Search collections
Configure
To configure search collections, click...
-
Administration | Search Administration | Manage Search | Search Collections | collection_name
Options...
- Search and Browse Collection
- Import or Export Collection
Portal Search provides a Portal Search XML interface for this feature. When upgrading, to prevent loss of data, export search collections to XML files before upgrading the software. Then after upgrading the software level, we can use the previously exported files to return the search collection data back into the new software level. We can import collection data only into an empty collection. When importing, a background process fetches, crawls, and indexes all documents that are listed by URL in the exported file.
- Delete Collection.
- New Content Source
Create a new content source for this collection. We can create more than one content source for a search collection.
- View the Collection Status information of the selected search collection...
Search Collection Name Name of the selected search collection. Search Collection Location Location of the selected search collection in the file system. This is the full path where all data and related information of the search collection is stored. Collection Description Description of the selected search collection if available. Search Collection Language Language for which the search collection and its index are optimized. The index uses this language to analyze the documents when indexing, if no other language is specified for the document. Allows spelling variants, including plurals and inflections. Summarizer used Whether a static summarizer is enabled for this search collection. Last update completed Date when a content source defined for the search collection was last updated by a scheduled update. Next update scheduled Date when the next update of a content source defined for the search collection is scheduled. Number of active documents Number of active documents in the search collections that is, all documents available for search by users. - To update the status information, click Refresh.
Clicking the refresh button of the browser will not update the status information.
- If you delete a portlet from the portal after a crawl of the portal site, the deleted portlet is no longer listed in the search results.
Refreshing the view does not update the status information about the Number of active documents. This information is not updated until after the next cleanup run of portal resources.
- To update the status information, click Refresh.
We cannot create additional search collections for the default Content Model search service. When we specify the directory location for the collection, be aware that creating the collection can overwrite files is that directory.
Set up a JCR search collection
A JCR search collection is a special purpose search collections used by WebSphere Portal applications. It is not designed to be used alongside user-defined search collections and requires a special setup, including the creation of a new content source for the search collection.
The portal installation creates a default JCR search collection named JCRCollection1. If this collection is removed or does not exist for other reasons, we can manually re-create the JCR search collection.
WCM Authoring search is requires a JCR search collection available, paired with the respective content source. If the JCR search collection gets deleted, a search is not possible using the Authoring portlet. The JCR search collection can only be used by a search portlet that knows how to present and deal with the search result in which the returned information is useless in a more generic context of search.
The JCR search collection is flagged so that it does not participate in search using the All Sources search scope. An administrator cannot manually add it. The JCR search collection is a special purpose search collection which the JCR requires to allow specialized application to perform low-level searches in the repository.
To create a new JCR search collection.
- Go to...
-
Portal Administration | Search Administration | Manage Search | Search collections | New collection
...and specify the following values...
Search Service For stand-alone environments, select Default Portal Service.
For clustered environment, select Remote Search Service.Location of collection For example, /opt/IBM/Portal/WebSphere1/PortalServer/JCR Name of collection. The name of the collection should be JCRCollection1 Description of collection Optional. Specify JCR seedlist collection. Specify Collection language Default is English (United States). 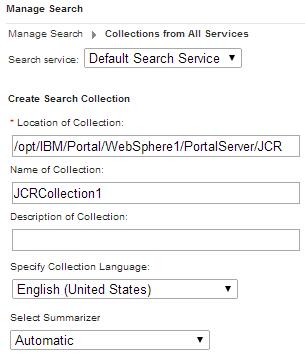
After creating the new collection we can see the name of the collection you have created in the list.
- Double-click the collection that you have created.
- To create the content source for the new search collection, click New Content Source and set....
Content source type Seedlist Provider Content Source Name JCRSource Collect documents linked from this URL http://server:10039/seedlist/server?Action=GetDocuments&Format=ATOM&Locale=en_US&Range=100&Source=com.ibm.lotus.search.plugins.seedlist.retriever.jcr.JCRRetrieverFactory&Start=0&SeedlistId=1@OOTB_CRAWLER1 For virtual portal...
http://server:port_number/seedlist/server/vpcontext?Action=GetDocuments&Format=ATOM&Locale=en_US&Range=100&Source=com.ibm.lotus.search.plugins.seedlist.retriever.jcr.JCRRetrieverFactory&Start=0&SeedlistId=1@OOTB_CRAWLER1
In the URL above the range parameter specifies the number of documents in one page of a session.
On the Security panel, set User Name and Password, then click Create
- Click Create to create the new content source.
If the Content Source was created successfully, the following message will be displayed on the page:
- EJPJB0025I: Content source source_name in collection collection_name is OK.
- To start the crawler manually, navigate to the content source and click the Start Crawler button for the content source.
To schedule the seedlist crawler, click the Edit Content Source button, and click the Scheduler tab. Specify the date and time and the frequency for the crawl. The crawler will be triggered automatically at the time that you scheduled.
