Session management
Overview
In many web applications, user choices or actions determine where the user is sent next, how the application behaves, or what the page displays. For example, if the user clicks a checkout button on a site, the next page must contain the user's shopping choices and information. The Java servlet specification provides a mechanism for servlet applications to maintain a user's state information. This mechanism, is known as a session. Sessions allow applications, running in a web container, to keep track of individual users.
A servlet distinguishes users by their unique session IDs. The session ID is stored as a cookie or alternatively can be conveyed to the servlet by URL rewriting.
Session identifiers
WAS passes the user an identifier known as a session ID, which correlates an incoming user request to a session object maintained on the server. The session ID arrives with each request.In accordance with the Servlet 2.3 API specification, the session management facility supports session scoping by web modules. Only servlets in the same web module can access the data associated with a particular session. Multiple requests from the same browser, each specifying a unique web application, result in multiple sessions with a shared session ID. We can invalidate any of the sessions that share a session ID without affecting the other sessions.
There are three approaches used in WAS for tracking sessions:
- Cookies
- URL rewriting
- SSL session identifiers (deprecated)
Deprecated feature: Session tracking using the SSL ID is deprecated in WAS 7.0. We can configure session tracking to use cookies or URL rewriting.
Cookies
WAS session support generates a unique session ID for each user and returns this ID to the user's browser with a cookie The default name for the session management cookie is JSESSIONID.
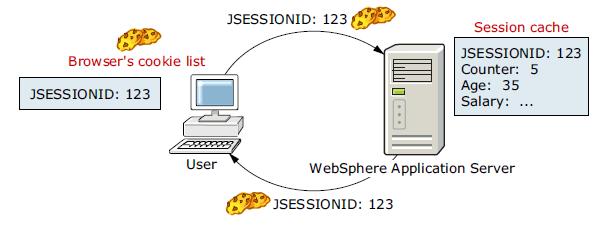
A cookie consists of information embedded as part of the headers in the HTML stream passed between the server and the browser. The browser holds the cookie and returns it to the server whenever the user makes a subsequent request. By default, WebSphere defines its cookies so they are destroyed if the browser is closed.
The web application developer uses the HTTP request object's standard interface to obtain the session.
//Suppose HttpServletRequest request has been initiated. HttpSession session = request.getSession(true); String sessionID = session.getId();
WebSphere places the user's session identifier in the outbound cookie when the servlet completes its execution, and the HTML response stream returns to the user.
URL rewriting
A typical usage of URL rewriting is configuring session tracking for Wireless Application Protocol (WAP) devices. Because most WAP devices do not support cookies, we can configure these devices to use URL rewriting to track sessions. URL rewriting requires the developer to perform the following actions:
- Use special APIs to encode the URLs.
- Set up the site page flow to avoid losing the encoded information.
Program session servlets to encode URLs
URL rewriting works by storing the session identifier in the page returned to the user. WAS encodes the session identifier as a parameter on URLs that are encoded programmatically by the web application developer.Web page link with URL encoding
<a href="/store/catalog;$jsessionid=DA32242SSGE2">
When the user clicks this link to move to the /store/catalog page, the session identifier is passed in the request as a parameter.
If the servlet returns HTML directly to the requester, without using JavaServer Pages (JSP), the servlet calls the API, to encode the returning content.
URL encoding from a servlet
//Suppose HttpServletResponse response has been initiated.
out.println("<a href=\");
out.println(response.encodeURL ("/store/catalog"));
out.println("\>catalog</a>");
The pages using redirection, servlet, or JSP must encode the session ID as part of the redirection.
URL encoding with redirection
//Suppose HttpServletResponse response has been initiated.
response.sendRedirect(response.encodeRedirectURL("http://myhost/store/catalog"));
Suppling a servlet or JSP file as an entry point
The entry point to an application, such as the initial window presented, might not require the use of sessions. However, if the application requires session support, after a session is created, all URLs are encoded to perpetuate the session ID for the servlet requiring the session support. The following syntax shows how we can embed Java code within a JSP file. JSP calls a similar interface to encode the session ID:
-
<% response.encodeURL ("/store/catalog"); %>
WAS inserts the session ID into dynamic pages but cannot insert the user's session ID into static pages, .htm, or .html.
Sessions invalidation
When the user no longer needs the session object (user logs off), the sessions belonging to that user can be invalidated. The invalidating process removes a session from the session cache and from the persistent store. WAS offers the following methods for invalidating session objects:
- On Demand
We can explicitly use the invalidate() command in application code to immediately invalidate the session object. If the session object is accessed by multiple threads in a web application, be sure that none of the threads still have references to the session object.
- Automated or Periodic
The session manager treats a session as a candidate for invalidation if it has not been accessed for a period longer than the specified session timeout. The session manager has an invalidation process thread that runs periodically to invalidate sessions that are eligible for invalidation.
In a distributed environment, one cluster member can be randomly chosen to act as the invalidator for the entire cluster. The cluster member can invalidate the session regardless of the session in which that cluster member was created.
- Scheduled invalidation
In a distributed environment, we can set specific times for the session management facility to scan for invalidated sessions instead of relying on the periodic invalidation timer.
Session listeners
Session listener classes are defined to listen for state changes of a session and its attributes.This listening allows control over interactions with sessions, so that programmers can monitor creation, deletion, and modification of sessions. With the help of listeners, programmers can perform initialization tasks when a session is created or can clean up tasks when a session is removed. It is also possible to perform some specific tasks for a session attribute when the attribute is added, deleted, or modified.
Table 28-1 Listener interfaces and their methods Target Event Interface Method Comments session create HttpSessionListener sessionCreated() To monitor creation and deletion, including session timeout. destroy HttpSessionListener sessionDestroyed() session activate HttpSessionActivationList ener sessionDidActivate() To monitor changes of session attributes, such as add, delete, and replace. passivate HttpSessionActivationList ener sessionWillPassivate() attribute add HttpSessionAttributeListe ner attributeAdded() To monitor sessions that are made active or that are made passive. remove HttpSessionAttributeListe ner attributeRemoved() replace HttpSessionAttributeListe ner attributeReplaced()
For more information, see the Java EE specifications at the following website:
Session security
We can integrate sessions and security in WAS. When session security (security integration) is enabled, the session manager checks the user ID of the HTTP request against the user ID of the session held within WAS.
This check is done as part of the processing of the request.getSession() function. If the check succeeds, the session data is returned to the calling servlet or JSP. If the check fails, WebSphere throws the com.ibm.websphere.servlet.session.UnauthorizedSessionRequestException.
