partitioning pattern and singleton pattern. Support for these patterns is also provided by the partitioning facility.
The goal of partitioning is to provide the ability to control specific resources during cluster member execution. Requests can be routed to a specific application server that has exclusive access to certain computing resources such as a dedicated server process or database server. The requests can be a HTTP, EJB or database read or update with the endpoint receiving the work being highly available. WebSphere Partitioning Facility offers functionality to route work to a particular cluster endpoint. This reduces overall system overhead while retaining high availability of each endpoint.
As a result, WebSphere Partitioning Facility is designed to make it easier to develop applications with the following characteristics:
- Write-intensive applications that traditionally do not scale well because of contention
- Applications that must process high-speed message feeds
- Applications with a need for singletons that must be made highly available
Partitioning patterns
The partitioning facility has been designed to address bottlenecks found in high volume Online Transaction Processing (OLTP) applications which read and write data intensively to databases requiring consistency and availability. All applications that use a database will experience some contention within the database due to locking. WebSphere Partitioning Facility eliminates contention between servers by creating partitions so that servers do not need to interact with each other, therefore achieving linear scalability.
Data partitioning pattern
Currently, applications servers are optimized for read-mostly applications which take advantage of its caching capabilities to off load the backend database systems. Here, caching makes a big difference. The low write rate allows WebSphere to exploit caching and gain good performance as the cluster size increases. However, as the application increases its database write ratios, these caching capabilities start to breakdown because of the increase need to maintain consistency between the cache and database. This type of system often leads to large and costly database configurations, often running on large SMP machines. In a high-volume environment, these database servers inevitably become both the cost and performance bottleneck.
Consider a high-volume stock trading application that has a very high traffic-growth rate. In a traditional J2EE environment, this application would run in a cluster of application servers, such that requests for buying and selling for each symbol are distributed to individual cluster members. This is also known as symmetric clustering, where all cluster members can perform any task at any time. This type of clustering does not scale well because the database server becomes the performance bottleneck.
Figure 8-1 Traditionally clustered J2EE application
The data partitioning pattern aims to offload the database by enabling the application server tier to act as a buffer. It also makes interactions with the database more productive by reducing contentions.
This pattern maps a subset of the data to a single server only. This server can then aggressively cache that data because it knows all requests for that subset are being routed to a single server. The data can be partitioned in different ways: by using either a variable set of partitions or a fixed set of partitions.
As an example, our stock trading application could be partitioned across a cluster of servers, such that requests for buying and selling each stock symbol are routed to a partition associated with that symbol. There may be more partitions than servers in the cluster, meaning each server is running multiple partitions. The work is effectively divided into unique data sets across the cluster, simplifying data replication and reducing overhead. Furthermore, if the underlying database is designed such that separate database instances correspond to the data that would be accessed by individual partitions, then contention on the database will be reduced as well.
This type of an environment scales extremely well. Adding additional hardware will simply reduce the number of partitions that must be hosted by each individual cluster member, giving the cluster added capacity without additional overhead normally associated with large scale clustering. This approach, where applications can run in one or more partitions on a single cluster member at a time is also known as asymmetric clustering. Unlike symmetric clustering, incoming requests for a partition are routed to the cluster member hosting the appropriate partition.
Figure 8-2 Application and data are partitioned across the cluster
When using a One of N policy for the partitions, the WebSphere High Availability Manager (HAManager) will activate each partition on exactly one cluster member. This is very useful if an application has some long-lived tasks that would benefit from running only on a single cluster member at a time.
Singleton pattern
A partition can be the point in a WebSphere cluster where a particular function or service of single cardinality resides. In this case, the service is said to be a singleton because it is the only place in the cluster where this function is running. The singleton pattern allows applications to be broken up and run across the cluster.
Consider a stock-trading application that requires incoming work to be executed in a sequence. The orders for buying and selling of a stock symbol must be processed in the correct sequence. In a symmetric cluster, orders arrive and are distributed across the cluster for processing. In this case, the sequence would not be preserved. Special programming is often used to maintain the correct sequence, but it is complex and by no means easy.
The singleton pattern allows an application to partition itself and then route incoming work exclusively to a single partition. The cluster member can process the orders and knows that the sequence has not been changed by other cluster members.
Partitioning
WebSphere Partitioning Facility is the facility through which partitions are created and managed in WebSphere XD. A partition is a uniquely addressable endpoint within a cluster. A partition is not a cluster member or a JVM. Each cluster member might host multiple partitions, but each partition exists on only one cluster member. Each partition is started as a highly available singleton, managed by the HAManager infrastructure. This ensures that the partitions remain constantly available while running in only one cluster member at any given time. A partition is created dynamically at startup during J2EE application initialization and then available for client applications to use as a target endpoint when in the active state.
J2EE application partitioning
Application partitioning allows workload to be routed to specific application partitions. With application partitioning, we can set up areas of the server where we know work can be performed that will not occur anywhere else in the cluster.
In the stock trading application example shown in Figure 8-2, the application is partitioned across a cluster of servers, such that requests for buying and selling each stock symbol are routed to the partition associated with that symbol. The work is effectively divided into unique data sets across the cluster, simplifying data replication and reducing overhead.
A partitioned J2EE application is a typical J2EE application with a single partitioned stateless session bean (PSSB). It is common to have a number of EJB modules within an application EAR file. However, only one EJB module can contain the single PSSB.
Partitioned stateless session bean
The partitioned stateless session bean (PSSB) is the central element of application partitioning. It allows the application server to query the application at startup to determine which partitions the application requires. It is also used by the application server to inform the application when a partition is activated or deactivated. Activated means the HAManager has assigned a partition to this cluster member.
Refer to section 6.2 "Core group" and especially section 6.2.4 "Core group policy" of the redbook WAS Network Deployment V6: High availability solutions, SG24-6688 for infomation about how the HAManager assigns partitions to a cluster member.
In addition, the partition names chosen during the PSSB Partition Manager initialization sequence must be unique within the cluster. The partitioned J2EE application should be installed in the cluster at the node scope level. The new cluster scope level introduced in IBM WebSphere Network Deployment V6 should not be used.
A PSSB can also be called from within a HTML, JSP or servlet by looking up the PSSB in the JNDI namespace. A servlet will typically execute a remote method of the PSSB remote interface, which will result in a routed call to the server with the appropriate target partition endpoint.
There are various types of programming strategies for PSSBs such as calling the EJB directly, or using a partition routable bean and a facade session interface to the PSSB. Both approaches allow the PSSB to provide the underlying routable support, but allow the business interface to be externalized in another bean within the same application.
EJB workload partitioning
A partitioned J2EE application is simply a normal J2EE application with a partitioned stateless session bean (PSSB). Here is a traditional J2EE application deployed to a cluster of two application servers running on two separate nodes. The application also consists of two EJBs.
Figure 8-3 Typical J2EE EJB clustered workload processing
In this example, each client request is routed from the EJB client through the object request broker (ORB) and the WLM plug-in to EJB1 in a round-robin fashion between the EJB1 instances. Both EJB1 instances are active in the cluster, and appear identical to the client from which work is distributed between them transparently by the WLM plug-in. While the ability to share the requests helps scalability, there are implicit limits and constraints to ensure the same data is loaded in each EJB instance to avoid any data inconsistency. This is the reason for the transparent functionality provided in the EJB container and other WebSphere components ensures data corruption is not possible, but it does take away some performance capabilities of the system.
The ability to allow two or more entity bean instances to share the same data is managed by WebSphere's EJB container and the database server. One of partitioning facility's goals is allowing a single endpoint in the cluster to handle all data for a specific instance, and reduce the burden of the WebSphere and database server to enforce these semantics. This will dramatically improve overall system scalability and throughput.
With IBM WebSphere Network Deployment V6, EJB container caching option A cannot be used in a cluster environment because option A assumes the entity bean has exclusive access to the underlying persistent store.
The partitioning facility now supports the concept of option A caching for entity beans in the cluster. This capability can only be realized when using the WebSphere Partitioning Facility programming model, and in some cases when used with the Async Bean support provided in the IBM WebSphere Network Deployment V6.
The partitioning facility requires a partitioned stateless session bean (PSSB) to be included in the J2EE application's EJB module. During the application startup sequence, one or more different partitions are created. Each partition is simply a uniquely addressable endpoint within the cluster. A PSSB is simply a stateless session bean that utilizes the WebSphere Partitioning Facility framework's Partition Manager to create individual partitions at bean startup time. In addition to the normal SessionBean interface, it also implements the PartitionHandlerLocal interface to process partition related life cycle events.
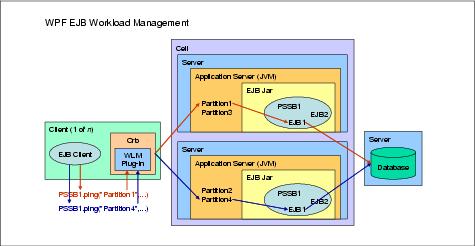
Because each partition is an endpoint, it is directly accessible by the EJB client. Here is the same J2EE application - when partitioned - contains PSSB1 in its EJB module. During application startup, partitions Partition1, Partition2, Partition3, and Partition4 are created. The EJB client invokes the ping method on PSSB1 with alternate values for the first parameter. This parameter is a key used by WLM to route the request to a specific partition endpoint within the cluster. Each partition has a life cycle similar to a normal EJB.
Figure 8-4 WebSphere Partitioning Facility EJB workload management
The EJB client would acquire the remote interface of PSSB1 via JNDI as usual, then execute the first ping(...) method with the key Partition1. Because WebSphere Network Deployment has been augmented with WebSphere XD, the WLM is able to route each call to a specific partition.
When designing a partitioned application that the requests should be directed to an application server which has exclusive access to specific resources. The WebSphere Partitioning Facility framework provides tools and APIs for the management of these partitions such as activation/deactivation, re-balancing of partitions, and when a partition is loaded or unloaded. A partition can also be moved to a different application server at any time.
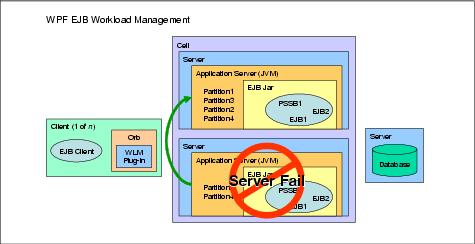
For example, if the application server hosting Partition2 and Partition4 fails, the HAManager would detect the failure and activate the failed partitions Partition2 and Partition4 on another surviving application server.
Figure 8-5 Partition failover senario
In this scenario, Partition2 and Partition4 would only experience a small outage due to the time required to detect and load the partitions on the surviving server. The recovery time can be fine-tuned based on business needs.
Partitions can also be moved to take up additional resources. If, for example, Partition2 experiences an increased load, it can be moved to another cluster member that is lightly utilized or has more computing resources. However, Partition2 still experiences a small outage during the move. If Partition2 must not experience any outage, then other collocated partitions such as Partition4 can be moved off to another cluster member, freeing up valuable resources to Partition2. There is a great deal of flexibility to meet operational requirements.
IIOP routing to a partition
EJB clients can call a remote method via the Object Request Broker (ORB) over Internet Inter-ORB Protocol (IIOP). When the client makes a remote call to the PSSB, the client stub determines which partition the request is intended for. The endpoint of the partition is determined using the workload management (WLM) component of WebSphere Network Deployment. The request is then sent directly to the cluster member hosting the partition. If more than one cluster member is hosting the partition, then the requests are dispatched in a round-robin fashion. Here is how IIOP routing is handled by WebSphere Partitioning Facility.
