How to choose between automated and manual transaction peer recovery
WAS high availability (HA) support uses a heartbeat mechanism to determine whether servers are still running. Servers are considered failed if they stop responding to heartbeat requests. Some scenarios, such as system overloading and network partitioning, can cause servers to stop responding to heartbeats, even though the servers are still running. WAS uses file locking technology to prevent such events from causing concurrent access to transaction recovery logs, because access to a recovery log by more than one server can lead to loss of data integrity. Network File System Version 4 (NFSv4) provides this release behavior. Network File System Version 3 (NFSv3) does not.
We can test whether a shared file system can support the failover of transaction logs by running the File System Locking Protocol Test for WAS.
NFSv4 releases locks held on behalf of a host in case that host fails. Peer recovery can occur automatically without restarting the failed hardware. Therefore, this version of NFS is better suited for use with automated peer recovery. NFSv3 holds file locks on behalf of a failed host until that host can restart. In this context, the host is the physical machine running the application server that requested the lock and it is the restart of the host, not the application server, that eventually triggers the locks to release.
Consider the behavior when a cluster member fails:
- AppServer01 is running on Host01 and holds an exclusive file lock for its own recovery log files.
- AppServer02 is running on Host02 and holds an exclusive file lock for its own recovery log files.
- Host01 fails, taking AppServer01 with it.
- The NFS lock manager on the file server holds the locks granted to AppServer01 on its behalf.
- A peer recovery event is triggered in AppServer02 for AppServer01 by WAS.
- AppServer02 attempts to gain an exclusive file lock for this peer recovery log, but is unable to do so as it is held on behalf of AppServer01.
- The peer recovery process is blocked.
- At an unspecified time, Host01 is restarted. The locks held on its behalf are released.
- The peer recovery process in AppServer02 is unblocked and granted the exclusive file locks needed to undertake peer recovery.
- Peer recovery takes place in AppServer02 for AppServer01.
- AppServer01 is restarted.
- If peer recovery is still in progress in AppServer02, the recovery is halted.
- AppServer02 releases the exclusive lock on the recovery logs and returns ownership of the recovery logs back to AppServer01.
- AppServer01 obtains the exclusive lock and can now undertake standard transaction logging.
On NFSv3 we must disable file locking to use automated peer recovery. Disabling file locking can lead to concurrent access to recovery logs so it is vital that we protect the system from system overloading and network partitioning first. Alternatively, we can configure manual peer recovery, where we prevent concurrent access by manually triggering peer recovery processing only for servers that have failed.
- System overloading
- Occurs when a machine becomes very heavily loaded such that response times are extremely poor and requests begin to time out. Several potential causes exist for such overloading, including:
- The server is underpowered and cannot handle the workload.
- The server received a temporary surge of requests.
- Insufficient physical memory is available. The OS is too busy paging to give the application server the required CPU time.
- Network partitioning
- Occurs when a communications failure in a network results in two smaller networks independent and cannot contact each other.
Heartbeats in a system running normally, compared to heartbeats after the apparent server failures of system overloading and network partitioning
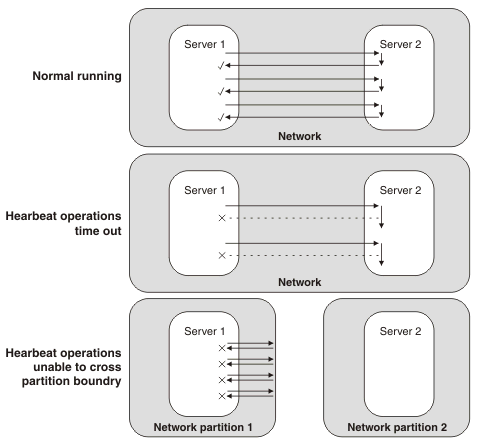
During normal running, two servers on the network exchange heartbeats. During system overloading, heartbeat operations time out, giving the appearance of a server failure. After network partitioning, each server is in a separate network and heartbeats cannot pass between them, also giving the appearance of a server failure.
See: Configure transaction properties for peer recovery