The session security integration is enabled by default.
The identity or user name of a session can be accessed through the com.ibm.websphere.servlet.session.IBMSession interface. An unauthenticated identity is denoted by the user name anonymous.
Session management security uses the following rules:
- Sessions in unsecured pages are treated as accesses by the anonymous user.
- Sessions created in unsecured pages are created under the identity of that anonymous user.
- Sessions in secured pages are treated as accesses by the authenticated user.
- Sessions created in secured pages are created under the identity of the authenticated user. They can only be accessed in other secured pages by the same user. To protect these sessions from use by unauthorized users, they cannot be accessed from an unsecure page. Do not mix access to secure and unsecure pages.
Session management configuration
There are three levels of session management configuration:
When you configure session management at the web container level, all applications and the respective web modules in the web container normally inherit that configuration. However, we can set up different configurations individually for specific applications and web modules that vary from the web container default.
Session management properties
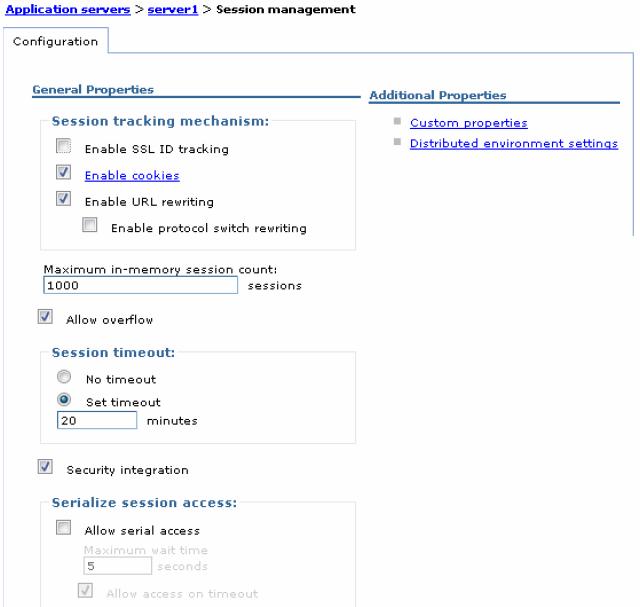
With the exception of the Overwrite session management parameter, the session management properties are the same at each configuration level. The following list describes the parameters available:- Overwrite session management determines whether these session management settings are used for the current module or inherited from the parent object.
Only the application level or the web module level have such parameters.
- Session tracking mechanism lets you select from cookies, URL rewriting, and SSL ID tracking.
Selecting cookies leads you to a second configuration page containing further configuration options.
- Maximum in-memory session count specifies the maximum number of sessions to keep in memory. Default is 1000 sessions:
- For local sessions, this value specifies the number of sessions in the base session table.
- For persistent sessions, this value specifies how many sessions are cached before manual updates or before the session manager reverts to reading a session from the persistent storage automatically.
- For local sessions, this value specifies the number of sessions in the base session table.
- Allow overflow specifies whether to allow the number of sessions in memory to exceed the value specified in the maximum in-memory session count field.
For local sessions, use the Allow overflow option to manage session storage. Sessions can either be limited to store in the primary cache table of the session manager, or optioned to allow additional sessions to be stored in secondary extended tables.
Allowing an unlimited amount of sessions can potentially exhaust system memory and even allow for system sabotage. For best performance, define a primary cache of sufficient size to hold the normal working set of sessions for a given application server.
- Session timeout specifies the amount of time to allow a session to remain idle before invalidation.
Default is 30 minutes. Important for performance tuning. It directly influences the amount of memory consumed by the JVM to cache the session information. Session timeout also impacts the session manager invalidation process time intervals. For the default timeout value, the invalidation process interval is around 300 seconds. Using default settings, it can take up to five minutes beyond the timeout threshold of thirty minutes for a particular session to become invalidated.
If you select the No timeout option, a session can never be removed from the memory unless explicit invalidation is performed. This persistent session can cause a memory leak when the user closes the window without logging out from the system. To use this option, verify enough memory or space in a persistent store is kept to accommodate all sessions.
- Security integration specifies the user ID be associated with the HTTP session.
Do not enable this property if the application server contains a web application that has form-based login configured as the authentication method and the local operating system is the authentication mechanism. Doing so causes authorization failures when users try to use the web application.
- Serialize session access determines if concurrent session access in a given JVM is allowed. Serialized access ensures thread-safe access when the session is accessed by multiple threads. No special code is necessary for using this option. This option is not recommended when user requests are issued frequently because it can affect performance.
We can set an optional property, the Maximum wait time, to specify the maximum amount of time that a servlet request waits on an HTTP session before continuing execution. The default value for this setting is five seconds.
- Distributed environment settings determines how to persist sessions (memory-to-memory replication or a database) and set tuning properties. For session recovery support, WAS provides distributed session support persist sessions replication. We can use session recovery support when the user's session data must be maintained across a server restart or when the user's session data is too valuable to lose through an unexpected server failure. Memory-to-memory persistence is available only in a ND distributed server environment.
- Custom properties specifies additional settings for session management.
Accessing session management properties
We can access all session management configuration settings using the administrative console.
We can change the configuration for the web container, enterprise application, or web module level. To make these changes use the following guidelines:
- Click...
-
Servers | Server Types | WebSphere application servers | server_name
- Under the Container Settings of the Configuration tab, click Session management. Or Under Container Settings, expand Web Container Settings, and click Web container. Under Additional Properties, click Session management.
- Click Applications | Application Types | WebSphere enterprise applications | application_name.
- Under Web Module Properties section of the Configuration tab, click Session management.
– An OSGi application:
- Click Applications | Application Types | Business-level applications | application_name | eba_asset_name.
- Under Additional Properties, click Session management.
- Web module level:
If the application is an enterprise application:
- Click Applications | Application Types | WebSphere enterprise applications | application_name.
- Under the Modules section of the Configuration tab, click Manage Modules | module_name.
- Under Additional Properties, click Session Management.
If you are working at the web module or application level and want these settings to override the inherited session management settings, under General Properties select Override session management.
Selecting session tracking options
To set or change the session mechanism type:
- Go to the appropriate level of Session Management
- Under General Properties, select the session tracking mechanism:
- To track sessions with cookies, select Enable Cookies.
- To change the cookie settings, click hot link of Enable Cookies.
- To track sessions with URL rewriting, select Enable URL Rewriting.
- To enable protocol switch rewriting, select Enable protocol switch rewriting.
