IBM J9 JVM features
The following list highlights the features of the IBM Java5 J9 JVM, as compared to a generic JVM:

| 
|
| Shared classes |
|
|
|
| Type safe and generational garbage collection |
|
|
|
| Asynchronous, queued compilation in a background thread |
|
|
|
| Five levels of code optimization with continuous sampling and profiling |
|
|
|
| Support for large page sizes |
|
|
|
| Numerous RAS and serviceability enhancements |
Each of these features exploits the strengths of the underlying platform to accelerate any application running within the JVM (that is, the WAS). The IBM J9 JVM code is continuously optimized, from a speed and memory utilization perspective, to exploit the platform.
The following sections Lets look at the most important of these in depth.
Just-in-Time (JIT) Compiler: optimization and compilation
Another key feature of the IBM J9 JVM on which WAS on AIX runs is the way in which Java byte code is turned into native code. Traditionally, the JVM loaded the byte code for each Java class it encountered during its execution and either executed it directly via interpretation or used a synchronous JIT compiler to turn the class into native code for executing on the real machine directly. The key to this behavior is that traditional Java execution of native code is synchronous and static; that is, after the code is native, that is the way it stays.
The IBM current J9 JVM for AIX, and other platforms, borrows methods from optimizing compiler and the database server design disciplines. Indeed, the some of the technology in the JIT Compiler itself is independent of Java and might well be used with static C or Fortran front-ends. The Java Virtual Machine is running code dynamically to achieve its ends, so it needs to disable the AIX 5.3 TL03 Stack Execution Disable setting in order to execute code it generates and runs on its stack. It does this through the use of the DEP_EXEMPT flag in the XCOFF header of the Java launcher. This is perfectly safe for the JVM process and does not affect the rest of the system.
The Java instruction set is not the same as the native code instruction set, so at load time the Java byte code is data. It is not until that byte code is translated to native code that the underlying platform sees it as real code and can handle management of the processor caches; perform instruction pre-fetches; load the Java stack variables and heap references into the data cache; populate processor registers, and so on. RISC processors, such as the IBM POWER family and those underlying most modern CISC processor implementations, rely on this information to maximize performance through appropriate processor resource allocation and scheduling.
When the IBM J9 JVM runs, it looks ahead and compiles Java byte code to native code asynchronously on a background thread, but it does not stop there. As in a database server, the background thread uses statistics and heuristics in its processing. So, when the asynchronous background thread first compiles a method to native code, it uses heuristics to work out the costs and benefits of compiling and optimizing the code to different levels for better memory and processor performance. These heuristics are important because there is no point in wasting expensive processing resources in compiling to the highest levels of performance if the code is only run once and does not take much time to run anyway.
But how, you may wonder, does the JIT compiler running on the background thread know how often the code will execute? Like a database server, it collects statistics, via JVM interpreter sampling, JIT compiler sampling, or even by the insertion of profiling hooks into the code itself. This is best explained with a step-by-step example.
Suppose the background thread finds a class myClass with a method myMethod that will take 0.2 milliseconds to run unoptimized and 0.1 milliseconds to run optimized. If the optimization process takes 0.1 milliseconds and the method is only run once, then there is no benefit in optimization because the outcome is the same either way, with an overall execution time for compilation and execution of 0.2 milliseconds. However, if the code is executed hundreds of times, then there is a benefit in taking that 0.1 millisecond cost up front.