Figure 8-6 IIOP routing in WebSphere Partitioning Facility
To facilitate workload management for partitions in a WebSphere XD environment, a new partition router is used. This new router is called WPFWLM router or partition router. All IIOP requests will be sent to the WPFWLM router first, no matter whether the requests need partition routing or not. If the partition router decides that the request requires partition routing, it will use the partition routing mechanism to route this request directly to the right partition. Otherwise, non partition requests will be forwarded to the standard WLM router for further processing.
The routing behavior can be controlled by implementing the <EJBName>_PartitionKey.java class. This class is used to signal whether the partition router or the WLM router should be used.
Database partitioning
In addition to partitioning our application, partitioning the database that our application accesses can dramatically increase scalability. Database partitioning involves creating a separate database instance for the subset of data that will be accessed by each partition. This gives each partition exclusive access to the data that it will be using, reducing database contention and giving the application the freedom to more aggressively cache values in memory. It also gives we the ability to scale the database across multiple servers, rather than implementing a database clustering solution. Database partitioning requires careful planning and consideration at the time of application design. It is not a feature for which there is a simple on/off switch.
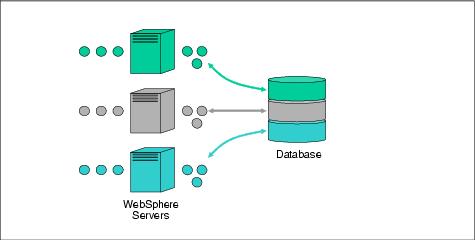
Although database partitioning has the obvious benefits of improved performance and scalability, it does require additional effort in database planning, programming, and configuration. However, the benefit often outweighs the required effort. For example, in a traditional clustered J2EE application, it is normal for the cluster to use a single database instance. This database becomes a single point of failure as well as an inhibiting scaling problem. It is a single point of failure because if it becomes unavailable, no work can be performed in the cluster. This is a scaling problem because most databases only scale vertically by buying a larger system. the following figure shows the single database server architecture in a traditional WebSphere Network Deployment clustered J2EE application.
Figure 8-7 Typical J2EE application with a single database node
In this diagram, there are two cluster members, but only one database server. If more cluster members are added to handle an increasing load, the database will become a performance bottleneck eventually.
Using database partitioning, we can scale the database horizontally by adding more database instances and mapping subsets of data to different database instances. The databases are independent of each other and a failure in one of the databases only means that the set of data residing there is now unavailable - but the application can continue to process transactions for the data residing in other online database instances. This is much more preferable to a complete failure. However, the administration is more complex as there are multiple databases instead of one.
The following figure shows the new architecture using two databases with EJB1 deployed in both servers. In one transaction, EJB1 in Application Server1 accesses Database1. In another transaction, EJB2 in Application Server2 accesses Database2. The database load is now spread across two database servers instead of just one.
Figure 8-8 Multiple database nodes with partitioned data
Proxy DataSource
Applications that use CMP beans normally specify a single datasource at the container level to use with the CMP beans. This approach is clearly not appropriate when the data is partitioned across two database instances. Although we could deploy the CMP beans one at a time with different datasources, this is not very flexible for the following reasons:
- Requires N copies of the code with JNDI names.
- Requires an additional deployment step when a database is added.
- Is difficult to manage.
WebSphere XD currently only supports database partitioning when using the DB2 JDBC drivers or the Oracle Type 4 JDBC driver.
WebSphere XD offers a feature called Proxy DataSource that allows applications to tell WebSphere which database to use before the transaction starts. When a cluster member receives a request for a particular application partition, it will tell the CMP runtime to ignore the DataSource the bean is deployed with and instead use a specific DataSource for the duration of the next transaction. This allows the directed transaction pattern to be used with the application, enabling it to increase its availability and allows the database tier to scale horizontally.
Refer to the WebSphere XD InfoCenter article entitled Proxy DataSource programming model for details on this programming model.
Beans using container-managed persistence must be invoked using their local interfaces. Also, the test connection feature of the Administrative Console does not support Proxy DataSources.
HTTP partitioning
The partitioning facility provides the capability to partition HTTP requests across backend WAS instances. Known as HTTP partitioning, this capability works in conjunction with the On Demand Router (ODR) that receives awareness of partition location and forwards HTTP requests to the appropriate target application server. This means that HTTP requests are predictably routed to a single endpoint, just as IIOP requests are.
A partitioned HTTP application must always contain a partitioned stateless session bean (PSSB), even if the partition mappings are defined in a partition.xml file, because the existence of the bean is what identifies an application as being partitioned. HTTP partitions can exist only on one server within a cluster, so node scoped partitioning, which is an option for EJB partitioning, is not available for HTTP partitioning. HTTP partitioning is also not designed to work with dynamic clusters, and partitions cannot be automatically rebalanced.
HTTP partitions are similar to EJB workload IIOP based partitions. They have the distinct feature that no data element belongs to more than one partition. This property enables the partitioning facility to decide how these data elements may be treated. That is, no data element belongs to two partitions and a single partition is only active on at most one cluster member. As a result, when an application receives a request for a particular partition, it can be certain that no other application instance is accessing this partition and the data elements associated with it. As such, the application can leverage this by being more aggressive in treating the partitioned data.
HTTP partitioning operates on the premise that incoming HTTP requests contain sufficient information to identify the partition associated with the request. This places two key restrictions on application architecture:
- Each HTTP request must access data associated with exactly one partition. This can be resolved by merging overlapping partitions into a single partition.
- The HTTP URL must contain the partition name. Hence care should be taken when designing the application's URL.
The role of the On Demand Router
The On Demand Router (ODR) serves as a reverse proxy between the HTTP client and the cluster member on which the partition is running. The ODR extracts the partitions name from the HTTP request and routes it to the cluster member that is currently serving this partition. The following figure shows Application Server1 is hosting Partition2. The HTTP partitioning function ensures requests are routed to the correct server, even in the event when a partition is moved from one cluster member to another.
Figure 8-9 The role of ODR in HTTP partitioning
Refer to the InfoCenter for more details on HTTP partitioning. Search for "HTTP partitioning" to see all related information. For example, the article Extracting partition names from HTTP requests.
Partition life cycle
A partition can be activated on any cluster member in a cluster. The HAManager guarantees there is a single instance of an active partition in the cluster at a given time within the cluster for cluster scoped partitions. The HAManager allows a partition to be moved from one member in the cluster to another using the wpfadmin command. When moving a partition, the partition state will be deactivated on the original cluster member and activated on the new target cluster member.
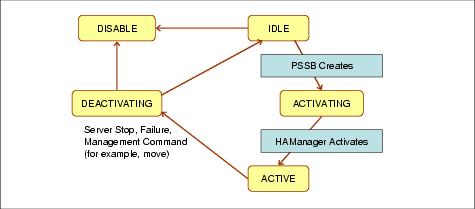
Partitions are by default highly available. A partition can only be hosted on a single cluster member at a time. They are made highly available using the HAManager. If a cluster member fails as a result of a JVM shutdown or JVM failure, then the HAManager moves all partitions which were running on the failed cluster member to another surviving cluster member. The following illustrates the state transitions a partition encounters as a member of an HA group.
State Description IDLE Partition is currently deactivated and waiting for an activation command. A partition is in this state during server startup after the createPartitionDefinition() through till the PartitionLoadEvent() method is called by the HAManager's core group coordinator. ACTIVATING HAManager is attempting to activate the partition but has not been acknowledged. This state is reached during the PartitionLoadEvent() method call within the partition stateless session bean (PSSB). ACTIVATED The partition is active and working. The PartitionLoadEvent() method has completed. This state implies the HAManager has selected a target cluster member for this partition. The work load manager (WLM) has also enabled clients to route requests to a cluster member with the specific partition. DEACTIVATING The partition received a deactivate signal and is still deactivating. This occurs during the PartitionUnloadEvent() method call within PSSB for the current partition. The partition then returns to IDLE. DISABLED This status means that the partition whilst still part of the HA group cannot become an active member. This is a failure state.
Partition alias
Partition alias gives us increased flexibility in how client requests are mapped to partitions. It provides the ability to round robin requests over a set of cluster specific partitions. It allows us more flexibility in programming because partition names can be changed later without changing the aliases. Partition alias also gives us the ability to group partitions within the same context, or to route requests to a partition based on a value other than the partition name.
Partition alias provides another way clients can route to a partition. Partition alias is not a replacement for the partition name, it is just another way to provide routing, other than by using the partition name. The benefits are:
- Increasing the flexibility of partition management
- Increasing the flexibility of coding
- User grouping of partitions
- Decoupling programming and deployment
Any string can be assigned as an alias of a partition and the same alias can be assigned to many partitions. Hence, many partitions can be associated with the same routing context. This makes it possible to group a set of partitions together. For example, partition P6 is assigned to the alias Alias1. A client can be routed to this partition by using either Alias1 context or P1 context. Partitions P2, P3 and P4 are grouped together and assigned to the alias of Alias2. A client using the Alias2 context can be routed to one of the partitions P2, P3 and P4 in a round robin fashion. Clients can still use the context P2 to be routed to partition P2.
Therefore, routing can use either partition alias context if it exists or partition context. If a partition alias does not exist for a partition and a client request uses a partition alias context, the client receives a NO_IMPLEMENT exception.
Refer to the article Partition alias programming in the WebSphere XD InfoCenter for programming examples. We find examples here that illustrate the use of mixed partition alias and non-partition alias programming.
Partition grouping
With partition grouping, we can group several partitions together, and clients can route to any partition in a group of partitions alternatively within the same group context.
The partition grouping feature provides mechanisms to group a subset of partitions so that they can share the same routing context. A cluster can have as many partition groups as we want; each partition group can have one or more partitions. Partition group routing will route clients to one of available partitions in a group alternatively and skip unavailable partitions. A weight-proportional routing algorithm is used among partitions in a group. WebSphere XD dynamic weights are still honored in the partition grouping.
Any string name can be assigned as an alias of a partition. The same partition alias can be assigned to many partitions, so many partitions can be associated with the same routing context. This new function also makes customer grouping of partition sets possible.
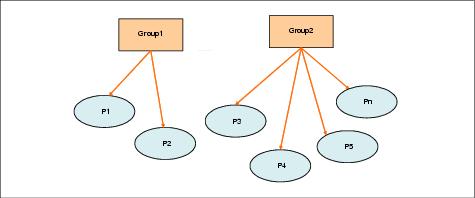
Partition grouping structure
For example, partitions P1 and P2 are assigned to the group Group1, so clients can be routed to these partitions by Group1 group context. Partitions P3, P4, P5, and Pn are assigned with to group Group2. Clients using the context of group Group2 can be routed to one of P3, P4, P5, and Pn in the weight-proportional manner.
Figure 8-12 Partition grouping
Refer to the sample application WPFPartitionGroupingSample.ear provided with IBM WebSphere XD V6.0 to see how this feature works.
Usage scenarios
In this section we use the DBChecking application to demonstrate a typical usage scenario for the partitioning facility. We explain several usage and system management examples as a precursor to diving into more complex functionalities.
The DBChecking application is a utility application that illustrates how highly available singleton services can be used to maintain global information that must be accessible to all cluster members. In our scenario, the global information that is maintained by the singleton service is the status of the database. This state is propagated to the application instances running on all cluster members so that the database is not accessed by the application when it is down.
The DBChecking application achieves this by using WebSphere Partitioning Facility for the singleton service and ObjectGrid for maintaining the database state on all cluster members.
