Scalability with high availability messaging engine policy
The scalability with high availability messaging engine policy is a predefined messaging engine policy type provided when you use messaging engine policy assistance. It helps you to configure a cluster that is a member of a bus when we require both high availability and scalability in the cluster.
The scalability with high availability configuration ensures that there is a messaging engine for each server in a cluster, and that each messaging engine has a failover location.
The scalability with high availability messaging engine policy creates a single messaging engine for each server in the cluster. Each messaging engine can fail over to one other specified server in the cluster. Each server can host up to two messaging engines, such that there is an ordered circular relationship between the servers. Each messaging engine can fail back, that is, if a messaging engine fails over to another server, and then the original server becomes available again, the messaging engine automatically moves back to that server.
Each messaging engine is assigned to a specific server by configuring it to run only on servers in its list of preferred servers, then specifying only two servers in that preferred servers list. Each server is the first preferred server for one messaging engine and the second preferred server for another one, which creates the circular relationship between the servers. Failback is enabled so that each messaging engine is always hosted by its preferred server if that server is running.
Both servers that can host a specific messaging engine must be able to access the message store (either a database or a file system) configured for that messaging engine.
Use the scalability with high availability policy for a system where to add more servers to a cluster without affecting the existing messaging engines, but we also want to ensure that messaging is always available.
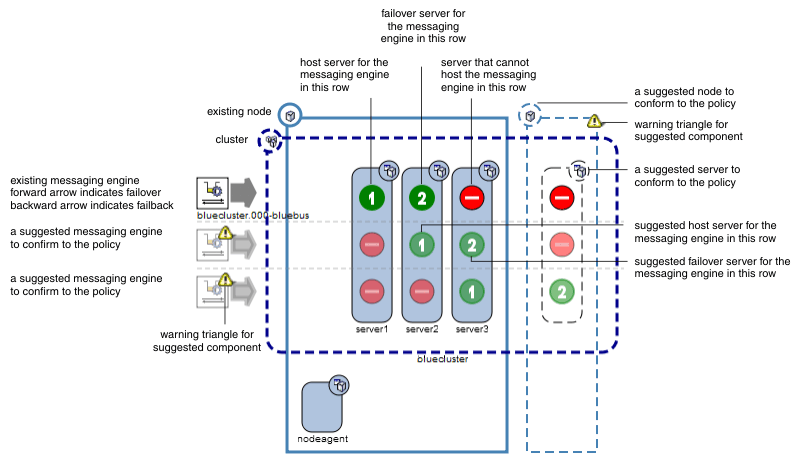
When you select the scalability with high availability messaging engine policy type on the console, a diagram shows the selected cluster and the eventual outcome of the policy.
If there are no warning triangles in the diagram, and the Is further configuration required? column shows No in the Scalability with high availability row, the topology of the cluster and the configuration of the messaging engine is suitable, and we can continue.
If there are warning triangles in the diagram, examine the messages in the Scalability with high availability row for guidance on how to achieve a suitable messaging engine configuration.
If we require high availability in a cluster, that cluster should contain at least two nodes, each with a server on it, that is, there should be at least two separate physical machines in the cluster. If the messages advise you to add another server on another node, you must go back and redefine the topology of the cluster before we add the cluster as a member of a bus.
For example, the following figure shows three servers configured on one node. If that node fails, there will be no servers available for any of the messaging engines to fail over to. To provide some high availability, there must be at least one other server on a separate node to ensure that there is a server on which at least one messaging engine can run. Also, there is only one messaging engine configured. To provide some scalability, there must be one messaging engine for each server.
Figure 1. Scalability with high availability policy selected without a suitable system configuration
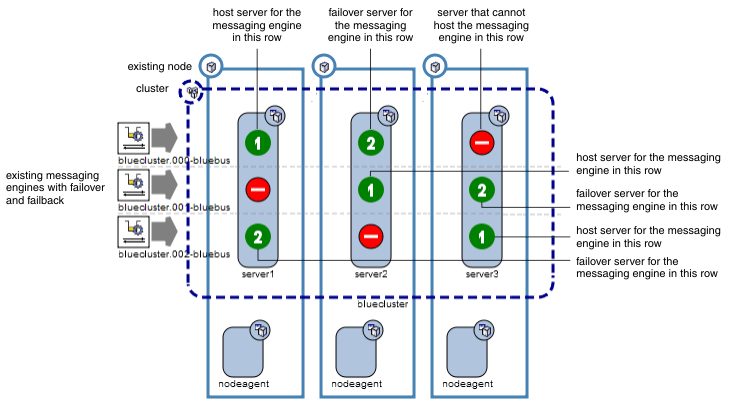
The figure two is an example of when the messaging engine configuration is suitable for the scalability with high availability policy. There are three servers, each on a separate node, and three messaging engines. Each messaging engine has a preferred server and one other server it can use for failover. Each server is the preferred host for one messaging engine, and the failover host for one other messaging engine. There are no warning triangles and no faded out components because the policy can be used successfully.
Figure 2. Scalability with high availability policy selected with a suitable system configuration
The following table shows the messaging engine policy settings for a cluster of three servers that use the scalability with high availability messaging engine policy.
| Messaging engine name | Failover | Failback | Preferred servers list | Only run on preferred servers |
|---|---|---|---|---|
| clustername.000-busname | true | true |
| true |
| clustername.001-busname | true | true |
| true |
| clustername.002-busname | true | true |
| true |
The predefined scalability with high availability messaging engine policy creates a configuration with aspects of scalability and high availability. It is not the only way to configure a cluster to provide scalability and high availability, but it is a frequently-used configuration. If we have other requirements, for example, message transmission is a priority and to increase the number of possible locations for each messaging engine, we can use the custom messaging engine policy.
For more information about configuration for high availability with scalability and workload sharing, see the related information.
Related concepts
Related tasks
Related information: