| 8.
|
|
| Start the process in the backup system.
|
This failover process takes several minutes after the fault is detected. This approach can be used for both function-centric or data-centric applications for both active/standby and active/active configurations.
Figure 8-11 and Figure 8-12 show active/standby failover configurations.
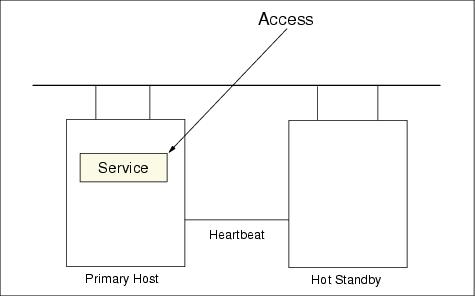
Figure 8-11 Active/standby configuration before failover

Figure 8-12 Active/standby configuration after failover
Figure 8-13 and Figure 8-14 show active/active failover configurations.
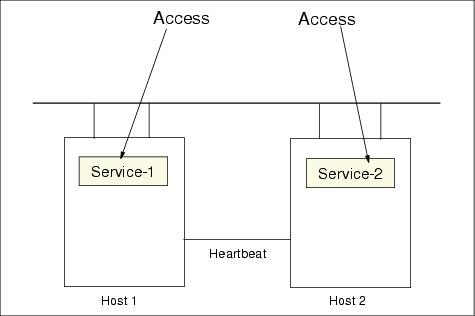
Figure 8-13 Active/active configuration before failover

Figure 8-14 Active/active configuration after failover
Fail back or fallback is similar to failover, but occurs from the backup system to the primary system once the primary system is back online. For mutual takeover, since the backup node has its original application running, as shown in Figure 8-14, failing back will improve the performance of both applications, as shown in Figure 8-13.
Note The two processes in the mutual takeover hosts are different applications. You should distinguish them from the processes that belong to the same application (we will discuss this later).
|
Fail fast refers to uncoordinated process pairs: the backup process is pre-existent, as shown in Figure 8-15. Please note the following points:
|
| These processes belong to the same application.
|
|
| These processes are not coordinated; in other words, these processes do not know each other's running state.
|
|
| These processes are pre-existent on hosts, which is different from the failover case where a new process starts with the takeover of resources after the original process fails.
|
|
| These processes do not take resources from each other.
Fast fail cannot be used in data-centric applications. It relies on 1-n mapping (such as sprayer) to handle client traffic and process errors. Tuning the connection and TCP/IP timeout parameters is a key part of this kind of failover performance. We do need to balance normal running performance and failover performance. Too short a connection and TCP/IP timeout may improve the failover performance, but harm the normal running performance.
WebSphere uses this approach for EJB workload management and plug-in workload management, where cluster layer resources are not shared among processes, processes are uncoordinated and do not know each other's state. This approach is suitable only for service-centric applications; it cannot be used for data-centric applications. We need another HA data management approach for Entity EJBs data and other data.
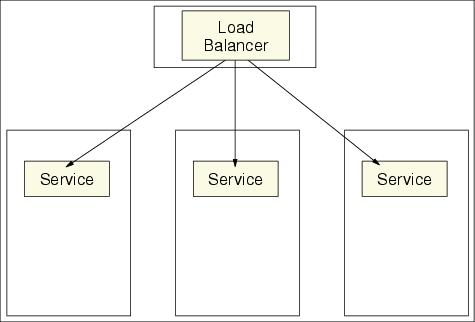
Figure 8-15 Fail fast without clustering
A feedback mechanism can be applied to the system to dynamically balance workload across the service nodes, as shown in Figure 8-16.
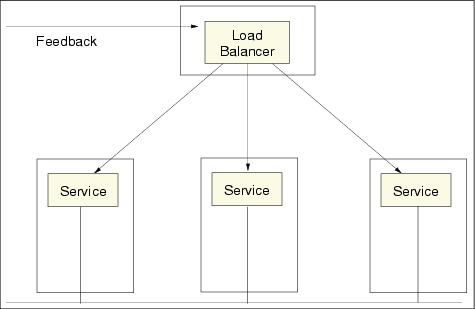
Figure 8-16 Fail fast with feedback for workload balancing
Fail transparent is defined as coordinated process pairs: we have a primary process and a backup process running on separate processors, as shown in Figure 8-17. The primary process sends checkpoints to the backup process. If the primary process fails, the backup process takes over. This mechanism is based on the backup process anticipating the failure of the primary process and then taking over without affecting the work in progress or user sessions. This approach requires that each process know the states of other processes as well as the state of the environment. Therefore, a cluster management layer is required and the application must query the status from this cluster layer. In other words, the processes are coordinated, and errors are handled transparently. Oracle Parallel Server/TAF is an example of the successful implementation of this kind of failover.
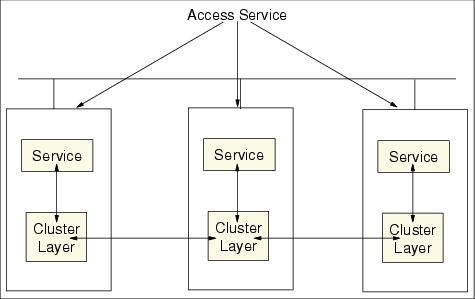
Figure 8-17 Fail transparent with clustering
In summary, we have three approaches to achieve high availability:
|
|
| Process and dependent resource group takeover
This approach requires cluster information and can be used for both data-centric and service-centric applications. Its implementation is difficult.
|
|
| Multiple uncoordinated processes
This approach does not require cluster information. However, this approach cannot be used for data-centric applications since it does not support the resource group concept.
|
|
| Multiple coordinated processes
This approach requires cluster information, and its implementation is very difficult. It can be used for both data-centric and service-centric applications. It can achieve transparent failover without interruption.
|
|
Prev | Home | Next
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both. IBM is a trademark of the IBM Corporation in the United States, other countries, or both. |