Executing WebSphere Partitioning Facility operations
This section illustrates a few basic WebSphere Partitioning Facility operations such as verifying the application is started, moving or balancing partitions, enabling performance monitoring, and monitoring partitions.
For this scenario, the DBChecking.ear is installed into the RedbookClusterWPFOG cluster with three cluster members:
- WPFOG1
- WPFOG2
- WPFOG3
Note that DBChecker is the name of the actual class or instance hereof while DBChecking is the name of the application and of the EAR file.
Although DBChecker is installed on all cluster members, only the active partition for DBChecker is highlighted for clarity.
After the application is started we can execute the WebSphere Partitioning Facility operations described in the following sections.
Verify the application is started
To verify the partition has started, enter the following command at a command prompt on the Deployment Manager node:
# cd deployment_manager_home\bin #./wpfadmin.sh listActiveThe result should be similar to the output below...
/usr/IBM /WebSphere/AppServer/profiles/dmgr1/bin # ./wpfadmin.sh listActive WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[listActive]" CWPFC0050I: Application DBChecking, Partition singleton: Server xdcell\node3\WPFOG3
The output indicates that the application has started and one partition is activated. This is partition singleton on server WPFOG3. Without providing any specific policy, the server on which the partition is running depends upon which server is first registered in the HAManager quorum. Thus the partitions are not guaranteed to start in a specific location until the developer or administrator provide additional configuration data.
From our observation, the partitions always start in the same cluster member upon a cluster restart. If the application is redeployed, the partition will probably be activated on a different cluster member.
/usr/IBM /WebSphere/AppServer/profiles/dmgr1/bin # ./wpfadmin.sh listActive WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[listActive]" CWPFC0050I: Application DBChecking, Partition singleton: Server xdcell\node1\WPFOG1
After redeploying the application, the active partition has now moved to WPFOG1.
We can also list all partitions and the status of the cluster members with wpfadmin. This command can be scoped to only show information for a particular application, partition, and classification. Type the following command to list the partitions in a cell:
# cd deployment_manager_home\bin #./wpfadmin.sh listThe result should be similar to...
/usr/IBM /WebSphere/AppServer/profiles/dmgr1/bin # ./wpfadmin.sh list WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[list]" CWPFC0046I: Application DBChecking, Partition singleton xdcell\node1\WPFOG1* xdcell\node2\WPFOG2 xdcell\node3\WPFOG3The partition running on WPFOG1 is the active partition as denoted by the asterisk.
Another useful command is wpfadmin.sh countActivePartitionsOnServers. The result provides a count of the active partitions per cluster member.
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh countActivePartitionsOnServers WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[countActivePartitionsOnServers]" CWPFC0051I: Server xdcell\node3\WPFOG3: 0 CWPFC0051I: Server xdcell\node2\WPFOG2: 0 CWPFC0051I: Server xdcell\node1\WPFOG1: 1 CWPFC0081I: Total number of partitions is 1
Balancing partitions
In general it is possible to balance partitions across a set of active servers after they have been activated. Reasons for balancing partitions include:
- If we require partitions to be fairly balanced across the entire cluster based on expected transaction volume.
- If we have defined a new policy and want to balance the load more effectively using the HAManager's policy infrastructure.
To balance partitions, type the following at a command prompt:
# wpfadmin.sh balanceIn our example, because the DBChecking application has only one partition which is a singleton, there are no partitions to balance. The output from balancing should be similar to...
/usr/IBM/WebSphere/AppServer/bin # ./wpfadmin.sh balance
WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager
WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[balance]"
CWPFC0088I: More servers than partitions. Nothing to balance.
/usr/IBM /WebSphere/AppServer/bin #
Moving partitions
Sometimes it is desirable to move a less busy partition from one cluster member to another to free up resources for busy partitions. In this scenario, the less busy partitions will incur the temporary outage, which can be more acceptable than deactivating the busy partitions.
We can use the HAManager JMX commands to move the least busy partition from one server to another or the wpfadmin command. This action deactivates the partition on the original server and then activates it on the new server. The partition is offline during this period. Most of the offline time is associated with the application's deactivate and activate code processing.
Because DBChecking has only one partition, we can demonstrate moving the only partition there is. As an example, to move partition singleton from xdcell/node1/WPFOG01 to xdcell/node2/WPFOG02 type the following at a command prompt:
#./wpfadmin.sh move --p singleton --d xdcell/node2/WPFOG2The result should look similar to...
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh move --p singleton --d xdcell/node2/WPFOG2
WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager
WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[move, --p, singleton, --d, xdcell/node2/WPFOG2]"
CWPFC0065I: Partition set to singleton
CWPFC0065I: Destination set to xdcell/node2/WPFOG2
CWPFC0054I: Move command submitted successfully for partition singleton from Server xdcell\node1\WPFOG1 to Server xdcell\node2\WPFOG2
If we list the active partitions after the move, the result should look similar to...
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh listActive
WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager
WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[listActive]"
CWPFC0050I: Application DBChecking, Partition singleton: Server xdcell\node2\WPFOG2
Enabling performance monitoring
The partitioning facility includes a performance monitoring facility that provides a command line and graphical visualized snapshot of the current operational statistics of a partitioned application. In general, a partitioned application must run reportTransactionComplete() for this service to provide results.
Performance monitoring is disabled by default because it requires additional system resources to track and publish statistics. In high performance scenarios and when resources are tight, it is a best practice to monitor the statistics in an intermittently versus longer-term, active monitoring.
To enable PMI for the WebSphere Partitioning Facility cluster, the H PMI level is required.
#./wpfadmin.sh enableWPFPMI H --c RedbookClusterWPFOGThis command should be run from the Deployment Manager's bin directory. It is not necessary to stop the cluster prior to enabling PMI. The command's output should look similar to...
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh enableWPFPMI H --c RedbookClusterWPFOG WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[enableWPFPMI, H, --c, RedbookClusterWPFOG]" CWPFC0065I: Cluster set to RedbookClusterWPFOG CWPFC0043I: The PMI module for the Partitioning Facility is enabled for cluster RedbookClusterWPFOG
After it is enabled, we can track the transaction count for a specific bean instance. The following command track the transaction count for the top 5 instances every 10 seconds:
#./wpfadmin.sh subscribeWPFPMI cumulative TransactionCount DBChecking DBCheckingPartition 5 10000 --c RedbookClusterWPFOGThe output should look similar to...
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh subscribeWPFPMI cumulative TransactionCount DBChecking DBCheckingPartition 5 10000 --c RedbookClusterWPFOG
WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager
WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[subscribeWPFPMI, active, TransactionCount, DBChecking, DBCheckingPartition, 5, 10000, --c, RedbookClusterWPFOG]"
CWPFC0065I: Cluster set to RedbookClusterWPFOG
CWPFC0040I: Partitioning Facility PMI has been subscribed with options range=active, type=TransactionCount, application name=DBChecking, ejb name=DBCheckingPartition, partition count=5, interval=10000
CWPFC0041I: Our client id is 1. Use this in future wpfadmin pmi calls.
Monitoring transaction performance statistics
The client id is the reference ID used to monitor this subscription. A new incremental client id will be assigned for each new subscription. As a result, the client id might be different on yours if we have made a previous subscription. At this point, we have the ability to begin active monitoring.
Before monitoring, the client must be run against the application for the transactions to be registered. Otherwise, there will be nothing for the performance monitoring facility to report. The following command is used to report on the transaction count we set up earlier using client id 1 and a refresh interval of 15 seconds:
#./wpfadmin.sh getTransactionCount --id 1 --top 15Because we have not yet run the client after subscription, we should see an output similar to...
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh getTransactionCount --id 1 --top 15
WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager
WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[getTransactionCount, --id, 1, --top, 15]"
CWPFC0065I: Id set to 1
CWPFC0065I: Top interval set to 15PartitionName TransactionCount TotalResponseTime MinimumTime MaximumTime
CWPFC0045I: No statistics are available! Please wait and try again.
Run the client application several times to register transactions with the performance monitoring facility and then re-run the previous monitoring command.
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh getTransactionCount --id 1 --top 15 WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[getTransactionCount, --id, 1, --top, 15]" CWPFC0065I: Id set to 1 CWPFC0065I: Top interval set to 15 PartitionName TransactionCount TotalResponseTime MinimumTime MaximumTime singleton 1 315 315 315 ========================== PartitionName TransactionCount TotalResponseTime MinimumTime MaximumTime singleton 2 453 315 453
This continues tracking as long as the user does not exit with a Control-C in the running window. If a single snap shot is required, rather than a continuous display, we can use the following command:
#./wpfadmin.sh getTransactionCount --id 1The previous subscription uses the cumulative option to collect statistics. Another method is use the active option. When used with a continuous client load, the active option will reflect the number of new transactions over a period of time. We can simulate a continuous load by looping the client application. The launchclient command has a -loop option for looping the client application in a regular set interval. To subscribe the transaction we want to monitor with the active option enter the following command:
#./wpfadmin.sh subscribeWPFPMI active TransactionCount DBChecking DBCheckingPartition 5 10000 --c RedbookClusterWPFOGTo run the client in a loop enter the following command:
#./launchClient.sh /usr/IBM /WebSphere/AppServer/profiles/node1/installedApps/xdcell/DBChecking .ear -CCproviderURL=corbaloc::node1:9812 -loop 10000
Monitoring WebSphere Partitioning Facility partitions using the Administrative Console
Performance statistics can also be monitored from within the Administrative Console. The only limitation is that Microsoft Internet Explorer with the Adobe SVG plug-in must be used.
Ensure the cluster is started, and in a separate window launch the looping launchclient command described above. This will provide a continuous load of transactions for monitoring.
In the Administrative Console:
- Select Runtime Operations | Runtime Map in the console navigation tree to open the runtime map panel.
- For a more aggressive monitoring, change the refresh rate value to 10 and click the Set Refresh Rate button.
- Expand Preferences and:
Set the Layer 1 Type to Application
Set the Layer 2 Type to Partition
Set the Layer 1 Displayed Entity field to DBChecking
Click Apply.
You should see the singleton partition displayed in the runtime map.
The runtime map gives we an active visual perspective. Moving our mouse over the map invokes the hover help feature, which displays the specifics of the partition and performance statistics. The statistics are updated automatically from our runtime configuration. As our environment changes, our map also changes. The update is governed by the refresh rate which is the time in seconds that the runtime map is updated.
Partitioning facility management
This section describes the management capabilities of the partitioning facility and how it is closely associated with the HAManager. An overview of the HAManager is presented below to help we understand the partitioning facility. A more detailed description of the HAManager can be found in chapter 6 of the redbook WAS Network Deployment V6: High availability solutions, SG24-6688.
HAManager
The high availability manager (HAManager) is a new component in WAS V6 and provides the capability to manage highly available groups of resources in a clustered environment. The HAManager is configured using a policy mechanism allowing for precise control of its runtime behavior.
The HAManager manages highly available groups of application servers and partitions and is specifically used for correlating partitions to cluster members. It also manages one or more high availability groups (HA groups). As cluster members are stopped, started, or fail, the HAManager monitors the current state, and based upon a given set of policy attributes, adjusts the state of the partitions as required. Consequently, the HAManager provides the fundamental functionality to manage partitions. The HAManager allows the creation of policies to give the programmer and administrator more control by replacing or augmenting the default policies. The HAManager is a collection of technologies to manage distributed resources. Core group, core group coordinator, and policy are key functions of the HAManager.
