WebSphere AppServer Tuning Guide
Contents
- Overview
- Throughput
- Queuing and EJBs
- Queuing and clustering
- Tuning Secure Socket Layer
- Application assembly performance
- Tuning Java memory
- The garbage collection bottleneck
- The garbage collection gauge
- Detecting over utilization of objects
- Detecting memory leaks
- Java heap parameters
- Number of connections to DB2
- Workload management topology
- Individual performance parameters
- Hardware capacity and settings
- Processor speed
- Memory
- Network
- OS settings
- AIX
- Solaris
- The Web server
- Web server config reload interval
- IBM HTTP server - AIX and Solaris
- Sun ONE Web server - Solaris
- IBM HTTP server - Linux
- IBM HTTP server - Windows
- The WebSphere appserver process
- Web containers
- Security
- Object Request Broker (ORB)
- Java Virtual Machines (JVMs)
- Quick start option
- EJB container
- XML parser selection
- Data sources
- Connection pool size
- Prepared statement cache size
- Java Messaging Service
- Message listener service
- Embedded JMS server
- JMS resources
- DB2
- DB2 logging
- DB2 Configuration Advisor
- Use TCP sockets for DB2 on Linux
- DB2 MaxAppls
- DB2 MaxAgents
- DB2 buffpage
- DB2 query optimization level
- DB2 reorgchk
- DB2 MinCommit
- Session management
- WAS Enterprises
- Business process choreographer
- Application profiling
- Activity sessions
- Dynamic query service
- Additional reference
- Performance tool procedures
- Starting Windows Performance Monitor
See also
Overview
WAS uses a queuing network, which is a group of interconnected queue resources. Each of these resources represents a queue of requests waiting to use that resource:
Clients | Network | Web server | Web container | Servlet Engine | EJB Container | Data Source | DB
The WebSphere queues are load-dependent resources. The average service time of a request depends on the number of concurrent clients.
Closed queues
Most WAS queues are closed, and place a limit on the maximum number of requests present.
In general, you want to run with closed queues, or you risk running out of memory. For example, Web container thread pool settings control the size of the Web container queue. If the average servlet running in a Web container creates 10MB of objects during each request, then a value of 100 for thread pools would limit the memory consumed by the Web container to 1GB. If the queue was open, or unlimited, then you could have a scenario where ever increasing number of threads would consume all of the memory in the JVM.
In a closed queue, requests can be either active or waiting. An active request is either doing work or waiting for a response from a downstream queue. For example, an active request in the Web server is either doing work (such as retrieving static HTML) or waiting for a request to complete in the Web container. A waiting request is waiting to become active. The request remains in the waiting state until one of the active requests leaves the queue.
All Web servers supported by WAS are closed queues, as are WAS data sources. Web containers can be configured as either open or closed queues. In general, it is best to make them closed queues. EJB containers are open queues; if there are no threads available in the pool, a new one will be created for the duration of the request.
If EJBs are being called by servlets, the Web container limits the number of total concurrent requests into an Web container also has a limit. This is true only if EJBs are called from the servlet thread of execution. Nothing prevents you from creating threads and bombarding the EJB container with requests. Thus, servlets should not create their own work threads.
Queuing before WebSphere
The first rule of tuning is to minimize the number of requests in WAS queues.
In general, requests should wait in the network in front of the Web server, rather than waiting in WAS. This config allows only those requests that are ready to be processed to enter the queuing network. To accomplish this, specify that the queues furthest upstream (closest to the client) are slightly larger, and that the queues further downstream (furthest from the client) are progressively smaller.
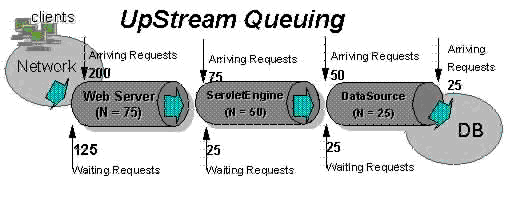
The queues in this example queuing network become progressively smaller as work flows downstream. When 200 client requests arrive at the Web server, 125 requests remain queued in the network because the Web server is set to handle 75 concurrent clients. As the 75 requests pass from the Web server to the Web container, 25 remain queued in the Web server, and the Web container handles the remaining 50. This process progresses through the data source until 25 user requests arrive at the final destination, the database server. Because there is work waiting to enter a component at each point upstream, no component in this system must wait for work to arrive. The bulk of the requests wait in the network, outside of WAS. This type of config adds stability, because no component is overloaded.
The Edge Server can be used to direct waiting users to other servers in a WAS cluster.
Exercise all meaningful code paths. Run a set of experiments to determine when the system capabilities are fully stressed (the saturation point). Conduct these tests after most of the bottlenecks have been removed from the application. The typical goal of these tests is to drive CPUs to near 100% utilization.
Start the initial baseline experiment with large queues. This allows maximum concurrency through the system. For example, start the first experiment with a queue size of 100 at each of the servers in the queuing network:
Start the initial baseline experiment with large queues. This allows maximum concurrency through the system. For example, start the first experiment with a queue size of 100 at each of the servers in the queuing network: Web server Web container data sourceNext, begin a series of experiments to plot a throughput curve, increasing the concurrent user load after each experiment. For example, perform experiments with 1 user, 2 users, 5, 10, 25, 50, 100, 150 and 200 users. After each run, record the throughput (requests per second) and response times (seconds per request).
Throughput
The curve resulting from the baseline experiments should resemble the typical throughput curve shown as follows:

The throughput of WAS is a function of the number of concurrent requests present in the total system. Section A, the light load zone, shows that as the number of concurrent user requests increases, the throughput increases almost linearly with the number of requests. This reflects that, at light loads, concurrent requests face very little congestion within the WAS system queues. At some point, congestion starts to develop and throughput increases at a much lower rate until it reaches a saturation point that represents the maximum throughput value, as determined by some bottleneck in the WAS system.
The most manageable type of bottleneck occurs when the CPUs of the UNIX machines become fully utilized. This is desirable because a CPU bottleneck can be fixed by adding additional or more powerful CPUs.
In the heavy load zone or Section B, as the concurrent client load increases, throughput remains relatively constant. However, the response time increases proportionally to the user load. That is, if the user load is doubled in the heavy load zone, the response time doubles. At some point, represented by Section C, the buckle zone, one of the system components becomes exhausted. At this point, throughput starts to degrade. For example, the system might enter the buckle zone when the network connections at the Web server exhaust the limits of the network adapter or if the requests exceed operating system limits for file handles.
If the saturation point is reached by driving CPU utilization close to 100%, you can move on to the next step. If the saturation CPU occurs before system utilization reaches 100%, there is likely another bottleneck that is being aggravated by the application. For example, the application might be creating Java objects causing excessive garbage collection bottlenecks in Java.
There are two ways to manage application bottlenecks: remove the bottleneck or clone the bottleneck. The best way to manage a bottleneck is to remove it. You can use a Java-based application profiler, such as Tivoli Performance Viewer (TPV), WebSphere Studio Application Developer, Performance Trace Data Visualizer, Optimizeit, JProbe or Jinsight to examine overall object utilization.
The number of concurrent users at the throughput saturation point represents the maximum concurrency of the application. For example, if the application saturated WAS at 50 users, 48 users might give best combination of throughput and response time. This value is called the Max Application Concurrency value. Max Application Concurrency becomes the preferred value for adjusting the WAS system queues. Remember, it is desirable for most users to wait in the network; therefore, queue sizes should increase when moving downstream farther from the client. For example, given a Max Application Concurrency value of 48, start with system queues at the following values: Web server 75, Web container 50, data source 45. Perform a set of additional experiments adjusting these values slightly higher and lower to find the best settings.
The TPV can be used to determine the number of concurrent users through the Servlet Engine Thread Pool Concurrently Active Threads metric.
In IBM performance experiments, throughput has increased by 10-15% when the Web container transport maximum keep-alive are adjusted to match the maximum number of Web container threads.
In many cases, only a fraction of the requests passing through one queue enters the next queue downstream. In a site with many static pages, many requests are fulfilled at the Web server and are not passed to the Web container. In this circumstance, the Web server queue can be significantly larger than the Web container queue. In the previous section, the Web server queue was set to 75 rather than closer to the value of Max Application Concurrency. Similar adjustments need to be made when different components have different execution times.
For example, in an application that spends 90% of its time in a complex servlet and only 10% making a short JDBC query, on average 10% of the servlets are using database connections at any time, so the database connection queue can be significantly smaller than the Web container queue. Conversely, if much of a servlet execution time is spent making a complex query to a database, consider increasing the queue values at both the Web container and the data source. Always monitor the CPU and memory utilization for both the WAS and the database servers to ensure the CPU or memory are not being saturated.
Queuing and EJBs
Method invocations to EJBs are only queued for remote clients, making the method call. An example of a remote client is an EJB client running in a separate JVM from the EJB. In contrast, no queuing occurs if the EJB client (either a servlet or another EJB) is installed in the same JVM that the EJB method runs on and the same thread of execution as the EJB client.
Remote EJBs communicate by using the RMI/IIOP protocol. Method invocations initiated over RMI/IIOP are processed by a server-side ORB. The thread pool acts as a queue for incoming requests. However, if a remote method request is issued and there are no more available threads in the thread pool size is reached. After the method request completes the thread is destroyed. By default, the ORB thread pool is set as a closed queue, with the option to set it as open if desired.
If a servlet is making a small number of calls to remote EJBs and each method call is relatively quick, consider setting the number of threads in the ORB Web container thread pool size value.
TPV shows a metric called Percent Maxed used to determine how much of the time all of the configured threads are in use. Percent Maxed has two values, the current and average value. If the current value is consistently 100%, then the ORB could be a bottleneck and the number of threads should be increased.
The degree to which the ORB thread pool value needs to be increased is a function of the number of simultaneous servlets (that is, clients) calling EJBs and the duration of each method call. If the method calls are longer or the applications spend a lot of time in the ORB, consider making the ORB Web container size. If the servlet makes only short-lived or quick calls to the ORB, servlets can potentially reuse the same ORB thread. In this case, the ORB thread pool can be small, perhaps even one-half of the thread pool size setting of the Web container.
Queuing and clustering
The capabilities for cloning appservers are useful if the system is experiencing bottlenecks that are preventing full CPU utilization of SMP servers. When adjusting the WAS system queues in clustered configs, remember that when a server is added to a cluster, the server downstream receives twice the load.

Two Web container clones are located between a Web server and a data source. It is assumed the Web server, servlet engines and data source (but not the database) are all running on a single SMP servers. Given these constraints, the following queue considerations need to be made:
- Web server queue settings can be doubled to ensure ample work is distributed to each Web container.
- Web container thread pools can be reduced to avoid saturating a system resource such as CPU or another resource that the servlets are using.
- The data source can be reduced to avoid saturating the database server.
- Java heap parameters can be reduced for each instance of the appserver. For versions of the JVM shipped with WAS, it is crucial that the heap from all JVMs remain in physical memory. Therefore, if a cluster of four JVMs are running on a system, enough physical memory must be available for all four heaps.
Tuning Secure Socket Layer
Handshake and bulk encryption and decryption
When an SSL connection is established, an SSL handshake occurs. After a connection is made, SSL performs bulk encryption and decryption for each read-write. The performance cost of an SSL handshake is much larger than that of bulk encryption and decryption.
How to enhance SSL performance
In order to enhance SSL performance, the number of individual SSL connections and handshakes must be decreased.
Decreasing the number of connections increases performance for secure communication through SSL connections, as well as non-secure communication through simple TCP connections. One way to decrease individual SSL connections is to use a browser that supports HTTP 1.1. Decreasing individual SSL connections could be impossible for some users if they cannot upgrade to HTTP 1.1.
Another common approach is to decrease the number of connections (both TCP and SSL) between two WAS components. The following guidelines help to ensure the HTTP transport of the appserver is configured so that the Web server plug-in does not repeatedly reopen new connections to the appserver:
- The maximum number of keep-alives should be, at minimum, as large as the maximum number of requests per thread of the Web server (or maximum number of processes for IHS on UNIX). In other words, make sure the Web server plug-in is capable of obtaining a keep-alive connection for every possible concurrent connection to the appserver. Otherwise, the appserver will close the connection after a single request has been processed. Also, the maximum number of threads in the Web container thread pool should be larger than the maximum number of keep-alives, in order to prevent the Web container threads from being consumed with keep-alive connections.
- The maximum number of requests per keep-alive connection can also be increased. The default value is 100, which means the appserver will close the connection from the plug-in after 100 requests. The plug-in would then have to open a new connection. The purpose of this parameter is to prevent denial of service attacks when connecting to the appserver and continuously send requests in order to tie up threads in the appserver.