Verify icm.properties has jcr.textsearch.enabled=true
Web Content Manager
If we use Web Content Manager, the JCRCollection1 collection is created the first time you create a web content item, if it does not already exist. In this case, it might not be necessary to create the collection manually, although it is fine to create it manually first, if required. It is used by the search feature within the Web Content Manager authoring portlet.
If you delete this search collection, you will not be able to search for items within the authoring portlet.
If you create the virtual portal with content, the portal creates the JCR collection for the virtual portal by default. If you create only the virtual portal and add no content to it, the portal creates no JCR collection with it. It will get created only when content is added to the virtual portal.
We can view the URL of the JCR collection in the search administration portlet Manage Search of the virtual portal. The URL looks as follows:
http://host_name:port_number/seedlist/server?Action=GetDocuments&Format=ATOM&Locale=en_US&Range=100&Source=com.ibm.lotus.search.plugins.seedlist.retriever.jcr.JCRRetrieverFactory&Start=0&SeedlistId=wsid@ootb_crawlerwsid
...where wsid is the actual workspace ID of the virtual portal. The workspace ID is the identifier of the workspace in which the content item is created, stored and maintained.
For example, if the workspace ID of the virtual portal is 10, then the URL looks as follows:
http://host_name:port_number/seedlist/server?Action=GetDocuments&Format=ATOM&Locale=en_US&Range=100&Source=com.ibm.lotus.search.plugins.seedlist.retriever.jcr.JCRRetrieverFactory&Start=0&SeedlistId=10@ootb_crawler10
Manage the content sources of a search collection
To work with content sources of a collection select...
- Administration | Search Administration | Manage Search | Search Collections
Then select a search collection by clicking the collection name link. Portal Search displays the Content Sources panel. It shows the status of the selected search collection and lists its content sources and their status. It shows information related to the individual content sources, and lets you perform tasks on these content sources.
We can select the following option icons and perform the following tasks in relation to the search collection which we selected from the Search Collections list:
- New Content Source
Create a new content source for the search collection selected from the Search Collections list. We can configure a search collection to cover multiple content source of different types. For example, we can combine portal sites, web sites, and local document collections. Options and data entry fields displayed depend on which type of content source we select. If we select Portal site, the appropriate data for the portal site is already complete. If we select WCM site, fill in the appropriate data.
For some content sources we might need to enter sensitive data, such as a user ID and password. To ensure encryption of this sensitive data when it is stored, update and run the file searchsecret.xml using xmlaccess.sh before creating the content source.
When creating a portal site content source in a portal cluster environment configured with SSL, provide the cell security info for the web server and the nodes. For example, in a cluster with cluster, primary, and secondary URLs...
-
https://web_server/wps/portal
http://node_1:10039/wps/portal
http://node_2:10050/wps/portal...provide the user ID and password for the web server and both nodes 1 and 2.
Under the General parameters tab, set the URL for the content source in a field...
-
Collect documents linked from this URL
The crawler needs this URL for crawling. A crawler failure can be caused by URL redirection problems. If this occurs, try by editing this field accordingly, for example, by changing the URL to the redirected URL.
We can set a timeout under the General parameters tab under the option...
-
Stop collecting after (minutes)
This timeout works as follows:
- The timeout works only for web site content sources.
- The timeout works as an approximate time limit. It might be exceeded by some percentage.
- The crawl action is put in a queue. It might therefore take several minutes until it is executed and the time counter starts. It might therefore seethat the crawl takes longer than the timeout set.
When you start the crawl by clicking Start Crawler, allow for some time tolerance and be aware of the time required for crawls and imports and availability of documents.
- The timeout works only for web site content sources.
- Under the Advanced Parameter tab, the entry field for the Default Character Encoding contains the initial default value windows-1252, regardless of the setting for the Default Portal Language under...
-
Administration | Portal Settings | Global Settings
Enter the required default character encoding, depending on the portal language. Otherwise documents might be displayed incorrectly under Browse Documents.
Before you start the crawl, set the preferred language of the crawler user ID to match the language of the search collection that it crawls.
- You start the initial crawl on a newly created content source using either...
- Start Crawler icon. This starts an immediate crawl.
- Define a schedule under the Schedulers tab. The crawl will start at the next possible time specified.
Options...
Refresh Update the list of content sources and the status shown for this collection. View Content Source Schedulers Manage schedulers. Only available if you have defined schedulers for the content source. Start Crawler Click this icon to start a crawl on the content source. This updates the contents of the content source by a new run of the crawler. While a crawl on the content source is running, the icon changes to Stop Crawler. Click this icon to stop the crawl. Portal Search refreshes different content sources as follows: - For website content sources
Documents that were indexed before and still exist in the content source are updated. Documents that were indexed before, but no longer exist in the content source are retained in the search collection. Documents that are new in the content source are indexed and added to the collection.
- For WebSphere Portal sites
The crawl adds all pages and portlets of the portal to the content source. It deletes portlets and static pages from the content source that were removed from the portal. The crawl works similarly to the option Regather documents from Content Source.