Core group
A core group is a set of processes (JVMs) that can be divided up into several high availability groups. In a runtime server environment, each core group functions as an independent unit. A process that is contained within a cell can be a member of one core group only. This process (JVM) can be a Node Agent, an application server, or a Deployment Manager. However, even though the Deployment Manager can belong to one core group only, it is still responsible for configuring all of the application servers within a cell, even if multiple core groups are defined for that cell. The core group configuration is used by the HAManager to establish the members where WPF partitions will be allocated at activation.
WebSphere XD only supports one core group, that is the DefaultCoreGroup.
Core group coordinator
The coordinator is the elected, or default, high availability manager from a runtime server perspective. The coordinator is responsible for tracking all of the members of a core group when members leave, join, or fail. In addition, the coordinator is not a single point of failure. In the event of a failure involving the coordinator, the preferred coordinator, or a default, picks up the HAManager work, including the management of the core group. The default coordinator is sometimes referred to as the active coordinator. Additional coordinators can be used. These serve as backup coordinators and under heavy load additional coordinators are required to spread the workload.
Policy
A policy is used to designate core group members as part of a specific HA group. The coordinator relies on the currently active policy as each HA managed event is detected for each core group member. Even though a policy is defined at the core group level, it does not apply to the core group. A policy is established for a HA group when that group is created.
A policy is basically a set of attributes describing how the HA managed group should behave and specifying a match criteria. Based upon the number of match criteria, the policy will be applied to a set of partitions. The number of matches determines which policy applies. If two policies result in matches with the same number of criteria, HAManager generates an error as it does not know which policy to apply to the HA managed group.
In the case of a cluster scoped partition, the partition is joined on each node in the cluster where the partition application is installed, but active in only one member that will receive the requests.
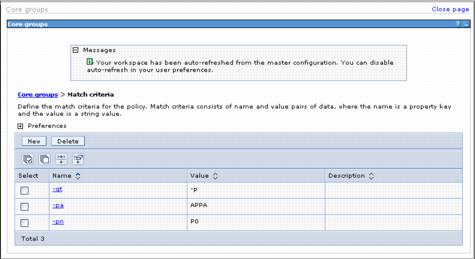
For example, the default policies located in the Deployment Manager's configuration directory coregroup.xml file should look similar to...
<policies xmi:type="coregroup:OneOfNPolicy" xmi:id="OneOfNPolicy_1129228841760" name=" WPF Cluster Scoped Partition Policy" description="Default WPF Cluster Scoped Partition Policy" policyFactory="com.ibm.ws.hamanager.coordinator.policy.impl.OneOfNPolicyFactory" isAlivePeriodSec="-1" quorumEnabled="true" failback="false" preferredOnly="false"> <MatchCriteria xmi:id="MatchCriteria_1129228841812" name="-gt" value="-p" description="Default WPF Match Criterion"/> <MatchCriteria xmi:id="MatchCriteria_1129228841829" name="-ps" value="-c" description="WPF Cluster Scope Match Criterion"/> </policies> <policies xmi:type="coregroup:OneOfNPolicy" xmi:id="OneOfNPolicy_1129228841904" name="WPF Node Scoped Partition Policy" description="Default WPF Node Scoped Partition Policy" policyFactory="com.ibm.ws.hamanager.coordinator.policy.impl.OneOfNPolicyFactory" isAlivePeriodSec="-1" quorumEnabled="false" failback="false" preferredOnly="false"> <MatchCriteria xmi:id="MatchCriteria_1129228841919" name="-gt" value="-p" description="Default WPF MatchCriterion"/> <MatchCriteria xmi:id="MatchCriteria_1129228841931" name="-ps" value="-n" description="WPF Node Scope Match Criterion"/> </policies>
In the two stanzas above, one describes the WPF node scoped partitions policy and the other is the WPF cluster scoped partitions policy. These policies support the default partition types for the partitioning facility. The key attributes to note for this example are the basic properties for each policy (quorumEnabled, isAlivePeriodSec, and so on) and the match criteria.
For the highlighted match criteria, -gt represents the group type, and -p stands for partition. The partition scope attribute -ps differs for each type, for example, the cluster scoped attribute is -c and node scoped is -n. These name and value types are reserved for the partitioning facility. However, the user can extend these for extended policy management. When a partition is created, the partitioning facility provides some default properties that can be used by programmers and administrators to control.
Several different HA groups can use the same policy, but all of the HA groups to which it applies must be part of the same core group. A policy is established for a HA group when that group is created. Here are the available policies for a HA group.
Policy
Description
All active
The service is activated on every available cluster member.
M of N
M group members in the core group are activated. The number represented by M is defined as part of the policy details. The partition runs on at most M of the N available cluster members. If less then M members are currently online, then it runs on all currently running members.
No operation
No group members are activated.
One of N
Only one group member in the core group is activated. That is, exactly one of the possible cluster members that can host the partition will be activated at a time. This is classic HA behavior which keeps the partition running on one server at all times.
Static
The HAManager only activates the service on a specific server. If that server is not available then that service is down.
Thus, each set of partitions can have slightly different policies applied to them. For example, different partition groups can be treated differently for such attributes as preferred and failback server within the same cluster.
The attributes in a policy describe how HAManager should manage a set of partitions that map to a policy via the respective match criteria. The available attributes set are...
Attributes
Description
IsAlivePeriodSec
The number of seconds between the isAlive method call for an active HA managed member.
quorumEnabled
A boolean value describing if the HA group should be managed with quorum detection or not.
failback
A boolean describing when an HA group active member fails and recovers, should the member be moved back to the server that is now recovered.
preferredOnly
Should the HA group active member be started on a specific cluster member, or any available at the time the partition is ready to be activated.
preferredServers
If preferredOnly is enabled, then which servers should HAManager target to active the member when the servers start and become operational.
HAManager quorum attribute
The default partition policy is quorum enabled, which is a policy attribute supported by the HAManager. If there is an odd number of cluster members in the cluster then quorum state is achieved when the number of members that have successfully started is (N/2) + 1. For example, if there are five cluster members, then at least three must be online for any application partitions to be activated in that cluster. Three servers constitute to achieving a quorum state.
If the number of cluster members is an even number then the same general rule applies, even though one member will be given two votes versus each getting one in the case of a cluster with an odd number of members. If there are four members then three of the four must be online. Each cluster member has a vote, and this vote is normally one. However, when the number of possible cluster members is even, then the first cluster member gets two votes. The first cluster member is not the application server that manages to start first and is a member of a cluster. Rather, the first cluster member is determined by a lexically sorted list of the cluster member names. This includes the entire <Cell>\\<Node>\\<member name> name identifier, not only the member name.
In general, quorum is reached when the sum of the votes from the online cluster members equals or exceeds the majority of the possible votes for the cluster. When the current cluster membership achieves quorum, then the HAManager will start activating cluster-scoped partitions in round-robin fashion over the set of online members and each partition is activated only once across the members of the cluster. The activation process normally results in an unbalanced cluster topology. The partitioning facility provides management functions to rebalance the partitions across all available cluster members operational at the time the balance is issued.
A partitioned application will continue running until the hosting cluster loses quorum. If the set number of votes falls to less than the majority then the application is stopped. This situation is uncommon and typically only happens when there is a network partition that causes the cluster machines to split into two independent clusters.
As an example, assume a cluster is created and a core group is defined for that cluster. In the core group, if a particular partition is given a preferred server to be activated, the HAManager will monitor and enforce the appropriate policy for the life cycle of the partition and the cluster member. If the cluster member (a core group member) is brought down for maintenance or simply fails, HAManager will reactivate the partition on another cluster member. Additionally, if the partition in this example were defined to fail back, HAManager would move the partition back to the previously failed cluster member when the cluster member becomes available again.
To ensure cluster reliability, if quorum is lost all remaining cluster members will be terminated. This is to avoid that the cluster handling the workload begins to enter a running state that is not safe or reliable. Administrators must plan for this case, and provision the cluster as required to account for this. Additionally, quorum is an attribute that can be turned on or off.
Highly available partitions
Partitions use a One of N policy with quorum enabled by default, which means partitions can only be activated when the majority of the possible cluster members are online or as considered in the case, in a state of quorum. It is possible to mix and match partition policies differently for each application.
For example, assume our sample Trade application which handles all stock types is to be converted to a partitioned application and would like to treat one of the stocks (S:0) differently due to a higher trade volume characteristics. We can define S:0 to be in its own partition and all the other stocks grouped together in a number of partitions. When the application servers start, all partitions will be activated on the set of servers available at the time quorum is established. With the default policy, there is no control over where the S:0 partition will be activated. However, we can place this partition exclusively on a particular server and have the other partitions balanced evenly across the rest of the available servers by creating a policy using the HAManager policy infrastructure.
This approach guarantees that transactions against stock S:0 will be activated on a preferred server, versus randomly balancing all partitions over all servers. If the partitions were managed as one grouping, the result could be that some servers may have an excessive number of transactions for S:0 in comparison to other stocks. On the other hand, some servers may have a large number of stocks that receive little to none in terms of transaction volume in a single day and are underutilized.
Other examples which utilize the HAManager policy support are to set preferred servers for specific partitions, predefine servers to be used for failover scenarios, define whether a partition should be sent back to the original server once the server is back online. Many other options are available and described in the subsequent sections.
Partition scope
Partitions have two possible scopes: cluster and node scope. The application specifies the scope when it creates the partition's PartitionDefinition. The partition scope influences the HA group properties for the partition at creation time and how the partition's HA group is handled once the cluster starts.
Cluster-scoped partitions
Cluster-scoped partition is the default scope setting. This means the HAManager will apply the policy to all running cluster members. When each member of the cluster creates and joins a partition HA group, only one instance will have the partition endpoint activated. This ensures client requests are routed to a unique cluster member. Cluster-scoped partitions are Internet Inter-ORB Protocol (IIOP) routable and only activate when the cluster reaches quorum.
Node-scoped partitions
This means the HAManager will apply the policy only to the cluster members on a particular node. If a One of N policy is used, then one cluster member per node is activated. If IIOP routing is used, then the requests are spread over the active cluster members on the various nodes.
For example, if a One of N policy matches a node-scoped partition then the partition is activated once on every node with a cluster member started. If there are four nodes with cluster members running, then the partition will be activated once on every one of the four nodes.
Node-scoped partitions do not wait for cluster quorum before activating. Requests to these partition types will be routed based upon a round-robin scheme across members. Thus, for solutions where more than one endpoint can serve and would be beneficial, node-scoped partitions should be used.
Partition layout strategies
As discussed earlier, the partitioning facility allows a J2EE application to declare singletons at application start time as well as dynamically while it is running. These singletons are then assigned by WebSphere to run on exactly one cluster member at a time. If the cluster member running a singleton fails then the singleton is restarted on one of the surviving cluster members. The selected cluster member to host a partition informs the application using a callback mechanism. The HAManager is used to decide on which cluster member to activate a partition and to handle failover and recovery.
Default configuration
The default configuration is to assign the partitions to cluster members in a round-robin fashion. Assume we have a two member cluster that is already running. If an application deployed to that cluster uses the PartitionRuntime.addPartition API to add a new partition, then the HAManager will pick one of the two cluster members (JVMs) to host that partition. The application will receive a callback indicating the partition is being loaded on that JVM. If another partition is added then it will be activated on the lexically next cluster member that is the second cluster member, as a result, one partition per cluster member.
