System management in a distributed server environment
- Centralized changes to configuration and application data
- Application data files
- Configuration file location during application installation
- Variable scoped files
- Rules for process startup
- Distributed process discovery
- File synchronization in distributed server environments
- Synchronization scheduling
- How files are identified for synchronization
- Ensure that manual changes are synchronized
- Reset the master cell repository
- Reset the master node repository
- Explicit or forced synchronization
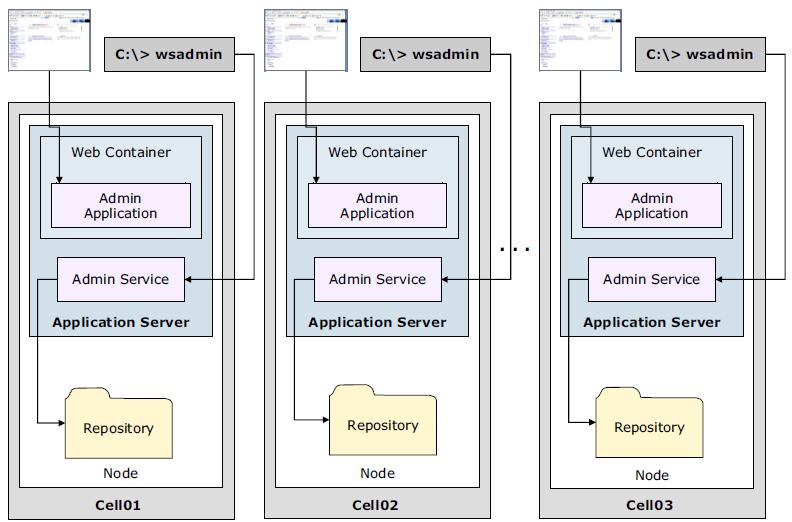
- Advanced system management of multiple stand-alone servers
- Advanced management of distributed and stand-alone servers
To build a distributed server environment...
- Create a deployment manager profile.
The deployment manager is responsible for administering the entire cell. A deployment manager administers one cell only.
- Create a custom profile, which creates a second cell (defaultCell), a node, and a node agent.
At this point, we do not have a functioning application server environment, just the beginnings of one.
- Federate the node to the deployment manager's cell using the addNode command.
After being federated, NodeA is no longer part of the defaultCell, but rather is part of the deployment manager's cell (dmgrCell).
- After the federation is complete, all administration of NodeA is delegated to the deployment manager, and new application servers can be created on the node using the administrative tools for the deployment manager.
Centralized changes to configuration and application data
The deployment manager maintains a master repository of all the configuration files for nodes and servers in the cell. When configuration changes are made with the deployment manager, the changes are first stored in the master repository. After that, automatic or manual synchronization pushes the changes down to the affected nodes.
The configuration and application data repository is a collection of files containing all of the information necessary to configure and execute servers and their applications. Configuration files are stored in XML format, while application data is stored as EAR files and deployment descriptors.
Each node containing a deployment manager, application server, administrative agent, or job manager has its own profile directory under the directory...
-
PROFILE_ROOT
The repository files are arranged in a set of cascading directories within each profile directory structure, with each directory containing a number of files relating to different components of the cell.
The PROFILE_HOME/config directory is the root of the repository for each profile. It contains the following directory structure:
- cells/cellname/
This is the root level of the configuration for the cell. Depending on the types of resources that are configured, you might see the following subdirectories:
cells/cellname/applications/ Contains one subdirectory for every application deployed within the cell. cells/cellname/buses/ Contains one directory for each SIBus defined. cells/cellname/coregroups/ Contains one directory for each defined core group. cells/cellname/nodegroups/ Contains one directory for each defined node group. cells/cellname/nodes/ Contains one directory per node. cells/cellname/nodes/<node> Contains node-specific configuration files and a server directory containing one directory per server and node agent on that node. cells/cellname/clusters/ Contains one directory for each of the clusters managed as part of the cell. Each cluster directory contains a single file, cluster.xml, which defines the application servers of one or more nodes that are members of the cluster.
temp/ The configuration repository uses copies of configuration files and temporary files while processing repository requests. Default location: -
PROFILE_HOME/config/temp
backup/ During administrative processes, such as adding a node to a cell or updating a file, configuration files are temporarily backed up to a backup location. Default location: -
PROFILE_HOME/config/backup
The overall structure of the master repository is the same for both a stand-alone server environment and a distributed server environment. But there are some critical differences, including:
- Stand-alone server environment:
- The master repository is held on a single machine. There is no copy of it on any other node.