This option defines whether the session ID, added to a URL as part of URL encoding, is included in the new URL if a switch from HTTP to HTTPS or from HTTPS to HTTP is required.
- To track sessions with SSL information, select Enable SSL ID tracking.
- Click OK and Save, and synchronize the configuration changes.
- Restart the application server or the cluster.
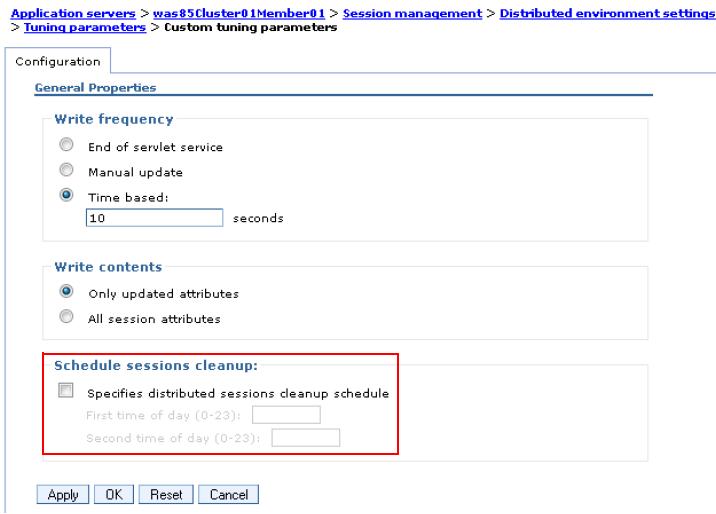
Scheduled invalidation configuration
To complete the schedule sessions cleanup setting...
- Go to the appropriate level of Session Management
- Under Additional Properties, click Distributed environment settings.
- Under Additional Properties, click Custom tuning parameters.
- Under General Properties, click Custom settings.
- Under Schedule sessions cleanup of General Properties
Cookie setting
When you select cookie as the session mechanism type, we can view or change the cookies settings by clicking the Enable Cookies hot link.
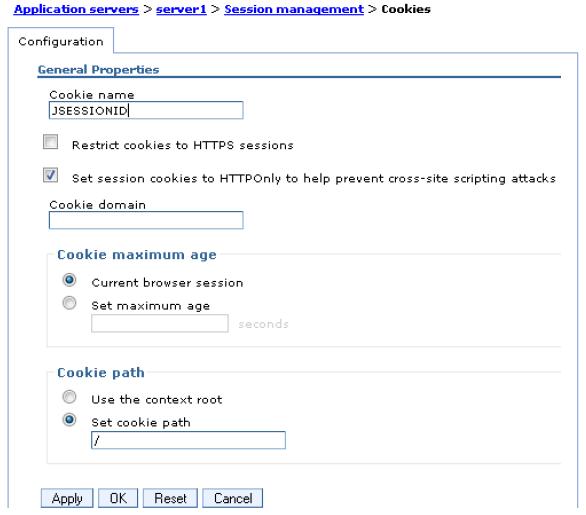
The available cookies settings...
- Cookie name
Unique cookie name for session management. Default is JSESSIONID.
- Restrict cookies to HTTPS sessions
Session cookies include the secure field. Enabling this feature restricts the exchange of cookies to HTTPS sessions only and the session cookie’s body includes the secure indicator field.
- Set cookies as HTTP only to help prevent cross-site scripting attacks
Session cookies include the HTTP only field. When checked, browsers that support the HTTP only attribute do not enable cookies to be accessed by client'side scripts. For security cookies, see the global security settings for web single sign-on (SSO).
- Cookie domain
Dictates to the browser whether to send a cookie to particular servers. For example, if we specify a particular domain, the browser sends back session cookies only to hosts in that domain. Default is the server.
The LTPA token or cookie sent back to the browser is scoped by a single DNS domain specified when security is configured. Thus, all application servers in an entire WAS domain must share the same DNS domain for security purposes.
- Cookie maximum age
Specifies the amount of time the cookie lives in the client browser. This option includes the following choices:
- Expire at the end of the Current browser session which is the default option.
- Expire by configuring Set maximum age
If you choose the maximum age option, specify the age in seconds. This value corresponds to the Time to Live (TTL) value described in the Cookie specification.
- Cookie path
Sets the paths on the server that define where the browser sends the session tracking cookie. Specify any string that represents a path on the server:
- Use the context root
- Set cookie path, which is also the default option (use the forward slash (/) to indicate the root directory).
Specify a value restricts the paths to which the cookie is sent. By restricting paths, we can keep the cookie from being sent to certain URLs on the server. If we specify the root directory, the cookie is sent no matter which path on the given server is accessed.
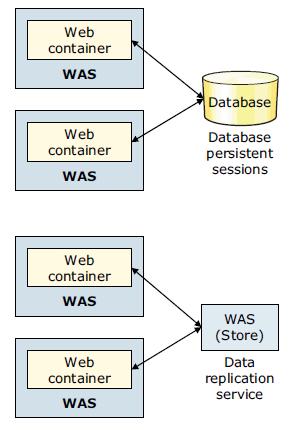
Storing session information
By default, WebSphere places session objects in memory as local session cache. However, the administrator can enable persistent session management to place session objects in a persistent store. Administrators must enable persistent session management in the following situations:
Local sessions
Many web applications use the simplest form of session management, which is the in-memory, local session cache. The local session cache keeps session information in memory and local to the WAS where the session information was first created. Local session management does not share user session information with other clustered servers. The local session management lacks a persistent store for the sessions it manages.A server failure eliminates the WAS instances and also destroys any sessions that are managed by those instances.
The administrator can define a limit on the number of sessions that are held in the in-memory cache by specifying the Maximum in-memory session count setting. The session manager also permits an unlimited number of sessions in memory by enabling the setting...
-
Allow overflow
If you choose to enable session overflow, monitor the state of the session cache closely for performance purpose.
Persistent sessions management
WAS provides the following options for persistent session management:- Database session persistence, where sessions are stored in the database specified.
- Memory-to-memory session replication using the data replication service available in distributed server environments.
In a distributed environment, we can have both these two session mechanism options. In a stand-alone environment, we can only set the database session persistence.
All information stored in a persistent session store must be serialized. As a result, all of the objects that are held by a persistent session store must implement java.io.Serializable. In general, consider making all objects that are held by a session serialized, even if immediate plans do not call for the use of persistent session management. Enabling this feature makes the transition between local and persistent management occur transparently.