- For IBM Web Content Manager sites
Portal Search uses an incremental crawling method. Additionally to added and updated content, the Seedlist explicitly specifies deleted content. In contrast, clicking Regather documents from Content Source starts a full crawl; it does not continue from the last session, and it is therefore not incremental.
- For content sources created with the Seedlist provider option
A crawl on a remote system that supports incremental crawling, such as IBM Connections, behaves like a crawl on a Web Content Manager site.
Regather documents from Content Source. This deletes all existing documents in the content source from previous crawls and then starts a full crawl on the content source. Documents that were indexed before and still exist in the content source are updated. Documents that were indexed before, but no longer exist in the content source are removed from the collection. Documents that are new in the content source are indexed and added to the collection. Verify Address of Content Source. Click this icon to verify the URL of the content source is still live and available. Manage Search returns a message about the status of the content source. Edit Content Source Click this icon to make changes to a content source. This includes configuring parameters, schedules, and filters for the selected content source. It is of benefit to define a dedicated crawler user ID. The pre-configured default portal site search uses the default administrator user ID wpsadmin with the default password on that user ID for the crawler. If you changed the default administrator user ID during the portal installation, the crawler user that default user ID. If you have made changes to the user ID or password for the admin user ID and still want to use that user ID for the Portal Search crawler, you need to adapt the settings here accordingly.
To define a crawler user ID, select the Security tab, and update the user ID and password.
If you modify a content source that belongs to a search scope, update the scope manually to verify the scope still covers that content source. Especially if you changed the name of the content source, edit the scope and make sure that it is still listed there. If not, add it again.
Delete Content Source Click this icon to delete the selected content source. If you delete a content source, the documents collected from the content source will remain available for search by users under all scopes which included the content source before it was deleted. These documents will be available until their expiration time ends. We can specify this expiration time under Links expire after (days): under General Parameters when you create the content source. View Information about the status and configuration of the content source. Collection Status Search Collection Name Name of the selected search collection. Search Collection Location Location of the selected search collection in the file system. This is the full path where all data and related information of the search collection is stored. Collection Description Description of the selected search collection if available. Search Collection Language Language for which the search collection and its index are optimized. The index uses this language to analyze the documents when indexing, if no other language is specified for the document. This feature enhances the quality of search results for users, as it allows them to use spelling variants, including plurals and inflections, for the search keyword. Summarizer used Whether a static summarizer is enabled for this search collection. Last update completed Date when a content source defined for the search collection was last updated by a scheduled update. Next update scheduled Date when the next update of a content source defined for the search collection is scheduled. Number of active documents Number of active documents in the search collections that is, all documents available for search by users. - To update the status information, click Refresh. Clicking the refresh button of the browser will not update the status information.
- If you delete a portlet from the portal after a crawl of the portal site, the deleted portlet is no longer listed in the search results. However, refreshing the view does not update the status information about the Number of active documents. This information is not updated until after the next cleanup run of portal resources.
See also...
-
Apply filter rules
Export and import search collections
- From Manage Search portlet, select option...
-
Import or Export Collection
- On the source portal export the search collections.
This exports the configuration data and document URLs of the search collections.
- Verify the portal application process has write access to the target directory.
- When we specify the target directory location for the export, be aware that the export can overwrite files is that directory.
- For each collection, document...
- The target file names and directory locations to which you export the collections.
- The location, name, description, and language
- Create the search collections on the target portal.
This task creates the empty shell for the search collection. Complete the following data entry fields...
Location of Collection New collection location. Name of Collection The name can match the old setting, but does not have to match it. Description of Collection The description can match the old setting, but does not have to match it. Specify Collection Language Select this to match the old setting. Select Summarizer You do not need to select this option. The value will be overwritten by the import. You do not have to add content sources or documents; that will be completed by the import task.
- Import the data of the search collections into the target portal.
For the import source information use the documented file names and directory locations to which you exported the collections before the portal upgrade.
- Configure Portal Search on the target portal.
- Verify the portal application process has write access to the target directory.
- Import collection data only into an empty collection.
Do not import collection data into a target collection that has content sources or documents already.
When you import search collection data into a collection, most of the collection configuration data are also imported, including...
- content sources
- schedulers
- filters
- language settings
If we configured such settings when creating the new collection, they are overwritten by the imported settings.
- To migrate from one portal version to a higher version, delete the search collections between the export and the re-import.
- When you import a portal site collection from a V5.1 portal to a V6 portal, the collection configuration data are imported, but not the documents. Therefore, to enable users to search the portal site collection on the target portal, we can either...
- Import the portal site collection and then start a crawl
- Re-create the portal site collection.
This restriction does not apply if you migrate the portal site search collections between Version 6 portals.
- When you import a collection, a background process fetches, crawls, and indexes all documents which are listed by URL in the previously exported file. Therefore be aware of the memory and time required for crawls.
Related : Prepare for Portal Search
Portal Search
Administer Portal Search
Reset the default search collection
Delayed cleanup of deleted portal pages
Tips for using Portal Search
Seedlist 1.0 REST service API