- The repository contains a single cell and node.
- Because each application server is stand-alone, there is no nodeagent/ directory.
- Clusters are not supported. Therefore, the repository tree does not contain the clusters/ directory or subdirectories.
- Distributed server environment:
- The master repository is held on the node containing the deployment manager.
- Each node also has a local copy of the relevant configuration and application data files from the master repository.
- When changes are made to the configuration in the master repository, those changes must be synchronized to the configuration files on the nodes. Permanent changes to the configuration requires changes to the file or files in the master repository.
- Changes can be made to the configuration files on a node, but the changes are temporary and are overwritten by the next file synchronization from the deployment manager. Configuration changes made to node repositories are not propagated up to the cell.
- Stand-alone server environment:
Application data files
The PROFILE_HOME/config directory of the master repository contains the following directory structure that holds application binaries and deployment settings:
- cells/cellname/applications/
Contains a subdirectory for each application deployed in the cell. Names of the directories match the names of the deployed applications.
The name of the deployed application does not have to match the name of the original EAR file that was used to install it. Any name can be chosen when deploying a new application, as long as the name is unique across all applications in the cell.
- cells/cellname/applications/appname.ear
Each application's directory in the master repository contains the following items:
- A copy of the original EAR, called appname.ear, which does not contain any of the bindings specified during installation of the application.
- A deployments directory called deployments/appname/.
- cells/cellname/applications/appname.ear/deployments/appname
The deployment descriptors in this directory contain the bindings specified during application deployment. The deployment directory of each application contains these files:
- deployment.xml
Contains configuration data for the application deployment, including the allocation of application modules to application servers and the module startup order.
- META-INF/
application.xml J2EE standard application deployment descriptor ibm-application-bnd.xmi IBM WebSphere-specific application bindings ibm-application-ext.xmi IBM WebSphere-specific application extensions was.policy Application-specific Java 2 security configuration. Optional. If it is not present, the policy files defined at the node level apply for the application.
The subdirectories for all application modules (WARs, RARs, and EJB JARs) contain deployment descriptors and other configuration files for each module.
- deployment.xml
See also:
Configuration file location during application installation
Several things occur upon installation of an application onto WAS:
- The application binaries and deployment descriptors are stored within the master repository.
- The application binaries and deployment descriptors are published to each node that will host the application. These files are stored in the local copy of the repository on each node.
- Each node then installs the applications that are ready for execution by exploding the EARs under...
- PROFILE_HOME/installedApps/cellname/
Contains a subdirectory for each application deployed to the local node.
- PROFILE_HOME/installedApps/cellname/appname.ear/
Each application-specific directory contains the contents of the original EAR used to install the application, including:
- The deployment descriptors from the original EAR (which do not contain any of the bindings specified during application deployment)
- All application binaries (JARs, classes, and JSPs)
Variable scoped files
Identically named files that exist at different levels of the configuration hierarchy are called variable scoped files. There are two uses for variable scoped files:
- Configuration data contained in a document at one level of the configuration hierarchy is logically combined with data from documents at other levels.
The most specific value takes precedence to resolve any conflicts. For example, if a variable is defined in the variables.xml file of both the cell and node, the entry at the node level is used.
- Documents representing data are not merged but rather are scoped to a specific level of the topology.
For example, the namestore.xml document at the cell level contains the cell-persistent portion of the namespace, while at the node level the file contains the node-persistent root of the namespace.
Rules for process startup
When a managed server is starting up, it sends a discovery request message that allows other processes to discover its existence and establish communication channels with it. This action makes it possible to start the processes in a distributed server environment without following a strict order for startup, for example, a node agent can be running while the deployment manager is not active, and vice versa. When the stopped process is started, discovery occurs automatically:
- The deployment manager can be running while a managed server is not active and vice versa.
