Deployment for transactional high availability
Before using the high availability (HA) function, we must consider deployment issues such as the file system type, or where we plan to store the transaction recovery logs. In particular, the file system type can have important consequences for our recovery configuration.
Common configuration
Transaction peer recovery requires a common configuration of the resource providers between the participating server members to undertake peer recovery between servers. Therefore, peer recovery processing can only take place between members of the same server cluster. Although a cluster can contain servers that are at different versions of WebSphere Application Server, peer recovery can only be performed between servers in the cluster that are at v6 or later.
Physical storage
For application servers to perform transaction peer recovery for each other, they must be able to access the transaction recovery logs of all the other members in the cluster. Ensure that the log files are stored on a medium that is accessible by all members of the cluster, and that each cluster member has a unique log file location on this medium. This medium, and access to it, for example through a local area network (LAN), must support the file-based force operation used by the recovery log service to force data to disk. After the force operation is complete, information must be persistently stored on physical disk media.
In a HA environment, application servers must also be able to access the compensation logs. Ensure that the compensation log files are stored on a medium that is accessible by all members of the cluster, and that each cluster member has a unique log file location on this medium.
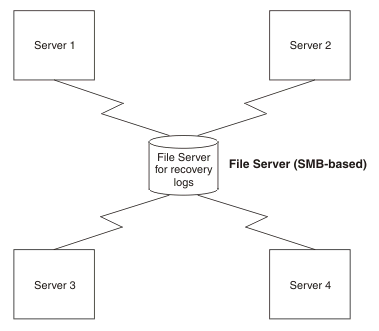
(iSeries) For example, we can store the logs on another IBM i server using the NetClient file system (QNTC), which provides access to data on a remote system using the Server Message Block (SMB) protocol.
(iSeries)
Figure 1. Recovery logs on SMB-based file server are available to all servers
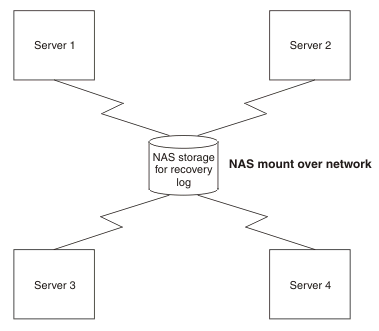
For example, we can use IBM Network attached storage (NAS) ( http://www.ibm.com/servers/storage/nas/index.html) mounted on each node, and shared SCSI drives, but not simple network share. All nodes must have read and write access to the recovery logs.
Figure 2. Recovery logs on NAS storage are available to all servers
In addition, configure the mechanism by which the remote log files are accessed, to exploit any fault tolerance in the underlying file system. For example, using the Network File System (NFS) and hard mounting the remote directory containing the log files using the -o hard option of the NFS mount command, the NFS client will try a failed operation repeatedly until the NFS server becomes available again.
Two types of potential server failure exist: software failure and hardware failure. Software failures generally do not affect other application servers directly. Even servers on the same physical hardware can undertake peer recovery processing. If a hardware failure occurs, all the servers deployed on the failed hardware become unavailable. Servers on other hardware are required to handle peer recovery processing. Any HA configuration requires that servers are deployed across multiple and discrete hardware systems.
File system
The file system type is an important deployment consideration as it is the main factor in deciding whether to use automated or manual peer recovery. See How to choose between automated and manual transaction peer recovery.
Subtopics
- How to choose between automated and manual transaction peer recovery
The type of file system is the dominant factor in deciding which kind of transaction peer recovery to use. Different file systems have different behaviors, and the file locking behavior in particular is important when choosing between automated and manual peer recovery.