The IBM J9 JIT compiler and JVM goes further than this example; it offers five levels of execution (for example, interpretation, compilation and multi-level optimization) and the background thread collects statistics on how often everything is used. If a class method is used to the point where it appears that further optimization is necessary, the byte code is recompiled to a further level of optimization on the background thread and then transactionally replaced in the native code store for later use. What this means is that a traditional WAS application-and even WAS itself-gets faster over time with more use because the optimization occurs continually to produce faster and more efficient native code. This is known as dynamic recompilation with runtime execution profiling.
The process is as follows:
| 1. | Each method starts out being interpreted; that is, level 1. This runs on the JVM directly. |
| 2. | After a number of invocations, the heuristics are used to compile the byte code at cold or warm level. |
| 3. | The background sampling thread is used to identify "hot" methods. |
| 4. | When at a hot level, a profiling step may be used to decide how and whether to transition to a scorching level. Certain hot methods are identified as "hot enough" to be recompiled with profiling hooks inserted. |
| 5. | The profiled hot methods that require further optimization are transitioned to scorching level. |
The JIT Compiler and Interpreter both sample the usage of methods to make the decision as to when the optimization is necessary. This includes deciding when profiling hooks should be inserted into the hot code to determine the requirements of transitioning to a scorching optimization level.
Many types of optimization are available in the JIT Compiler with the IBM J9 JVM:
|
|
|
| Inlining |
|
|
|
| Cold block outlining |
|
|
|
| Value propagation |
|
|
|
| Block hoisting |
|
|
|
| Loop unroller |
|
|
|
| Asynchronous check removal |
|
|
|
| Copy propagation |
|
|
|
| Loop versioning |
|
|
|
| Common sub-expression elimination |
|
|
|
| Partial redundancy elimination |
|
|
|
| Optimal store placement |
|
|
|
| Simplifier |
|
|
|
| Escape analysis |
|
|
|
| Dead tree removal |
|
|
|
| Switch analysis |
|
|
|
| Redundant monitor elimination |
Readers who are familiar with C and C++ compilers should find themselves on familiar territory here because these are all features found in compilers such as Visual Age C++. Add to these Full Speed Debug and Hot Code Replace and you can see features that show that Java is no lacking when considering compiler performance optimization. Because all of this compilation and optimization takes place asynchronously on a background thread, there is little negative impact on the code execution.
Figure 5-8 illustrates IBM J9 JIT Compiler optimization.
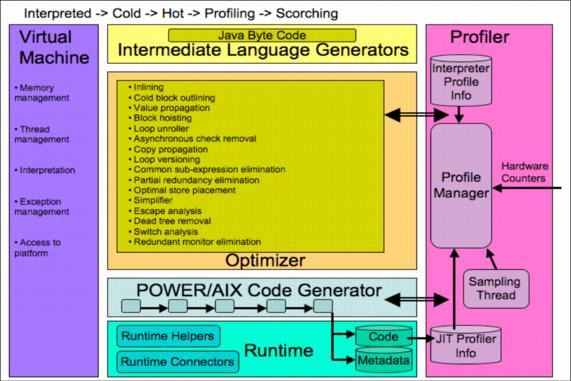
Figure 5-8 IBM J9 JIT Compiler optimization
Note that most methods in WAS are not hot, so they do not get fully optimized. However, methods that are hot and are part of the key working set will transition to the higher compilation levels fairly quickly.
One particular optimizer feature of interest is the use of micropartitioning and how the physical and virtual processors available are handled by the JVM. If there is only one physical processor running one physical thread, then there is no need of protection from multiple accessors to shared memory, resources, and so on, so the optimizer removes all locking to get further performance increases. Therefore, contrary to common perception, using one processor may be relatively faster than using two processors with more than one processor's worth of CPU allocation across them, because all of the synchronization overheads have been removed.
All of these features of the JIT Compiler optimization are used, not merely on the code deployed to WAS, but also to the WAS code itself, with the WAS working set moving towards its most optimal performance over a period of time as the code is executed in real production usage patterns. If the usage patterns change, the code optimizations in use may also change because this is a dynamic behavior, not a static one.
Shared Classes
The Shared Classes feature improves startup of multiple WebSphere instances and reduces the memory footprint of subsequent instances. Essentially, the Shared Classes feature of the J9 JVM is a cache of commonly used classes across a set of JVM instances. Each class is split into its immutable and changeable parts and stored separately in shared memory and local memory; the ROMClass and the RAMClass respectively.
The current Java 5 J9 JVM stores the shared classes in shared memory to allow it to be accessed between processes, with a semaphore protecting the shared memory region from multiple JVMs writing to it. The details regarding the names of the shared memory regions and the semaphores can be found in the /tmp/javasharedresources file.
This implementation has a downside in that the shared memory is then not available for other processes, so IBM limited WAS usage of shared classes to 50 MB. This implementation is also not WPAR-friendly because shared memory is not accessible between WPARs. The recently released Java 6 J9 implementation uses memory mapped files so, Java6 processes do not have the 50 MB limitation. This will enable a future WAS implementation based on the Java6 JVM to have a far larger class cache (possibly holding all of WAS), which can be shared across WPARs.
The IBM implementation of the standard Java URLClassLoader has been changed to first look in the cache for the ROMClass rather than keep going back to disk with each new JVM instance and reloading each class into local JVM process memory. Thus, startup time of subsequent JVM instances is greatly improved due to reduced disk activity and the virtual memory footprint of each subsequent JVM instance is reduced because it is loading the ROMClass information from virtual memory directly rather than loading it from disk into its own address space.
There are downsides to this approach, but IBM has addressed them. Any Java code that subclasses the standard URLClassLoader, which is common, will benefit from the shared class cache. Code that does not use the shared class cache can be made to use it through the help of IBM provided helper APIs, such as in the com.ibm.cds_1.0.0.jar file used within the OSGI/Eclipse framework underlying WAS. Instrumented code also changes, so the cache needs special handling. Protection is needed to ensure that JVMs started by different users can only see what they are meant to see, so multiple caches are supported on a system.
Java parameters are provided within the Java runtime to allow class sharing to be examined, with the -Xshareclasses option switching on class sharing and allowing monitoring through its suboptions, and -Xscmx to control the cache size for cache creation. Note that -Xscmx only has any effect if the -Xshareclasses option is used.
The suboptions for the -Xshareclasses option allow listing of all the caches in use and their usage count and printing of statistics on the number of classes that are cached.
To create a cache named myCache of 10 MB that holds the classes used by Java application class myClass, use this command:
java -Xshareclasses:name=myCache -Xscmx10M myClass
To destroy the cache named myCache, use this command:
java -Xshareclasses:name=myCache,destroy
To print the basic statistics for the cache named myCache, use this command:
java -Xshareclasses:name=myCache,printStats
To print detailed statistics for the cache named myCache, use this command:
java -Xshareclasses:name=myCache,printAllStats
To list all of the caches in use in the system, use this command:
java -Xshareclasses:listAllCaches
For all options, apart from creating the cache, it is normal to get a message stating: Could not create the Java virtual machine.
What happens with shared classes for WAS on AIX?
Examining the output of the ps -eaf command shows that WAS enables class sharing:
-Xshareclasses:name=webspherev61_%g,groupAccess,nonFatal -Xscmx50M
This syntax creates a 50 MB shared class cache that is accessible by all JVMs started by users in the same primary UNIX group as the user starting this instance. Thus, if root starts WAS (which we do not advise), the %g parameter maps to the system group and a cache accessible by all WAS instances started by members of this group is created that is called webspherev61_system, from the preceding command.
If a normal user in the "staff" primary group starts a WAS instance, then a separate shared class cache is created called webspherev61_staff and no ROMClass data is shared between these caches.
Normally, a wasuser account and wasgroup group are used for the application server instances as best practice, so using java -Xshareclasses:listAllCaches provides the output shown in Example 5-27.
Example 5-27 listAllCaches output

