High availability
In order to eliminate the Dispatcher itself as a single point of failure, you can configure it for high availability by providing a secondary machine.
The first (active) Dispatcher machine performs load balancing in the same way as a single Dispatcher configuration. The second system monitors the health of the first, and takes over the load balancing if it detects that the first Dispatcher has failed. The two machines need to reside on the same subnet. This configuration is illustrated in Figure 4-5.
Each of the two machines is assigned a specific role, either primary or backup. The primary machine constantly sends connection data to the backup system. Each machine is monitoring the health of the other through heartbeats. Heartbeats are sent every half second, the failover occurs when the backup machine receives no response from the primary within two seconds. Another reason for a failover is when the backup machine is able to ping more reach targets than the primary machine.
The failover process is as follows: The standby machine becomes active, takes over the cluster IP address, and assumes the role of forwarding packets. The primary machine automatically becomes standby.
|
Note: By default, high availability is only supported for the Dispatcher component, not for the Site Selector. For a highly available Site Selector, configure Dispatcher to host a cluster in front of multiple Site Selectors. The cluster will act as the sitename DNS clients are requesting. The Dispatcher tier can provide the failover mechanism and the Site Selectors will then have no single point of failure. The DNS advisor to be used to detect a failed site selector is included with the product. |
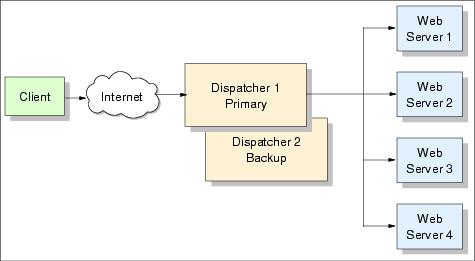
Figure 4-5 Dispatcher high-availability topology
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both.
IBM is a trademark of the IBM Corporation in the United States, other countries, or both.