Typical failover
Figure 12-2 and Figure 12-3 show a typical HACMP-controlled failover. A hot standby with cascading resource groups is configured. Before the failover occurs, the shared disk array is mounted on the primary node, and database and LDAP processes are running on the primary node. WebSphere and applications access the databases through the service IP address. In order to enable this service IP address takeover, you need to define a boot IP address to this adapter.
If the primary node fails, HACMP will detect the failure, run the stop scripts and release the disk volume groups and other shared resources held by the primary node. By means of the heartbeat mechanism between two nodes, the standby node will take over the service IP address, mount the shared disk array, take over other resources, and run the start script. Even though the service runs in the different computer nodes, the same IP address is used to access the database server before and after failover. Therefore, such failover is transparent to clients, since the clients do not need to use different IP addresses for accessing the servers. However, the in-flight connections become invalid during the failover. Therefore, WebSphere must provide the capacity to handle such situations. Support for this feature began in WebSphere V3.02 with HACMP 4.3.1. This feature was improved in WebSphere V5 (and later releases of WebSphere V3.5.x and WebSphere V4) to minimize failures.

Figure 12-2 HACMP cluster configuration for WebSphere
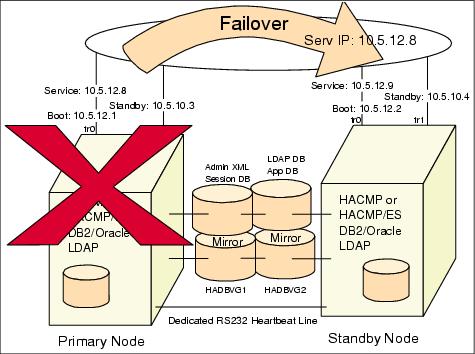
Figure 12-3 HACMP cluster after failover
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both.
IBM is a trademark of the IBM Corporation in the United States, other countries, or both.