Startup scenario in default configuration
Assume we have an application that declares two partitions on startup, P0 and P1. We then deploy the application to a two server cluster (M1 and M2) and start M1. You should see a message called HMGR218I in M1's SystemOut.log file. This is when the HAManager has accepted M1 into the cluster; a cluster with one member in it currently. The HAManager then discovers two partitions P0 and P1 that are not running on any cluster members. It therefore activates them both on the only choice open to it, M1.
Now we start M2 and eventually HMGR218I appears in its SystemOut.log. The HAManager sees both cluster members are up and running, but the partitions P0 and P1 are already running in M1 so there is nothing that needs to be done. The problem is that this may not be what we want. We may want the partitions balanced.
HA groups and partition naming
Everything that needs to be made highly available in WebSphere ultimately maps to an HA group. Each HA group has a name and the name consists of a set of name/value pairs. Each HA group has a unique name. The name for a partition is made up from the fields shown in below...
Name
Explanation
Default Value
-gt
Group type
-p
-ps
Partition scope
"-c" or "-n"
-pn
Partition name
The application partition name
-pnn
Partition node name
The node name
-pa
Application name
The name of the application
-pc
Application partition class
Application specified value or default value
User
Application specified prop
Application specified value
The majority of the default name/value pairs are self explanatory. This list can be expanded with any set of application specified pairs.
HAManager policy matching algorithm for partitions
The HAManager uses a simple matching algorithm when determining the policy for a particular HA group. A HA group must match one and exactly one policy. A policy in turn can be matched to zero or more HA groups. A policy matches an HA group if all the name/values in the policy match-set are contained in the HA group name. If more than a single policy matches the HA group then the policy that matches the most name/value pairs is chosen. If two or more policies equally match a group then this is an exception condition and the core group coordinator will refuse to activate any members as it cannot determine which policy to use.
How do HA groups for partitions map to policies?
WebSphere XD includes a single default policy for partitions. This is a One of N policy which matches to all HA groups and matches to the following name template:
-gt = -pBasically all partitions match this very generic template and by default they all have a One of N behavior. We can add more specific policies to provide specific behaviors depending on our needs. We now examine group name templates or match sets for various needs:
All partitions within an application
This is the template:
-gt = -p -pa = APPAIf a policy with this match set is added then it will apply to all partitions within the application APPA.
All partitions within a specific application class and application
This is the template:
-gt = -p -pa = APPA
-pc = JMSLISTENERSThis matches all partitions created using the following code snippet:
my_pdef = PartitionManager. createPartitionDefinition(name, ..JMSLISTENERS.., PartitionScope.K_CLUSTER)This will match partitions with any name in the partition classification or group of partitions called JMSLISTENERS. This is handy to manage all such partitions as a single entity with a single policy.
A specific partition which isn't in an application class
This is the template:
-gt = -p -pa = APPA -pn = LISTENER_Q0This will match a partition created as follows:
my_pdef = PartitionManager. createPartitionDefinition(..LISTENER_Q0..)
A specific partition which is in an application class
This is the template:
-gt = -p -pa = APPA -pn = LISTENER_Q0 -pc = JMSLISTENERSThis overrides the policy for JMSLISTENERS earlier. Note that if we had defined a partition class policy then it would match three pairs for our HA groups as does the partition specific policy. This would result in an error. Hence the need for the extra name/value pair in the matchset for this case, it now matches four and overrides the three match class specific case.
Static partition scenario
Using our example with the two partitions P0 and P1 and two cluster members M1 and M2, we create two polices.
Type
Static
Matchset
-gt=-p, -pa=APPA,-pn=P0
Server
M1
Static policy for P0
Type
Static
Matchset
-gt=-p, -pa=APPA,-pn=P1
Server
M2
Static policy for P1
This results in a balanced system but no failover. P0 is basically statically bound to M1 and M1 alone. This is what a static policy does. If M1 is not running then P0 is not activated either.
Preferred server with failback scenario
To illustrate this scenario we need to create two One of N policies.
Type
One of N
Matchset
-gt=-p, -pa=APPA,-pn=P0
Failback
True
Server
M1, M2
One of N policy for P0
Type
One of N
Matchset
-gt=-p, -pa=APPA,-pn=P1
Failback
True
Server
M2, M1
One of N policy for P1
If we were to start M1 first, both partitions would activate on M1. If we then start M2, P0 will stay running on M1 because of the two choices at this point (M1 or M2). M1 is more preferred as it is specified first in the server list. But P1 will move to M2 because M2 is more preferred than M1. This only occurs because failback is set to true. If failback was false then P1 would continue running on M1.
Disable a partition from running on a single JVM
If an administrator wants to exclude a cluster member from hosting a particular active partition, the wpfadmin disablepartition command is available to achieve this. This is only temporary and if the cluster member is restarted then it can once again host the active partition. If the administrator wants to permanently exclude a partition from a server then a policy such as the one shown here should be used.
Suppose we have four cluster members: M1, M2, M3, and M4. We can define the policy shown below to prevent the partition P0 running on M3:
Type
One of N
Matchset
-gt=-p, -pa=APPA,-pn=P0
Preferred Only
True
Server
M1, M2, M4
Policy for disabling a partition on a specific server
This only allows the partition P0 to activate on M1, M2 or M4. The list of servers can be updated and the updated list will take effect immediately. If the partition is active on a server that is now excluded, then it will be deactivated and the partition will reactivate on a legal server.
Disable a partition from being activated at all
This must also be done using a policy. A policy similar to the one illustrated in the table below would disable P0 from activating on any cluster member:
Type One of N Matchset -gt=-p, -pa=APPA,-pn=P0 Preferred Only True Server NodeAgent1 Policy for disabling a partition permanently
This tells the HAManager that the JVM named NodeAgent1 (the Node Agent JVM for M1) is the only legal JVM to run the partition. However, as this JVM is not a member of the application cluster, the HAManager will never be able to activate this and this effectively disables the partition. The policy can be removed or updated to enable the partition. Once a policy such as this is added then if the partition is currently active, it will be deactivated.
Disable all partitions for an application
Again, this can only be done using a policy. A policy such as the one illustrated below would disable all partitions for an application:
Type One of N Matchset -gt=-p, -pa=APPA Preferred Only True Server NodeAgentM1 Policy for disabling all partitions permanently
This will only work if this policy is the most specific policy matching the partitions for the application. For example, if the static policy was present and the other partitions used the default policies then the effect of both policies would be that P0 is activated on M2 but the other partitions would be disabled. If the policy for P0 was removed then it too would be disabled immediately.
Managing policies
Policies play an important role in a partitioned application, both for programming and effective administration. The goal of this section is not to give a detailed explanation of policies which has already been presented in the previous section, but to show we how to create some of the example policies previously explained.
The Administrative Console has a set of panels for modifying the policies of HA groups. Any changes to a policy will be effective immediately and do not require a restart of the cluster or application servers.
From the Administrative Console do the following to modify the policies for the DefaultCoreGroup:
- Expand Servers from the navigation tree.
- Select Core groups | Core group settings to bring up the Core groups pane.
- Click DefaultCoreGroup.
- Select Policies from the Additional Properties. The Policies pane is displayed.
Here we can see the default policies for the DefaultCoreGroup in WebSphere XD. There are two partition facility specific policies for cluster and node scoped partitions. Never change these default policies. Always add more specific policies instead.
We now add the two policies explained in Preferred server with failback scenario that demonstrate a fail back scenario.
- Click New.
- Select One of N policy from the Policies menu.
- Click Next to go to the policy configuration pane. Check the Fail back and Preferred servers only boxes and specify a name for the policy. Click Apply.
- Click Match criteria to add new Name/Value pairs for our policy.
- Click New. Then specify the first of three Name/Value pairs:
Name: -gt and Value: -pClick OK. Repeat this step to add the other two Name/Value pairs as follows:
Name: -pa and Value: APPA
Name: -pn and Value P0Our entries should then look like...
With these settings, we have defined the group type, partition name and application name settings. Next we need to specify the preferred servers list:
- Click the Policies link at the top of the panel.
- Select the APPA P0 policy.
- We already have a cluster with two members (WPFOG1 and WPFOG2) on which we would like the partition to run. When the new policy is visible, click the Preferred servers link. Select the most preferred server, node01/WPFOG1 in our case and click Add. Then select a second server, node02/WPFOG2 in our example, and click Add. The screen should now look similar to...
- Click OK. We have defined a policy for the first partition.
- Now repeat this process starting with step 5 to create an APPA policy for P1 with these differences:
- -pn is now set for P1.
- The preferred server list is set to WPFOG2 as the first preferred server and WPFOG1 as the second preferred server.
When we have completed this second policy, our policy list should look similar to...
- Save our changes. If our application is already running, then the new policies will take effect immediately.
Management script (wpfadmin)
The wpfadmin script is a python script that allows the user to perform several administrative operations on a cluster. This script can be used to create our own customized automated command script.
The script provides many commands to assist in managing a WPF environment. These commands ease the burden of setting trace specifications, managing active partition members, managing polices, and many other tasks.
The script calls a HAManager MBean (JMXCoordinator) which then calls directly to the HAManager runtime support to perform the operations. Below is a list of the most common operations supported by the wpfadmin script.
For the purposes of this section, where applicable, we use the DBChecking application to explain any new operation.
In the examples below, wpfadmin is executed to demonstrate sample invocations. On Windows platforms, the wpfadmin.bat application can be used and referenced on the command line as wpfadmin, while on UNIX platforms, the wpfadmin.sh script is used. The command functions are identical across all supported platforms unless documented otherwise.
listActive
Displays the application servers hosting active partitions. This command can be scoped to only show information for a particular application, partition, or classification.
Available options:
--o <number of partitions>The number of partitions that are printed out. If --o is not specified, it defaults to 50 partitions.
--a <application name>Prints out partition information for the given application.
--p <partition name>Prints out partition information for the given partition.
--class <classification name>Prints out partition information for the given classification.
Usage: ./wpfadmin listActive
list
The list command Lists the partitions and the status of the member servers. This command can be scoped to only show information for a particular application, partition, or classification.
Available options:
--o <number of partitions>The number of partitions that are printed. The default of 50 partitions is used if --o is not specified.
--a <application name>Prints partition information for the given application.
--p <partition name>Prints partition information for the given partition.
--class <classification name>Prints partition information for the given classification.
Usage: ./wpfadmin list
move
Moves a partition to another server.
Available options:
--p <partition name>The name of the partition to move.
--d <server>Destination server for the partition to move to, in the form cell/node/server.
Usage: ./wpfadmin move -p PartitionB -d CellA/NodeA/Server1
The partition will receive an outage for this command. The application programmers should have implemented the partitionLoadEvent() and partitionUnloadEvent() as described in the programming section of the InfoCenter.
balance
Balances partitions across the set of active servers. Also, if the user specifies the -id option, only the partitions for which PMI statistics are being gathered relative to the id specified will be balanced.
Available options:
--o <number of partitions>The number of partitions to balance. If --o is not specified, it defaults to 50 partitions.
--a <application name>Balance partitions of the given application.
--class <classification name>Balance partitions for the given classification.
--id <PMI id>Balance partitions for the given PMI id.
Usage: ./wpfadmin balance
Similar to the move operation, the partition will receive an outage for this command. The application programmers should have implemented the partitionLoadEvent() and partitionUnloadEvent() as described in the programming section of the InfoCenter.
disablePartition
Disables a partition. Depending on how policies are configured, the partition will either be enabled on another server, or will just be disabled.
Available options:
--p <partition name>The name of the partition to disable...
./wpfadmin disablePartition --p partition_nameAn example of disablePartition is displayed below...