# /usr/IBM/WebSphere/AppServer/java/jre/bin/java -Xshareclasses:listAllCaches Shared Cache OS shmid in use Last detach time webspherev61_system 1048576 2 Thu Jun 14 23:31:27 2007 webspherev61_staff 3 1 Thu Jun 14 23:20:17 2007 colin 3 1 Thu Jun 14 23:20:17 2007 webspherev61_wasgroup 1048576 2 Thu Jun 14 23:31:27 2007
Could not create the Java virtual machine.

Example 5-27 shows that there are multiple WAS JVMs in use that have been started by users under different primary groups, and that there are also multiple JVMs using two of the caches. Also, a JVM has created a cache called colin.
Example 5-28 displays the contents of one of the caches, which shows how WAS is using the cache.
Example 5-28 Sample cache statistics
# /usr/IBM/WebSphere/AppServer/java/jre/bin/java -Xshareclasses:name=webspherev61_wasgroup,printStats Current statistics for cache "webspherev61_wasgroup": base address = 0x0700000010000090 end address = 0x07000000131FFFF0 allocation pointer = 0x0700000012FB1510 cache size = 52428656 free bytes = 1320004 ROMClass bytes = 50009216 Metadata bytes = 1099436 Metadata % used = 2% # ROMClasses = 11397 # Classpaths = 9 # URLs = 23 # Tokens = 0 # Stale classes = 0 % Stale classes = 0% Cache is 97% full Could not create the Java virtual machine.
The output in Example 5-28 shows that the cache is stored in a virtual memory region starting at segment 0x07000000 for the 64-bit JVM process, the first shared memory segment, and with WAS running with no additional applications the 50 MB cache is 97% full with 11397 classes. Example 5-28 illustrates usage of the printAllStats command line option to show that a large part of the cache contains the core Java standard library.
Example 5-29 Sample cache statistics, using printAllStats
# /usr/IBM/WebSphere/AppServer/java/jre/bin/java
-Xshareclasses:name=webspherev61_wasgroup,printAllStats
Current statistics for cache "webspherev61_wasgroup":
1: 0x07000000131FF7A8 CLASSPATH
/usr/IBM/WebSphere/AppServer/java/jre/lib/ext/ibmorb.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ext/ibmext.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/vm.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/core.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/charsets.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/graphics.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/security.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmpkcs.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmorb.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmcfw.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmorbapi.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmjcefw.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmjgssprovider.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmjsseprovider2.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmjaaslm.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/ibmcertpathprovider.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/server.jar
/usr/IBM/WebSphere/AppServer/java/jre/lib/xml.jar
1: 0x07000000131FF748 ROMCLASS: java/lang/Object at 0x0700000010000090.
Index 2 in classpath 0x07000000131FF7A8
1: 0x07000000131FF708 ROMCLASS: java/lang/J9VMInternals at 0x0700000010000718.
Index 2 in classpath 0x07000000131FF7A8
1: 0x07000000131FF6C8 ROMCLASS: java/lang/Class at 0x07000000100020E0.
Index 2 in classpath 0x07000000131FF7A8
1: 0x07000000131FF688 ROMCLASS: java/io/Serializable at 0x0700000010008630.
Index 3 in classpath 0x07000000131FF7A8
1: 0x07000000131FF648 ROMCLASS: java/lang/reflect/GenericDeclaration at
0x07000000100086F0.
Index 3 in classpath 0x07000000131FF7A8
1: 0x07000000131FF608 ROMCLASS: java/lang/reflect/Type at 0x0700000010008840.
Index 3 in classpath 0x07000000131FF7A8
1: 0x07000000131FF5C8 ROMCLASS: java/lang/reflect/AnnotatedElement at
0x07000000100088F8.
Index 3 in classpath 0x07000000131FF7A8
...
Note, in Example 5-28, that the cache is 97% full. You might be wondering if a bigger cache would be beneficial for running large application server work loads. This may be correct, but the law of diminishing returns and tradeoffs comes into play in this analysis.
In practical terms, a JVM should be limited to about 3 to 4 GB of heap space to avoid garbage collection performance issues (for which multiple instances is the answer) and the cache eats into this. Too much usage of shared memory also impacts other processes, so it should be used sparingly. However, many administrators would still want to control the cache size themselves and make their own decisions as to the setting for -Xscmx.
You will not find this configuration setting in scripts, properties files, and other configuration elements. The setting is added to the command line dynamically by the WsServerLauncher class, which is found in the core com.ibm.ws.runtime_6.1.0.jar file.
The configuration for it and other command line options is found in the aix.systemlaunch.properties file inside the com.ibm.ws.runtime_6.1.0.jar JAR file from the application server plugins directory. Example 5-30 shows the contents of that file.
Example 5-30 aix.systemlaunch.properties file

# Default system properties
# Default environment settings
com.ibm.websphere.management.launcher.defaultEnvironment=EXTSHM=ON
# Default JVM options
com.ibm.websphere.management.launcher.defaultJvmOptions=-Declipse.security
-Dosgi.install.area=${WAS _INSTALL_ROOT}
-Dosgi.configuration.area=${USER_INSTALL_ROOT}/configuration -Djava.awt.headless=true
-Dosgi.framework.extensions=com.ibm.cds
-Xshareclasses:name=webspherev61_%g,groupAccess,nonFatal -Xscmx50M

The implementation of shared classes is documented to some extent, but can readily be seen through a simple view of the file system. Inside the /tmp directory, a subdirectory is created by the shared classes option when it is first run, called javasharedresources. Inside this subdirectory is evidence of the caches created and their reliance on UNIX system V features to implement the cache management; that is, shared memory to hold the cache and semaphores to lock the cache access to manage multiple accesses.
The JVM shared classes implementation knows to look in this directory to find the key management information for managing access to the shared classes from multiple JVMs. The contents of this directory are shown in Example 5-31, and the process illustrated in Figure 5-9.
Note that it is the ROMClasses that are stored in the cache (Java byte code), rather than native code itself. The native code is stored and handled by the JIT compiler owned by each JVM.
Example 5-31 javasharedresources directory listing