For example, if the node agent is not running when the deployment manager starts, the deployment manager tries to determine if the node agent is running but fails to set up the communication channel. When the node agent is started later, it contacts the deployment manager, creates a communication channel, and synchronizes data.
The execution of a managed server is not dependent on the presence of a running deployment manager. The deployment manager is only required when permanent configuration changes need to be written to the master repository.
- The node agent starts but no managed servers are started.
The node agent is aware of its managed servers and checks whether they are started. If so, it creates communication channels to these processes. Then, after a managed server starts, it checks whether the node agent is started and then creates a communication channel to it.
The node agent must be started before any application servers on that node are started. The node agent contains the Location Service Daemon (LSD) in which each application server registers on startup. The node agent is purely an administrative agent and is not involved in application serving functions.
Distributed process discovery
Each node agent and deployment manager maintains status and configuration information using discovery addresses or ports. On startup, processes use these discovery addresses to discover other running components and to create communication channels between them.
In this example, both node agents use ports 7272 and 5000, which assumes they reside on separate physical machines. If nodes are located on the same machine, configure to use non-conflicting ports.
During discovery, the following actions occur:
- The master repository located on the deployment manager installation contains serverindex.xml for each node.
The deployment manager reads this file on startup to determine the host name and IP port of each node agent's NODE_DISCOVERY_ADDRESS. The default port is 7272. We can display this port from the dmgr console by selecting System Administration | Node agents. Then select each node agent and expand Ports under the Additional Properties section. We can also verify this port by looking at the NODE_AGENT section in serverindex.xml of each node...
-
dmgr_PROFILE_HOME/config/cells/cellname/nodes/nodename/serverindex.xml
- The copy of the configuration repository located on each node contains serverindex.xml for the deployment manager.
The node agent reads this file on startup to determine the host name and IP port of the deployment manager's CELL_DISCOVERY_ADDRESS. The default port is 7277. We can display this port from the dmgr console by selecting System Administration | Deployment manager. Then expand Ports under the Additional Properties section. We can verify this port by looking at the DEPLOYMENT_MANAGER section in serverindex.xml for the deployment manager node...
-
PROFILE_HOME/config/cells/cellname/nodes/dmgr_nodename/serverindex.xml
- The copy of the configuration repository located on each node also contains serverindex.xml for the node.
Each managed server reads this file on startup to determine the host name and IP port of the node agent's...
-
NODE_MULTICAST_DISCOVERY_ADDRESS
A multicast address helps you avoid using too many IP ports for managed server-to-node agent discovery requests. Using multicast, a node agent can listen on a single IP port for any number of local servers. The default port is 5000. We can display this port from the dmgr console by selecting...
-
System Administration | Node agents | node_agent | Additional Properties | Ports
We can also verify this port by looking at the NODE_AGENT stanza in serverindex.xml of the node...
-
PROFILE_HOME/config/cells/cellname/nodes/nodename/serverindex.xml
File synchronization in distributed server environments
The file synchronization service is the administrative service responsible for keeping the configuration and application data files that are distributed across the cell up to date. The service runs in the deployment manager and node agents, and ensures that changes made to the master repository are propagated out to the nodes, as necessary. The file transfer system application is used for the synchronization process. File synchronization can be forced from an administration client, or can be scheduled to happen automatically.
During the synchronization operation, the node agent checks with the deployment manager to see if any files that apply to the node were updated in the master repository. New or updated files are sent to the node, while any files that were deleted from the master repository are also deleted from the node.
Synchronization is a one-way process. The changes are sent from the deployment manager to the node agent. No changes are sent from the node agent back to the deployment manager.
Synchronization scheduling
We can schedule file synchronization using the dmgr console...
-
System administration | Node agents | node_agent_name | File synchronization service
...to choose from the available options.