The session manager maintains a cache of the most recently used sessions in memory. If it cannot find the session information from the cache, session manager queries the persistent storage. Retrieving a user session from the cache eliminates a more expensive retrieval from the persistent store. Session data is stored to the persistent store based on your selections for write frequency and write content option.
WXS dynamic cache provider can be used as a new session replication approach. This shared in-memory cache sits in a highly-available replicated grid. User sessions can be shared between any set of application servers, even across data centers, allowing a more reliable and fault-tolerant user session state. No application code change is required when using WXS to store and manage session data.
Configuring the persistent session setting
To specify the persistent session:
- Go to the appropriate level of Session Management
- Under Additional Properties, click Distributed environment settings.
- Under General Properties select which session storage mechanism to use.
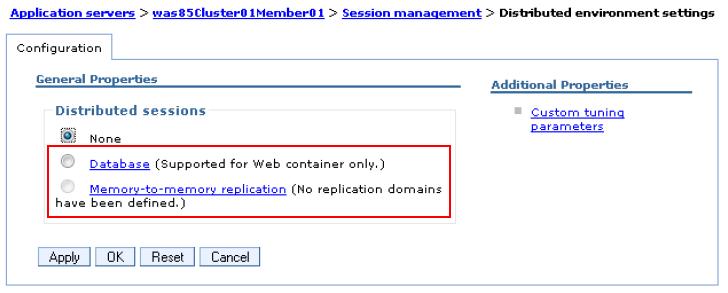
- Click the Database or Memory-to-memory replication hot link and then specify the details of each persistent session configuration.
Enabling database persistence
In this section, we discuss enabling database persistence.
Before enabling database persistence:
- Create a session database.
- Create a table for the session data:
- In distributed environments, the session table is created automatically when you define the data source for the session management database. However, to use a page (row) size greater than 4 KB, create the table space manually.
- To expand the column size limits, we can create the table externally.
- (z/OS DB2) Create a table for the session data
- Create a JDBC provider.
- Create a data source point for the database.
-
Resources | JDBC | JDBC Providers | JDBC_provider | Data Sources | New
The data source must be non-XA enabled and must be a non-JTA enabled data source.
The JNDI name of the database for persistence, for example, can be jdbc/Sessions.
Enabling the database persistence
To enable database persistence:
- Go to the appropriate level of Session Management
- Under Additional Properties, click Distributed environment settings.
- Select the Configuration tab. Click the Database hot link.
- Specify the database information.
- The Data Source JNDI name from the preparation step.
- The database user ID and password used to access the database and for table creation.
- Configure a table space and page sizes if you create them manually.
- Switch to a multi-row schema.
Using multi-row sessions becomes important if the size of the session object exceeds the size for a row. If the multi-row session enabled, the session manager breaks the session data across multiple rows as needed. This method allows WAS to support large session objects. It also provides a more efficient mechanism for storing and retrieving session contents under certain circumstances.

- Optional: To change the default tuning parameters, click Custom tuning parameters.
- Click OK and Save the configuration changes. In cluster environment, repeat these steps for each server in the cluster. Save and synchronize the changes.
- Restart the application servers or cluster.
Database session persistence can also be configured using scripting.
Memory-to-memory replication
Memory-to-memory replication uses the data replication service to replicate data across many application servers in a cluster without using a database. Separate threads handle replication within an existing application server process. In this mode, sessions can replicate to address HTTP Session single point of failure (SPOF) and eliminates the effort maintaining a replication database. Session information between application servers is encrypted.The data replication service is an internal WAS component. In addition to its use by the session manager, it is also used to replicate dynamic cache data and stateful session beans across many application servers in a cluster.
Memory-to-memory replication requires the high availability (HA) manager to be active.
Data replication service modes
The memory-to-memory replication function is accomplished by creating a data replication service instance in an application server that communicates to other data replication service instances in remote application servers.
We can set up a replication service instance to run in any of the following modes:
- Server mode: The server is used to receive backup copies of other application server sessions. It does not send copies of sessions created in that particular server.
- Client mode: The server broadcasts or sends copies of the sessions it owns. It does not receive backup copies of sessions from other servers.
- Both mode: The server simultaneously sends copies of the sessions it owns and acts as a backup table for sessions that are owned by other application servers. This mode is the default setting.
Replication configuration type
The following list notes the officially supported configuration types. However, WAS allows additional possibilities for memory-to-memory replication configuration. Only the following configurations are officially supported:
- Peer-to-peer replication
- Client/server replication
- Single replication
- Custom replication
Single replication in a cluster is the default setting. We can also modify the number of replicas within a cluster through the replication domain.
Peer-to-peer topology
Each application server stores sessions in its own memory. It also stores sessions to and retrieves sessions from other application servers. Each application server can retrieve sessions from other application servers. Each application server can also provide sessions to other application servers.The basic peer-to-peer topology (using client, server, or both mode for replication) is the default configuration and has a single replica (we can also add additional replicas by configuring the replication domain).
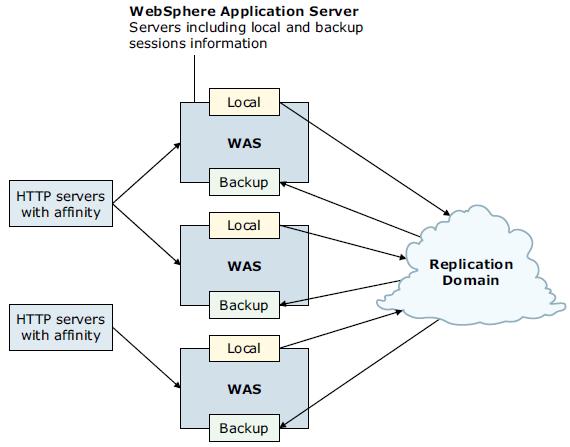
Session hot failover
A new feature called session hot failover was added to WAS V8.5.
This feature is only applicable to the peer-to-peer mode. In a cluster environment, session affinity in the web server plug-in for WAS routes the requests for a given session to the same server. If the current owner server of the session fails, the web server plug-in routes the requests to another appropriate server in the cluster. This feature causes the web server plug-in to failover to a server that already contains the backup copy of the session, therefore avoiding the overhead of session retrieval from another server containing the backup.