# ls /tmp/javasharedresources C230D1A64_memory_colin_G01 C230D1A64_memory_webspherev61_wasgroup_G01 C230D1A64_semaphore_webspherev61_system C230D1A64_memory_webspherev61_staff_G01 C230D1A64_semaphore_colin C230D1A64_semaphore_webspherev61_wasgroup C230D1A64_memory_webspherev61_system_G01 C230D1A64_semaphore_webspherev61_staff

Figure 5-9 illustrates the IBM J9 JVM shared classes.
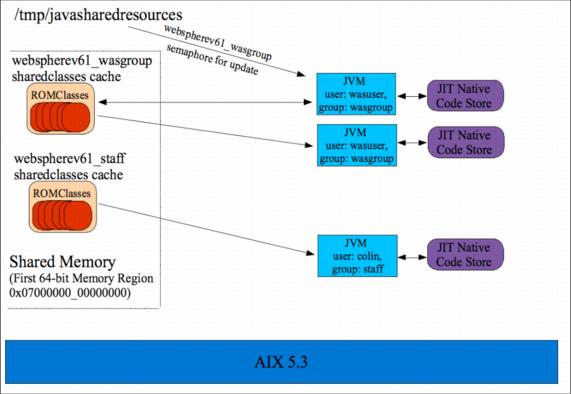
Figure 5-9 IBM J9 JVM shared classes
Now that you have seen how it works, you might be wondering why this is all necessary. The main benefits of using shared classes include greatly improved startup time of each JVM using the shared cache, and a decrease in overall memory resource requirements.
To best illustrate this, we used a memory-constrained single processor POWER3™ machine with 1 GB of RAM; this machine used to struggle running multiple instances of WebSphere 6.0.2.
Example 5-52 shows the time taken to load multiple instances, using the root account to avoid any impact of other limits. This example displays the benefit of the cache directly.
Example 5-32 Benefit of using shared classes

# ./timeit.sh Listing caches JVMSHRC005I No shared class caches available Could not create the Java virtual machine. About to start instance 1 at: Sat 16 Jun 21:00:36 2007 ADMU0116I: Tool information is being logged in file /usr/IBM/WebSphere/AppServer/profiles/sandpit2/logs/server1/startServer.log ADMU0128I: Starting tool with the sandpit2 profile ADMU3100I: Reading configuration for server: server1 ADMU3200I: Server launched. Waiting for initialization status. ADMU3000I: Server server1 open for e-business; process id is 303260 Instance 1 completed loading at Sat 16 Jun 21:04:50 2007 Shared Cache OS shmid in use Last detach time webspherev61_system 5242880 1 Sat Jun 16 21:01:20 2007 Could not create the Java virtual machine. About to start instance 2 at: Sat 16 Jun 21:04:51 2007 ADMU0116I: Tool information is being logged in file /usr/IBM/WebSphere/AppServer/profiles/sandpit/logs/server1/startServer.log ADMU0128I: Starting tool with the sandpit profile ADMU3100I: Reading configuration for server: server1 ADMU3200I: Server launched. Waiting for initialization status. ADMU3000I: Server server1 open for e-business; process id is 213026 Instance 2 completed loading at Sat 16 Jun 21:08:05 2007 # /usr/IBM/WebSphere/AppServer/java/jre/bin/java -Xshareclasses:listAllCaches Shared Cache OS shmid in use Last detach time webspherev61_system 5242880 2 Sat Jun 16 21:05:29 2007 Could not create the Java virtual machine.

The output in Example 5-32 shows that the first instance of WAS took 4 minutes and 14 seconds to start. The second instance took 3 minutes and 14 seconds to start. The second instance took 76% of the time of the first instance to start up. This improvement is important for restarting after a failure when vertical scaling and clustering is used (that is, multiple instances in a single operating system image).
The benefit to memory usage is also significant, and can be seen when looking at the resident set size (RSS) and virtual memory size (SZ) in pages, by using the ps command as shown in Example 5-33. In the example, the first instance shows a virtual memory usage of 84124 x 4K pages, or 328 MB. The second instance shows 78380 x 4K pages, or 306 MB.
This 22 MB saving may not seem that significant, but this environment is not running anything but base WAS, so in production use the savings could be enough to allow support for a much larger number of user sessions in a JVM or a few more JVM instances running in the system. In practice, the savings due the shared class cache are usually much larger than is seen here.
Example 5-33 Shared classes: memory usage

# ps aux USER PID %CPU %MEM SZ RSS TTY STAT STIME TIME COMMAND ... root 303260 8.1 10.0 84124 84128 pts/0 A 21:01:19 3:19 /usr/IBM/WebSphe root 213026 7.3 9.0 78380 78384 pts/0 A 21:05:29 2:41 /usr/IBM/WebSphe ...

