Network Deployment (Distributed operating systems), v8.0 > Applications > Service integration > High availability and workload sharing > Service integration high availability and workload sharing configurations
Configuration for workload sharing with high availability
This configuration consists of multiple messaging engines running in a cluster, where each messaging engine can fail over to one or more alternative servers.
There are three ways to achieve this configuration:
- We can add a cluster to the service integration bus by using messaging engine policy assistance, and use the scalability with high availability messaging engine policy. This procedure creates a single messaging engine for each server in the cluster. Each messaging engine can fail over to one other specified server in the cluster. Each server can host up to two messaging engines, such that there is an ordered circular relationship between the servers. Each messaging engine can fail back, that is, if a messaging engine fails over to another server, and the original server becomes available again, the messaging engine automatically moves back to that server.
- We can add a cluster to the service integration bus by using messaging engine policy assistance, and use the custom messaging engine policy. We can create as many messaging engines as you require for the cluster. For each messaging engine you create, configure the messaging engine policy to provide the messaging engine behavior that you require.
- We can add a cluster to the service integration bus without using messaging engine policy assistance. One messaging engine is created automatically, then you add the further messaging engines that you require to the cluster. A typical configuration has one messaging engine for each server in the cluster. Create a new "One of N" core group policy for each messaging engine in the cluster. Configure the policies so that one messaging engine runs on each server and so that there is high availability behavior, for example, each messaging engine can fail over to one designated server.
- We can set an ordered list of preferred servers that the messaging engine can run on and fail over to.
- We can specify whether the messaging engine can run on any server in the cluster, or only on those in the preferred servers list.
- We can specify whether the messaging engine can fail back to a more preferred server when one becomes available.
After creation of the new policies, use the match criteria to associate each policy with the required messaging engine.
The default service integration policy, "Default SIBus Policy", does not provide this behavior, so create new core group policies.
This type of configuration provides availability, because each messaging engine can fail over if a server becomes unavailable. The configuration provides workload sharing because there are multiple messaging engines to share the traffic through the destination, and scalability, because it is possible to add new servers to the cluster without affecting existing messaging engines in the cluster.
The following diagram shows an example configuration of this type. There are three messaging engines, ME1, ME2, and ME3, with data stores A, B, and C, respectively. The messaging engines run in a cluster of three servers and share the traffic passing through the destination. Each server is on a separate node, so that if one node fails, the servers on the remaining nodes are still available.
Each messaging engine has one preferred location and one secondary location. Each server in the cluster contains the definition of two messaging engines that can run on it, and creates an instance of each messaging engine so that one messaging engine can run on it as its preferred location, and the other instance is ready to be activated if another server fails. ME1 runs on server1 and can fail over to server2; ME2 runs on server2 and can fail over to server3; ME3 runs on server3 and can fail over to server1.
The message store for each messaging engine must be accessible by the preferred server and the secondary server. The way to achieve this is depends on the data store topology you use. If you use a networked database server, ensure that the database server is accessible from all servers in the cluster that might run the messaging engine. Alternatively, you can use an external high availability framework to manage the database by using a shared disk.
This example configuration is the configuration created when you use messaging engine policy assistance and the scalability with high availability messaging engine policy for a cluster of three servers.
Figure 1. High availability with workload sharing or scalability configuration

The following diagram shows what happens if server1 fails. The messaging engine ME1 is activated on the next server in the preferred servers list for that messaging engine, which is server2. ME2 continues to run on server2, and ME3 continues to run on server3.
Figure 2. High availability with workload sharing or scalability configuration after server1 fails
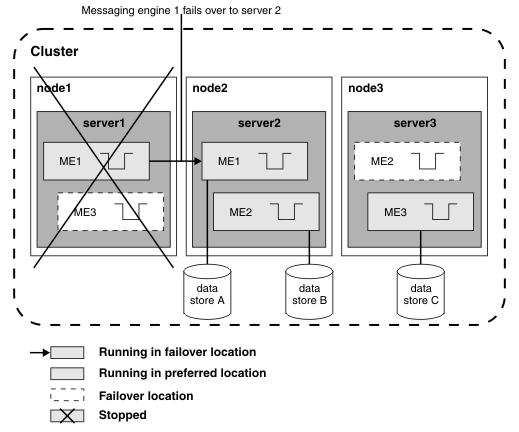
The following diagram shows what happens if server1 becomes available again and server2 fails. The messaging engine ME1 is activated on server1, the first server in the preferred servers list for that messaging engine, because failback is set for ME1. ME2 is activated on the next server in the preferred servers list for that messaging engine, which is server3. ME3 continues to run on server3.
Figure 3. High availability with workload sharing or scalability configuration after server2 fails
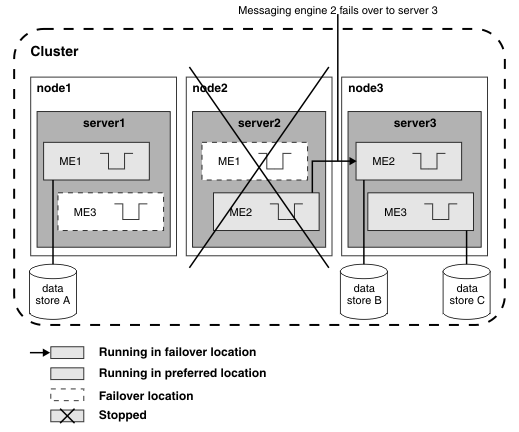
The predefined scalability with high availability messaging engine policy creates a configuration with aspects of scalability and high availability. The following diagram shows another example of a configuration that provides high availability and workload sharing, where message transmission is a priority. There are two messaging engines, ME1 and ME2, with data stores A and B, respectively, running in a cluster of three servers and sharing the traffic through a destination. In normal operation, ME1 runs on server1 and ME2 runs on server2. Server3 provides a failover location for both messaging engines. This is known as an "N+1" configuration, because there is one spare server.
Figure 4. Highly available messaging engines with workload sharing in an "N+1" configuration
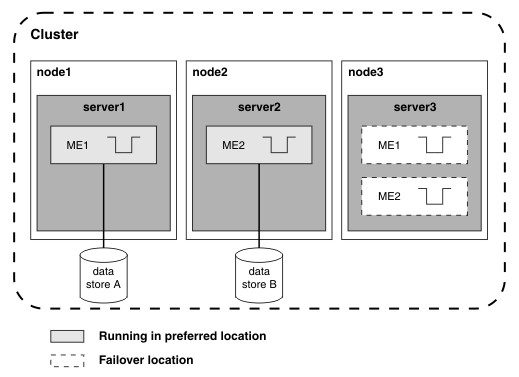
The preferred server list for ME1 is server1, server3, and the preferred server list for ME2 is server2, server3. The advantage of this configuration is that if one server fails, each remaining server hosts only one messaging engine. The disadvantage of this configuration is the expense of the spare server.
To achieve this type of configuration, you can use the custom messaging engine policy.
If you do not use messaging engine policy assistance and you want the messaging engine to use preferred servers, specify one or more preferred servers for the messaging engine. Whenever a preferred server is available, the high availability manager (HAManager) runs the messaging engine in it. When no preferred server is available, the messaging engine runs in any other available server. We can also set the Fail back option on the policy so that when a preferred server becomes available again, the HAManager moves the messaging engine back to it.
Policies for service integration High availability Scalability with high availability messaging engine policy
Add a cluster as a member of a bus Configure high availability and workload sharing of service integration
Scalability with high availability messaging engine policy