/usr/IBM /WebSphere/AppServer/bin #./wpfadmin.sh disablePartition --p singleton WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[disablePartition, --p, singleton]" CWPFC0065I: Partition set to singleton CWPFC0052I: Partition singleton has been disabled. /usr/IBM /WebSphere/AppServer/bin #
enablePartition
This command enables a partition.
Available options are:
--p <partition name>The name of the partition to enable.
Usage:
./wpfadmin enablePartition --p partition nameAn example of enablePartition is displayed below...
Example 8-14 Using enablePartition
/usr/IBM /WebSphere/AppServer/bin #./wpfadmin.sh enablePartition --p singleton WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[enablePartition, --p, singleton]" CWPFC0065I: Partition set to singleton CWPFC0082I: Partition singleton has been enabled. /usr/IBM /WebSphere/AppServer/bin #
enableWPFPMI
Enables the WebSphere Partitioning Facility PMI module for all active servers.
Available options:
<level>Level of PMI statistics that will be gathered for the wpfModule. Normally it should be set to H.
--c <cluster name>All servers in the given cluster will have PMI enabled.
Usage: ./wpfadmin enableWPFPMI H --c cluster_name
subscribeWPFPMI
Subscribes the asynchronous PMI module for WebSphere Partitioning Facility. Here is an example of this command:
./wpfadmin subscribeWPFPMI [active|cumulative] [TransactionCount|ResponseTime] application_name ejb_name partition_count aggregator_interval --c cluster_name.The elements of the command are defined in the following list:
If active is passed, the data the user sees will be reset every time the aggregator interval runs its course. If cumulative is passed, the data will not be reset. If TransactionCount is passed, the latest aggregated data for each of the partitions regarding the number of transactions processed will be returned. If ResponseTime is passed, the latest aggregated data for each of the partitions regarding the minimum, maximum, and average response time will be returned.
These two options allow the user to look at what partitions are currently processing the most transactions (or which partitions have the highest response times), as well as a history of the partitions that have processed the most transactions up to this time (or history of the partitions that have had the highest response times).
<application_name> and <ejb_name> specify the application and EJB for which to keep PMI statistics. <partition_count> specifies for how many partitions PMI statistics should be kept. For example, if there are 10,000 partitions in the cluster, and the partition count is set to 20, only the top 20 partitions in terms of transaction count or response times will be stored. <aggregator_interval> specifies the interval in seconds the aggregator waits between aggregations. The default value is 15000 milliseconds. <cluster_name> specifies the cluster where the application is running. If the PMI specification level for wpfModule is not set to H for any server in this cluster, subscribeWPFPMI will fail. The subscribeWPFPMI command returns an id integer. We then use this id in subsequent commands when getting statistics and updating subscribe options.
All of these options can be set separately as well.
disableWPFPMI
Disables the WebSphere Partitioning Facility PMI module.
Available options:
--c <cluster name>PMI will be disabled for all servers in the given cluster.
Usage:
./wpfadmin disableWPFPMI -c <cluster name>An example of disableWPFPMI is displayed below...
Example 8-15 Using disableWPFPMI
/usr/IBM /WebSphere/AppServer/bin #./wpfadmin.sh disableWPFPMI --c RedbookClusterWPFOG WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[disableWPFPMI, --c, RedbookClusterWPFOG]" CWPFC0065I: Cluster set to RedbookClusterWPFOG CWPFC0064I: The wpfModule of PMI is disabled for cluster RedbookClusterWPFOG
listPolicies
This command lists the name of all policies in the core group.
Usage: ./wpfadmin listPolicies
Here is an example of listPolicies...
/usr/IBM /WebSphere/AppServer/bin #./wpfadmin.sh listPolicies WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[listPolicies]" Policies in DefaultCoreGroup Default SIBus Policy Clustered TM Policy WPF Cluster Scoped Partition Policy WPF Node Scoped Partition Policy WPF PMI Aggregator Policy Policy for ME0 Policy for ME1 APPA P0 policy APPA P1 policy
Performance monitoring
Performance monitoring is the activity in which we collect and analyze data about the performance of our applications and the environment. The product collects data on the run time and applications through the Performance Monitoring Infrastructure (PMI). This infrastructure is compatible with and extends the JSR-077 specification.
In WebSphere XD, we create a PMI module for each partition active in the cluster. We also provide features to query the most active partitions in a user specified period.
Enabling WebSphere Partioning Facility PMI
Before gathering WebSphere Partioning Facility PMI data, we have to enable WebSphere Partioning Facility PMI as WebSphere Partioning Facility PMI data is recorded in the system only when WPF PMI is enabled. WPF PMI can be enabled in several ways: Using the wpfadmin utility command, the Administrative Console, or the wsadmin tool.
This support must be enabled before the cluster is started.
Enabling WPFPMI using the wpfadmin command
We can call wpfadmin enableWPFPMI level --c cluster_name to enable WPF PMI in a particular cluster. This is the simplest and also the recommended way to enable WPF PMI.
To enable WPFPMI using wpfadmin :
- Change the current directory to Deployment_Manager_Home /bin.
- Execute:
wpfadmin enableWPFPMI H --c cluster_nameYou should see the output below...
/usr/IBM /WebSphere/AppServer/bin # ./wpfadmin.sh enableWPFPMI H --c RedbookClusterWPFOG WASX7209I: Connected to process "dmgr" on node dmgr1 using SOAP connector; The type of process is: DeploymentManager WASX7303I: The following options are passed to the scripting environment and are available as argument that is stored in the argv variable: "[enableWPFPMI, H, --c, RedbookClusterWPFOG]" CWPFC0065I: Cluster set to RedbookClusterWPFOG CWPFC0043I: The PMI module for the Partitioning Facility is enabled for cluster RedbookClusterWPFOG
Enabling WPFPMI using the Administrative Console
Alternatively, we can enable WebSphere Partitioning Facility PMI from the Administrative Console. From the Administrative Console, follow these steps to enable WebSphere Partitioning Facility PMI for a particular server:
- Click Servers | Application servers in the console navigation tree.
- Select a server. For example WPFOG1 in our scenario.
- In WebSphere V6.x, PMI is enabled by default. If this has been disabled for our environment, we need to re-enable PMI. To verify that PMI is enabled for our server, click the Performance Monitoring Infrastructure (PMI) link. Verify the Enable Performance Monitoring Infrastructure (PMI) box on the Configuration tab is checked. If not, we need to check this box and restart our server or servers if there is more than one.
- Select the Custom PMI level.
- Click the Custom link to go the Custom monitoring level settings pane.
On the left is a navigation tree for all the components within the server. We can selectively choose the component we want to monitor.
When this is done on the Configuration tab, settings will apply once the server is restarted. When on the Runtime Tab, settings apply immediately.
- On the Configuration tab, click Partitioning Facility in the navigation tree. This brings up the PMI metrics that we can collect.
- Select the counters we would like to enable and click the Enable button. Notice that the status next to the counters change from Disabled to Enabled.
- Select the Runtime tab.
- Click Partitioning Facility in the navigation tree. You should see the DBChecking partition singleton. We can only see this on the Runtime Tab and not on the Configuration Tab. We can enable and disable the metrics for the respective partition on this tab also. Changes made in the Runtime Tab take effect immediately.
The changes we made on the Configuration Tab will not take affect until we restart the application server. If we must enable PMI for other servers, we must repeat this process for each server. We can also use JMX MBean or wsadmin tool to enable the WPF PMI. This is not different from enabling other PMI modules. For more details about PMI, refer to the WAS InfoCenter or to Chapter 14., "Server-side performance and analysis tools" of the IBM WebSphere V6 Scalability and Performance Handbook,> SG24-6392
WebSphere Partitioning Facility PMI path
There is one WebSphere Partitioning Facility PMI module for each partition. The partition PMI is grouped by the application name and the EJB name. So if users want to query the PMI data for Partition p1 in Session EJB session1 of Application app1, the PMI path is wpfModule,app1#session1,p1. Using this PMI path, users can directly query the PMI data for a specific partition using wsadmin or JMX MBean just like we would normally do in the application server.
WebSphere Partitioning Facility PMI data aggregation
Since partitions are activated in different application servers, PMI data for all partitions is probably spread over different application servers in a cluster. Most likely, users are interested in the N most active partitions in the whole cluster. WebSphere Partitioning Facility provides a PMI aggregation and sorting feature to satisfy this requirement.
WebSphere Partitioning Facility elects one server as the PMI aggregator, which aggregates the partition statistics data from all servers. The PMI aggregator is an HA group with One of N policy. The policy name is called WPF PMI Aggregator Policy. Users can customize the policy using the wpfadmin tool or the Administrative Console. At any time, there is only one PMI aggregator active in the core group. This aggregator is responsible for aggregating the statistics for all the partitioned applications.
The best practice is to let this PMI aggregator run on a separate server from those housing partitions so it will not slow down business execution. Each application server is responsible for publishing all of its partition PMI data when PMI is turned on. The aggregator will run at a user specified interval, thus cutting down the volume of statistics the user will be shown. The PMI aggregator performs the following tasks:
- Aggregate the statistics from different servers for each partition. Since partitions can be moved from one server to another, PMI data for a partition can be spread over different application servers. The PMI aggregator must gather all the PMI data for a partition from all servers.
- Sort the PMI statistics based on what users want. For example, if users are interested in the most active (biggest number of transaction counts) 50 partitions over last 15 seconds. The PMI aggregator will calculate the PMI statistics from the last 15 seconds and sort them based on the transaction count.
- Publish the sorted PMI statistics results.
A user can specify the statistics interests when subscribing the WebSphere Partitioning Facility PMI statistics. These interests include application name and session EJB name, statistics type, statistics range, partition count, and aggregation interval. We can also change these interests after subscribing them.
WebSphere Partitioning Facility PMI statistics subscription
If we are interested in the PMI statistics of a particular partition or a server, we do not need to subscribe the WebSphere Partitioning Facility PMI statistics. We can directly retrieve it using the wsadmin tool or the JMX MBean.
If we are interested in the aggregated or sorted PMI statistics, then we need to subscribe the WebSphere Partitioning Facility PMI statistics using a wpfadmin command or the WebSphere Partitioning Facility JMX MBean. Since we have already introduced statistics subscription in our scenario.
WPF programming
This section gives an overview of the WebSphere Partitioning Facility programming environment and how to enable a programmer, who is already familiar with EJB development to create partitioned applications. The developer should have a good understanding of the HAManager policies and how the administrator may manage a WPF environment. Have programmers review the earlier sections of this chapter to understand the WPF capabilities. Programmers should also review the partitioning examples shipped with the product. These examples include the source code and can be imported into IBM Rational Application Developer V6.
WebSphere Partitioning Facility requires the use of one PSSB EJB and optionally allows us to use other session EJBs as partition routable session EJBs (PRSBs) or non-routable facade session beans to PSSB beans.
The partitioning facility strives to offer the promise of high transaction rate computing, but also allows the developer to continue using the existing J2EE programming model. Other than adding WPF framework related APIs, the developer's entity bean implementation should be fundamentally the same as with any other J2EE application and can use the same toolset.
When the WPF framework APIs are used, and the partitioned stateless session bean implements the WebSphere Partitioning Facility framework APIs, the bean will take on a new level of function and have enhanced management functions available to the administrator.
Partition stateless session bean (PSSB)
A partitioned stateless session bean (PSSB) is a stateless session bean that implements the PartitionHandlerLocal interface, and utilizes the PartitionManager to create partitions from the partitioning facility framework. The runtime characteristics are the same as for normal stateless session bean from a runtime perspective.