- Use a hardware accelerator if the system performs several SSL handshakes.
Hardware accelerators currently supported by WAS only increase the SSL handshake performance, not the bulk encryption/decryption. An accelerator typically only benefits the Web server because Web server connections are short-lived. All other SSL connections in WAS are long-lived.
- Use an alternative cipher suite with better performance.
The performance of a cipher suite is different with software and hardware. Just because a cipher suite performs better in software does not mean a cipher suite will perform better with hardware. Some algorithms are typically inefficient in hardware (for example, DES and 3DES), however, specialized hardware can provide efficient implementations of these same algorithms.
The performance of bulk encryption and decryption is affected by the cipher suite used for an individual SSL connection.The following chart displays the performance of each cipher suite. The test software calculating the data was IBM JSSE for both the client and server software, which used no crypto hardware support. The test did not include the time to establish a connection, but only the time to transmit data through an established connection. Therefore, the data reveals the relative SSL performance of various cipher suites for long running connections.
Before establishing a connection, the client enabled a single cipher suite for each test case. After the connection was established, the client timed how long it took to write an integer to the server and for the server to write the specified number of bytes back to the client. Varying the amount of data had negligible effects on the relative performance of the cipher suites.
- Bulk encryption performance is only affected by what follows the WITH in the cipher suite name. This is expected since the portion before the WITH identifies the algorithm used only during the SSL handshake.
- MD5 and SHA are the two hash algorithms used to provide data integrity. MD5 is 25% faster than SHA, however, SHA is more secure than MD5.
- DES and RC2 are slower than RC4. Triple DES is the most secure, but the performance cost is high when using only software.
- The cipher suite providing the best performance while still providing privacy is SSL_RSA_WITH_RC4_128_MD5. Even though SSL_RSA_EXPORT_WITH_RC4_40_MD5 is cryptographically weaker than RSA_WITH_RC4_128_MD5, the performance for bulk encryption is the same. Therefore, as long as the SSL connection is a long-running connection, the difference in the performance of high and medium security levels is negligible. It is recommended that a security level of high be used, instead of medium, for all components participating in communication only among WAS products. Make sure that the connections are long running connections.
Application assembly performance checklist
Application assembly tools are used to assemble J2EE components and modules into J2EE applications. Generally, this consists of defining application components and their attributes including EJBs, servlets and resource references. Many of these application config settings and attributes play an important role in the runtime performance of the deployed application. The most important parameters and advice for finding optimal settings follow:
Enterprise bean modules
Note that although WAS 5.0 also supports EJB 2.0, the following information refers to EJB 1.1 settings.
Entity EJBs - Bean cache
WAS provides significant flexibility in the management of database data with Entity EJBs. The Entity EJBs Activate At and Load At config settings specify how and when to load and cache data from the corresponding database row data of an EJB. These config settings provide the capability to specify EJB commit options A, B or C, as specified in the EJB 1.1 specification.The Activate At and Load At settings are detailed below along with specific settings to achieve each of the EJB commit options A, B and C.
Commit Option Description A Caches database data outside of the transaction scope. Generally applicable where the integrity is compromised. B More aggressive caching of entity EJB object instances. Can result in improved performance over commit option C, but also results in greater memory usage. C Most common real-world config for Entity EJBs.
Bean cache Activate At
Specifies the point at which an EJB is activated and placed in the cache. Removal from the cache and passivation are also governed by this setting. Valid values are Once and Transaction. Once indicates that the bean is activated when it is first accessed in the server process, and passivated (and removed from the cache) at the discretion of the container, for example, when the cache becomes full. Transaction indicates that the bean is activated at the start of a transaction and passivated (and removed from the cache) at the end of the transaction. The default value is Transaction.
Bean cache Load At
Specifies when the bean loads its state from the database. The value of this property implies whether the container has exclusive or shared access to the database. Valid values are Activation and Transaction. Activation indicates the bean is loaded when it is activated and implies that the container has exclusive access to the database. Transaction indicates that the bean is loaded at the start of a transaction and implies that the container has shared access to the database. The default is Transaction.
Sets
The settings of the Activate At and Load At properties govern which commit options are used.
- Commit option A (exclusive database access):
Activate At = Once
Load At = Activation.This option reduces database input/output by avoiding calls to the ejbLoad function, but serializes all transactions accessing the bean instance. Option A can increase memory usage by maintaining more objects in the cache, but can provide better response time if bean instances are not generally accessed concurrently by multiple transactions.
- For commit option B (shared database access)
Activate At = Once
Load At = Transaction.Option B can increase memory usage by maintaining more objects in the cache. However, because each transaction creates its own copy of an object, there can be multiple copies of an instance in memory at any given time (one per transaction), requiring the database be accessed at each transaction. If an EJB contains a significant number of calls to the ejbActivate function, using option B can be beneficial because the required object is already in the cache. Otherwise, this option does not provide significant benefit over option A.
- For commit option C (shared database access)
Activate At = Transaction
Load At = Transaction.This option can reduce memory usage by maintaining fewer objects in the cache, however, there can be multiple copies of an instance in memory at any given time (one per transaction). This option can reduce transaction contention for EJB instances that are accessed concurrently but not updated.
Method extensions - Isolation level
Isolation level also plays an important role in performance. Higher isolation levels reduce performance by increasing row locking and database overhead while reducing data access concurrency. Various databases provide different behavior with respect to the isolation settings. In general, Repeatable Read is an appropriate setting for DB2 databases. Read Committed is generally used for Oracle. Oracle does not support Repeatable Read and will translate this setting to the highest isolation level serializable.
Isolation level can be specified at the bean or method level. Therefore, it is possible to configure different isolation settings for various methods. This is an advantage when some methods require higher isolation than others, and can be used to achieve maximum performance while maintaining integrity requirements. However, isolation cannot change between method calls within a single EJB transaction. A runtime exception will be thrown in this case.
Isolation levels
Serializable Prohibits the following types of reads:
Dirty reads A transaction reads a database row containing uncommitted changes from a second transaction. Nonrepeatable reads One transaction reads a row, a second transaction changes the same row, and the first transaction rereads the row and gets a different value. Phantom reads One transaction reads all rows that satisfy an SQL WHERE condition, a second transaction inserts a row that also satisfies the WHERE condition, and the first transaction applies the same WHERE condition and gets the row inserted by the second transaction. Prohibits dirty reads and nonrepeatable reads, but it allows phantom reads. Prohibits dirty reads, but allows nonrepeatable reads and phantom reads. Allows dirty reads, nonrepeatable reads, and phantom reads.
The container uses the transaction isolation level attribute as follows:
- Session beans and BMP
For each database connection used by the bean, the container sets the transaction isolation level at the start of each transaction unless the bean explicitly sets the isolation level on the connection.
- Entity beans with CMP
The container generates database access code that implements the specified isolation level.
Method extensions - Access intent
WAS EJB method extensions provide settings to specify individual EJB methods as read-only. This setting denotes whether the method can update entity attribute data (or invoke other methods that can update data in the same transaction).
Guide
By default, all EJB methods are assumed to be "update" methods. This results in EJB Entity data always being persisted back to the database at the close of the EJB transaction. Marking enterprise methods as Access Intent Read that do not update entity attributes, provides a significant performance improvement by allowing the WAS EJB container to skip the unnecessary database update.A behavior for "finder" methods for CMP Entity EJBs is available. By default, WAS will invoke a "Select for Update" query for CMP EJB finder methods such as findByPrimaryKey. This exclusively locks the database row for the duration of the EJB transaction. However, if the EJB finder method has been marked as Access Intent Read, the container will not issue the "For Update" on the select resulting in only a read lock on the database row.
Container transactions
The container transaction properties specifies how the container manages transaction scopes when delegating invocation to the EJB individual business method. The legal values are:
Guide
Container transaction attribute can be specified individually for one or more EJB methods. Enterprise bean methods not requiring transactional behavior can be configured as Supports to reduce container transaction management overhead.
Legal values
NeverThis legal value directs the container to invoke bean methods without a transaction context. If the client invokes a bean method from within a transaction context, the container throws the java.rmi.RemoteException exception.
If the client invokes a bean method from outside a transaction context, the container behaves in the same way as if the Not Supported transaction attribute was set. The client must call the method without a transaction context.
Mandatory
This legal value directs the container to always invoke the bean method within the transaction context associated with the client. If the client attempts to invoke the bean method without a transaction context, the container throws the javax.jts.TransactionRequiredException exception to the client. The transaction context is passed to any EJB object or resource accessed by an EJB method.
Enterprise bean clients that access these entity beans must do so within an existing transaction. For other EJBs, the EJB or bean method must implement the Bean Managed value or use the Required or Requires New value. For non-EJB EJB clients, the client must invoke a transaction by using the javax.transaction.UserTransaction interface.
Requires New
This legal value directs the container to always invoke the bean method within a new transaction context, regardless of whether the client invokes the method within or outside a transaction context. The transaction context is passed to any EJB objects or resources that are used by this bean method.
Required
This legal value directs the container to invoke the bean method within a transaction context. If a client invokes a bean method from within a transaction context, the container invokes the bean method within the client transaction context. If a client invokes a bean method outside a transaction context, the container creates a new transaction context and invokes the bean method from within that context. The transaction context is passed to any EJB objects or resources that are used by this bean method.
Supports
This legal value directs the container to invoke the bean method within a transaction context if the client invokes the bean method within a transaction. If the client invokes the bean method without a transaction context, the container invokes the bean method without a transaction context. The transaction context is passed to any EJB objects or resources that are used by this bean method.
Not Supported
This legal value directs the container to invoke bean methods without a transaction context. If a client invokes a bean method from within a transaction context, the container suspends the association between the transaction and the current thread before invoking the method on the EJB instance. The container then resumes the suspended association when the method invocation returns. The suspended transaction context is not passed to any EJB objects or resources that are used by this bean method.
Bean Managed
This value notifies the container that the bean class directly handles transaction demarcation. This property can be specified only for session beans, not for individual bean methods.
Web module
Webapp - Distributable
The distributable flag for J2EE Webapps specifies that the Webapp is programmed to be deployed in a distributed servlet container.
Guide
Webapps should be marked as distributable if, and only if, they will be deployed in a WAS cluster or cloned environment.
Webapp - Reload interval
Reload interval specifies a time interval, in seconds, in which the Webapp file system is scanned for updated files, such as servlet class files or JSPs.
Guide
Reload interval can be defined at different levels for various application components. Generally, the reload interval specifies the time the appserver will wait between checks to see if dependent files have been updated and need to be reloaded. Checking file system time stamps is an expensive operation and should be reduced. The default of 3 seconds is good for a test environment, because the Web site can be updated without restarting the appserver. In production environments, checking a few times a day is a more common setting.
Webapp - Reloading enabled
This specifies whether file reloading is enabled.
Webapp - Web components - Load on startup
Indicates whether a servlet is to be loaded at the startup of the Webapp. The default is false.
Guide
Many servlets perform resource allocation and other up-front processing in the servlet init() method. These initialization routines can be costly at runtime. By specifying Load on startup for these servlets, processing takes place when the appserver is started. This avoids runtime delays, which can be encountered on a servlets initial access.
Tuning Java memory
Enterprise applications written in Java involves complex object relationships and utilize large numbers of objects. Although Java automatically manages memory associated with an object's life cycle, understanding the application's usage patterns for objects is important. In particular, ensure the following:- The application is not over utilizing objects
- The application is not leaking objects (that is, memory)
- The Java heap parameters are set to handle the use of objects
Understanding the effect of garbage collection is necessary to apply these management techniques.
The garbage collection bottleneck
Garbage collection should take at most 5% of the total execution time. Going above this threshold triggers a warning signal. If not managed, garbage collection can be one of the biggest bottlenecks for an application, especially when running on SMP server machines.
The garbage collection gauge
You can use garbage collection to evaluate application performance health. By monitoring garbage collection during the execution of a fixed workload, users gain insight as to whether the application is over utilizing objects. Garbage collection can even be used to detect the presence of memory leaks.
Use the garbage collection and heap statistics in TPV to evaluate application performance health. By monitoring garbage collection, memory leaks and overly-used objects can be detected.
For this type of investigation, set the minimum and maximum heap sizes to the same value. Choose a representative, repetitive workload that matches production usage as closely as possible, user errors included. Allowing the application to run several minutes until the application state stabilizes is important. To ensure meaningful statistics, run the fixed workload until the state of the application is steady. Reaching this state usually takes several minutes.
