Publishing rules
Through example publishing scenarios, learn how to use the publishing features provided by the Personalization component of WebSphere Portal. Portal administrators see alternative server topologies that can help you to plan the deployment of your company's personalized portals. Here are some publishing scenarios and tasks to help you understand how to publish personalized portal content.
- Authoring versus run-time systems
- Scenario 1 – Using a separate authoring server
- Scenario 2 – Using a staging server
- An overview of Personalization publishing
- Examining the publish status
- Scripted or command-line publishing
- Publishing securely
- Publishing to a cluster
- Publishing to an IPv6 host
- Use resource collection classes
Authoring versus run-time systems
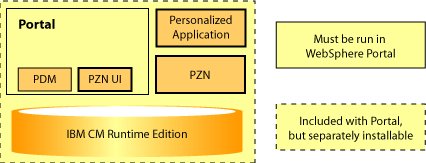
WebSphere Portal Personalization supports the ability to author rules and campaigns on one system and publish them to other systems. Systems on which rules are authored are referred to as authoring systems; the systems on which rules are executed are called run-time systems.
The authoring interface includes...
- Tools for creating rules in the IBM Content Manager runtime edition repository
- A set of portlets which provide a view of that repository
The run time includes a set of Java libraries to execute rules, and an IBM Content Manager runtime edition repository to store the rules. The distinction between the authoring and run-time servers is now merely how the servers have been purposed within your organization, rather than which components are installed on which server or where rules are stored.
Figure 1 shows the relationships among the Personalization authoring portlets (PZN UI), the Personalization run time (PZN), and your personalized application. The Personalization user interface and run time both use the same repository.
Scenario 1 – Using a separate authoring server
In the simplest publishing scenario, there are two servers between which you want to move rules. Typically, business users create and test rules on one server, and then either the business user or portal administrator publishes them to a production server. In Figure 2, the arrows indicate publishing possibilities. The blue arrow indicates the typical publishing step for moving a rule from a business user’s authoring environment to production.
The other arrows represent publishing steps that are possible, but are not encountered during every day use. Occasionally, customers have requested the ability to publish from a production portal back into their authoring environment. This is useful if some problems have arisen in your production portal which cannot be reproduced in your authoring or staging environments. In this case, you can “back-publish” to insure that your authoring or staging environment contains the same artifacts as your production environment. Although, ideally, all the artifacts are backed up sufficiently outside your production environment, you might need to back-publish for disaster recovery of the authoring system.

Scenario 2 – Using a staging server
You might decide to keep a full replica of your production system so you can perform your final verification tests before you make any changes to the production system. For this purpose, you could introduce a staging server. Switching your staging and production environment when your staging is certified is one way to move between staging and production. Your network can reroute traffic from the production system to the staging system at a desired point, turning the old production environment into the staging environment and the old staging environment into the production environment.
When rules change very infrequently and the very highest level of control over rules is required, rerouting your production traffic to your staging machine is a good option. When rules change frequently, when different rules change on different schedules, or when rules change on a different schedule than your binaries, this approach might be cumbersome because it requires frequent coordination with your network administrators.
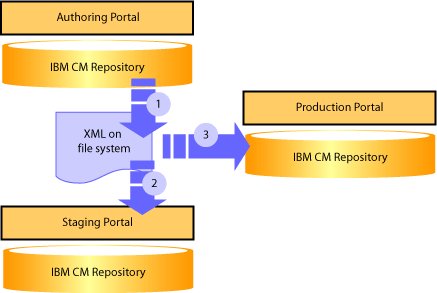
Another typical configuration of development, authoring, staging, and production is shown in Figure 3. In this scenario, you introduce two more servers. Developers might use one or more of their own sandbox portals or portal unit test environments. The test environments could also run locally on developer machines. A staging portal fully isolates quality assurance testing from developers and business users. All four installations are full WebSphere Portal installations, with both authoring and run time capabilities. The development portal could be a Rational Unit Test Environment.
Many organizations will be fully satisfied with a two server setup outlined in scenario one and do not need to consider introducing a staging server. On the other hand, if your organization has already planned to use a staging server for your other portal applications, then this configuration will support using that environment for personalization.
Figure 3. A typical installation with four portal servers

The blue arrows in the figures represent publishing steps required to move an artifact from authoring to production. By publishing directly from the staging portal to production, you can be sure that what is in production has always gone through staging. Use servlets secured with different credentials and firewalls to prevent publication directly from authoring to production.
