Propagating the WebSphere Commerce Search index with the repeater
We can use the indexprop utility to propagate the WebSphere Commerce search index. It sends an HTTP request to the search index repeater to start replicating with the staging search index. This process ensures that the catalog changes are populated into the WebSphere Commerce Search index in production.The search index repeater is used as both a master and a subordinate for search replication.
It is used as a subordinate when replicating with the staging search index, where the staging search index is the master and the repeater is the subordinate acting as a backup of the search index for production. After the first replication is completed from staging, the repeater communicates the changes to its subordinate nodes that are in production.
The repeater then becomes the master, where all nodes from the search subordinates are configured to poll changes from the repeater on a regular preconfigured fixed-time interval. This time interval is defined in the solrconfig.xml file under replication.
Replicating between the repeater and all search subordinates in production can be automated, as the indexed data in the repeater always matches the indexed data in production. The search index repeater must be a subordinate to the staging search server and master to the production search server.
Important: The repeater must reside in Production, as it relies on the production database to perform emergency updates.
The following diagram illustrates the timing of events we must consider when indexing with staging propagation:
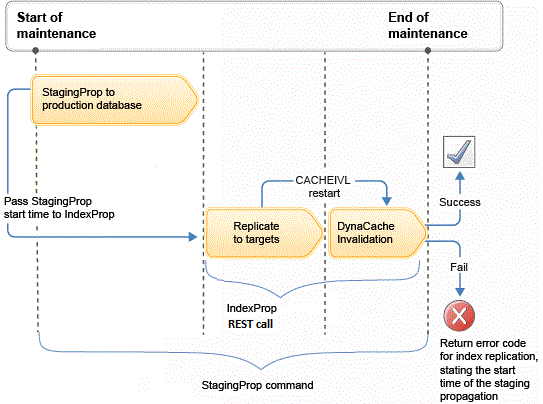
Refer to Propagating the search index for typical uses of the indexprop utility.
Before beginning
-
(Developer) Ensure that the test server is stopped and that Rational Application Developer is not running.
- Ensure that our search master and repeater server are started.
- If global security is enabled, ensure that security credentials for replication are set up for all search servers.
Procedure
- Log on as a WebSphere Commerce non-root user.
- If we are using this utility to replicate the search index, update the replication
configuration file on the staging environment to match the WebSphere Commerce Search environment:
- Open the replication.csv file for editing. The default location of the file is
solrHome/replication.csv.
Note: When running the UpdateSearchIndex scheduler job:
- The UpdateSearchIndex scheduler job does not call the indexprop API by default. Therefore, the replication.csv does not need to be copied to a location outside the Solr home directory.
- The replication.csv file should be copied to a location outside the Solr home directory. This avoids replication automatically taking place every time the UpdateSearchIndex scheduler job is run. For example, copy the replication.csv to the WC_installdir/instances/instance_name/search directory. Then, pass the -solrHome value when calling the indexprop REST API.
- Update the replication configuration file with the following information:
- SearchServerName
- The subordinate server name.
- SearchServerPort
- The subordinate server port.
- CoreName
- The core name to replicate.
- UserName
- The user name for the application security-enabled subordinate server.
If application security is not enabled, set this value to null.
- Password
- The password for the application security-enabled subordinate server.
The password must be encrypted by the wcs_encrypt utility.
If application security is not enabled, set this value to null.
For more information on how to update the replication configuration file (replication.csv), download and extract the following archive that contains sample CSV files:
- Ensure that the core to replicate is configured in the solr.xml file.
- Open the replication.csv file for editing. The default location of the file is
solrHome/replication.csv.
- Run the indexprop utility. To run the call to perform replication, use the POST method and basic authentication in the header (spiuser and its
password).
http://search_hostname:search_http_port/search/admin/resources/index/replicate
Where the supported parameters are:
- indexId
- The ID of the master catalog. The default is all.
- indexName
- The permitted values are catalog, inventory, or price. The default is catalog.
- langId
- Default is all.
- To check the status of the replication process, use the GET method and basic authentication in
the header.
http://search_hostname:search_http_port/search/admin/resources/index/replicate/status
To enable logging, set the trace level to "com.ibm.commerce.search.*=all" on the Search server. The related trace data will then be available in the trace.log file.
Related concepts
Index-building topologies and scenarios
Indexing with staging propagation
Related reference
Propagating the search index