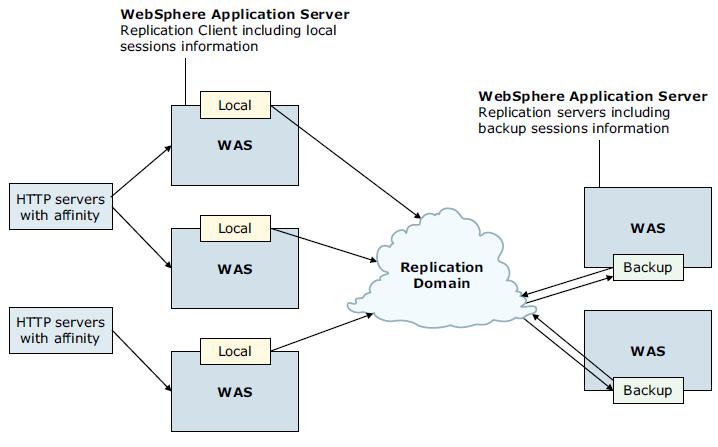
Client/server topology
The client'server configuration, used to attain session affinity, consists of a cluster of servers that are configured as client only and server only. The servers, configured as server only, are dedicated replication servers that store sessions and provide session information replication clients.These replication servers do not respond to user web requests. Client replication servers send session information to the replication servers and retrieve sessions from the replication servers. They respond to user web requests and store only the sessions that belong to themselves.
Replication domain
Replication domains are used for replication by the HTTP session manager, dynamic cache service, and stateful session bean failover components. All memory-to-memory data replication service instances that need to share information must be in the same replication domain.
Create a separate replication domain for each consumer. For example, create one replication domain for the session manager and another separate replication domain for the dynamic cache. Configure only one replication domain when you configure session manager replication and stateful session bean failover. Using this pattern ensures the backup state information of HTTP sessions and stateful session beans reside on the same application server.
To create, view, and configure the replication domains on the dmgr console, click...
-
Environment | Replication domains | replication_domain_name

Where...
| Name | Unique name within the cell for the replication domain. | ||||||
| Request timeout | How long a replication domain consumer waits when requesting information from another replication domain consumer before it gives up and assumes the information does not exist. Default is five seconds. | ||||||
| Number of replicas | Number of replicas created for every session entry.
|
Enabling memory-to-memory replication
Complete the following actions to enable the memory-to-memory replication. Complete these tasks before enabling data for the replication service:- Create a cluster consisting of at least two application servers.
- Install applications to the cluster.
Configuring the cluster members
To configure the cluster members:
- Click...
-
Servers | Server Types | WebSphere application servers | server_name
- Under Container Settings section, click Session management.
- Click Distributed environment settings under Additional Properties.
- The configuration tab is then opened
Click Memory-to-memory replication.
- Choose a replication domain.
- Select the replication mode. Clicking Both client and server identifies this topology as a peer-to-peer topology. In a client'server topology, click Client only for servers that respond to user requests. Click Server only for those servers used as replication servers.
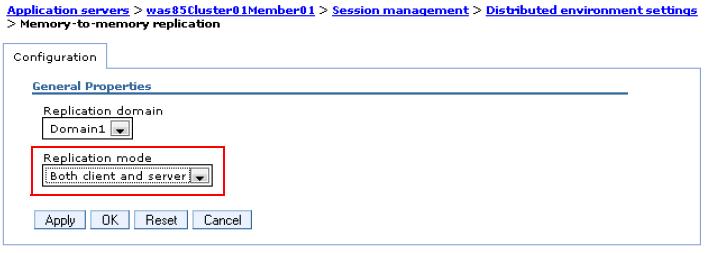
- Click OK.
- Optional: To change the default tuning parameters, click Custom tuning parameters.
- Click OK and Save the changes on the Memory-to-memory replication page and the Session management page.
- Repeat these steps for the rest of the application servers in the cluster.
- Synchronize the configuration, and restart the cluster.
You must configure all session managers connected to a replication domain to have the same topology. If one session manager instance in a domain is configured to use the client'server topology, the rest of the session manager instances in that domain must be a combination of servers configured as Client only and Server only. If one session manager instance is configured to use the peer-to-peer topology, all session manager instances must be configured as Both client and server.
Multiple data replication service instances that exist on the same application server and are configured to be part of the same domain must have the same mode. Multiple instances exist on the same application server due to session manager memory-to-memory configuration at various levels.
Session affinity
Session affinity is a favored relationship between a client and application server. Affinity established between the two can override load-balancing algorithms. Though load-balancing can be overridden it is done in a way that contributes to application performance using in-memory cache. The application server that serves the clients first request creates this affinity through session information and cookies.
What is the session affinity
The session management facility requires an affinity mechanism so that all requests for a particular session are directed to the same application server instance in the cluster. This routing ensures that all of the HTTP requests are processed with a consistent view of the user's HTTP session. This requirement conforms to the Servlet 2.3 specification, in that multiple requests for a session cannot coexist in multiple application servers, and provides better performance as sessions are cached in local memory.
WAS ensures that session affinity is maintained. Each server ID (clone ID or partition ID) is appended to the session ID. When an session is created, its ID is passed back to the browser as part of a cookie or URL encoding. When the browser makes further requests, the cookie or URL encoding is sent back to the web server. The web server plug-in for WAS examines the HTTP session ID in the cookie or URL encoding, extracts the unique ID of the cluster member handling the session, and forwards the request.
The JSESSIONID cookie can be divided into the following parts:
- Cache ID
- Session ID
- Separator
- Clone ID
- Partition ID
For example, if the JSESSIONID cookie is 0000SHOQmBQ8EokAQtzl_HYdxIt:vuel491u. Each parts mapping of the JSESSIONID
Table 28-3 Cookie mapping Content Value in the example Cache ID 0000 Session ID SHOQmBQ8EokAQtzl_HYdxIt separator : Content Value in the example Clone ID / Partition ID vuel491u
Within a cluster, clone ID is used to identify the cluster member when routing the request to application servers within a cluster. It must be unique to maintain session affinity. When memory-to-memory replication in peer-to-peer mode is selected, a partition ID will be used instead of a clone ID.
The clone ID can be seen in the web server plug-in configuration file plug-in-cfg.xml. We can use the session management custom property HttpSessionCloneId to change the clone ID of the cluster member
We can also configure the clone ID for each application server using scripting.
Session affinity can still be broken if the cluster member handling the request fails.
To avoid losing session data, use persistent session management. In persistent sessions mode, the cache ID and server ID (clone ID or partition ID) changes in the cookie when there is a failover or when the session is read from the persistent store.
Session affinity and failover
Sessions created by cluster members in the cluster environment share a common persistent session store. The session affinity, in the web server plug-in for WAS, routes the requests for a given session to the same server. If the current owner server instance of the session fails, the web server plug-in routes the requests to another appropriate server in the cluster. The user can continue to use session information without impact. Note that only a single cluster member can control and access a given session at a time.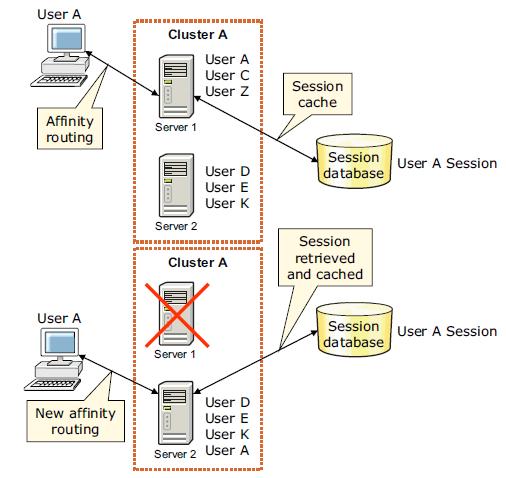
After a server failure, web server plug-in redirects the user to another cluster member, and the user's session affinity switches to this replacement cluster member. After the initial read from the persistent store, the replacement cluster member places the user's session object in the in-memory cache. From then on, requests for that session go to the selected cluster member.
The requests for the session can go back to the failed cluster member when it is recovered.
Session affinity with on demand router
In WAS V8.5, the on demand router (ODR), similar to the web server plug-in, uses session affinity for routing work requests. After a session is established on a server, later work requests for the same session go to the original server. Further more, the ODR can provide session affinity support for the following scenarios:
- When the ODR routes to servers that are not WAS products.
- When using the dynamic cluster.
- When the application using a custom session setting, such as a session ID cookie name, is something other than JSESSIONID.
Session affinity consideration
WebSphere provides session affinity on a best-effort basis. There are narrow windows where session affinity fails, for example:- When a cluster member is recovering from a crash, a window exists where concurrent requests for the same session can be received by different cluster members. To avoid or limit this situation, set the retry timeout to a smaller value, if the environment allows.
- A server overload or long processing times can cause requests that belong to the same session to go to different cluster members.
The session affinity can impact or be impacted by other system configurations, for example:
- Health policies from Intelligent Management can impact the session affinity. If the policies that define the action are putting a server into maintenance mode then session affinity to the server is broken.
- The cluster routing options and workload management options are impacted by session affinity. After a session is created at the first request, all the subsequent requests must be served by the same member of the cluster. So the predefined load balancing options will not work.
- High availability also impacts the session affinity. The high availability manager can help obtain better session peer to peer replication. When the current owner server instance of the session fails, then the requests can be routed to another appropriate server in the cluster for failover.
Session management tuning
Session performance considerations
The administrators have several options for improving the performance of session management:
This action reduces the memory required by the cache. Enabling overflow cache and persistence session management can impact the design. You need to balance the options of memory consumption and retrieval frequency.
This method reduces both the data retrieval time and the serialization impact. Even with this feature’s support, you still need to keep the session objects small.
Avoid circular references within sessions if using multi-row session support. The multi-row session support does not preserve circular references in retrieved sessions.
More information: best practices using sessions, refer to the following website: http://www14.software.ibm.com/webapp/wsbroker/redirect?version=phil&product=was-nd -dist&topic=cprs_best_practice
Session management tuning
WAS session support has many options for tuning session performance to match the checklist, as mentioned in 28.5.1, “Session performance considerations” on page 1020. These options support administrator flexibility in determining the performance and failover characteristics for their environment. Table 28-4 shows the tuning features summary. In this section, we cover write frequency, write contents and multi-row schema. More information: other tuning features, refer to section 28.2, “Session management configuration” on page 1000.Table 28-4 Summary of tuning features Feature or option Goal Applies to sessions in memory, database, or memory-to-memory Write frequency Minimize database write operations. Database Session affinity Access the session in the same application server instance. All Multi-row schema Fully utilize database capacities. Database Feature or option Goal Applies to sessions in memory, database, or memory-to-memory Base in-memory session pool size Fully utilize system capacity without overburdening system. All Write contents Allow flexibility in determining what session data to write Database Scheduled invalidation Minimize contention between session requests and invalidation of sessions. Database Table space and row size Increase efficiency of write operations to database. Database (DB2 only)
WAS provides predefined performance tuning options for the following distributed session persistence tuning parameters:
- Write frequency settings: How often session data is written
- Write contents settings: How much data is written
- Session cleanup settings: When the invalid sessions are removed from the system
To view and edit the tuning parameters:
- Go to the appropriate level of Session Management described in 28.2.2, “Accessing session management properties” on page 1001.
- Under Additional Properties, click Distributed environment settings | Custom tuning parameters. The configuration page is then displayed with the following options:
- Very high (optimize for performance)
- High
- Medium
- Low (optimize for failover)
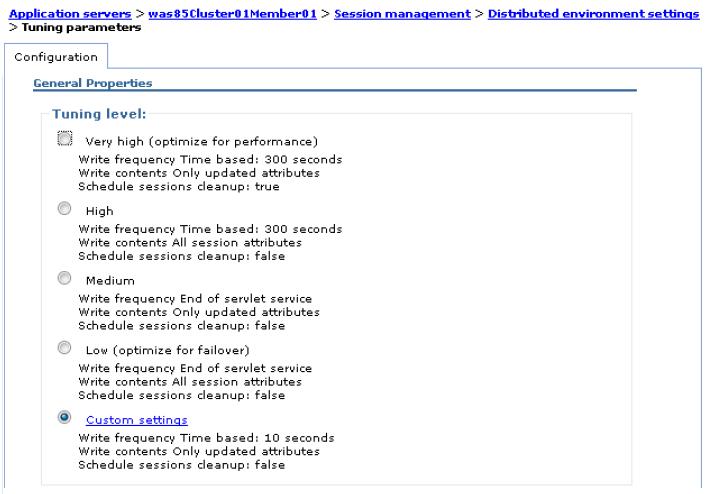
- We can use predefined options or customize the tuning parameters. Click the Custom settings hotlink on the configuration page. After the hotlink opens, the available tuning parameters are displayed
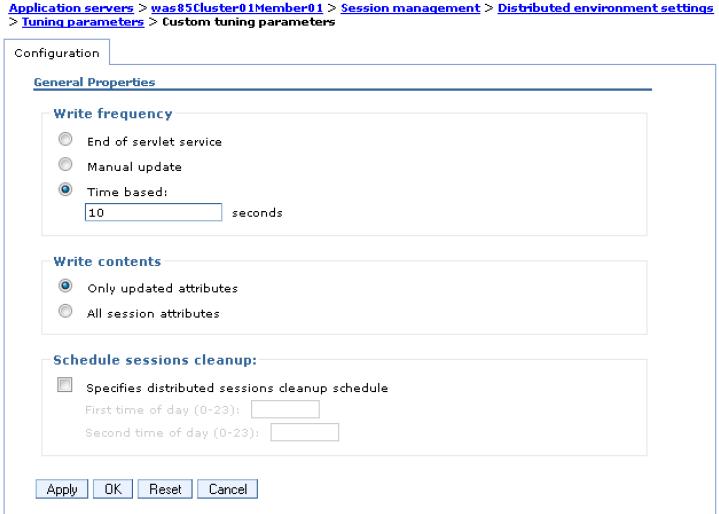
The following sections go into more detail about these custom settings.
