Create a datapool associated with a test
Overview
Datapools contain variable data for use by tests
Create a datapool
- Double-click a test

- In the Test Contents area, click the name of the test.

- In the Common Options tab, click Add Datapool.
- Select Use wizard to create new Datapool

- Select project and fill in name for new Datapool.

- On the next panel, enter a description.

You do not need to change the table dimensions when importing a CSV file. The number of rows will be populated based on the incoming data.
- On the next panel, select a CSV to import data from...
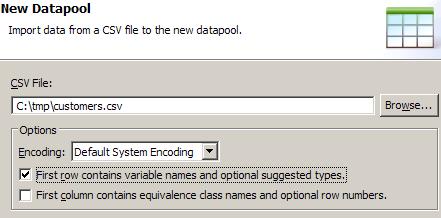
...where customer.csv contains something like...
-
userid,passwd
jennifer@new.com,jennifer
john@new.com,john
melinda@new.com,melinda
nick@new.com,nickUnless required, uncheck...
-
First column contains equivalence class names and optional row numbers
- The new Datapool should appear in Test Element Details panel for the test...
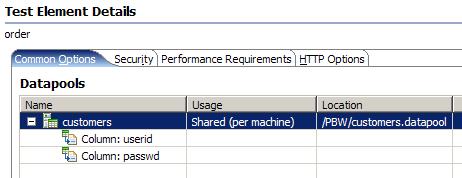
- Double-clicking the new datapool will show contents.

Datapool options
| To create | Test Editor | Add Datapool window |
|---|---|
| One-column datapool
Default access mode | In Existing datapools in workspace, select...
You can optionally name the datapool column in this session, and you can add other columns and data later. |
| One-column datapool
choose the access mode. | In Existing datapools in workspace, select...
You are prompted for the access mode. You can optionally name the datapool column in this session, and you can add other columns and data later. |
| Association test and existing datapool | Select the datapool.
The datapool is associated with the test, and you can optionally set the access mode in this session. |
| New datapool. | Select a project and click Use wizard to create new datapool. |
Datapool Open mode
Set the datapool open mode to configure how users see the data...
| Option | Description |
|---|---|
| Shared | All data in datapool is shared with every machine and every vuser. Default.
Virtual users on each computer draw from a shared view of the datapool, with datapool rows apportioned to them collectively in sequential order, on a first-come-first-served basis. Helps ensure that...
The exact row access order among all virtual users or iterations cannot be predicted, because this order depends on the test execution order and the duration of the test on each computer. |
| Private | Each virtual user draws from a private view of the datapool, with datapool rows apportioned to each user in sequential order. Each virtual user gets the same data from the datapool in the same order.
Because each user starts with the first row of the datapool and accesses the rows in order, different virtual users will use the same row. The next row of the datapool is used only if the test is put in a schedule loop with more than one iteration. |
| Segmented | Per machine.
Virtual users on each computer draw from a segmented view of the datapool, with data apportioned to them collectively from their segment in sequential order, on a first-come-first-served basis. The segments are computed based on how a schedule apportions virtual users among computers. For example, if a schedule assigns 25% of users to group 1 and 75% to group 2, and assigns these groups to computer 1 and computer 2, the computer 1 view will consist of the first 25% of datapool rows and the computer 2 view will consist of the remaining 75% of rows. This option prevents virtual users from selecting duplicate values (for example, account IDs). If you set no wrapping, no row can be used more than once. |
Access sequence
Options for how tests access the datapool include...
| Sequential | Rows in the datapool are accessed in the order in which they are physically stored in the datapool file, beginning with the first row and ending with the last. |
| Random | Rows in the datapool are accessed in any order, and any given row can be accessed multiple times or not at all. Each row has an equal chance of being selected each time. |
| Shuffled | Before each datapool access, the order of the rows is changed, and a different sequence results. Rows are accessed randomly but all rows must be selected once before a row is selected again. |
To set, double-click the datapool title.
Think of the nonsequential access order (Random and Shuffled) as being like a shuffled deck of cards. With Random access order, the selected card is returned anywhere in the deck, which means that one card might be selected multiple times before another is selected once. Because you never reach the end of the deck, Wrap when the last row is reached is unavailable.
With Shuffled access order, the selected card is returned to the bottom of the deck. After each card has been selected once, you either resume selecting from the top with the same access order (Wrap when the last row is reached is Yes), or no more selections are made (Wrap when the last row is reached is No).
Fetch or wrap
| Option | Description |
|---|---|
| Wrap when the last row is reached | By default, when a test reaches the end of a datapool
or datapool segment, it reuses the data from the beginning.
To force a test to stop at the end of a datapool or segment, clear the check box beside...
Forcing a stop might be useful if, for example, a datapool contains 15 records, you run a test with 20 virtual users, and you do not want the last five users to reuse information. Although the test is marked Fail because of the forced stop, the performance data in the test is still valid. However, if it does not matter to application if data is reused, the default of wrapping is more convenient. With wrapping, you need not ensure that datapool is large enough when you change the workload by adding more users or increasing the iteration count in a loop. This option is unavailable with the Random option, because with random access, there is, in effect, no end of file. |
| Fetch only once per user | Specify that each access of the datapool from any test being run by a particular virtual user will always return the same row.
By default, one row is retrieved from the datapool for each execution of a test, and the data in the datapool row is available to the test only for the duration of the test. |
To illustrate how these options affect the rows that are returned, assume that a test contains a loop which accesses a datapool. The loop has 2 iterations.
Row that is accessed in each iteration...
| Datapool option | Iteration 1 | Iteration 2 |
|---|---|---|
| Sequential and Private | row 1 | row 2 |
| Shared and Shuffled | row x | row y |
| Fetch only once per user | row x | row x |
Import CSV files
If you are creating a fully functioning datapool, you can optionally import the data from a CSV file during this session. You can import data later by clicking...
-
File | Import | Test | Datapool
Next
Associat a test value with a datapool column.
Related