The special features of this bean type include the following:
- While the application starts in the enterprise beans container, the bean is analyzed, and if this bean is a PSSB, the PartitionHandlerLocal interface methods are called. The interface implementation methods can use the PartitionManager API to submit requests to the HAManager's core group coordinator to create and activate partitions based upon the current policy.
- During the activation of methods from the client to the server implementation of the PSSB, each client method invocation is intercepted and processed to determine which partition this method should be driven against on the server infrastructure. For example, assume a PSSB named TestBean is being demonstrated, and this bean has a remote interface method called ping(String partition). When the client executes the TestBean.ping(partition) method, the TestBean_PartitionKey.ping(partition) (a class the programmer will create) processes all the method attributes and returns a single string to advise the WLM subsystem which partition endpoint the method should be directed towards.
- The PSSB has several methods to handle the state changes that the partition instances might encounter during normal activities. For example, there is a PartitionLoadEvent(String) and PartitionUnLoadEvent(String) method that will be executed if the administrator uses a JMX or wpfadmin command to move a partition endpoint from a server to another server. In this case, if a Partition P001 is associated with application server appsvr1, and a user executes a wpfadmin move operation that changes the P001 partition from appsvr1 to appsvrN in the cluster, these bean callback methods are invoked. The PSSB on appsvr1 would receive a deactivate callback from the HAManager, and in turn the partitioning facility's run time would call the PartitionUnLoadEvent(String) method. After this method successfully completes, the HAManager on appsvrN drives an activation related callback method, and the partitioning facility's run time runs a PartitionLoadEvent(String) on the PSSB.
In summary, a PSSB is a typical session bean that implements and calls methods from the partitioning facility's framework. These methods are similar in many ways to existing EJB callback method handling but have functions that are related to partitioning rather than normal EJB callback methods.
PSSB <Bean>_PartitionKey routing class
The programmer implementing WPF must implement a <Bean>_ParititionKey class to direct where the method request should be routed within the cluster. The endpoint will be a partition, and is described using a string. For example, in the WebSphere Partitioning Facility samples, the following classes with the WPFKeyBasedPartition_PartitionKey are implemented and appear similar to the example below...
Example 8-18 WPFKeyBasedPartition_PartitionKey
package com.ibm.websphere.wpf.ejb; /** * PartitionKey for Partitioned Stateless Session Bean WPFKeyBasedPartition */ public class WPFKeyBasedPartition_PartitionKey { /** * return the partition string as the partition key * @param partition * @return */ public static String buy(String partition) { return partition; } }
This sample is taken from the WPFFacadePartitionSample PSSB. The bean has only a single static remote method, buy(String) which has the partition destination passed into it. The user will receive all method argument passed to the signature, and can process them as required to determine which appropriate partition endpoint cluster member should host the work. All methods in the remote interface of the PSSB should be implemented.
Updating the PSSB bean generated stub
The wpfstubutil is a utility that regenerates the stub, and inserts the appropriate interfaces to enable the <Bean>_PartitionKey class to be called for each route method execution. This tool should be called each time after the EJB is deployed. The deployment process will result in the file being rewritten without these modifications.
When installing a J2EE application, the administrator can choose to deploy EJBs during the installation. If the EJBs are already deployed, they will be re-deployed if the administrator chooses so. For a partitioned J2EE application, re-deploying the EJBs will reset the generated stub and the WPF framework required changes at run time. Therefore, the administrator should never deploy the EJBs when installing a partitioned J2EE application.
Partition routable session bean (PRSB)
A partition routable session bean (PRSB) is a stateless session bean packaged in the same EJB module (jar) with the PSSB, but does not implement the required PSSB interfaces. The PSSB must implement the interfaces as defined above.
When using PRSBs, the PRSB would implement the business methods and the PSSB would not specify them. There can be more than one PRSB implemented in the jar. This is useful if the application has several sets of partitions for multiple purposes (the partition sets must be named uniquely) and multiple session beans implementing separate pieces of a given application.
The advantage is that only the business method interfaces need to be present in the PRSB versus all the plumbing. For example, the APIs supporting the WPF framework like getPartitions, partitionUnloadEvent(), etc. Since the PSSB bean is collocated, the routing will be based upon the PSSB, but does enable the application writer to avoid using the PSSB implementation directly to make the code more readable. All administration functions however utilize the PSSB bean name, this is just an abstraction.
As a reminder, the PSSB partitions for that partitioned application are associated with the PSSB. For example, the -pn group member property must be the name of the PSSB bean, versus the PRSB. However, this should not cause a problem.
The programmer must use the wpfstubutil on the PRSB just as they would with the PSSB if remote methods are to be routable to the correct partition on the server.
Facade interface for a partitioned stateless session bean
A PSSB and PRSB can directly provide an interface for remote method invocations to a remote server infrastructure (or locally as well if within the same JVM). However, often programmers would like to have a single facade to these sorts of WPF framework bean types, and the server implementation would execute the PSSB and PRSB bean functionality. This is not only for EJB programmers, but also for those implementing servlets, for example. To implement this, WebSphere XD provides a simple example, the WPFFacadePartitionSample.
This sample caches the remote home of an example PSSB bean, and provides a single, non-routable method implementation that executes the PSSB method on the server JVM. The source code is included in the WPFFacadePartitionSample.ear.
The advantage of this approach is that the client uses only a facade interface, and the PSSB/PRSB client routing portion is executed in the server infrastructure. Thus, the general routing functionality will be faster as the client routing state information does not have to be downloaded and cached in the client JVM making the request.
For example, the WPFKeyBasedPartitionSample.ear sample client (WPFKeyBasedPartitionClient.java) uses JNDI, directly instantiates the PSSB home instance, and creates an instance from it. Each remote method invocation on the instance requires the client JVM to acquire routing information, download the client JVM, and then cache it. The download step can add overhead to the client implementation in terms of performance (the routing data is cached and stored in memory for both cases so there is not a memory footprint savings). For the case where a user solution has thousands of partitions and many clients in separate client JVMs, bottlenecks can arise when transferring this much information which can be avoided by using this approach.
In summary, both Facade and non-Facade approaches are supported and useful in certain scenarios.
PSSB local interfaces
When implementing a PSSB, it must be a stateless bean and the interfaces listed below must be used:
Interface Ejb-jar description Interface Local Home local-home com.ibm.websphere.wpf.Partition-HandlerLocalHome Local local com.ibm.websphere.wpf.Partition-HandlerLocal As an example, the ejb-jar.xml for WPFKeyBasedPartition would look similar to...
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE ejb-jar PUBLIC "-//Sun Microsystems, Inc.//DTD Enterprise JavaBeans 2.0//EN" "http://java.sun.com/dtd/ejb-jar_2_0.dtd"> <ejb-jar id="ejb-jar_ID"> <display-name>WPFKeyBasedPartitionEJB</display-name> <enterprise-beans> <session id="WPFKeyBasedPartition"> <ejb-name>WPFKeyBasedPartition</ejb-name> <home>com.ibm.websphere.wpf.ejb.WPFKeyBasedPartitionHome</home> <remote>com.ibm.websphere.wpf.ejb.WPFKeyBasedPartition</remote> <local-home>com.ibm.websphere.wpf.PartitionHandlerLocalHome</local-home> <local>com.ibm.websphere.wpf.PartitionHandlerLocal</local> <ejb-class>com.ibm.websphere.wpf.ejb.WPFKeyBasedPartitionBean</ejb-class> <session-type>Stateless</session-type> <transaction-type>Container</transaction-type> <env-entry> <description>The number of partitions this session bean will create</description> <env-entry-name>NumberOfPartitions</env-entry-name> <env-entry-type>java.lang.Integer</env-entry-type> <env-entry-value>10</env-entry-value> </env-entry> </session> </enterprise-beans> </ejb-jar>
Partition router object (<EJBName>_PartitionKey class)
The application programmer is responsible for creating a partition router that acts as a callback for WPF. WPF uses this callback to determine the target partition for requests. The class, which is a plain old java object (POJO), must follow these rules:
- It must reside in the same package as the EJB it supports.
- The class name must be the same as the EJB and have the string _PartitionKey appended to the name.
- There must be a static method for each remote method on the EJB. These methods should match the signature of each method on the EJB but should always return a string representing the EJB's partition name. WPF calls these methods when a remote method is called on the EJB.
- The method should not throw any checked exceptions.
- The customer must run wpfstubutil on the deployed ear with the partition router object to WPF enable for partition routing.
Partition names
The programmer must ensure that partition names are unique, this is especially important when using cluster scoped partition names.
Cluster scoped partition names
Cluster scoped partition names must be unique within the cluster they are hosted in. For example, if a partitioned application creates a partition named singleton, another application in the same cluster cannot create another partition with the same name.
One way to address this, is to use the PartitionManager.getApplicationName() interface, which can preappend the deployed application name to the partition name. For example, assume the administrator deployed the application with DBChecking, the createPartitionDefinition() API could preappend DBChecking to singleton, and create a partition named DBChecking_singleton. This should be used carefully, specifically by not using long strings.
Node scoped partition names
Node scoped partition names within the same application will be the same for each application on each logical node, however, node scoped partition names across different partitioned applications also need to be unique.
Designing our environment for partitioning facility
Plan how a cluster operates in normal conditions and under failure conditions in high workload environments. This section serves as a reminder to administrators and programmers to avoid common scenarios that degrade cluster performance. Each application solution is different, but these guidelines should provide some general advice to ensure our application can achieve and sustain a high performance implementation.
Scalability considerations
Keep an eye on virtual memory paging. The HAManager monitors cluster wide resources and burdens the system with a certain amout of load. If cluster members are paging such that the HAManager functionality cannot operate effectively, HA managed events can begin to account for perceived cluster member anomalies. Application server load should be low enough to handle spikes at times when challenges arise.
Partition design
The number of partitions in a specific solution should be managed carefully. When possible, fewer partitions are generally simpler and more efficient. Each partition takes system resources to implement within the workload management function, additional administrator effort from a system management standpoint, and a reduction in cluster performance when tracking from a performance monitoring perspective.
As a solution requires more partitions, each of these begins to scale and requires either additional resources and additional performance to maintain. Some solutions are complicated and might need larger number of partitions, or even creating two or three different types of partitions to be more efficient. Possibly, we could dynamically create partitions as they are needed and remove them when not required.
From an administrative standpoint, often one of the more costly long-term aspects of an implementation, managing several thousand partitions and the load placed against them in the cluster, is more challenging when compared to a solution requiring the management of hundreds of partitions. However, several solutions might require some thousands of partitions, and if so, the needed computing resources, developers, and administrative resources will be more extensive.
Internally to IBM, the partitioning facility has been tested with 10,000 partitions under load across several machines successfully. A key concern found during those tests was that the number of active core group coordinators must be at least four. Additionally, using HAManager policies to set these coordinators to specific physical machines in the cluster and setting preferred servers for the partitions to avoid these machines (or even application servers if we have a reduced number of machines) proved to be beneficial.
In addition, when running large partition sets we might need to increase the JVM heap sizes for the Deployment Manager and any application servers that we assign as active coordinators. This approach ensures that when performance spikes occur and failure conditions arise, the operational integrity of the cluster is not compromised.
As a general rule, applications should use as few partitions possible. WebSphere Partitioning Facility can scale to a very large number of partitions. However, more partitions equates to more memory and additional management overhead.