Page sizes
AIX has supported multiple page sizes, configured using the vmo command, for a few releases, with 16 MB supported from AIX 5.1, and 64 K and 16 GB pages supported in AIX 5.3 TL04 on a POWER5+™ machine, as well as the more traditional 4 K page size. A 64 K page is for general usage, with the 16 MB and 16 GB options for large memory and high performance applications. As previously, the 4 K page size is the default but now AIX will automatically make use of some 64 K pages when the system could benefit from it.
The J9 JVM can make use of the AIX support for multiple page sizes via the -Xlp <size> option to use large pages for the heap. This can further improve the memory behavior previously discussed. For the most benefit with minimal effort, use -Xlp64K to make use of 64 K pages; however, this will only work from AIX 5.3 TL04 onward on a POWER5+ or above, and the benefit varies greatly with the type of system usage. For more information about using large pages, refer to 6.6, Using large page sizes.
Garbage collection
Java was designed to be a "safe" language, with the complexities and risky features of C and C++ removed and strong typing. One of the risky features is support for developer-controlled memory management, in which a developer who allocates memory is also responsible for freeing it. Java uses a garbage collection mechanism to relieve developers of the responsibility of tidying up memory management.
Java garbage collection is not "magical" and the mechanism can still be overwhelmed by poor coding practices such as creating millions of unnecessary objects (that is, using immutable strings in buffers). The developer has no control over when garbage collection is run, which can lead to "stalls" in a production environment when the garbage collector has to run to make space and compact the heap.
Recognizing that this is a common problem, but also that usage patterns are not all alike, IBM has included the ability to tune the garbage collector for different behavior. However, controlling the garbage collection policy can only assist, but not eliminate, the performance issues inherent in a poorly coded application.
For an in-depth discussion of garbage collection policy and tuning the IBM JVM. see 6.1, The importance of JVM tuning through 6.4, Heap sizing in Chapter 6, Tuning the IBM Java Virtual Machine.
DLPAR support
The JVM has classes that extend java.lang.management to detect changes in processor and memory resources in a DLPAR environment. Events are triggered from the JVM, which code can subscribe to; see 6.7, Dynamic logical partitions, for more details.
Memory allocation control and malloctype
With 32-bit applications, control of the way the C malloc call made use of space on one or more heaps was more important for high performance than it is today. Heaps could be split into buckets, and some applications were dependent on a particular behavior from AIX3.1.
Although things have greatly improved, it is still possible to control the use of the heap using the AIX malloctype and mallocoptions environment variables, but performance benefits are likely to be small for all but the most demanding applications. Note that it is the native heap that is controlled by these options rather than the Java heap, but the JVM will respect the settings for the native heap.
Thus, if there is a WAS application that makes significant use of native library code calls that will result in numerous memory allocations, then it may be worth experimenting with the malloctype=Watson setting in particular that is available in AIX 5.3 to supplement the malloctype=default allocator commonly used for 64-bit code.
Threading and thread management
In the past, threading and thread management has been an issue on AIX, because the JVM has always used UNIX 98 User Mode threads for maximum performance. This could result in problems in communicating with other processes that were also using their own user mode threads, because there was no context for control of synchronization.
The default for AIX was always AIXTHREAD_SCOPE=P and AIXTHREAD_MNRATIO=8 for a mapping of 8 user mode threads to a single kernel mode thread. With the current release, the mode is simple and equivalent to kernel mode threads; that is, AIXTHREAD_SCOPE=S and AIXTHREAD_MNRATIO=1:1. These settings are now implicit within the JVM and are ignored by the JVM if set. From AIX 6.1 onward, this is the default setting for the operating system anyway.
Signal management
It is possible to disable some of the non-essential non-exception UNIX signals by using the -Xrs (reduce signals) setting. This can have a minimal performance benefit but in practical terms, it should be left alone unless instructed otherwise by IBM support. Similarly, the -Xnosigcatch and -Xsigcatch settings can be used to control what signals are caught and ignored by the JVM, and therefore WAS. But again, these settings should be left at their defaults unless you are instructed otherwise.