Writing frequency settings
The settings determine how often session data is written to the persistent data store:
- End of servlet service
If the session data changed, it is written to the persistent store after the servlet finishes processing an HTTP request. Therefore, the session data is written to the persistent store at the completion of the HttpServlet.service() method call. The content written to the persistent store is controlled by the write contents option setting.
- Manual update
The modified session data and last access time are written to the persistent store when the IBMSession.sync() method is called on the object:
- Manual update mode requires an developer to use the IBMSession.sync() for managing sessions.
- If manual update mode is specified but the servlet or JSP terminates without invoking the sync() or the application does not invoke the sync(), the session manager saves content differently. During those circumstances, the session manager saves the contents of the session object into the local session cache, not the persistent data store. The session manager updates only the last access time in the persistent store asynchronously and at a later time.
- The session data written to the persistent store is controlled by the write contents option selected.
- Time-based
The session data is written to the persistent store based on the specified write interval value:
- The expiration of the write interval does not necessitate a write to the persistent store unless the session has been touched.
- Only the last access time is written to the persistent store, if the session write interval has expired but the session has only been retrieved.
- The session data written is dependent on the write contents settings.
- Time-based write allows the servlet or JSP to issue the IBMSession.sync() method to force the write of session data to the database.
- If the time between session servlet requests for a particular session is greater than the write interval, the session effectively is written after each service method invocation.
- The session cache needs to be large enough to hold all of the active sessions as persistent store writes increase. Extra persistent store writes occur because the receipt of a new session request can result in writing the oldest cached session to the persistent store.
- The session invalidation time must be at least twice the write interval to ensure that a session is not inadvertently invalidated prior to being written to the persistent store.
- A newly created session is always written to the persistent store at the end of the service method.
Time-based writes require session affinity for session data integrity. We can gain potential performance improvements by reducing the frequency of persistent store writes.
Consider an example where the web browser accesses the application once every five seconds. The following three modes are available for selection and manage that situation differently:
- In End of servlet service mode, the session is written out every five seconds.
- In Manual update mode, the session is written out when the servlet issues IBMSession.sync().
public void service (HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException { // Use the IBMSession to hold the session information and manual update method sync() com.ibm.websphere.servlet.session.IBMSession session = (com.ibm.websphere.servlet.session.IBMSession)req.getSession(true); Integer value = 1; //Update the in-memory session stored in the cache session.putValue("MyManualCount.COUNTER", value); //The servlet saves the session to the persistent store session.sync(); } - In Time-based mode, the servlet or JSP does not need to use the IBMSession class or issue the IBMSession.sync() method. If the write interval is set to 120 seconds, the session data is written out every 120 seconds. Last access time attribute: The last access time attribute is updated each time the session is accessed by the servlet or JSP, whether or not the session is changed. This update is done to make sure the session does not time out.
Write contents settings
WebSphere supports the following modes for writing session contents to the persistent store:- Write changed (the default) Writes only the session data updated using setAttribute() and removeAttribute().
- Write all Writes all the session data to the database.
When using database persistence, the behavior for subsequent servlet or JSP requests for this session varies depending on whether the single-row or multi-row database mode is in use, as follows.
Table 28-5 Write content setting for single-row or multi-row schemas Write Contents Behavior with single-row schema Behavior with multi-row schema Write changed If any session attribute is updated, all objects bound to the session are written. Only the session data modified through setAttribute method or removeAttribute method calls is written. Write all All bound session attributes are written. All session attributes that currently reside in the cache are written. If the session never left the cache, all session attributes are written.
The combination of the Write all mode with a time-based write can greatly reduce the performance penalty and essentially give you optimum performance.
Single and multi-row schemas (database persistence)
When using the single-row schema, each user session maps to a single database row, which is WebSphere's default configuration for persistent session management. When using the multi-row schema, each user session maps to multiple database rows, with each session attribute mapping to a database row. Table 28-6 gives the design considerations for choosing single-row or multi-row.
Table 28-6 Single-row compared to multi-row Programming concepts on usage Application scenario Benefit of single-row We can read/write all values with just one record read/write, which takes up less space in a database because you are guaranteed that each session is only one record long. Programming concepts on usage Application scenario Limitation of single-row There is a 2 MB limit of stored data per session. The sum of all session attributes is limited to 2 MB. Benefit of multi-row The application can store an unlimited amount of data. You are limited only by the size of the database and a 2 MB-per-record limit.
The application can read individual fields instead of the entire record.
When large amounts of data are stored in the session but only small amounts are specifically accessed during a given servlet's processing of an HTTP request, multi-row sessions can improve performance by avoiding unneeded Java object serialization. Limitation of multi-row If data is small in size, you might not want the extra impact of multiple row reads when everything can be stored in one row.
In the case of multi-row usage, design the application data objects so they do not have references to each other. This prevents circular references.
Consider them all
Summary of considering row-type, write contents, and write frequency for best results. Table 28-7 Write contents, row-type, and write frequency comparisonRow type Write contents Write frequency Action for setAttribute Action for removeAttribute Single Write changed End of servlet service / Manual update
If any of the session data changed, write all of this session's data from cache.a
If any of the session data changed, write all of this session's data from cache.a Time-based If any of the session data changed, write all of this session's data from cache.a
If any of the session data changed, write all of this session's data from cache.a Write All End of servlet service / Manual update Always write all of this session's data from cache. Always write all of this session's data from cache. Time-based Always write all of this session's data from cache. Always write all of this session's data from cache. Row type Write Write frequency Action for Action for contents setAttribute removeAttribute Multiple Write End of servlet Write only Delete only changed service / Manual thread-specific data thread-specific data update that changed. that was removed. Time-based Write thread-specific Delete thread-specific data that changed for all threads using this data that was removed for all session. threads using this session. Write all End of servlet Write all session data Delete thread-specific service / Manual update from cache. data that was removed for all threads using this session. Time-based Write all session data from cache. Delete thread-specific data that was removed for all threads using this session.