Details of each option are:
| Enable synchronization at server startup | Synchronization occurs before the node agent starts a server. Note that if you start a server using the startServer command, this setting has no effect. |
| Automatic synchronization | Synchronization can be made to operate automatically by configuring the file synchronization service of the node agent. The setting allows you to enable periodic synchronization to occur at a specified time interval. By default, this option is enabled with an interval of one minute. |
| Startup synchronization | The node agent attempts to synchronize the node configuration with the latest configurations in the master repository prior to starting an application server. The default is to not synchronize files prior to starting an application server. |
| Exclusions | specifies files or patterns that must not be part of the synchronization of configuration data. Files in this list are not copied from the master configuration repository to the node and are not deleted from the repository at the node. |
In a production environment, the automatic synchronization interval must be increased from the one-minute default setting so that processing and network impact is reduced.
How files are identified for synchronization
As part of synchronization, WAS must be able to identify the files that changed and therefore must be synchronized. To do this, it uses the following scheme:
- A calculated digest is kept by both the node agent and the deployment manager for each file in the configuration they manage.
These digest values are stored in memory. If the digest for a file is recalculated and it does not match the digest stored in memory, this indicates the file changed.
- An epoch for each folder in the repository and one for the overall repository are stored in memory.
These epochs are used to determine whether any files in the directory changed. When a configuration file is altered through one of the WAS administration interfaces, the overall repository epoch and the epoch for the folder in which that file resides are modified.
During configuration synchronization operations, if the repository epoch changed since the previous synchronize operation, individual folder epochs are compared. If the epochs for corresponding node and cell directories do not match, the digests for all files in the directory are recalculated, including the changed file.
Manually updating a configuration file does not cause the digest to change. Only files updated with administration tools are marked as changed. Manually updating the files is not recommended, but if we do, a forced synchronization will include any manually updated files.
Ensure that manual changes are synchronized
Manually changing configuration files is not recommended. It must only be done as a diagnostic measure or on the rare occasion that modify a configuration setting not exposed by the administration clients.
Manual editing is not recommended for these reasons:
- When using wsadmin and the dmgr console, we have the benefit of a validation process before the changes are applied. With manual editing, we have no such fail-safe.
- Updates made manually are not marked for synchronization and are lost at the next synchronization process unless you manually force synchronization.
Manual edits of configuration files in the master cell repository can be picked up if the repository is reset so that it re-reads all the files and recalculates all of the digests. We can reset either the master cell repository epoch or the node repository epoch, but be sure to keep these facts in mind:
- Reset the master cell repository causes any manual changes made in the master configuration repository to be replicated to the nodes where the file is applicable.
- Reset the node repository causes any manual changes to the local node files to be overwritten by whatever is in the master cell repository. Any manual changes in the master repository are picked up and brought down to the node.
When you manually change installed applications, they are treated the same as other configuration files in the repository in these respects:
- If you manually change the EAR file and reset the master cell repository, the changed EAR file is replicated out to the nodes where it is configured to be served and is expanded in the appropriate location on that node for the application server to find it. The application on that node is stopped and restarted automatically so that whatever is changed is picked up and made available in the application server.
- If you manually edit one of the deployment configuration files for the application and reset the repository, that change is replicated to the applicable nodes and is picked up the next time the application on that node is restarted.
Reset the master cell repository
To perform a reset of the master cell repository:
- Start the dmgr.
- Run...
-
cd dmgr_PROFILE_HOME\bin
./wsadmin.sh - Enter the following statements:
-
wsadmin>set config [$AdminControl queryNames *:*,type=ConfigRepository,process=dmgr]
wsadmin>$AdminControl invoke $config refreshRepositoryEpoch - If the commands can be executed successfully, we can see a number returned by the refreshRepositoryEpoch operation.

Reset the master node repository
To perform a reset of the master node repository:
- Start the dmgr.
- Open a command prompt and run...
-
cd PROFILE_HOME\bin
wsadmin - Enter the following statements:
-
wsadmin>set config [$AdminControl queryNames *:*,type=ConfigRepository,process=nodeagent]
wsadmin>$AdminControl invoke $config refreshRepositoryEpoch - If the commands can be executed successfully, we can see a number returned by the refreshRepositoryEpoch operation.