Detecting over-utilization of objects
To see if the application is overusing objects, look in TPV at the counters for the JVMPI profiler. Note that you have to set the -XrunpmiJvmpiProfiler command line option and set the maximum level for the JVM module in order to enable the JVMPI counters. The average time between garbage collection calls should be 5 to 6 times the average duration of a single garbage collection. If not, the application is spending more than 15% of its time in garbage collection.
Also, look at the numbers of freed, allocated and moved objects.
If the information indicates a garbage collection bottleneck, there are two ways to clear the bottleneck. The most cost-effective way to optimize the application is to implement object caches and pools. Use a Java profiler to determine which objects to target. If the application cannot be optimized, adding memory, processors and clones might help. Additional memory allows each clone to maintain a reasonable heap size. Additional processors allow the clones to run in parallel.
Detecting memory leaks
Memory leaks occur when an unneeded object has references that are never deleted and the object is never removed from memory. A memory leak ultimately leads to system instability. Over time, garbage collection occurs more frequently until finally the heap is exhausted and Java fails with an Out of Memory exception.
Applications that leak memory are likely to crash sooner when subjected to a high workload, which accelerate the accumulation of leaking objects.
Memory leaks are measured in terms of the amount of kilobytes that cannot be garbage collected. The following is a list of testing methodologies for detecting memory leaks:
- Long-running test
Memory leak problems can manifest only after a period of time, therefore, memory leaks are found when during long-running tests. Short runs can lead to false alarms. One of the problems in Java is whether to say that a memory leak is occurring when memory usage has seemingly increased either abruptly or monotonically in a given period. These kind of increases can be valid, and the objects created can be referenced at a much later time. In other words, how do you differentiate the delayed use of objects from completely unused objects? By running applications long enough, you will get a higher confidence for whether the delayed use of objects is actually occurring. Because of this, memory leak testing cannot be integrated with some other types of tests, such as functional testing, that occur earlier in the process. However, tests such as stress or durability tests can be integrated.
- System test
Some memory leak problems occur only when different components of a big project are combined and executed. Interfaces between components can produce known or unknown side-effects. System test is a good opportunity to make these conditions happen.
- Repetitive test
In many cases, memory leak problems occur by successive repetitions of the same test case. The goal of memory leak testing is to establish a big gap between unusable memory and used memory in terms of their relative sizes. By repeating the same scenario over and over again, the gap is multiplied in a very progressive way. This testing helps if the amount of leaks caused by an execution of a test case is so minimal that it could hardly be noticed in one run.
Repetitive tests can be used at the system level or module level. The advantage with modular testing is better control. When a module is designed to keep the private module without creating external side effects such as memory usage, testing for memory leaks can be much easier. First, the memory usage before running the module is recorded. Then, a fixed set of test cases are run repeatedly. At the end of the test run, the current memory usage is recorded and checked for significant changes. Remember, garbage collection must be forced when recording the actual memory usage by inserting System.gc() in the module where you want garbage collection to occur or using a profiling tool forcing the event to occur.
- Concurrency test
Some memory leak problems can occur only when there are several threads running in the application. Unfortunately, synchronization points are very susceptible to producing memory leaks because of the added complication in the program logic. Careless programming can lead to references being kept or unreleased. The incident of memory leaks is often facilitated or accelerated by increased concurrency in the system. The most common way to increase concurrency is to increase the number of clients in the test driver.
Consider the following when choosing which test cases to use for memory leak testing:
- A good test case exercises areas of the application where objects are created. Most of the time, knowledge of the application is required. A description of the scenario can suggest creation of data spaces, such as adding a new record, creating an HTTP session, performing a transaction and searching a record.
- Look at areas where collections of objects are being used. Typically, memory leaks are composed of objects of the same class. Also, collection classes such as Vector and Hashtable are common places where references to objects are implicitly stored by calling corresponding insertion methods. For example, the get method of a Hashtable object does not remove its reference to the object being retrieved.
TPV helps to find memory leaks. For best results, repeat experiments with increasing duration, like 1000, 2000, and 4000-page requests. The TPV graph of used memory should have a sawtooth shape. Each drop on the graph corresponds to a garbage collection. There is a memory leak if one of the following occurs:
- The amount of memory used immediately after each garbage collection increases significantly. The sawtooth pattern will look more like a staircase.
- The sawtooth pattern has an irregular shape
Also, look at the difference between the number of objects allocated and the number of objects freed. If the gap between the two increases over time, there is a memory leak.
If heap consumption indicates a possible leak during a heavy workload (the host running the appserver is consistently near 100% CPU utilization), yet the heap appears to recover during a subsequent lighter or near-idle workload, this is an indication of heap fragmentation. Heap fragmentation can occur when the JVM is able to free sufficient objects to satisfy memory allocation requests during garbage collection cycles, but the JVM does not have the time to compact small free memory areas in the heap into larger contiguous spaces.
Another form of heap fragmentation occurs when small objects (less than 512 bytes) are freed. The objects are freed, but the storage is not recovered, resulting in memory fragmentation.
Heap fragmentation can be avoided by turning on the -Xcompactgc flag in the JVM advanced settings command line arguments. The -Xcompactgc command ensures that each garbage collection cycle eliminates fragmentation, but this setting has a small performance penalty. However, compaction is a relatively expensive operation.
You can use connection leak trace logic to detect JDBC connection leaks.
Java heap parameters
The Java heap parameters also influence the behavior of garbage collection. Increasing the heap size allows more objects to be created. Because a large heap takes longer to fill, the application runs longer before a garbage collection occurs. However, a larger heap also takes longer to compact and causes garbage collection to take longer.
For performance analysis, the initial and maximum heap sizes should be equal
When tuning a production system where the working set size of the Java application is not understood, a good starting value is to let the initial heap size be 25% of the maximum heap size. The JVM will then try to adapt the size of the heap to the working set size of the application.

The illustration represents three CPU profiles, each running a fixed workload with varying Java heap settings. In the middle profile, the initial and maximum heap size are set to 128MB. Four garbage collections occur. The total time in garbage collection is about 15% of the total run. When the heap parameters are doubled to 256MB, as in the top profile, the length of the work time increases between garbage collections. Only three garbage collections, but the length of each garbage collection is also increased. In the third profile, the heap size is reduced to 64MB and exhibits the opposite affect. With a smaller heap, both the time between garbage collections and time for each garbage collection are shorter. For all three configs, the total time in garbage collection is approximately 15%. This example illustrates an important concept about the Java heap and its relationship to object utilization. There is always a cos for garbage collection in Java applications.
Run a series of test experiments that vary the Java heap settings. For example, run experiments with 128MB, 192MB, 256MB, and 320MB. During each experiment, monitor the total memory usage. If you expand the heap too aggressively, paging can occur. (Use the vmstat command or the Windows Performance Monitor to check for paging.) If paging occurs, reduce the size of the heap or add more memory to the system. When all the runs are finished, compare the following statistics :
- Number of garbage collection calls
- Average duration of a single garbage collection call
- Ratio between the length of a single garbage collection call and the average time between calls
If the application is not over utilizing objects and has no memory leaks, state of steady memory utilization is reached. Garbage collection also occurs less frequently and for short duration's.
If the heap free time settles at 85% or more, consider decreasing the maximum heap size values because the appserver and the application are under-utilizing the memory allocated for heap.
Workload management topology
WAS provides various Workload Management (WLM) topologies. The following two topologies (name Topology A and B) are examples of workload being sent from one machine:
- Topology A contains a Web server and a WAS plug-in to a cluster of appservers. Each cluster member contains a Web container and EJB container.
- Topology B includes a Web server, a plug-in, and one Web container to a cluster of EJB containers.
In both topologies, the Object Request Broker pass-by-reference is selected and the backend database is on a dedicated machine.
Topology A has an advantage because the Web container and EJB container are running in a single JVM. In Topology B, the Object Request Broker pass-by-reference option is ignored between the Web container cluster member and the EJB container member. In Topology A, the Web container. In other words, the request does not have to be passed from one thread in one JVM to another thread in another JVM.
Also, if the processor utilization of the cluster member machines is near 100% CPU utilization, additional members could be added. If the Web server box is not running at capacity and the Web container processing is not heavy, try freeing the processor on the other members by moving to Topology B.
Throughput for Topology A can improve performance from 10-20% more than Topology B. This performance increase can be seen using the J2EE benchmark Trade, which is included with this release. In the test environment, Topology A had the advantage, however, many factors related to the application and environment can influence results.
Number of connections to DB2
When configuring the data source settings for the databases, ensure the DB2 MaxAppls setting is greater than the maximum number of connections for the data source. If you are planning to establish clones, the MaxAppls setting needs to be the maximum number of connections multiplied by the number of clones.
Note that this does not apply to mainframe, host-based DB2 instances.
The same relationship applies to the session manager number of connections. The MaxAppls setting must be at least as high as the number of connections. If you are using the same database for session and data sources, MaxAppls needs to be the sum of the number of connection settings for the session manager and the data sources.
MaxAppls = (# of connections set for data source
+ # of connections in session manager)
* # of clones
After calculating the MaxAppls settings for the WAS database and each of the application databases, ensure that the MaxAgents setting for DB2 is equal to or greater than the sum of all of the MaxAppls.
MaxAgents = sum of MaxAppls for all databases
Individual performance parameters
As mentioned previously, tuning various system components strongly affects on the performance of WAS. This section discusses how to set the parameters of individual components in order to bring the system to an optimum level of usage.
Hardware
This section discusses considerations for selecting and configuring the hardware on which the appservers will run.
Processor speed
- Ideally, other bottlenecks have been removed where the processor is waiting on events like input/output and application concurrency. In this case, increasing the processor speed often helps throughput and response times.
System memory
-
Increasing memory to prevent the system from paging memory to disk is likely to improve performance.
Allow at least 256MB memory for each processor.
- Try adjusting the parameter when the system is paging (and processor utilization is low because of the paging).
- Recommended value: 512MB
Networks
-
Run network cards and network switches at full duplex. Running at half
duplex decreases performance.
Verify the network speed can accommodate the required throughput. Make sure that 100MB is in use on 10/100 Ethernet networks.
See the white paper WAS Admin Best Practices for Performance and Scalability for more information regarding hostname resolution on the administrative client host.
Operating system settings
This section discusses considerations for tuning the operating systems in the server environment.
AIX
AIX with DB2
Separating your DB2 log files from the physical database files can boost performance. You should also separate the logging and the database files from the drive containing the Journaled File System (JFS) service. AIX uses specific volume groups and file systems for the JFS logging.
To set:
Use the AIX filemon utility to view all file system input and output, and to strategically select the file system for the DB2 logs. Then, set the DB2 log location according to DB2 logging.
AIX file descriptors (ulimit)
Number of open files permitted.
The default setting is typically sufficient for most applications. If the value set for this parameter is too low, a Memory allocation error is displayed.
To set: Check the UNIX reference pages on ulimit for the syntax for different shells. For the KornShell shell (ksh), to set ulimit to 2000, issue the ulimit -n 2000 command.
Use the command ulimit -a to display the current values for all limitations on system resources.
Default value: For AIX, the default setting is 2000.
Other AIX information
There are many other AIX operating system settings to consider, that are not within the scope of this document. The following list includes some of settings that the WebSphere performance team adjusts:
- Adapter transmit and receive queue
- TCP socket buffer
- IP protocol
- mbuf pool performance
- Update file descriptors
- Update the scheduler
Solaris
Tuning these parameters has a significant performance impact for Solaris. StartupServer.sh sets these:
When to try these parameters: Try these parameters when you are using WAS on Solaris.
Before the three TCP parameters were changed, the server stalled during certain peak periods. The netstat -i command showed that many sockets open to port 80 were in the state CLOSE_WAIT or FIN_WAIT_2.
Solaris file descriptors (ulimit)
Number of open files permitted.
If the value of this parameter is too low, a Too many files open error displays in the WAS stderr.log.
How to view or set: Check the UNIX reference pages on ulimit for the syntax for different shells. For KornShell (ksh) use the ulimit -n 1024 command. Use the ulimit -a command to display the current values for all limitations on system resources.
Default value: The WAS startupServer.sh script sets this parameter to 1024 if its value is less than 1024.
Solaris TCP_TIME_WAIT_INTERVAL
How long to keep closed connection control blocks. After the applications complete the TCP connection, the control blocks are kept for the specified time.
When high connection rates occur, a large backlog of the TCP connections build up and can slow server performance. The server can stall during certain peak periods. If this occurs, The netstat -i command will show that many of the sockets opened to port 80 were in the CLOSE_WAIT or FIN_WAIT_2 state. Visible delays have occurred for up to four minutes, during which the server did not send any responses, but CPU utilization stayed high, with all of the activity in system processes.
