Advantages of using shared queues
Shared queue allows for IBM MQ applications to be scalable, highly available, and allows workload balancing to be implemented.
The advantages of shared queues
The shared queue architecture, where cloned servers pull work from a single shared queue, has some useful properties:- It is scalable, by adding new instances of the server application, or even adding a new z/OS image with a queue manager (in the queue sharing group) and a copy of the application.
- It is highly available.
- It naturally performs pull workload balancing, based on the available processing capacity of each queue manager in the queue sharing group.
Use shared queues for high availability
The following examples illustrate how we can use a shared queue to increase application availability.
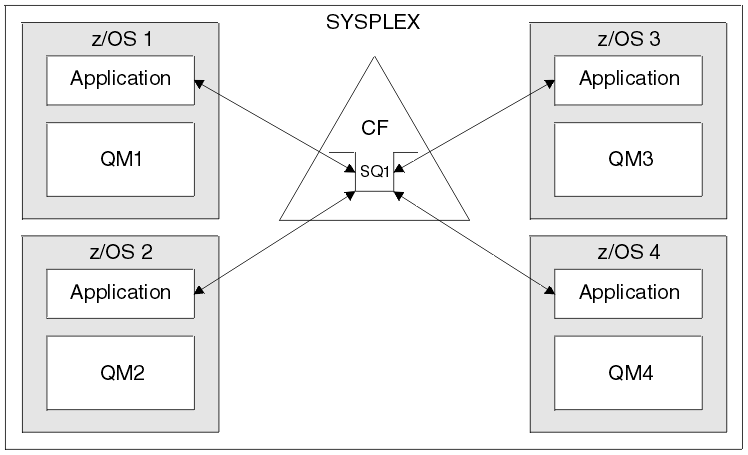
Consider an IBM MQ scenario where client applications running in the network want to make requests of server applications running on z/OS. The client application constructs a request message and places it on a request queue. The client then waits for a reply from the server, sent to the reply-to queue named in the message descriptor of the request message.
IBM MQ manages the transportation of the request message from the client machine to the server's input queue on z/OS and of the response from the server back to the client. By defining the server's input queue as a shared queue, any messages put to the queue can be retrieved on any queue manager in the queue sharing group. This means that we can configure a queue manager on each z/OS image in the sysplex and, by connecting them all to the same queue sharing group, any one of them can access messages on the server's input queue.
Messages on the input queue of the server are still available, even if one of the queue managers terminates abnormally or you have to stop it for administrative reasons. We can take an entire z/OS image offline and the messages will still be available.
To take advantage of this availability of messages on a shared queue, run an instance of the server application on each z/OS image in the sysplex to provide higher server application capacity and availability, as shown in Figure 1.
One instance of the server application retrieves a request message from the shared queue and, based on the content, performs its processing, producing a result that is sent back to the client as an IBM MQ message. The response message is destined for the reply-to queue and reply-to queue manager named in the message descriptor of the request message.
There are a number of options used to configure the return path. For more information about these options, see Distributed queuing and queue sharing groups.
Peer recovery
To further enhance the availability of messages in a queue sharing group, IBM MQ detects if another queue manager in the group disconnects from the coupling facility abnormally and completes units of work for that queue manager that are still pending, where possible. This feature is known as peer recovery.
Suppose a queue manager terminates abnormally at a point where an application has retrieved a request message from a queue in sync point, but has not yet put the response message or committed the unit of work. Another queue manager in the queue sharing group detects the failure, and backs out the in-flight units of work being performed on the failed queue manager. This means that the request message is put back on to the request queue and is available for one of the other server instances to process, without waiting for the failed queue manager to restart.
If IBM MQ cannot resolve a unit of work automatically, we can resolve the shared portion manually to enable another queue manager in the queue sharing group to continue processing that work.
Parent topic: Where are shared queue messages held?