These publishing steps could be initiated from the user interface or scripted from the command line. An XML file may be exported and then published from the command line. A user first exports the folders, rules, and anything else that needs to be published. The exported XML is handed off to a deployment team who publishes to a staging server for final verification and quality assurance testing. After final verification, the same XML file is published to the production portal. Using an intermediate XML file and having a controlled deployment process assures what is on your production portal has gone through staging, and lets you keep a backup of the exported XML to re-publish later.
You can include calls to the Personalization publish in your deployment scripts by calling the command line publish tool called PznLoad on exported XML files. Using the command line tools in deployment scripts can coordinate your publishes with other changes to your Portal. You see how to use the command line publish in a later section.
An overview of Personalization publishing
WebSphere Portal Personalization sends published objects across HTTP to a servlet which resides on each personalization server. This servlet can...
- receive publishing data
- initiate new publishing jobs
When a user begins a publishing job from the personalization authoring environment, the local servlet is provided with the set of information necessary to complete the job. The local servlet contacts the destination endpoint servlet (which could be the same servlet) and sends its data to it. The destination servlet reports success or failure.
To begin publishing personalization objects, you create an object in the authoring environment which describes the target endpoint. This endpoint definition is referred to as a publish server and is created and managed in a manner similar to creating and managing rules and campaigns.
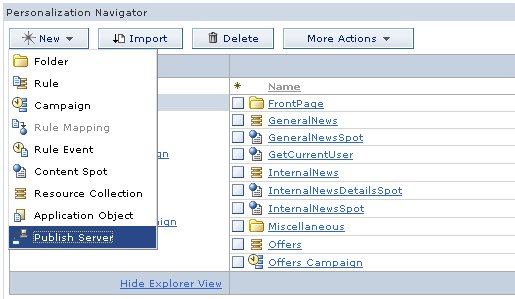
The server requires one field, the URL associated with the publish servlet for that endpoint. The publish server may also define which workspace will receive publishing data. Personalization operates in the default Content Manager run-time edition workspace after installation. If the target workspace field is empty, then the publish server uses the default workspace. (Set the workspace field if you are configuring scenario three described above.)
The last option is whether or not to delete remote objects that have been deleted on the local system. The default is Smart Delete, which simply removes items that are no longer present. If you do not have delete permission on the remote server you could select the Leave deleted resources on server option.
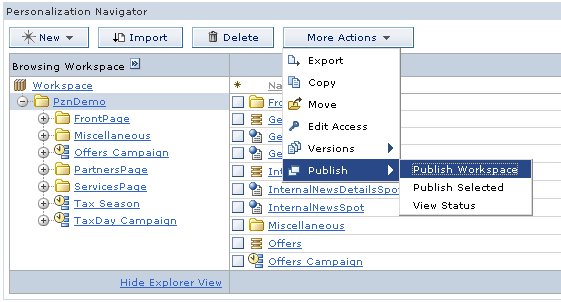
After you create a publish server, you can publish either the entire workspace or a set of objects within it. You specify either of these options by selecting...
More Actions | Publish submenu
Choosing either option opens a page similar to Figure 7.
Figure 6. Start a publish job
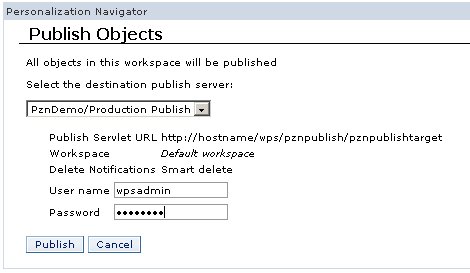
The Publish page displays what will be published. This page requires the user to choose a destination publish server and any necessary authentication information. If the remote system is secured and is not a member of the current server’s Single Sign-On domain you can enter a user name and password in the provided fields. The values for user and password are stored in the WebSphere Portal credential vault and are not accessible to any other user.
Finally, click Publish to launch the publish job.