How to view or set: Use the get command to determine the current interval and the set command to specify an interval of 60 seconds. For example:
ndd -get /dev/tcp tcp_time_wait_interval
ndd -set /dev/tcp tcp_time_wait_interval 60000
Default value: The Solaris default time wait interval is 2400000 milliseconds.
Recommended value: The TCP_TIME_WAIT_INTERVAL parameter can be set as low as 30000 milliseconds. As a starting point, the WAS startupServer.sh script sets it to 60000ms.
Solaris TCP_FIN_WAIT_2_FLUSH_INTERVAL
The timer interval prohibiting a connection in FIN_WAIT_2 to remain in that state.
When high connection rates occur, a large backlog of TCP connections accumulate and can slow server performance.
The server can stall during peak periods. Using the netstat -i command indicated that many of the sockets opened to port 80 were in CLOSE_WAIT or FIN_WAIT_2 state. Visible delays have occurred for as many as four minutes, during which the server did not send any responses, but CPU utilization stayed high, with all of the activity in system processes.
How to view and set: Use the following commands to determine the curren interval or to set the interval to 67.5 seconds:
ndd -get /dev/tcp tcp_fin_wait_2_flush_interval
ndd -set /dev/tcp tcp_fin_wait_2_flush_interval 67500
Default value: The Solaris default is 675000
Recommended value: 67500
Related parameters: See Solaris
Solaris TCP_KEEPALIVE_INTERVAL
The timer interval prohibiting an active connection from staying in ESTABLISHED state if one of the peers never responds.
If you are concerned with failed communications from clients or peers, this value determines how long a connection will stay open.
How to view or set: Use the following commands to determine the curren value or to set the value to 300 seconds:
ndd -get /dev/tcp tcp_keepalive_interval
ndd -set /dev/tcp tcp_keepalive_interval 300000
Default value: 7200000
Recommended Value: 300000
Other Solaris TCP parameters
Customers have reported success with modifying other Solaris TCP parameters, including the following:
tcp_conn_req_max_q
tcp_comm_hash_size
tcp_xmit_hiwa
Although significant performance differences have not been seen after raising these settings, the system might benefit.
Solaris kernel semsys:seminfo_semume
> The semsys:seminfo_semume kernel tuning parameter limits the Max Semaphore undo entries per process and needs to be greater than the default. Because this setting specifies a maximum value, the parameter does not cause any additional memory to be used unless it is needed.
This value is displayed as SEMUME if the /usr/sbin/sysdef command is run. There can be an entry in the /etc/system file for this tuning parameter. Set this parameter throughout the /etc/system entry as follows:
set semsys:seminfo_semume = 1024
Default value: 10
Solaris kernel semsys:seminfo_semopm
To set: This setting is displayed SEMOPM if the /usr/sbin/sysdef command is run. There can possibly be an entry in the /etc/system file for this tuning parameter.
Set via the /etc/system entry:
semsys:seminfo_semopm = 200
Set the virtual page size for WAS JVM to 64KB
To set:
chatr +pi64M +pd64M $WAS_HOME/java/bin/PA_RISC2.0/native_threads/java
The command output provides the current operating system characteristics of the process executable.
The Web server
WAS provides plug-ins for several Web server brands and versions. Each Web server operating system combination has specific tuning parameters that affect the application performance.
This section discusses the performance tuning settings associated with the Web servers.
Web server config reload interval
WAS administration tracks a variety of config information about WAS resources. Some of this information, such as URIs pointing to WAS resources, needs to be understood by the Web server. This config data is pushed to the Web server through the WAS plug-in at intervals specified by this parameter. Periodic updates allow new servlet definitions to be added without having to restart any of the WAS servers. However, the dynamic regeneration of this config information is costly in terms of performance.
To set, edit...
$WAS_HOME/config/plug-in.xml
...and modify <RefreshInterval=xxxx>.
The default reload interval is 60 seconds.
IBM HTTP Server (IHS) - AIX and Solaris
The IBM HTTP Server (IHS) is a multi-process, single-threaded server.
Sun ONE Web server, EE - Solaris
The default config of the Sun ONE Web server, Enterprise Edition provides a single-process, multi-threaded server.
Active threads
- After the server reaches the limit set with this parameter, the server stops servicing new connections until it finishes old connections.
- If this setting is too low, the server can become throttled, resulting in degraded response times.
To tell if the Web server is being throttled, consult its perfdump statistics. Look at the following data:
WaitingThreads count: If WaitingThreads count is getting close to zero, or is zero, the server is not accepting new connections. BusyThreads count: If the WaitingThreads count is close to zero, or is zero, BusyThreads is probably very close to its limit. ActiveThreads count: If ActiveThreads count close to its limit, the server is probably limiting itself. - How to view or set: Use the Maximum number of simultaneous requests parameter in the Enterprise Server Manager interface to control the number of active threads within Sun ONE Web server, Enterprise Edition. This setting corresponds to the RqThrottle parameter in the magnus.conf file.
- Default value: 512
IBM HTTP Server - Linux
MaxRequestsPerChild
The MaxRequestsPerChild directive sets the limit on the number of requests that an individual child server process handles. After the number of requests reaches the value set for the MaxRequestsPerChild parameter, the child process dies. If there are no known memory leaks with Apache and Apache's libraries, set this value to zero (0).
To set:
- Edit the IBM HTTP server file, $IHS_HOME/conf/httpd.conf
- Change the value of the parameter.
- Save the changes and restart the IBM HTTP server (apachectl).
Default value: 500
How to view thread utilization:
Two ways to find how many threads are being used under load are as follows:- Use the Win2K Performance Monitor:
Start > Programs > Administrative Tools > Performance Monitor > Edit > Add to chart
- Set the following:
Object IBM HTTP Server Instance Apache Counter Waiting for connection To calculate the number of busy threads, subtract the number waiting from the total available (ThreadsPerChild).
- Use IBM HTTP Server server-status (this choice
works on all platforms, not just Windows)
Follow these steps to use IBM HTTP Server server-status:
- Edit the IBM HTTP Server file httpd.conf as follows:
- Uncomment the following lines:
#LoadModule status_module modules/ApacheModuleStatus.dll #<Location /server-status> #SetHandler server-status #</Location> - Save the changes and restart the IBM HTTP server.
- In a Web browser, go to the following URL and click Reload to update status:
http://yourhost/server-status.
- Alternatively, if the browser supports refresh, go to...
http://yourhost/server-status?refresh=5
...to refresh every 5 seconds. You will see 5 requests currently being processed, 45 idle servers.
Default value: 50 (for IBM HTTP Server 1.3.26).
ListenBackLog
When several clients request connections to the IBM HTTP Server, and all threads (see ThreadsPerChild) are being used, a queue exists to hold additional client requests. The ListenBackLog directive sets the length of this pending connections queue. However, if you are using the default Fast Response Cache Accelerator (FRCA) feature, the ListenBackLog directive is not used since FRCA has its own internal queue.
To set:
For non-FRCA:
- Edit IBM HTTP Server file httpd.conf.
- Add or view the ListenBackLog directive.
Default value for HTTP Server 1.3.26:
1024 with FRCA enabled
511 with FRCA disabled (the default)
Recommended value: Use the defaults.
The WAS process
Each WAS process has several parameters influencing application performance. Each appserver in WAS is comprised of an Web container. Use the WAS administrative console to configure and tune applications, Web containers, nodes in the administrative domain.
Web containers
To route servlet requests from the Web server to the Web containers, WAS establishes a transport queue between the Web server plug-in and each Web container.
Thread pool
Use the maximum thread size parameter to specify the maximum number of threads that can be pooled to handle requests sent to the Web container. Requests are sent to the Web container through any of the HTTP transports.
To set:
- Click thru...
Servers | Application Servers | server | Web Container | Thread Pool
- Enter the desired maximum number of threads in the Maximum Size field. Set minumum number of threads to 1/4 of Maximum Size. For debugging, set min and max values equal.
TPV displays a metric called Percent Maxed that determines the amount of time that the configured threads are in use. Percent Maxed has two values, the current and average value. If the current value is consistently 100%, the Web container could be a bottleneck and the number of threads should be increased.
Default value: 50
Note that if this value is set too low, you can get unexpected and anomalous behavior when you ramp up the number of users on the system. One error associated with too few threads is...
DSRA9400E: Fatal error occurred during Connection reassociation: javax.resource.ResourceException:
...however, exceptions can spawn from a variety of places on the process chain, leading to other, less intuitive error messages.
MaxKeepAliveConnections
Maximum number of concurrent connections to the Web container that are allowed to be kept alive.
The Web server plug-in keeps connections open to the appserver as long as it can. However, if the value of this property is too small, performance is negatively impacted because the plug-in has to open a new connection for each request instead of sending multiple requests through one connection. The appserver might not accept a new connection under a heavy load if there are too many sockets in TIME_WAIT state.
If all client requests are going through the Web server plug-in and there are many TIME_WAIT state sockets for port 9080, the appserver is closing connections prematurely, which decreases performance. The appserver will close the connection from the plug-in, or from any client, for any of the following reasons:
- The client request was an HTTP 1.0 request when the Web server plug-in always sends HTTP 1.1 requests.
- The maximum number of concurrent keep-alives was reached. A keep-alive must be obtained only once for the life of a connection, that is, after the first request is completed, but before the second request can be read.
- The maximum number of requests for a connection was reached, preventing denial of service attacks in which a client tries to hold on to a keep-alive connection forever.
- A time out occurred while waiting to read the next request or to read the remainder of the current request.
To set:
- Click through:
Servers > Application Servers > Web Container > HTTP Transports
- Click the port_number link in the Host column.
- Click Custom Properties > New.
- Enter the MaxKeepAliveConnections name in the Name field.
- Enter the value in the Value field
- Click Apply or OK.
- Click Save.
Recommended value: The value should be at least 90% of the maximum number of threads in the Web container thread pool, all the threads could be consumed by keep-alive connections leaving no threads available to process new connections.
MaxKeepAliveRequests
The maximum number of requests allowed on a single keep-alive connection. This parameter can help prevent denial of service attacks when a client tries to hold on to a keep-alive connection. The Web server plug-in keeps connections open to the appserver as long as it can, providing optimum performance.
To set:
- Click through:
- Click the port_number link in the Host column.
- Click Custom Properties > New.
- Enter the MaxKeepAliveRequests name in the Name field.
- Enter the value in the Value field
- Click Apply or OK.
- Click Save.
Servers > Application Servers > Web Container > HTTP Transports
A good starting value is 100. If the appserver requests are received from the plug-in only, increase this parameter's value.
URL invocation cache
The invocation cache holds information for mapping request URLs to servlet resources.
A cache of the requested size is created for each thread. The number of threads is determined by the Web container maximum thread size setting.
A larger cache uses more of the Java heap, so you might need to increase maximum Java heap size. For example, if each cache entry requires 2KB, maximum thread size is set to 25, and the URL invocation cache size is 100; then 5MB of Java heap are required.
If more than 50 unique URLs are actively being used (each JSP is a unique URL), increase this parameter.
To set: The size of the cache can be specified for the appserver along with other JDK parameters by:
- In the administrative console, click the appserver you are tuning.
- Click JVM Setting.
- Click Add in the System Properties section.
- Add the name invocationCacheSize and a value of 50.
- Click Apply to ensure that the changes are saved.
- Stop and restart the appserver.
Default value: 50
To view parameter utilization monitor heap statistics with TPV or by using the verbose:gc config setting.
Recommended value: 50 or more, depending on your number of unique URLs.
Related parameters: See Heap size settings
Allow thread allocation beyond maximum
When this option is selected, more Web container threads can be allocated than specified in the maximum thread size field.
To set:
- In the administrative console, select the appserver you are tuning.
- Click Web Container Service under Additional Properties.
- Click Thread Pool under Additional Properties.
- Select the checkbox Growable thread pool.
- Click Apply to ensure the changes are saved.
- Stop and restart the appserver.
Default value: The default value setting is "unchecked" (the thread pool can not grow beyond the value specified for the maximum thread size).
Recommended value: This option is intended to handle brief loads beyond the configured maximum thread size. However, use caution when selecting this option because too many threads can cause the system to overload.
Dynamic cache service
The dynamic cache service improves performance by caching the output of servlets, commands and JSP files. WAS consolidates several caching activities, including servlets, Web services, and WebSphere commands into one service called the dynamic cache. These caching activities work together to improve application performance, and share many config parameters, which are set in an appserver's dynamic cache service.
The dynamic cache works within an appserver JVM, intercepting calls to cacheable objects, for example, through a servlet's service() method or a command's execute() method, and either stores the object's output to or serves the object's content from the dynamic cache. Because J2EE applications have high read-write ratios and can tolerate small degrees of latency in the currency of their data, the dynamic cache can create an opportunity for significant gains in server response time, throughput, and scalability.
Security
This section discusses how various settings related to security affect performance.
Disabling security
Security is a global setting. When security is enabled, performance can be decreased between 10-20%. Therefore, disable security when not needed.
How to view or set: In the administrative console, click Security > Global Security. The checkboxes Enabled and Enforce Java 2 Security control global security settings.
Default value: By default, security is not enabled.
Fine-tune the security cache time out for the environment
If WAS security is enabled, the security cache time out can influence performance. The time out parameter specifies how often to refresh the security-related caches.
Security information pertaining to beans, permissions, and credentials is cached. When the cache time out expires, all cached information becomes invalid. Subsequent requests for the information result in a database lookup. Sometimes, acquiring the information requires invoking a Lightweight Directory Access Protocol(LDAP)-bind or native authentication. Both invocations are relatively costly operations for performance.
Determine the best trade-off for the application, by looking at usage patterns and security needs for the site.
In a 20-minute performance test, when the cache time out was set so that a time out did not occur, a 40% performance improvement was achieved.
To set: click Security > Global Security > Cache Timeout.
Default value: The default is 600.
Security cache types and sizes (system parameters)
The following system properties determine the initial size of the primary and secondary Hashtable caches, which affect the frequency of rehashing and the distribution of the hash algorithms. The larger the number of available hash values, the less likely a hash collision will occur, and more likely a slower retrieval time. If several entries compose a Hashtable cache, creating the table in a larger capacity allows the entries to be inserted more efficiently rather than letting automatic rehashing determine the growth of the table. Rehashing causes every entry to be moved each time.
com.ibm.websphere.security.util.LTPAAuthCacheSize
Stores basic authentication credentials at the Security Server. Whenever an Lightweight Third Party Authentication (LTPA) token expires, a new token is generated from the basic authorization credentials in this cache. If no basic authorization credentials exist, the requesting browser must send the basic authorization credentials to the Security Server. The browser will prompt the user for user ID and password if no cookie exists containing the credentials.
com.ibm.websphere.security.util.LTPATokenCacheSize
Stores LTPA credentials in the cache using the LTPA token as a lookup value. When using an LTPA token to log in, the LTPA credential is created at the Security Server for the first time. This cache prevents the need to go to the Security Server on subsequent logins using an LTPA token.
com.ibm.websphere.security.util.CredentialCacheSize
Given the user ID and password for login, this cache returns the concrete credential object, either Local OS or LTPA, without the need to repeat authentication at the Security Server. If the credential object has expired, the need to repeat authentication is required.
com.ibm.websphere.security.util.LTPAValidationCacheSize
Given the credential token for login, this cache returns the concrete LTPA credential object, without the need to revalidate at the Security Server. If the token has expired, the need to revalidate is required.
com.ibm.websphere.security.util.PermissionCacheSize
Holds the WAS permission objects retrieved when a getGrantedPermissions method is called. If access to the same resource by the same principal occurs again, the permissions will be retrieved rapidly from the cache instead of going to the repository on the administrative server. This cache is common to both EJB and Web-granted permissions.
com.ibm.websphere.security.util.AdminBeanCacheSize
Stores information, including the required permissions, about EJBs that have been deployed in the administrative server.
com.ibm.websphere.security.util.BeanCacheSize
Stores information, including the required permissions and RunAs mode, about EJBs that have been deployed in a container on the appserver.
Configure SSL sessions appropriately
The SSLV3Timeout value specifies the time interval after which SSL sessions are renegotiated.
This is a high setting, and modification probably does not provide any significant impact. By default, it is set to 9600 seconds.
The Secure Association Service (SAS) feature establishes an SSL connection only if it goes out of the JVM to another JVM. Therefore, if all the beans are co-located within the same JVM, the SSL used by SAS is not expected to hinder performance.
To set modify the SSLV3Timeout and other SAS properties by editing sas.server.props and sas.client.props files. The files are located in the product_installation_root\properties directory, where product_installation_root is the directory where WAS is installed.
Default value: The default is 9600 seconds.
Object Request Broker (ORB)
Several settings are available for controlling internal Object Request Broker (ORB) processing. You can use these to improve application performance in the case of applications containing EJBs.You can change these settings for the default server or any appserver configured in the administrative domain.
To change the settings, click Servers > Application Servers. Then, click ORB Service from Additional Properties.
Pass-by-value versus pass-by-reference (NoLocalCopies)
For EJB 1.1 beans, the EJB 1.1 specification states that method calls are to be pass-by-value. For every remote method call, the parameters are copied onto the stack before the call is made. This can be expensive. The pass-by-reference, which passes the original object reference without making a copy of the object, can be specified.
For EJB 2.0 beans, interfaces can be local or remote. For local interfaces, method calls are pass-by-reference, by default.
Actual benefit observed: If the EJB client and EJB server are installed in the same WAS instance, and the client and server use remote interfaces, specifying pass-by-reference can improve performance up to 50%.
Pass-by-reference helps performance only in the case where non-primitive object types are being passed as parameters. Therefore, int and floats are always copied, regardless of the call model.
WARNING: Pass-by-reference can be dangerous and can lead to unexpected results. If an object reference is modified by the remote method, the change might be seen by the caller.
How to view or set:
- Click through:
Servers > Application Servers | appserver | Additional Properties | ORB Service
- Select Pass by Reference.
- Click OK and Apply to save the changes.
- Stop and restart the appserver.
The default value Pass-by-value for remote interfaces, pass-by-reference for EJB 2.0 local interfaces.
If the appserver expects a large workload for EJB requests, the ORB config is critical. Take note of the following properties:
com.ibm.CORBA.ServerSocketQueueDepth
This property corresponds to the length of the TCP/IP stack listen queue and prevents WAS from rejecting requests when there is not space in the listen queue.
If there are many simultaneous clients connecting to the server-side ORB, this parameter can be increased to support the heavy load up to 1000 clients.
To set the property:
- Click through:
Servers > Application Servers | appserver | Additional Properties | Process Definition | Java Virtual Machine
- Type...
... in the Generic JVM Properties field.-Dcom.ibm.CORBA.ServerSocketQueueDepth=200.
Default value: 50
com.ibm.CORBA.MaxOpenConnections and Object Request Broker connection cache maximum
This property has two names and corresponds to the size of the ORB connection table. The property sets the standard for the number of simultaneous ORB connections that can be processed.
If there are many simultaneous clients connecting to the server-side ORB, this parameter can be increased to support the heavy load up to 1000 clients.
To set:
- Click through:
Servers > Application Servers | appserver | Additional Properties | ORB Service
- Update the Connection cache maximum field
- Update the Connection cache maximum field
- Click Apply to save the changes.
- Restart the appserver.
Default value: 240
ORB thread pool size
This property relates to the size of the ORB thread pool. A worker thread is taken from the pool to process requests from a given connection.
If there are many simultaneous clients connecting to the server-side ORB, this parameter can be increased to support the heavy load up to 1000 clients.
To set:
- In the administrative console, select the appserver you are tuning and then click the Services tab.
- Click Servers > Application Servers.
- Click the appserver you want to tune.
- Click the ORB Service under Additional Properties.
- Click Thread Pool under Additional Properties.
- Update the Maximum Size field and click OK.
- Click Apply to save the changes.
- Restart the appserver.
Default value: 50
Java Virtual Machines (JVMs)
Tuning the JVM
The JVM offers several tuning parameters affecting startup of the WebSphere Application Servers and application. You can also increase the value of the minimum heap size. The minimum size can be set between 60MB and less than or equal to the maximum value. Then, the number of garbage
Quick Start option
A method selected for compilation is compiled initially at a lower optimization than in default mode, and later, depending on some sampling results, can be recompiled to the level of the initial compile in default mode. This feature is only available on the Windows platform for 1.3.1. In the 1.4 JRE, the full framework is available on all platforms.
Quickstart is useful for applications where early moderate speed is more important than longrun throughput, as in some debug scenarios, test harnesses, and short-running tools.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Enter the value -Xquickstart in the Generic JVM Arguments field.
- Click Apply or OK.
- Save your changes.
- Stop and restart the appserver.
Actual benefit observed: Gains between 15-20% in startup time are possible. Also, by adding -DCOPT_NQREACHDEF, another 15% boost can be achieved.
Avoiding class verification
This parameters skips the class verification stage during class loading, saving you overhead.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Enter the value -Xverify:none in the Generic JVM Arguments field.
- Click Apply or OK.
- Save your changes.
- Stop and restart the appserver.
Actual benefit observed: When using this value with the JIT on, gains are between 10-15% in startup time.
Sun JDK 1.3 HotSpot -server warmup
The HotSpot JVM introduces adaptive JVM technology containing algorithms for optimizing byte code execution over time. The JVM runs in two modes, -server and -client. Performance is significantly enhanced if running in -server mode and a sufficient amount of time is allowed for a HotSpot JVM to warmup by performing continuous execution of byte code.
In most cases, -server mode should be run. This produces more efficient run time execution over extended periods. The -client option can be used if a faster startup time and smaller memory footprint are preferred, at the cost of lower extended performance.
How to view or set: Follow these steps to change the -client or -server mode:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine > Custom Properties under Additional Properties.
- Select New and enter HotSpotOption in the Name field. Enter -client or -server in the Value field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: -server
How to view parameter utilization: Monitor the process size and the server startup time to check the difference between -client and -server.
Recommended value: -server
Sun JDK 1.3 HotSpot new generation pool size
Most garbage collection algorithms iterate every object in the heap to determine which objects to free. The HotSpot JVM introduces generation garbage collection which makes use of separate memory pools to contain objects of different ages. These pools can be garbage collected independently from one another. The sizes of these memory pools can be adjusted. Extra work can be avoided by sizing the memory pools so that short-lived objects will never live through more than one garbage collection cycle.
If garbage collection has become a bottleneck, try customizing the generation pool settings.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine > Custom Properties under Additional Properties.
- Enter the following values in the Generic JVM Arguments field: -XX:NewSize (lower bound), -XX:MaxNewSize (upper bound)
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default values: NewSize=2m, MaxNewSize=32m
How to view parameter utilization: You can monitor garbage collection statistics using object statistics in TPV or the verbose:gc config setting.
Recommended value: Bound the new generation between 25 to 50% the total heap size.
Related parameters: Heap size settings
Just In Time (JIT) compiler
The Just In Time (JIT) compiler can significantly affect performance.
In all cases, run with JIT enabled, which is the default. To disable JIT:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Select the checkbox Disable JIT.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: JIT is enabled.
How to view parameter utilization: Disabling the JIT compiler decreases throughput noticeably. To see the current setting, follow the steps above.
Recommended value: Run with the JIT enabled (the check box should be clear).
Heap size settings
These parameters can set the maximum and initial heap sizes for the JVM.Increasing the heap size can improve startup.
In general, increasing the size of the Java heap improves throughput until the heap no longer resides in physical memory. After the heap begins swapping to disk, Java performance drastically suffers. Therefore, the maximum heap size needs to be low enough to contain the heap within physical memory.
The physical memory usage must be shared between the JVM and the other applications, such as, the database. For assurance, use a smaller heap, for example 64MB, on machines with less memory.
Try a maximum heap of 128MB on a smaller machine, that is, less than 1GB of physical memory, 256MB for systems with 2GB memory, and 512MB for larger systems. The minimum heap size depends on the application. Setting the minimum heap size equal to the maximum avoids the onset of garbage collection activity. Subsequent garbage collection cycles are fewer, but have a longer duration that can affect performance.
If performance runs are being conducted and highly repeatable results are needed, set the initial and maximum sizes to the same value. This setting eliminates any heap growth during the run. For production systems where the working set size of the Java applications is no understood, an initial setting of one-fourth the maximum setting is a good starting value. The JVM tries to adapt the size of the heap to the working set of the Java application.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Enter values in the General Properties field for the following fields: Initial Heap Size and Maximum Heap Size.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default values:
- Minimum heap size: Default or zero
- Maximum heap size: 256 MB
To view parameter utilization: You can monitor garbage collection statistics using object statistics in TPV or by using the verbose:gc config setting.
Recommended values:
- Minimum heap size: Default or zero. To improve startup time, set the minimum heap size between 60MB and less than or equal to the maximum value.
- Maximum heap size: Machine-specific or should be low enough to avoid paging, or swapping out memory to disk.
Related parameters: See the topic Tuning Java memory for more information.
