Parallel preprocessing and distributed indexing
We can index large catalog data into the search server with parallel preprocessing and distributed indexing by sharding and merging.
Data can be split either horizontally or vertically into different threads, so that each thread can process smaller chunks of the data. This approach is useful when the catalog size is large, or when preprocessing and indexing times are not acceptable. After the data is processed, it is merged into a single master data set. Depending on if the data was split horizontally or vertically, the merging of the data occurs in different levels. The number of shards or the size of the data each shard contains typically depends on available software and hardware resources.
Horizontal shards run independently and can preprocess and index data. Vertical shards can only preprocess data. When using a combination of shard types, horizontal shards depend on the vertical shards. That is, none of the horizontal shards can begin indexing until all the vertical shards complete their preprocessing. Shards can be created to either include horizontal shards only, or a combination of horizontal and vertical shards.
Note: Be aware of the following restrictions for parallel preprocessing and distributed indexing:
- Sharding does not replace the existing build index RESTFul API. Instead, it is used as a fast path for indexing catalog entry data.
- Sharding supports only full index builds. Sharding is not required for delta updates because they do not typically perform poorly.
- Sharding is used only for changes to approved content. It is not used for changes to workspaces.
- Contract price data is not supported by the shard indexing utility.
- This approach is not supported by a Derby database.
The following sections define the shard types and processes that are performed for each type, including indexing approaches.
Horizontal shards
Horizontal shards process a predefined number of catalog entries independently of the other horizontal shards. It processes multiple catalog entry properties at the same time. The following processes occur for horizontal shards:
- Horizontal shards preprocess the catalog entry data into its own temporary tables.
- The preprocessed data is indexed into a separate index core.
- The indexed data is then later merged into a final master index.
After processing horizontal shards, the final data format that is produced is indexed data.

Vertical shards
Vertical shards process only one property of all the catalog entries. That is, only one operation is performed in vertical shards: Preprocessing the data into a temporary table.
Due to Solr indexing requirements, the entire Solr index document’s fields must be available when the document is created. This limitation means that vertical sharding is not supported for WebSphere Commerce Version 9 releases before 9.0.0.7.
After processing vertical shards, the final data format that is produced is preprocessed data.
To enable vertical sharding, see Enable vertical and horizontal sharding.
Shard indexing approaches
The shard indexing utility (di-parallel-process) supports the following index approaches by default:- Indexing only horizontal shard types, or
- Indexing a combination of horizontal and vertical shard types.
Indexing only horizontal shard types
Indexing only horizontal shard types results in all of the shards preprocessing at the same start time. They are run in parallel, independently of each other. After any of the shards completes preprocessing, it can immediately start indexing its preprocessed data into its own index core.
After all shards are indexed, an index merge command is triggered to merge all shard indexes into a single master index. Since all horizontal shards produce indexed data, the resulting merge works with indexed data for the master index. The following diagram shows the process for indexing only horizontal shard types:
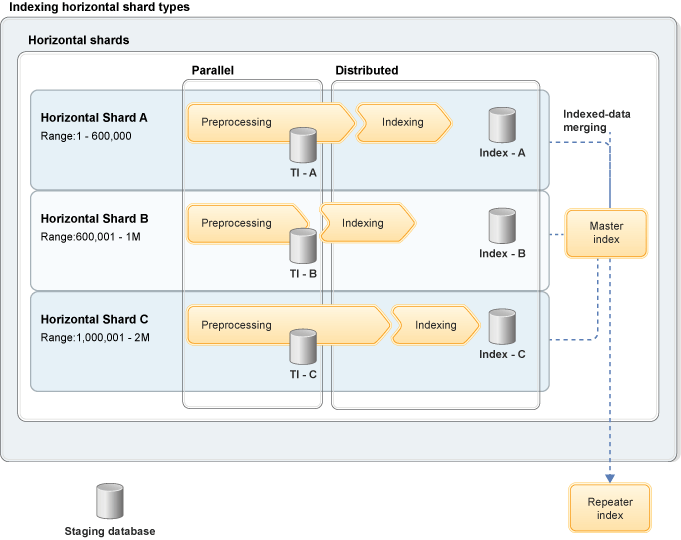 Where:
Where:
- Shards, A, B, and C process different range sizes.
- All shards start preprocessing at the same time.
- Each of the shards writes into its own temporary tables. Due to the different range values, each preprocess completes at different time.
- Indexing of each shard starts immediately after its preprocessing task completes. Therefore, the indexing starts and ends at different times.
- After all the shards complete their indexing, a merge command is sent to merge the three different shards indexed data into the master index. Then, the data is replicated into the repeater index.
Indexing horizontal and vertical shard types
Indexing a mix of horizontal and vertical shards type is slightly different from indexing horizontal shards only. While the preprocessing of all shards can start at the same time, the horizontal shards indexing can begin only after all the vertical shards complete their preprocessing. The horizontal shards indexing scripts read data from both its own shard’s temporary table, and the vertical shard's temporary table. The following diagram shows the process for indexing horizontal and vertical shard types:
 Where:
Where:
- All shards' preprocessing tasks begin at the same time.
- Horizontal shard B completes its preprocessing task, however remains idle until the vertical shard preprocessing completes.
- After the vertical shard preprocessing completes, the indexing can begin.
- The vertical shard has only a preprocess task, results in preprocessed data to be merged by the horizontal shards, in addition to their own preprocessed data. After the indexing tasks are complete, a merge command is sent to merge the horizontal shard's indexed data into the master index, then replicated into the repeater index.
By default, the catalog hierarchy is only supported for a vertical shard. However, we can create custom vertical shards to suit your requirements. The following criteria help to identify which preprocessing XML files must be made common and run in different shards:
- If any of the temporary tables in the identified preprocessing XML file take longer to preprocess than other tables
- If no other temporary tables depend on the identified XML file's temporary tables
- If none of the temporary tables in the identified preprocessing XML file join with the particular shard table (TI_CATENTRY_0_#SHARD_TAG#)
If any of these conditions are true, then it can be moved into its own shard and removed from each of the individual shards. For example, the wc-dataimport-preprocess-parent-catgroup.xml file calculates indirect parent categories that a catalog entry has.
For more information and an example hybrid (horizontal and vertical) sharding configuration, see
Enable vertical and horizontal sharding.
- Creating and indexing shards
We can set up and index a specified number of sharding cores by defining them in an input properties file and running the parallel-process utility in the Utility server Docker container. - Enable vertical and horizontal sharding
Only horizontal sharding is enabled by default in WebSphere Commerce Version 9. We can use vertical sharding with horizontal sharding if you enable the feature. - Sharding input properties file
The sharding input properties file is a file created that is passed in to the di-parallel-process utility when indexing shards. - Building indexes by shard using multiple JVMs
When indexing takes too long, and further tuning does not seem to help, it could be that your server is approaching its physical limitations. To avoid such a condition, we can distribute the index across two or more Search servers, so that the indexing workload is also distributed. We can distribute your index across multiple Java Virtual Machines.