Figure 7. Publish page
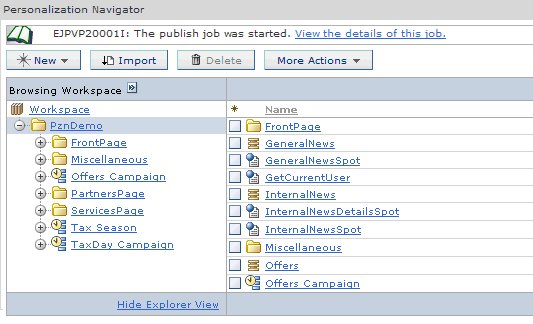
If the local system is able to locate and authenticate with the remote publish server, you are returned to the main navigator view, and you see the Personalization message EJPVP20001I at the top of the portlet. Then, the publish job runs as a background process on the local server. Click the View the details of this job link to open the publish status window to see information about the progress and success or failure of the publish job.
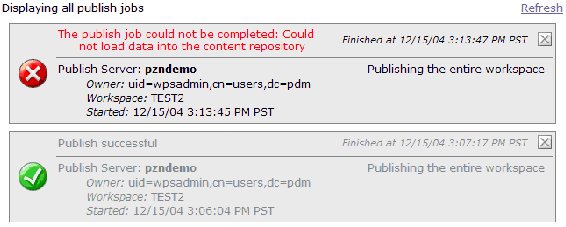
Examining the publish status
To see the status of all current publish jobs, select More Actions > Publish > View Status , or click the link that is provided when a publish job has successfully started. All publish jobs that are currently running or have been completed are displayed. After a job has completed (successfully or otherwise) a close icon displays in the upper right corner that you can click to remove the job from the list of monitored jobs. (If you click this icon, you can no longer view the status of that job.)
Figure 9. Publish status window
Scripted or command-line publishing
Use a WebSphere Portal Personalization provided command-line executable to load exported Personalization artifacts into a local or remote server. So, you can script the delivery of rules and campaigns from staging to production, or the offline publishing between disconnected systems (such as when production servers are secured behind a firewall). You can use this function to quickly revert production servers to an earlier state.
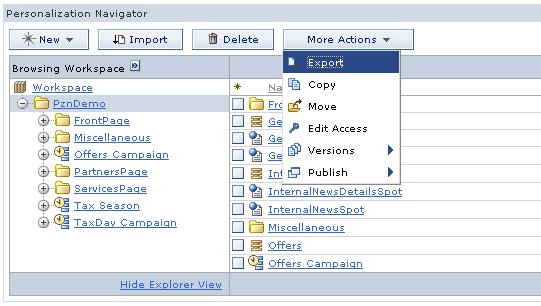
Publishing via the command-line is a two step process. First, you export the personalization objects you want to transfer from the authoring environment to a remote system. When you select More Actions Export in the Personalization Navigator portlet, you are prompted for a location to save a nodes file. This file contains an XML representation of all the currently selected personalization objects. You can export entire folders.
Figure 10. Exporting a folder to the file system
After exporting and saving the desired objects, you use the pznload executable to send this data to the desired server. The pznload executables are in portal_server_root
Once a publish is started, you see status messages in the command console. If an error occurs, to get more information, turn on the Java Run time Environment tracing for WebSphere on the client system or examine the error and trace logs on the server system.
WebSphere Portal Personalization uses the built-in SSL capabilities of WAS to provide secure publishing across unprotected networks. Your personalized portal can benefit from the full range of authentication repositories supported by WAS security.
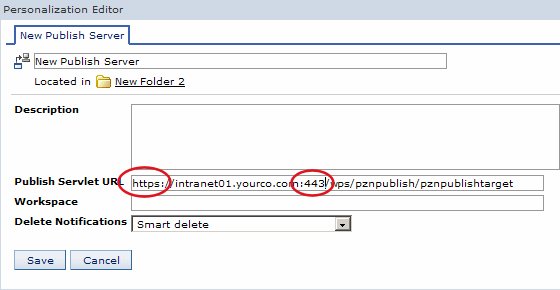
To enable Personalization publishing over SSL, see the Personalization Navigator's inline help: click the question mark in the upper right corner of the portlet, and scroll down to the bottom of the page to locate the link to the help topic on publishing. After you enable SSL between two Personalization servers you can enable its use for a specific publish server by adjusting the URL of the publish servlet to use the HTTPS protocol. If the remote server is not using the default HTTPS port of 443, modify the URL by adding a colon and the port number immediately after the host.name.
Figure 11. Altering the publish servlet URL for secure publishing
To initiate a publishing job the portlet makes a request to the publish servlet on the local server, which then communicates with its counterpart on the destination publish server.