Actual benefit observed: When using the heap size parameter to improve startup, the number of garbage collection occurrences are reduced and a gain of 10% improvement is seen.
Class garbage collection
Disabling class garbage collection makes class reuse more available. Performance improvement is small.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Enter the value -Xnoclassgc in the Generic JVM Arguments field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: Class garbage collection enabled.
How to view parameter utilization: You can monitor garbage collection statistics using the verbose:gc config setting. Output from verbose:gc also includes class garbage collection statistics.
Recommended value: Enabled
Related parameters: Heap size settings
Garbage collection policy
The algorithm used by the garbage collector is "mark-and-sweep." In the IBM JDK 1.3.1, concurrent marking performs marking of application threads starting from the stack even before the heap becomes full. In doing so, the garbage collector pauses become uniform and long-time pauses are not apparent.
How to view or set: Concurrent marking is done if the gcpolicy is set to optavgpause. The tradeoff is reduced throughput because threads might have to do extra work.
Default value: Concurrent marking disabled
Recommended value: Use concurrent marking only if there is high variability in the response time in a given application.
Garbage collection threads
You can have several garbage collection threads. This is called parallel garbage collection. It is advisable to use this option if your machine has more than 1 processor. This is only applicable for IBM JDK 1.3.
How to view or set:
Set the value corresponding to the number of processors.
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Enter the value -Xgcthreads=[number_of_processors] in the Generic JVM Arguments field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Heap compaction
Heap compaction is the most expensive garbage collection operation. In IBM JDK 1.3.1, compaction is avoided as much as possible. If you disable heap compaction, you will eliminate all associated overhead.
How to view or set:
Set the value corresponding to the number of processors.
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine under Additional Properties.
- Enter the value -Xnocompactgc in the Generic JVM Arguments field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Initial system heap size
Set the initial system heap size where class objects are stored. The method definitions and static fields are also stored with the class objects. Although the size the system heap has no upper bound, set the initial size correct so that you do not incur the cost of expanding the system heap size, which involves calls to the operating system memory manager. You can compute a good initial system heap size by knowing the number of classes loaded in the WebSphere product, which is about 8,000 classes, and their average size. Having knowledge of the application classes allows you to include them in the calculation.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine.
- Enter the value -Xinitsh in the Generic JVM Arguments field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Thread local heap size
The thread local heap is a portion of the heap that is allocated exclusively for a thread. Because of the thread local heap size, the thread does not need to lock the entire heap when allocating objects. However, when the thread local heap gets full, object allocation is done from the heap that then needs to be synchronized. Thus, a good size for the local cache is critical to good performance. This requires knowledge of the application’s use of objects.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine.
- Enter the value -Xmc in the Generic JVM Arguments field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Local cache object allocation
Set the limit of an object size to be allocated from the local cache. Objects that exceed the limit size need to be allocated in the regular heap. Note that you want objects to be allocated from the local cache as much as possible. Otherwise the local cache depletes since it does not grow dynamically. If you know that some objects are going to be very large, you might want to allocate them from the regular heap.
How to view or set:
- Click Servers > Application Servers > server_name.
- Click the Process Definition > Java Virtual Machine.
- Enter the value -Xml in the Generic JVM Arguments field.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
EJB container
Cache settings
To determine the cache absolute limit, multiply the number of EJBs active in any given transaction by the total number of concurrent transactions expected. Then, add the number of active TPV to view bean performance information.
How to view or set: Edit the EJB container service properties for the appserver you are tuning.
Default value: Cache size=2053, Cache clean-up interval=3000
Break CMP EJBs into several EJB modules
The load time for hundreds of beans can be improved by distributing the beans across several JAR files and packaging them to an EAR file. This is faster when the administrative server attempts to start the beans, for example, 8-10 minutes versus more one hour when one JAR file is used.
XML parser selection
Add XML parser definitions to the jaxp.properties file and xerces.properties file found in the ${WAS_HOME}/jre/lib directory to help facilitate server startup. The XMLParserConfiguration value might have to be changed as new versions of Xerces are provided.
How to view or set:In both files, insert the following lines:
javax.xml.parsers.SAXParserFactory=org.apache.xerces.jaxp.SAXParserFactoryImpl
javax.xml.parsers.DocumentBuildFactory=org.apache.xerces.jaxp.DocumentBuilderFactoryImpl
org.apache.xerces.xni.parser.XMLParserConfiguration=org.apache.xerces.parsers.StandardParserConfiguration
Data sources
Connection pool size
When accessing any database, the initial database connection is an expensive operation. WAS supports JDBC 2.0 Standard Extension APIs to provide support for connection pooling and connection reuse. The connection pool is used for direct JDBC calls within the application, as well as for EJBs using the database.
If clones are used, one data pool exists for each clone. This is important when configuring the database server maximum connections.
Actual benefit observed: When the connection pooling capabilities are used, performance improvements, up to 20 times the normal results, are realized.
How to view or set: Use the administrative console to specify the database connection pool options.
Default value: Minimum connection pool size: 1, Maximum connection pool size: 10
To view parameter utilization use the TPV:
- Start the TPV.
- Select the appserver you are tuning.
- Expand the database connection pools category.
- Select the data source.
- Click the data source and set to high. High is necessary to obtain the percentUsed counter.
- Click Run to start collecting statistics, and observe the following:
Pool size Average number of connections in the pool to the database Percent used Average percent of the pool connections in use Concurrent waiters Average number of threads waiting for a connection Use TPV to find the optimal number of connections in pool. If the number of concurrent waiters is greater than 0 but CPU load is not close to 100%, consider increasing the connection pool size. If Percent Used is consistently low under normal workload, consider decreasing the number of connections in the pool.
Recommended value: Better performance is achieved if the value for the connection pool size is set lower than the value for the Max Connections in the Web container. Lower settings (10-30 connections) typically perform better than higher (more than 100) settings.
On UNIX platforms, a separate DB2 process is created for each connection. These processes quickly affects performance on systems with low memory, causing errors.
Each Entity EJB transaction requires an additional connection to the database specifically to handle the transaction. Be sure to take this into account when calculating the number of data source connections.
Deadlock can occur if the application requires more than one concurrent connection per thread, and the database connection pool is not large enough for the number of threads. Suppose each of the application threads requires two concurrent database connections and the number of threads is equal to the maximum connection pool size. Deadlock can occur when both of the following are true:
- Each thread has its first database connection, and all are in use.
- Each thread is waiting for a second database connection, and none would become available since all threads are blocked.
To prevent the deadlock in this case, the value set for the database connection pool must be at least one higher, one of the waiting threads to complete its second database connection and free up to allow database connections.
To avoid deadlock, code the application to use, at most, one connection per thread. If the application is coded to require C concurrent database connections per thread, the connection pool must support at least the following number of connections, where T is the maximum number of threads.
T * (C - 1) + 1
The connection pool settings are directly related to the number of connections that the database server is configured to support. If the maximum number of connections in the pool is raised, and the corresponding settings in the database are not raised, the application fails and SQL exception errors are displayed in the stderr.log file. Prepared statement cache size, and Number of connections to DB2
Prepared statement cache size
A prepared statement is a precompiled SQL statement that is stored in a prepared statement object. This object is used to efficiently execute the given SQL statement multiple times.
Actual benefit observed: In test applications, tuning the prepared statement cache improved throughput by 10-20%.
How to view or set in the administrative console click Resources > JDBC Providers > provider_name > Data source > data_source_name > Statement Cache Size. The Statement Cache Size field contains a value that is the total cache size.
Recommended value: If the cache is not large enough, useful entries are discarded to make room for new entries. In general, the more prepared statements your application has, the larger the cache should be. For example, if the application has 5 SQL statements, set the prepared statement cache size to 5, so that each connection has 5 statements.
TPV can help tune this setting to minimize cache discards. Use a standard workload that represents a typical number of incoming client requests, use a fixed number of iterations, and use a standard set of config settings. Note: The higher the prepared statement cache is the more system resources are delayed. Therefore, if you set the number too high, you could lack resources because your system is not able to open that many prepared statements.
Follow these instructions to use the TPV:
- Start TPV.
- Click host > server > JDBC Connection Pools > jdbc_provider.
- Before starting the benchmark workload, right-click driver and select Clear Values.
- (Optional) Right-click driver and select Reset to Zero.
- Start the workload and run to completion. After the workload finishes, record the value reported for PrepStmt Cache Discards.
- Stop the appserver and make the following adjustments: Click Data Source > Connection Pooling > Statement Cache Size value.
- Rerun the workload and record the TPV value reported for PrepStmt Cache Discards.
The best value for Data Source > Connection Pooling > Statement Cache Size is the setting used to get either a value of zero or the lowest value for PrepStmt Cache Discards. This setting indicates the most efficient number for a typical workload. Thread pool, and Connection pool size
Java Messaging Service
Properly tuning the Java Messaging Service (JMS) in WAS can provide performance improvement up to two times, depending on the system specifications and application.
Message listener service
Maximum sessions
Each session corresponds to a single listener thread, but does not control the number of concurrently processed messages.
Adjust this parameter when message order is not a strict requirement. This parameter also helps to add some level of concurrency so that receiving a message can be done concurrently before the synchronized part of receiving the message occurs.
To set:
- Click through
Servers | Application Servers | server_name | Message Listener Service | Listener Ports
- Enter the value of message listener service.
- Click Apply and Save.
- Cycle the appserver.
Default value: 1
Recommended value: If message concurrency is desired, that is multiple messages processed simultaneously, set the value to 2-4 sessions per system processor. Keep the value as low as possible to eliminate client thrashing. If a strict message order is desired, set the value to 4 so there is always a thread waiting in a hot state, blocked on receiving the message.
Maximum messages
Controls the maximum number of concurrently processed messages.
Adjust this parameter when message order is not a strict requirement. This parameter controls the concurrency level in the listener service.
How to view or set:
- Open the administrative console.
- Click Servers > Application Servers > server_name.
- Click the Message Listener Service > Listener Ports.
- Enter the value of maximum number of messages.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: 1
Recommended value: If message concurrency is desired, that is multiple messages processed simultaneously, set the value to 2-4 sessions per system processor. Keep the value as low as possible to eliminate client thrashing. If a strict message order is desired, set the value to 1.
Thread pool size
Controls the maximum number of threads the Message Listener Service is allowed to run.
Adjust this parameter when multiple MDBs are deployed in the same appserver and the sum of their maximum session values exceeds the default value of 10.
How to view or set:
- Open the administrative console.
- Click Servers > Application Servers > server_name.
- Click the Message Listener Service > Thread Pool.
- Enter the value of maximum number of threads.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: minimum=10 maximum=50
Recommended value: Set the minimum to the sum of all MDB’s maximum sessions values. Set the maximum value to anything equal to or greater than the minimum.
Non-Application Server Facilities operation mode
The JMS server has two modes of operation, Application Server Facilities (ASF) and non-ASF. ASF is meant to provide concurrency and transactional support for applications. Non-ASF bypasses that support to streamline the path length.
Use this parameter if message order is a strict requirement. This parameter should also be used when concurrent PTP messages are desired. Do not use this parameter if concurrent publications and subscriptions messages are desired because ASF provides better throughput.
To set:
- Click through:
Servers | Application Servers | server_name | Message Listener Service | Custom Properties
- If the property non.asf.receive.timeout exists and has a value greater than 0, use non-ASF mode.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: ASF mode (custom property not created)
Recommended value: The value is the number of milliseconds to wait for a message to be delivered. If the timeout occurs, it must recycle causing extra work. This should be set to under the transaction timeout, but close to it with several (10 or more) seconds to spare. The seconds to spare should be more if under extreme loads which threads may be waiting long periods of time to get CPU cycles.
Embedded JMS server
Number of threads
With the embedded JMS publications and subscriptions server, this value is the number or threads to use for the publications and subscriptions matching engine, which matches publications to subscribers.
Use this parameter when concurrent publications and subscriptions exist that would exceed the capacity of the default value.
To set:
- Click thru:
Servers | Application Servers | server_name | Server Component | JMS servers.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: 1
Recommended value: Set this value to a little higher than the number of concurrent message publishers. If large numbers of subscribers exist, increasing this value more can also provide some benefit.
JMS resources
XA enabled
Controls if the appserver uses an XA Queue/Topic Connection Factory under the covers. Use this parameter if multiple resources are not used in the same transaction.
To set:
- Click through
Resources | WebSphere MQ JMS Provider | Queue/Topic Connection Factories | Queue/Topic Connection Factory Name
- Select or deselect the checkbox to enable or disable.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: Enable
Recommended value: Do not enable when the message queue or topic received is the only resource in the transaction. Enable this parameter when other resources including other queues or topics are involved.
