WebSphere MQ built-in queue manager clustering
The WebSphere MQ queue manager cluster concept reduces administration efforts and provides load balancing of messages across instances of clustered queues. Therefore, it also offers some level of high availability. However, local messages in the failed queue managers cannot be processed until the failed queue managers are restarted, because queue manager cannot be failed over with their states in a WebSphere MQ built-in cluster.
The WebSphere MQ cluster configuration is quite easy and straightforward. You have fewer channels to set up. WebSphere MQ clusters allow a group of queue managers to advertise the existence of some of their channels and queues to each other. The knowledge of these resources is shared among the queue managers and forms the cluster by including the queues and channels belonging to various queue managers. Because no single controlling entity is in charge of the cluster, it is very robust, with no single point of failure. The collection of queue managers provides the service. As long as there are enough remaining queue managers and connections, the service is available. Failure of a network or failure of the destination queue manager manifests itself as a channel failure, with the communications channel performing its normal retry cycle. At the same time, any messages waiting on the SYSTEM.CLUSTER.TRANSMIT.QUEUE intended to move along the failed channel will be reprocessed and another destination found, if this is possible and appropriate. The communications channel between each pair of queue managers in the cluster is protected independently, without any global monitoring of the cluster as a whole.
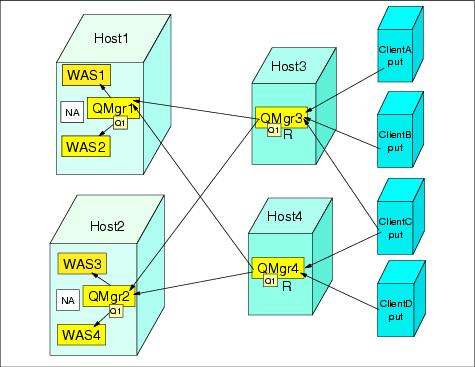
The ability to define equivalent queues in a WebSphere MQ cluster, with identical names on several of the queue managers in the cluster, leads to increased system availability. Each queue manager runs equivalent instances of the applications that process the messages. Figure 11-10 shows how a message put on one queue manager anywhere in the cluster is moved to other clustered queues and processed. If one of the queue managers fails, or the communication to it is suspended, it is temporarily excluded from the choice of destinations for the messages. This approach allows redundant servers to be completely independent of each other, thousands of miles apart if necessary. A problem in one server is less likely to affect the others.
Figure 11-10 demonstrates the configuration and topology of a WebSphere Network Deployment V5 cluster (using horizontal and vertical scaling) with a WebSphere MQ cluster. This topology shows typical high availability characteristics for all variations of topologies. You can add more queue managers or appservers to the systems or add more physical boxes, but the essential high availability characteristics of WebSphere Network Deployment V5 and WebSphere MQ will not change.
When the queue manager on Host2 fails, messages residing in the local queue will be trapped there, and the appservers WAS3 and WAS4 cannot process these trapped messages until the queue manager is restarted. The queue manager on Host1 is still functioning. It can handle new messages in its local queue that can be processed by the application servers on Host1.
If WAS1 fails, WAS2 continues to process messages from the local queue in Host1. If both WAS1 and WAS2 fail, the messages on QMgr1 will not be processed, and the messages on QMgr1 will increase to its maximum size or until WAS1 or WAS2 recover and are able to process them.
If Host1 fails or the network to Host1 is down, the messages will be distributed to QMgr2, which is located on Host2 and WAS3 and WAS4 will process them. If you use only WebSphere vertical scaling (no horizontal scaling), you will lose the protection for system or network failures.
If all messages are produced and consumed locally, this is a good high availability solution because of the messaging client redundancy. We have used this configuration for our Trade3 and Big3 test scenarios. However, locally produced and consumed messages are not typical for real applications, since this reduces the value of asynchronous messaging. A messaging environment is meant to transfer messages over long distances, such as a credit card verification application. We have two ways to do it:
1. Message producers can use a session EJB to put messages on a queue. An MDB can consume these messages locally. Because the message producers (servlets and EJBs) are workload managed (message producer redundancy), clustered queues are a perfect HA solution for this case. 2. The clients send messages asynchronously to the queue on Host3, and the MDB processes the messages from the local queue (on Host1 or Host2), which is clustered with the queue on Host3. If the queue manager on Host3 fails, the clients cannot put messages into the queue and messages cannot be distributed to the local queues on Host1 and Host2. We can configure another queue manager on Host4 and allow clients to connect to either queue manager, but the clients have no server transparency (different IPs). In addition to the problem of stuck messages in failed local queues, the WebSphere MQ cluster doesn't provide a mechanism for triggering the failover of a queue manager. WebSphere MQ clustered queues may be distributed across a wide geographical range. For an MQ cluster, at least two repository queue managers are needed for high availability. Also, at any site or access point, at least two producers/publishers or two consumers/subscribers are needed for high availability. We must have ways to either increase client chain redundancy, such as:
Single client -> Servlet/EJB WLM-> multiple copies of the clients-> put/consume messages into/from the clustered queue. Alternatively, provide a single image of the queue manager to the client with hardware-based high availability for the queue manager.
Network sprayers, such as the Load Balancer from the WebSphere Edge Components, can also be used to enhance WebSphere MQ cluster scalability and high availability as well as to provide a single access point for messaging application clients (the figure is similar to Figure 11-11, but with an HA Load Balancer in front of the WebSphere MQ clustered queue managers). However, messages trapped in the local queues of failed queue managers are still SPOFs since they cannot be processed until the failed queue managers are restarted.
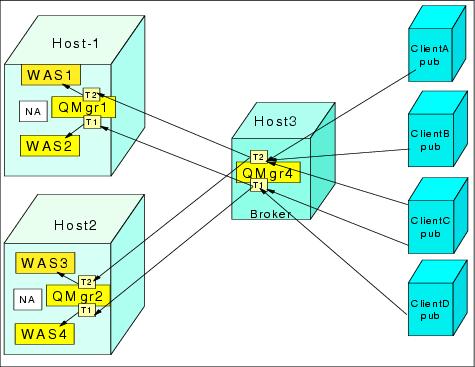
The use of publish/subscribe in a WebSphere MQ cluster with cluster queues is not a practical configuration, because a subscriber has an identity, which in MQSeries terms is identified by the combination:
"Subscriber queue name + Queue manager name + Correlation ID".
Since a JMS subscriber only receives publications that have its correlation ID, and no two correlation IDs are the same, a given publication message must go to its defined subscriber. This means that subscription queues should not be cluster queues when the hosting queue manager is part of a cluster. Figure 11-12 shows a WebSphere cluster (using horizontal and vertical scaling) with listeners pointing to subscribe topics. It is very clear that the broker on Host3 is a SPOF. We can use clustering techniques to make the publish/subscribe broker in Host3 highly available as discussed in the next section.
The best approach is to combine the WebSphere MQ built-in queue manager cluster and HACMP (or other kinds of clustering software). We discuss this scenario in the next section.
Prev | Home | Next WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both.
IBM is a trademark of the IBM Corporation in the United States, other countries, or both.
{kind=link}
{kind=link}
{kind=link}