- When a session is written to the database using single-row mode, all of the session data is written. Therefore, no database deletes are necessary for properties removed with the removeAttribute() method because the write of the entire session does not include removed properties.
Session database tuning
To maximize performance tuning, it is required to tune the underlying session persistence database. WebSphere provides a first step by creating an index for the sessions table when the table is created. The index is composed of the session ID, the property ID for multi-row sessions, and the web application name.
Most database managers provide a great deal of capability in tuning at the table or table space level. However, creating a separate database or instance provides the most flexibility in tuning.
In general, tune and configure the database appropriately for the database that experiences a great deal of I/O. The database administrator (DBA) monitors and tunes the database buffer pools, database log size, and write frequency. Additionally, maximizing performance requires striping the database or instance across multiple disk drives and disk controllers and using any hardware or operating system buffering available to reduce disk contention.
Managing your session database connection pool
When using persistent session management, the session manager interacts with the session database through a data source. Each data source controls a set of database connections known as a connection pool. Maximum pool size represents the number of simultaneous accesses to the persistent session database available to the session manager. For high-volume web sites, simultaneous data source queuing can impact the overall performance of the web application. However, each connection represents memory impact, so a large pool decreases the memory available for WebSphere to execute applications. To avoid memory issues, performance tuning is needed to balance the optimal setting for a given application.
More information: Data source and connection pool
The session affinity routing, combined with session caching, reduces database read activity for session persistence. Likewise, manual update write frequency, time-based write frequency, and multi-row persistent session management reduce unnecessary writes to the persistent database. Incorporating these techniques can also reduce the size of the connection pool required to support session persistence for a given web application.
Stateful session bean failover
Each EJB container provides a method for stateful session beans to failover to others. When enabled, all stateful session beans in the container can failover to another instance of the bean and still maintain the session state. Stateful session bean uses the functions of the data replication service and workload management. In contrast to the HTTP session persistence, stateful session EJB availability is handled using only memory-to-memory replication.
Using the EJB container properties, we can specify a replication domain for the EJB container and enable the stateful session bean failover using memory-to-memory replication.
We can also override the parent object's stateful session bean replication settings from the module level. This action enables you to specify whether failover occurs for the stateful session beans at the EJB module level or container level. The following two examples relate how we can enable failover for specific results:
Enabling stateful session bean failover
In this section, we discuss how to enable stateful session bean failover.
Configuring stateful session bean failover at the EJB container level
To view and edit stateful session bean failover properties at the EJB container level...
- Click...
-
Servers | Server Types | WebSphere application servers | server_name
- Under the Container Settings section of the Configuration tab, click EJB Container Settings | EJB container.
- Under the General Properties section, select the Enable stateful session bean failover using memory-to-memory replication option
This option is disabled until you define a replication domain. There is a memory-to memory replication hyperlink to help configure the replication settings. If no replication domains are configured, the link takes you to a window where we can create one. If at least one domain is configured, the link takes you to a window where we can select the replication settings to be used by the EJB container
- Click OK and Save your changes.
Configuring stateful session bean failover at the applications level
To access and edit stateful session bean failover properties at the EJB application level...
- Click Applications | Application Types | WebSphere enterprise applications | applicaiton_name.
- Select your choice of replication settings. Under the Enterprise Java Bean Properties section of the Configuration tab, select Stateful Session Bean Failover Settings. The Stateful Session Bean Failover Settings panel appears.

– Enable stateful session bean failover using memory-to-memory replication
This option enables stateful session bean failover. To disable the failover, clear this option. Click the check box.
- Use replication settings from EJB container
If selected, any replication settings that are defined for this application are ignored.
When engaging the use replication settings from EJB container option, configure memory-to-memory replication at the EJB container level. Otherwise, the settings on this window are ignored by the EJB container during server start, and the EJB container logs a message that indicates that stateful session bean failover is not enabled for this application.
- Use application replication settings
If selected, you override the EJB container settings. This option is disabled until you define a replication domain. This selection has a memory-to-memory replication hyperlink to help configure the replication settings. If no replication domains are configured, the link takes you to a window to create one. If at least one domain is configured, the link takes you to a window where we can select the replication settings to be used by the application.
- Use replication settings from EJB container
- Click OK and Save your changes.
We can also configure stateful session bean failover at the application level using the wsadmin script.
Configuring stateful session bean failover at the EJB modules level
To access and edit stateful session bean failover properties at the EJB module level...
- Click Applications | Application Types | WebSphere enterprise applications | application_name.
- Under Modules section, select Manage Modules.
- Select the JAR file to configure.
- Under Additional Properties, select Stateful session bean failover settings.
- Select Enable stateful session bean failover using memory to memory replication.
- Select your choice of Replication settings. You have a choice of two radio buttons:
- Use application or EJB container replication settings: If you select this button, any
replication settings that are defined for this EJB module are ignored.
- Use module replication settings: If you select this button, you override the replication settings for the EJB container and application. This button is disabled until you define a replication domain. This selection has a hyperlink to help configure the replication settings. If no replication domains are configured, when you click the link, then you visit a page where we can create one. If at least one domain is configured, when you click the link, then you visit a page where we can select the replication settings to be used by the EJB container.
- Use application or EJB container replication settings: If you select this button, any
replication settings that are defined for this EJB module are ignored.
- Select OK and Save your changes.
Enabling failover of servants in an unmanaged z/OS server
With WAS V8.5 for z/OS, we can enable the stateful session bean failover among servants. Failover only occurs between the servants of a given unmanaged server. If an unmanaged z/OS server has only one servant, enabling failover has no effect. An unmanaged z/OS server that has failover enabled does not fail over to another unmanaged z/OS server.
Stateful session bean failover consideration
When you enable the stateful session bean failover, consider which of the following impacts and stateful session bean configurations:
- Stateful session bean activation policy with failover enabled.
- Stateful session bean use of container managed units of work or bean managed units of work with failover enabled.
- If you create either an HTTP session or a stateful session bean that stores a reference to another stateful session bean, make sure the HTTP session and stateful session bean are configured to use the same replication domain.
- Do not use a local and a remote reference to the same stateful session bean.
- Avoid referencing non-persistent EJB timers in a stateful session bean instance when failover is enabled.
- Avoid the use of remote asynchronous methods on stateful session beans.