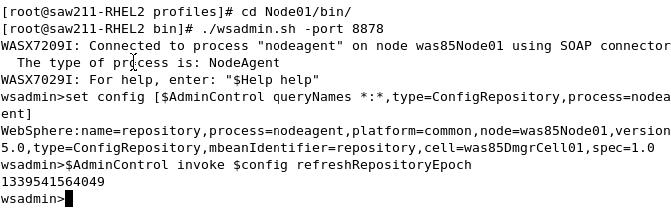
We can also use the explicit node synchronization process to complete the node repository reset and synchronization.
Explicit or forced synchronization
Synchronization can be explicitly forced at any time using the dmgr console, the syncNode command, or the wsadmin scripting tool.
- From the console...
-
System administration | Nodes | node | [Synchronize | Full Resynchronize ]

The Synchronize button initiates a normal synchronizing operation with no re-reading of the files. The Full Resynchronize button is the reset and recalculate function.
- syncNode command
This command has no cache of epoch values that can be used for an optimized synchronization and therefore performs a complete synchronization. Note that this action requires the node agent to be stopped.
The syncNode command resides in the bin directory under the base install or the node profile directory. To begin synchronization using this option, give the following commands:
-
cd PROFILE_HOME\bin
syncNode cell_host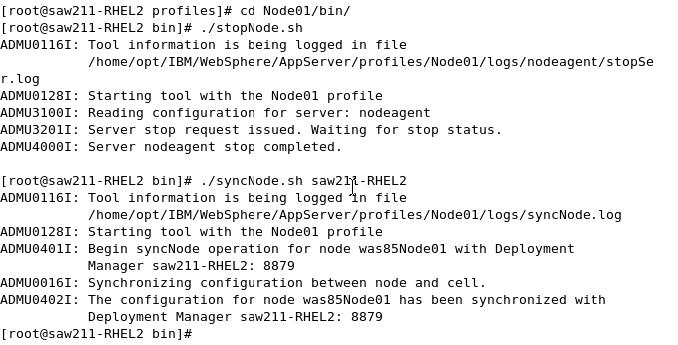
- wsadmin scripting tool
We can use file synchronization to propagate unique configuration data that needs to be used on all nodes. To synchronize to all nodes, put the file in the config/cells/cellname folder. If the file applies to just one node, put it only in the folder corresponding to that specific node. The same approach can be applied for any additional documents in a server-level folder.
Advanced system management of multiple stand-alone servers
Based on business requirements, an organization can have multiple stand-alone application servers installed on the same system or on multiple systems. These servers might be used for development, testing, staging, and so on.
A multiple stand-alone server environment can offer advantages when compared to a stand-alone server:
| Isolation for critical applications | Critical applications can be deployed on their own server to prevent negative impacts that can be caused by other, faulty applications on the same server. |
| Dedicated resources | To help customize tuning, each profile has a unique JVM and unique applications, configuration settings, data, and log files. |
| Enhanced serviceability | Profiles share a single set of product core files. When the product is updated, all of the profiles are updated, too. |
There are two options for administering the application servers in a multiple stand-alone server environment:
| | Independent administration | Administrative agent |
|---|---|---|
| Centralized control point | No. An administrator has to juggle multiple consoles. | Yes. An administrator can use an administrative agent as the central control point. |
| System resources used for administrative functions | Each application server runs its own administrative service and the dmgr console application. | After a node containing a stand-alone server is registered with the administrative agent, the dmgr console application and administrative service are stopped on that application server. The administrative agent is responsible for managing all of the servers on the registered node. System resources are dedicated to running applications. |
| Management capabilities when server is not running | The administrative application and administrative service are not available if the server is not running. An administrator must start the server locally. | The administrative agent modifies the stand-alone server's configuration repository directly using the administrative service. The administrative agent can also start, stop, and create new servers within the managed node. |
Combining the administrative agent with multiple stand-alone servers is a great starting point for simplifying administration. However, features, such as failover, workload management, session data replication, and many other features, cannot be configured in anything except a distributed server environment.