Connection pool size
Controls the size of the connection pool on a per queue or topic basis.
Use this parameter if concurrent server-side access to the JMS resource exceeds the default value.
How to view or set:
- Click through:
Resources | WebSphere MQ JMS Provider | Queue/Topic Connection Factories | Queue/Topic Connection Factory Name | Connection Pools
- Enter the size of connection pool.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: minimum=1 maximum=10
Recommended value: The minimum value should be the sum of all concurrently processed server-side messaging threads to that particular queue or topic. This includes both message producers and consumers on the server, not the client side.
Queue connection factory transport type
The external JMS provider controls the communication protocols between JMS clients, both server side and client side. CLIENT is a typical TCP based protocol which can send/receive requests over a network.
BINDINGS is a shared memory protocol that can only be used when the queue manager is on the same node/machine as the JMS client and comes at some security risks that need be addressed through the use of EJB roles.
Use this parameter when you are want to deal with the security issues and the client is local to the queue manager node.
To set:
- Click through
Resources | WebSphere MQ JMS Provider | WebSphere MQ Queue Connection Factories | Queue/Topic Connection Factory
- Enter the protocol type.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: CLIENT
Recommended value: BINDINGS is faster by 30% or more, lacks security that must be dealt with in other means. If you want to deal with the security concerns, BINDINGS is more desirable than CLIENT.
Topic connection factory transport type
Controls the communication protocol between JMS client and JMS Server. BINDINGS can only be used for the external JMS provider and is a shared memory communication protocol. BINDINGS can only be used with the external provider where the queue manager is on the local node. It also bypasses security, so additional measures must be taken to address security through EJB Roles and such. QUEUED is a standard TCP protocol. DIRECT is a lightweight sockets protocol for use in nontransactional, nondurable, nonpersistent Pub/Sub messaging, but only worked for clients and MDBs using the non-ASF protocol.
Use this parameter when using non-ASF nonpersistent, nondurable, nontransactional messaging or when the queue manager is local and willing to deal with the additional security tasks.
How to view or set:
- Click through:
Resources > WebSphere MQ JMS Provider > WebSphere MQ Queue Connection Factories > Queue/Topic Connection Factory Name
- Enter the protocol type.
- Click Apply or OK.
- Click Save.
- Stop and restart the appserver.
Default value: QUEUED
Recommended value:
- DIRECT is the fastest and should be used where possible.
- BINDINGS should be used when you want to deal with additional security tasks and the queue manager is local to the JMS client.
- QUEUED is the fallback for all other cases.
Note that until MQ5.3 CSD2, DIRECT can lose messages when under load and used with MDBs. This also happens with client-side based applications unless the broker’s maxClientQueueSize is set to 0. This is done with the command
wempschangeproperties nodename
-e default
-o DynamicSubscriptionEngine
-n maxClientQueueSize
-v 0
-x ExecGroupUUID
Where the executionGroupUUID can be found by starting the broker and looking in the Event Log/Applications for event 2201. This is usually ffffffff-0000-0000-0000-000000000000.
WebSphere MQ
WebSphere MQ and associated data files should be located away from any other disk input or output on the fastest disk available. RAID is recommended. Default locations are /opt/mqm and /var/mqm.
Log file pages
Controls the size of the queue mangers log files in number of pages.
Use this parameter when high volumes of messages are being sent through a server.
To set
QueueManager | QM_name | Log | LogBufferPages
For embedded JMS, set the LogFilePages to the desired value. Then, run the deletemq and createmq commands in the WASHome\bin directory to delete or recreate the queue manager. For external JMS, set LogFilePages to the desired value. Do this before creating the queue manager
MQSeries | CurrentVersion | Configuration | Log Defaults
Then, run the amqmdain regsec command to secure the registry value and create the queue manager.
Default value: external: 256 embedded: 512
Recommended value: Set the value to its maximum of 16384 pages, because there is no performance penalty for setting this value too high.
Log buffer pages
Controls the size of the queue mangers buffer to log file writes in number of pages.
Use this parameter when high volumes of messages are being sent through a server.
To set: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > Log > LogFilePages
For embedded JMS, edit the createmq.properties setting LogFilePages in the WASHome\properties directory to the desired value.
Then, run the deletemq and createmq commands to delete or recreate the queue manager. For external JMS, set LogFilePages to the desired value. Do this before creating the queue manager in the registry at...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > Log Defaults > LogFilePagesThen, run the amqmdain regsec command to secure the registry value and create the queue manager.
Default value: 0
Recommended value: Set the value to its maximum of 512 pages, because there is no performance penalty for setting this value too high.
Log primary files
Controls the number of primary or permanent log files for the queue manager.
Use this parameter when high volumes of messages are being sent through a server.
How to view or set: Windows: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > Log > LogPrimaryFiles
For embedded JMS, edit the createmq.properties setting LogPrimaryFiles in the WASHome\properties directory to the desired value. Then, run the deletemq and createmq commands to delete or recreate the queue manager. For external JMS, set LogPrimaryFiles to the desired value. Do this before creating the queue manager. Then, run the amqmdain regsec command to secure the registry value and create the queue manager.
Default value: external: 3 embedded: 0
Recommended value: Set the value to its maximum of 63 pages, because there is no performance penalty for setting this value too high.
Log secondary files
Controls the number of secondary log files for the queue manager. Secondary files are files created when the primary files are not enough and deleted when they are no longer needed.
Use this parameter when high volumes of messages are being sent through a server.
How to view or set: Windows: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > Log > LogSecondaryFiles
For embedded JMS, edit the createmq.properties setting LogSecondaryFiles in the WASHome\properties directory to the desired value. Then, run the deletemq and createmq commands to delete or recreate the queue manager. For external JMS, set LogSecondaryFiles to the desired value. Do this before creating the queue manager. Then, run the amqmdain regsec command to secure the registry value and create the queue manager.
Default value: external: 2 embedded: 60
Recommended value: There is a limit of 63 total files from the primary and secondary combined, and because secondary logs are slower, setting this value to 0 is ideal for performance.
Log default path
Controls the location of the queue manager’s log files.
Use this parameter when high volumes of messages are being sent through a server.
How to view or set: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > Log > LogDefaultPath
For embedded JMS, edit the createmq.properties setting LogPath in the WASHome\properties directory to the desired value. Then, run the deletemq and createmq commands to delete or recreate the queue manager. For external JMS, set LogDefaultPath to the desired value. Do this before creating the queue manager. Then, run the amqmdain regsec command to secure the registry value and create the queue manager.
Default value: WebSphereMQHome\log
Recommended value: WebSphere MQ tries to keep the head of the disk always positioned at the place in the file where it needs to write next, thus it is ideal to have a disk dedicated to this task. A fast RAID volume is best.
Default queue buffer size
Controls the size (in bytes) of an in-memory buffer for nonpersistent queues.
Use this parameter when large message sizes are used or large bursts of messages cause the queue to back up. If the queue backs up past this buffer, messages are flushed out to the disk.
How to view or set: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > TuningParameters > DefaultQBufferSize
Embedded JMS is not currently supported; you need MQ5.3 CSD2 and an accompanying Version 5.0 fix. For external JMS, set DefaultQBufferSize to the desired value. Do this before creating the queue manager. Then, run the amqmdain regsec command to secure the registry value and create the queue manager.
Default value: 64K (registry key does not exist)
Recommended value: Set this parameter to accommodate the typical number of messages sitting on the queue at any given time. This should be numberOfMessages*(500+messageSizeInBytes). This had a maximum value of 100MB, but typically around 1MB is enough.
Default persistent queue buffer size
Controls the size (in bytes) of an in-memory buffer for nonpersistent queues.Use this parameter whenever memory is available.
How to view or set: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > TuningParameters > DefaultPQBufferSize
Embedded JMS is not currently supported; you need MQ5.3 CSD2 and an accompanying Version 5.0 fix. For external JMS, set DefaultPQBufferSize to the desired value. Then, create the queue manager. This is a permanent queue setting, therefore, to change it the queue must be deleted and recreated.
Default value: 0 (registry key does not exist)
Recommended value: Set this parameter to accommodate the number of typical concurrently processed messages, plus a little more for read-ahead capabilities. This can be done by calculating numOfCocurrentMessages*(msgSizeInBytes+500)*2. Typically, 1MB is enough.
Maximum channels
Controls the allowable number of concurrent CLIENT transport clients.Use this parameter when large numbers of clients are being used.
How to view or set: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > Channels > MaxChannels
Embedded JMS is not currently supported; you need MQ5.3 CSD2 and an accompanying Version 5.0 fix. For external JMS, set MaxChannels to the desired value. Then, restart the queue manager.
Default value: external: 100 (registry key does not exist) embedded: 1000
Recommended value: Set this parameter high enough to contain the maximum number of concurrent JMS clients.
Channel application bind type
Controls if the channel application is an MQ FASTPATH application.Use this parameter at all times.
How to view or set: In the registry, navigate to...
HKEY_LOCAL_MACHINE > SOFTWARE > IBM > MQSeries > CurrentVersion > Configuration > QueueManager > QM_name > Channels > MQIBindType
Embedded JMS is not currently supported; you need MQ5.3 CSD2 and an accompanying Version 5.0 fix. For external JMS, set MQIBindType to the desired value. Then, restart the queue manager.
Default value: not FASTPATH (registry key does not exist)
Recommended value: FASTPATH
Transaction log path
Customizes the WebSphere transaction log location and size. When the application running on the WebSphere platform accesses more then one resource, WebSphere stores transaction information to properly co-ordinate and manage the distributed transaction. In a higher transaction load, this persistence slows down performance of the appserver due to its dependency on the operating system and the underlying storage systems. To achieve better performance, move the transaction log files to a storage device with more physical disk drives, or preferably RAID disk drives. When the log files are moved to the file systems on the raided disks, the task of writing data to the physical media is shared across the multiple disk drives. This allows more concurrent access to persist transaction information and faster access to that data from the logs. Depending upon the design of application and storage subsystem, performance gain can range from 10% to 100%, or even more in some cases.This change is applicable only to the config where the application uses distributed resources or XA transactions for example, multiple databases and resources are accessed within a single transaction. Consider setting this property when the appserver shows one or more of following signs:
- CPU utilization remains low despite an increase in transactions.
- Transactions fail with several time outs.
- Transaction rollbacks with “unable to enlist transaction” exception.
- AppServer hangs in middle of a run and requires the server to be restarted.
- The disk on which an appserver is running shows higher utilization.
How to view or set:
- Open the administrative console.
- Click Servers > Application Servers > server_name > Transaction Service.
- Enter the fully qualified path name you want to have for the log files’ location.
- (Optional) Enter the maximum size of the file by following the syntax [path];xxM Where path is the fully qualified path name and xx is the maximum size of the file in megabytes. The minimum value is 1.
- Click Apply or OK.
- Click Save.
- Stop and restart the server.
Default value: Initial value is the %WAS_HOME%\tranlog directory and a default size of 1MB.
Recommended value: Create a file system with at least 3-4 disk drives raided together in a RAID-0 config. Then, create the transaction log on this file system with the default size. When the server is running under load, check the disk input and output. If disk input and output time is more then 5%, consider adding more physical disks to lower the value. If disk input and output is low, but the server is still high, consider increasing the size of the log files.
DB2
DB2 has many parameters that can be configured to optimize database performance. For complete DB2 tuning information, refer to the DB2 UDB Administration Guide: Performance.
DB2 logging
DB2 has corresponding log files for each database that provides services to admins including viewing database access and the number of connections. For systems with multiple hard disk drives, large performance improvements can be gained by setting the log files for each database on a different hard drive from the database files.
How to view or set:
At a DB2 command prompt, issue the following command:
db2 update db cfg for [database_name] using newlogpath [fully_qualified_path]
Related parameters: See AIX with DB2.
DB2 Configuration Advisor
Located in the DB2 Control Center, this advisor calculates and displays recommended values for the DB2 buffer pool size, the database and database manager config parameters, with the option of applying these values. See more information about the advisor in the online help facility within the Control Center.
Use TCP sockets for DB2 on Linux
type="square">On Linux platforms, whether the DB2 server resides on a local machine with WAS or on a remote machine, configure the DB2 application databases to use TCP sockets for communications with the database.
How to view or set: The directions for configuring DB2 on Linux can be found in the WAS installation documentation for the various operating systems. This document specifies setting DB2COMM for TCP/IP and corresponding changes required in the etc/service file.
Default value: Shared memory for local databases
Recommended value: On Linux, change the specification for the DB2 application databases and any session databases from shared memory to TCP sockets.