If a Personalization server is configured to use a non-standard HTTPS port or context root, or if you see messages such as EJPVP20002E: The local publish service was not available when publishing from the authoring environment
the local publish servlet URL might be incorrect. To specify the correct URL for the local publish server:
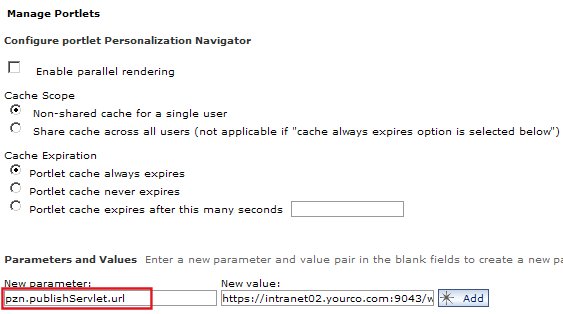
To determine whether a particular URL is valid, point your browser to that location and enter your username and password for the system. If you see the message Publish servlet available and all SSL certificates have been properly imported, you should be able to publish. You can change this URL to redirect all publish jobs through a specific cluster member.
Figure 12. Configuring the local publish service
In some environments even SSL publishing may not be secure enough. The pznload command-line program lets you fully control the transportation of the rules and campaigns during publish. You can encrypt the exported .nodes file and send it using e-mail, or use another secure channel such as physical media transported between the staging and production servers.
Publishing to or from a clustered environment requires no special configuration. The specific cluster member that will perform the publishing task is chosen by the same rules that apply to incoming Web requests (because the publishing mechanism uses HTTP messages). At the end of a successful publishing job, Personalization flushes its caches for that workspace to ensure that any subsequent personalized content will be as current as possible.
When you first used the Personalization authoring portlets on a cluster to publish objects, the Publish Status dialog, accessed through...
...only shows information about the publish jobs initiated on that cluster member. To make all publishing jobs visible, set pzn.publishServlet.url parameter described above to be a specific cluster member.
Set the URL to point to a single machine at the internal HTTP port:
For example, supposed the cluster head is visible at...
...and the cluster members are accessible at...
If you set the publish servlet URL parameter to...
...you force all publishing requests to run on this single machine.
It is suggested to publish to a single node in the cluster as opposed to the cluster head.
The server which initiates the publish command must have the IPv6 protocol stack installed and available. When publishing from the command line using pznload to an IPv6 host, you may need to set the system environment variable IBM_JAVA_OPTIONS to a value of...
...on the system where pznload is run.
You use resource collections in Personalization to access LDAP, IBM Content Manager, the Portal user object, or other custom sources of data.
The DB2 Content Manager run-time edition and the WebSphere Portal user resource collection classes are installed in the Personalization shared library. Therefore, you do not need to move these classes between systems because they are already installed with Personalization.
For LDAP resources, Rational Application Developer provides a wizard to generate classes which implement the resource collection interfaces.
To use the authoring portlet, all resource collection classes must be in the class path of the Personalization authoring portlet. The rule editor uses these classes to display the list of attributes belonging to the collection. If the resource collection classes are not found by the rule editor, you could see the following message in a JavaScript alert.
Figure 13. Message displayed when resource classes cannot be found
The resource collection classes must also exist on the class path of the application invoking the Personalization rules. The Personalization rules engine finds the resource collection classes using the class path of the application which invokes the rules. If you use the Personalized List portlet to display rule results, this application is the Personalized List application pznruleportlet.war in the Personalization Lists.ear.
So, the classes should be accessible to both the rule editor and the personalized application. An application server shared library is the easiest way to accomplish this. You can configure the shared library using the Application Server Administrative Console. For more information, see the sections on the shared library in the WAS Information Center.
You handle updates and additions to the resource collection classes just as you would handle updates to any application binary or JSP. These classes are not affected by Personalization publishing. The definition of the resource collection which Personalization uses to associate a resource collection with its classes is stored in the Content Manager repository. Initially represented by the .hrf file, this definition is published along with the rules and campaigns.
Publishing securely
Portlet Management | Portlets | | Personalization Navigator portlet | Configure portlet
Publishing to a cluster
More Actions | Publish | View Status
http://intranet.yourco.com
http://intranet01.yourco.com
http://intranet02.yourco.com
http://intranet01.yourco.com:10040/wps/pznpublish/pznpublishservlet
Publishing to an IPv6 host
-Djava.net.preferIPv4Stack=false -Djava.net.preferIPv6Addresses=true
Use resource collection classes

Parent topic
Use rules