Multiple stand-alone servers with independent administration
Multiple stand-alone servers managed with the administrative agent
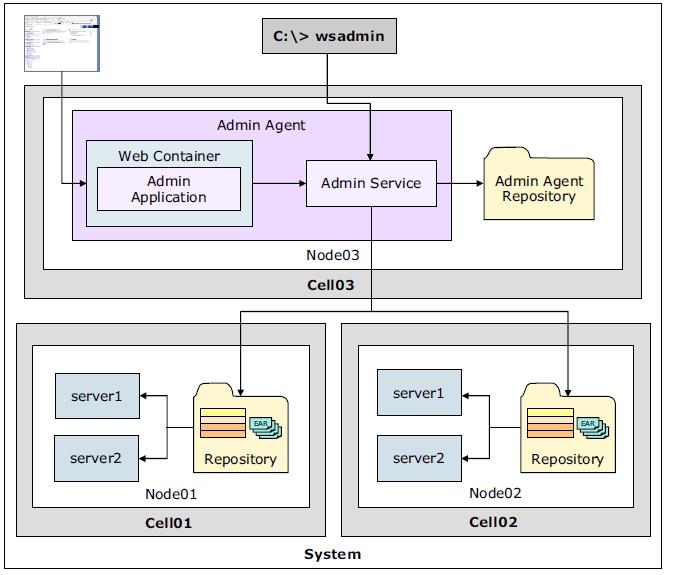
Advanced management of distributed and stand-alone servers
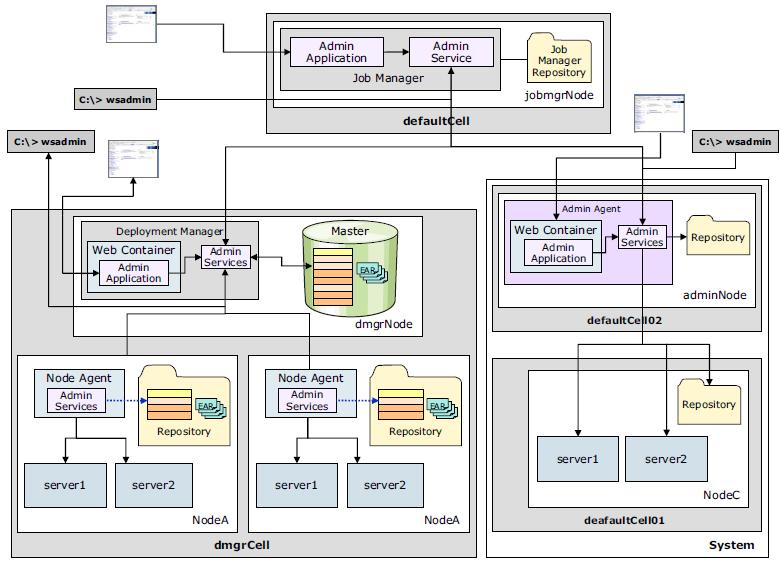
The job manager can be used to administer multiple distributed environments and stand-alone servers. The job manager administers the environment asynchronously using the concept of jobs. Because jobs are submitted asynchronously, a low-latency network is sufficient, which can be useful when the environment is distributed over distant geographical areas.
The job manager is available only with the Websphere Application Server Network Deployment (ND) offering and with WAS for z/OS.
The job manager administers the registered environments by submitting jobs that perform tasks, for example:
- Start and stop servers
- Create and delete servers
- Install and uninstall applications
- Start and stop applications
- Run wsadmin scripts
- Distribute files
To administer a distributed environment, the deployment manager is registered with the job manager. To administer stand-alone servers, the nodes managed by the administrative agent are registered with the job manager.

The job manager has a repository for its own configuration files, which are related to security, administration of the job manager, configurations, and so on. However, unlike a deployment manager, the job manager does not maintain a master repository. Instead, it allows the administrative agents and deployment managers to continue managing their environments as they if they were not registered with the job manager. The job manager can administer multiple administrative agents and deployment managers, and each administrative agent and deployment manager can be registered with multiple job managers.