DB2 MaxAppls
Related parameters: See Number of connections to DB2 >
DB2 MaxAgents
Related parameters: See Number of connections to DB2
DB2 buffpage
Buffpage is a database config parameter. A buffer pool is a memory storage area where database pages containing table rows or index entries are temporarily read and changed. The purpose of the buffer pool is to improve database system performance. Data can be accessed much faster from memory than from disk.
How to view or set: To view the current value of buffpage for database x, issue the DB2 command get db cfg for x and look for the value of BUFFPAGE.
To set BUFFPAGE to a value of n, issue the DB2 command update db cfg for x using BUFFPAGE n and be sure NPAGES is -1 as follows:
db2 <-- go to DB2 command mode, otherwise the following "select" will not work as is connect to x <-- (where x is the particular DB2 database name) select * from syscat.bufferpools (and note the name of the default, perhaps: IBMDEFAULTBP) (if NPAGES is already -1, you are OK and no need to issue following command) alter bufferpool IBMDEFAULTBP size -1 (re-issue the above "select" and NPAGES should now be -1)
To view parameter utilization collect a snapshot of the database while the application is running and calculate the buffer pool hit ratio.
- Collect the snapshot by issuing the following DB2 commands:
- update monitor switches using bufferpool on
- get monitor switches (To see that bufferpool monitoring is on)
- reset monitor all (To clear monitor counters)
- Run the application.
- Issue the following commands:
- get snapshot for all databases.
Issue this command before all applications disconnect from the database, otherwise statistics will be lost.
- update monitor switches using bufferpool off
- get snapshot for all databases.
- To calculate the hit ratio, look at the following snapshot statistics for the database:
- Buffer pool data logical reads
- Buffer pool data physical reads
- Buffer pool index logical reads
- Buffer pool index physical reads
The buffer pool hit ratio indicates the percentage of time that the database manager did not need to load a page from disk in order to service a page request. That is, the page was already in the buffer pool. The greater the buffer pool hit ratio, the lower the frequency of disk input/output. The buffer pool hit ratio can be calculated as follows:
P buffer pool data physical reads
+ buffer pool index physical readsL buffer pool data logical reads
+ buffer pool index logical readsHit ratio (1-(P/L)) * 100%
DB2 query optimization level
When a database query is executed in DB2, various methods are used to calculate the most efficient access plan. The query optimization level parameter sets the amount of work and resources that DB2 puts into optimizing the access plan. The range is from zero to 9.
An optimization level of 9 causes DB2 to devote a lot of time and all of its available statistics to optimizing the access plan.
How to view or set:
The optimization level is set on individual databases and can be set with
either the command line or with the DB2 Control Center. Static SQL statements use the optimization level specified on the prep and bind commands. If the optimization level is not specified, DB2 uses the default optimization as specified by the dft_queryopt parameter. Dynamic SQL statements use the optimization class specified by the current query optimization special register which is set using the SQL Set statement. For example, the following statement sets the optimization class to 1:
Set current query optimization = 1
If the current query optimization register has not been set, dynamic statements will be bound using the default query optimization class.
Default value: 5
Recommended value: Set the optimization level for the needs of the application. Use high levels should only when there are very complicated queries.
DB2 reorgchk
The performance of the SQL statements can be impaired after many updates, deletes or inserts have been made. Performance can be improved by obtaining the current statistics for the data and rebinding.
How to view or set:
Use the following DB2 command to issue runstats on all user and system tables for the database
you are currently connected to:
reorgchk update statistics on table all
You should then rebind packages using the bind command.
In order to see if runstats has been done, issue the following command on DB2 CLP:
db2 -v "select tbname, nleaf, nlevels, stats_time from sysibm.sysindexes"
If no runstats has been done, nleaf and nlevels will be filled with -1 and stats_time will have an empty entry "-".
If runstats was done already, the real-time stamp when the runstats was completed will also be displayed under stats_time. If you think the time shown for the previous runstats is too old, do runstats again.
DB2 MinCommit
This parameter allows you to delay the writing of log records to a disk until a minimum number of commits have been performed, reducing the database manager overhead associated with writing log records. For example, if MinCommit is set to 2, a second commit would cause output to the transaction log for the first and second commits. The exception occurs when a one-second time out forces the first commit to be output if a second commit does not come along within one second.
Actual benefit: In test applications, up to 90% of the disk input/output was related to the DB2 transaction log. Changing MinCommit from 1 to 2 reduced the results to 45%.
Try to adjust this parameter if the disk input/output wait is more than 5% and there is DB2 transaction log activity from multiple sources. When a lot of activity occurs from multiple sources, it is less likely that an single commit will have to wait for another commit (or the one-second time out). Do not adjust this parameter if you have a application with a single thread performing a series of commits (each commit could hit the one-second delay).
How to view or set: To view the current value for a particular database follow these steps:
- Issue the DB2 command get db cfg for xxxxxx (where xxxxxx is the name of the application database) to list database config parameters.
- Look for "Group commit count (MINCOMMIT)".
- Set a new value by issuing the DB2 command update db cfg for xxxxxx using mincommit n (where n is a value between 1 and 25 inclusive).
The new setting takes effect immediately.
The following are several metrics that are related to DB2 MinCommit:
- The disk input/output wait can be observed on AIX with the command vmstat 5. This shows statistics every 5 seconds. Look for the wa column under the CPU area.
- The percentage of time a disk is active can be observed on AIX with the command iostat 5. This shows statistics every 5 seconds. Look for the %tm_act column.
- The DB2 command get snapshot for db on xxxxxx (where xxxxxx is the name of the application database) shows counters for log pages read and log pages written.
Default value:The default value is 1.
Recommended value: MinCommit should be 1 or 2 (if the circumstance permits).
Session management
A detailed description of HTTP session management can be found within the InfoCenter under Applications > Web Modules > Managing HTTP sessions. Currently, the installed default settings are optimal for performance.
WAS Enterprises
Business process choreographer
Process MDB maximum sessions
Specifies the maximum number of concurrent JMS server sessions used by a listener to process messages.
Adjust this parameter when the machine running the process application does not realize the available capacity and produces less throughput by running long processes.
Benefit: The maximum number of concurrent JMS server sessions used by the process MDBs increase, resulting in higher message processing and application throughput. A 40% increase in throughput is observed in a process application with long running processes on a NetFinity 5500 500 MHz, 4-way, 4GB RAM system.
How to view or set: This parameter can be set with the server.xml file or through the administrative console.
In the server.xml file, change the max sessions parameter value as specified under listener ports stanza as follows:
<listenerPorts xmi:id="ListenerPort_1"
name="bpeIntListenerPort"
description="Internal Listener Port for Process Choreographer"
connectionFactoryJNDIName="jms/bpeCF"
destinationJNDIName="jms/bpeIntQueue"
maxSessions="5"
maxRetries="10"
maxMessages="1">
<stateManagement xmi:id="StateManageable_5" initialState="START"/>
</listenerPorts>To set this parameter:
- Click the listener ports where the process MDBs are configured.
- Adjust the value in the maximum sessions parameter to the recommended value of 15.
- Click Apply or OK.
- Click Save.
Servers --> Application Servers --> server_name --> Additional Properties --> Message Listener Service --> Listener Ports
Default value: 5
Recommended value: A value of 15 has given the best throughput with the above config. Based on the amount of work and the resources available, a value between 15 and 20 should be used to obtain maximum process throughput.
How to view parameter utilization: Use the Task Manager for Windows and topas on Unix to check the CPU utilization to check that the full system capacity is being utilized.
Related parameters: Prepared statement cache, Connection pool
Application profiling - Disabling
For applications with characteristics that lend themselves to application profiling, throughput and scalability are improved due to reduced database contention.
Disable application profiling when the service is not utilized by any applications.
Application profiling is configured at deploy time through the Application Assembly Tool (AAT). There are no tuning knobs to set to make the application profiling service itself run faster. If you do not plan to use application profiling, disable the service as follows:
- Open the administrative console.
- Click Servers > Manage Application Servers > server_name.
- Click Application Profiling under Additional Properties.
- Deselect the startup checkbox in the Application Profiling Service field under Additional Properties.
- Click Apply or OK.
- Click Save.
Default value: The application profile service is enabled by default, but no application profiles are configured. The default access intent policy is wsPessimisticUpdate-weakestLockAtLoad. This policy can be changed to a different access intent policy that suits the needs of the application. Refer to the InfoCenter for more information on the shipped access intent policies.
Recommended value: The recommended config varies by application, but the ideal Application Profile config assigns tasks (statically or programmatically) to specific methods. These tasks are propagated to the appserver, where the J2EE 1.3 programming model is flexible and there are many ways to configure an application. Each application must be evaluated on its own.
Activity sessions - Disabling
The activity session service provides an alternative unit-of-work (UOW) scope to that provided by global transaction contexts. An activity session context can live longer than a global transaction context and can encapsulate global transactions.
If applications are not using the activity session service, either through the UserActivitySession API or through deployment descriptors, and the activity session samples are not installed, the service should be disabled. Disabling the services provides slight performance improvement for remote requests.
How to view or set: Set this parameter by using the administrative console:
- Open the administrative console.
- Click the Servers > Manage Application Servers > server_name.
- Click ActivitySession service under Additional Properties.
- Select or clear the Startup checkbox.
- Click Apply or OK.
- Click Save.
Default value: Enable the activity session service at startup.
Default timeout value
The default time out for an activity session. Allows a server to reset an activity session if a remote client has failed to complete the activity session with this time period.
The time out value depends on the nature of the applications that are using activity sessions. The default value is a reasonable starting point. If you find that resources are being held for unreasonable periods because client initiated activity sessions are not being completed in a timely manner, you could be necessary to reduce this value.
To view or set:
- Open the administrative console.
- Click the appserver you are tuning.
- Click Activity Session Service.
- Reduce the time out value.
Dynamic query service
Dynamic query service simplifies the coding process and extends the capabilities of the EJB development process. Performance benefits are seen when the expanded functionality over EJB-QL allows the application to run smaller amounts and less complex data. An example of this is returning one field of an EJB, rather than returning a large amount of complex objects.
The dynamic query service is installed and the application started by default if it is selected in the installation process.
Parsing and building the query every time it is executed, rather than at deploy time, causes the development process to significantly slow down. Therefore, only use the dynamic query service when it is offset by the benefit of code simplification or added capabilities.
How to view or set: The dynamic query service is provided by an J2EE application installed during the Enterprise install process. It is accessed programmatically within other applications.
Sample: This is the code used to perform the field only retrieval using dynamic query:
The following code example from the Trade sample and retrieves a collection of String objects only, representing the symbols of the holdings, not the entire holding itself:
QueryHome aJQSHome = TradeStaticContext.getQueryHome(); Query aJQService = aJQSHome.create(); String query = "SELECT h.symbol FROMFROM TRADEHOLDINGBEAN h WHERE h.userID = ?1"; Object[] params = {userID}; QueryIterator itr = aJQService.execuPteQuery(query, params, null, 0, 50);
The equivalent non-Dynamic query code is as follows:
First define a query in ejb-jar.xml:
<query id="Query_1"> <description>Description</description> <query-method id="QueryMethod_1"> <method-name>findByUserID</method-name> <method-params> <method-param>java.lang.String</method-param> </method-params> </query-method> <ejb-ql>SELECT OBJECT(c) FROMFROM TRADEHOLDINGBEAN c WHERE c.userID = ?1</ejb-ql> </query>
Now utilize that query to get the same information:
HoldingHome hhome = TradeStaticContext.getHoldingHome(); java.util.Collection coll = hhome.findByUserID(userID); java.util.Iterator itr = coll.iterator(); while (itr.hasNext()) { Holding h = (Holding)itr.next(); v.addElement(h.getSymbol()); }
Additional references
- Performance Analysis for Java Web sites
- AIX documentation
-
WAS Development Best Practices for Performance and Scalability
Describes development best practices for both Webapps containing servlets, JSP files, and JDBC connections, and enterprise applications containing EJB components.
- iSeries performance documents
Includes WAS for iSeries Performance Considerations and links to the PTDV tool, Workload Estimator tool, and other documents.
- IBM WAS Advanced Edition Tuning Guide (Version 4.02)
- Redbook: WAS V3.5 Handbook (SG24-6161-00)
- Redbook: WAS V3 Performance Tuning Guide (SG24-5657-00)
Starting Windows Performance Monitor
From the Start menu choose
Programs > Administrative Tools > Performance Monitor
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both.
IBM is a trademark of the IBM Corporation in the United States, other countries, or both.
Tivoli is a trademark of the IBM Corporation in the United States, other countries, or both.
AIX is a trademark of the IBM Corporation in the United States, other countries, or both.