The JVMs hosting the HAManager coordinators must have adequate memory to manage their partitions. It is possible to tell the HAManager to use more than one coordinator to manage its partitions. If the applications in a core group use many partitions (>1,000), then the HAManager should be configured to use more coordinators. The actual number that a single coordinator can manage depends on the amount of available memory in the JVM and the number of partitions/coordinator. Partitions are uniformly distributed over the available coordinator JVMs using a hash scheme.
Policies design
The number of policies defined in the default core group of the HAManager has an affect on performance. The default number of WebSphere Partitioning Facility policies is two cluster and node scoped policies. Users can create an enumerable number of more unique policies that meet their requirements. However, keep in mind, when HAManager attempts to apply the policies it must search through all policies available and determine which one best applies to a specific HA group.
In general, the suggested approach to policies is to use what we need. For example, for the example used in a unique policy was created per partition to control the startup of the application to a given application server in the cluster. If the application had 10,0000 partitions, that would require 10,000 policies. This is obviously not the approach a programmer and administrator should take.
Fewer policies can be used when using additional member properties. One of the createPartitionDefinition() API signatures can have a map of additional attributes provided. These properties could help reduce the number of policies. For example, if we create a new attribute called startOn, and the value could be a string that represents server# where # is a number representing one of the cluster members. The policy could then specify the default already provided for the cluster scoped policy (-gt=-p, -ps=-c), but also (startOn=server4). This would provide three match criteria, and enable # of policies versus 10,000 partitions. For example, if there were 30 servers to start the partitions on, there could be 30 policies, each with a third match set criteria and the preferred server to be server4.
Cluster member memory usage for active partitions
The route table for a partition using a One of N policy consumes about 4 KB of memory on the cluster member on which it is active. Cluster members that are not activated for a partition do not have such a route table. The HAManager coordinators also have a copy of this route table. Therefore, if a cluster member has Y active partitions then the cluster member needs Y * 4 KB of memory for the route tables. And, if there are N partitions for the application, then the coordinator needs N * 4 KB of memory.
For example, assume we have an application that has 20,000 partitions. There are ten machines - Node1 to Node10. These machines have 4 GB of memory and have two CPUs. Each machine hosts two cluster members and a Node Agent. Assuming the partitions are spread evenly among the cluster members then each machine has 2000 active partitions, 1000 per cluster member. Thus, each cluster member uses about 4 MB (1000 * 4 KB) of memory for the route tables.
A single coordinator would require about 20000 * 4 KB or roughly 80 MB of memory. However, the coordinator function can be spread across multiple servers. An example configuration for the HAManager might be:
- Number of coordinators = 4 (All references to 4 below mean the value of this setting)
- Preferred Servers = NodeA_NodeAgent, NodeB_NodeAgent, NodeC_NodeAgent, NodeD_NodeAgent
Based upon this configuration, the HAManager will run up to four coordinators in the cell. If there are less than 4 JVMs running in the cell, then the HAManager will use all running JVMs for the coordinator function. The management of route tables will be uniformly distributed using a hashing algorithm among the set of available coordinators (preferred servers above). The HAManager normally uses the lexically lowest servers as coordinators. It simply sorts the JVMs using the server name (cell/node/serverName) and picks the lower M for the coordinator function where M is the number of desired coordinators from the cell configuration.
Based upon the current example, each coordinator needs 20 MB of memory when all four coordinators are running (80 MB / 4 coordinators). The preferred coordinator list lets we specify which JVMs we would like to use as coordinators. The coordinator function is fault tolerant. Therefore, if a JVM currently hosting a coordinator fails, then another JVM will replace it. In the case where there are less than four JVMs available, the coordinator tasks will be redistributed equally over the survivors.
If all machines were running and then NodeB crashed (and thus NodeB_NodeAgent is no longer available), the coordinator would continue to run on four JVMs, the three remaining preferred servers and the lexically lowest of the rest of the JVMs in the cell, thus keeping the number at four.
The JVMs on the machines that are coordinator candidates, that is the preferred servers, should have their heap sizes configured to accommodate the possible coordinator function. We can have more preferred servers than coordinators. The HAManager will then simply choose the four most preferred servers that are currently running.
Defining more than one core group coordinator
We recommend the use of more than one coordinator for a large number of partitions (a thousand or more) to reduce partition activation time and to distribute the memory cost associated with the coordinator function.
As we have seen before, the coordinator manages the route tables of all the partitions that it is designated to host. Let us assume that there is a single coordinator for 20,000 partitions. When the set of running JVMs changes, the single coordinator needs to evaluate the policy for all 20,000 partitions. It will then send activation/deactivation messages to the surviving set of JVMs in the cell depending on the policy, which with a single coordinator could take an inordinate amount of time. More coordinators allow this work to be performed by multiple machines in parallel and thus improve the cell's reaction time in the event of partition failures.
Also 20,000 partitions can translate to about 80 MB of memory for a single coordinator server process. Garbage collection (GC) could become a factor depending on what else the JVM is hosting. Multiple coordinators also allows for the memory burden to be distributed among multiple JVMs.
Configuring preferred servers for core group coordinators
The preferred servers for the core group coordinators should ideally be on separate physical boxes for isolation reasons. The coordinator adds almost no load on its JVM host during steady state operation with the exception of its memory requirements.
We recommend the preferred servers be on stable servers. A stable server is a JVM that is running continually and that is normally not stopped during production. The reason for this is that when a JVM which is currently a coordinator fails or is stopped, then the routing tables are redistributed over the surviving JVMs (preferred servers) in the cell.
It is better to reduce this churn to a minimum from an operation perspective and this is the reasoning for the recommendations. The additional memory load of a coordinator will increase the frequency of garbage collection (GC) and it will reduce the memory available for caches, or to any applications running in that JVM. The CPU usage will very slightly influence the JVM when the cluster membership changes. These issues can be avoided by running this function on separate machines if possible.
Asychronous delivery using Async Bean
For applications with computationally expensive operations that process incoming requests from a nontransactional message transport, it is recommended to use a separate worker thread to perform the computation. After receiving the request, create an Async Bean work instance and submit the work to a WorkManager to be performed on a separate thread.
When the work completes, continue processing the request. Assume that our application is running on a four-way SMP machine. The WorkManager used for the application should be limited to two threads and should not be expandable, limiting the impact of these long running tasks to two of the four CPUs. The remaining two CPUs can be used to schedule the short running tasks.
Application hosting on nodes and cluster members
It may be obvious, but to achieve the highest performance levels do not run anything else on the cluster members with our critical application, especially when it has two or less CPUs.
Do not run any computational commands on the machine such as tar, gzip, or similar applications. These commands may negatively impact thread scheduling for the applications.
Additionally, service functions such as the WPF PMI Performance Monitor and the HAManager coordinators should be carefully managed. As we have seen, the HAManager policy mechanism allows the administrator to be very specific about which runtime components should run where.
For example, if the performance monitoring function will be used often for our environment, it is suggested the PMI aggregator be configured to run on an application server exclusively. This will then prohibit the chance that performance monitoring could slow production functionality. An even better solution is to put the performance monitoring PMI aggregator on another machine.
Working with partitions
Here we provide some recommendations on how to deal with the case of a hot partition, or a partition that is experiencing an inordinately high workload for which the hosting server cannot keep up.
We can use the wpfadmin command or the HAManager JMX commands to move the busy partition from one server to another. This action will deactivate the partition on the original server and then activate it on the new server. The partition will be offline during this period. Most of the offline time is associated with the application's deactivate and activate code processing. This results in an outage for the specific partition. Therefore, the approach below is preferred over this approach.
To avoid an outage on the busiest partition, it is recommended to move the less busy partitions from the same cluster member to free up CPU capacity for the busy partitions. In this case, the less busy partitions will incur the temporary outage, which can be more acceptable than deactivating the busy partitions.
0 Mixing application types
If our application set has relatively short requests, then installing several similar applications on the cluster should provide reasonable throughput. However, the use of CPU intensive requests requires special considerations.
One approach is to have a partitioned J2EE application for a compute intensive application in a unique cluster within the cell, with exclusive access to specialized hardware for that purpose. Alternatively, if one needs to mix a lighter application set with a more computationally bound application set within the same cluster, the WPF framework can prove helpful if managed correctly.
To manage the mix of application types, it would be prudent to utilize the HAManager policy function to focus CPU intensive procedure calls to physical and logical nodes designed to handle that load. In addition, WPF allows the administrator to dynamically modify the target endpoint if additional computer resources can be acquired under heavy load situations.
An additional approach is to create a partition set with an M of N policy. Then, set the Preferred only attribute to true coupled with designating specific preferred servers for those specific partitions to dedicated machines in the cluster. Finally, create a client to direct requests to the cluster resources designed to handle that load. The M of N policy lets we assign more machines for that workload if we need it plus IIOP WLM will round robin the requests over the set of machines which are running the heavy load capable partition set.
1 Option A CMPs
Another key implementation point is how to store partition data in memory. The EJB specification describes an entity caching policy (Option A) that loads EJB data on first request, and then keeps it in memory until server shutdown. This can be effectively used in a partitioned environment, but is not possible in a non-partitioned environment, since updates can be guaranteed to arrive at a particular routable EJB.
The only option that will work is option A. Option A CMPs can be thought of as cached CMP although its not technically a cache. The J2EE specification says that if an option A CMP method throws an unexpected exception then the bean instance must be removed from the container and the transaction currently active is rolled back. We can take advantage of this to implement the partition data cache.
One of the problems with Option A caching is that there is a possibility that when partitions move we may end up with stale cached data. For example, if there are four partitions, A, B, C, and D, each starting in their JVM and then the JVM hosting A dies. Partition A would move to the JVM hosting partition B. The JVM originally hosting partition A then comes back on line and partition A moves back to that JVM. Now data in partition A is updated. If the JVM hosting partition A dies again, partition A moves back to the JVM hosting partition B and the previously cached data in the JVM now hosting A and B once again is stale due to the changes that happened while partition A was back on its original server. This can be overcome with the use of cache invalidation APIs to discard the cache on partition load events.
2 Lazy EJB startup
For better performance, EJBs are not fully initialized until the EJBHome is referenced for the first time in IBM WebSphere Network Deployment V6. During initialization, partition stateless session beans (PSSBs) are fully initialized since a LocalHome lookup is done to activate all partitions. Only the PSSBs are initialized, not any of the EJBs that reference them until they are referenced for the first time. The initialization is similar to the way that Startup Beans are required to initialize during server startup.
Problem resolution
This section lists some of the most common places in the partitioning facility environment where we can find more information when encountering a problem.
Core group coordinator JVM trace files
The core group coordinator is the component which actually observes a group and then applies policies to it and tells the various JVMs whether they should activate/deactivate group members hosted within that JVM. The core group coordinator usually runs in a single JVM in the group at a time. The logs of this JVM can be useful for determining any problems.
By default, the HAManager elects the lexically lowest named core group member to be the coordinator so we need to look at those server's log files - unless we have overwritten this setting by specifying preferred coordinator servers.
Core group runtime view
This allows us to see which groups are currently running, their members, the member states and the policies currently assigned to the group.
Access this view in the Administrative Console by selecting Servers | Core groups | Core group settings | DefaultCoreGroup | Runtime tab.
Tracing
Tracing can be enabled to obtain detailed information about the execution of WebSphere XD components, including the partitioning facility, and other processes in the environment. Trace files show the time and sequence of methods called by WebSphere XD classes, and we can use these files to pinpoint the failure. We can find the component we require to trace in Appendix B, Trace-level change script.