Make Deployment Manager highly available using clustering software and hardware
As noted before, the Deployment Manager server is a SPOF in WebSphere V5. As an option for 24x7 requirements, we discuss in the following sections how to make it highly available with clustering software and hardware.
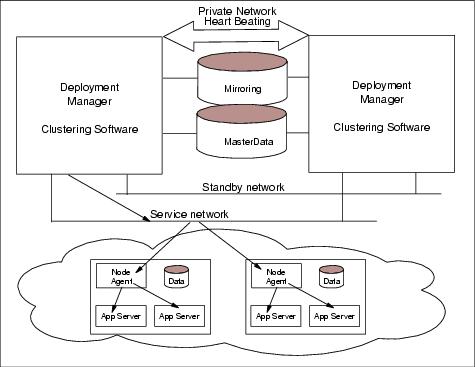
Figure 10-5 Clustered Deployment Manager for high availability
As shown in Figure 10-5, a software and hardware system includes HA clustering software (such as HACMP, VCS, ServiceGuard, SCS, and MSCS), a shared disk array subsystem, two host machines, a private service network, public primary network and optionally a backup network on different LANs that connect to other WebSphere nodes and other resources. The Deployment Manager is installed onto the shared disk and is configured in an HA resource group that includes the server hosting the Deployment Manager.
If a failure occurs in the Deployment Manager process, operating system, JVM, network, disk subsystem, repository data, and host machine, the heartbeat system will detect these failures and initiate a failover by:
| Stopping the Deployment Manager server process in the failed host |
| Releasing the shared disk and other resources from this node |
| Removing the service IP address from the failed node |
| Mounting the shared disk to the other healthy node |
| Adding the same service IP address to the adopted node |
| Starting the Deployment Manager server |

Figure 10-6 Failover of Deployment Manager with the assistance of HACMP
Depending on the hardware clustering product and configuration, you may need to make your Deployment Manager use the virtual (cluster) host name rather than the actual host name. Additionally, during our tests, we sometimes received an HACMP "rc207" return code that indicated a failure to stop the Deployment Manager and to release the shared disk resource. This happens because the Deployment Manager stop operation is initiated through asynchronous JMX messaging (wsadmin in our case). In this situation, the disk resource is still owned and held by this process. Adding a delay to the failover configuration script (as shown in Example 10-4) will allow the stop operation to finish completely so that the disk can be released before the shared disk resource is switched to the other node.
Example 10-4 Add delay after stopManager command

#/usr/bin/ksh
/HA/WebSphere/DeploymentManager/bin/stopManager.sh
sleep 60

Note You might need some testing to find the right sleep time for your environment. If the sleep time is too short, you will still receive the rc207 error. If it is too long, the Deployment Manager failover will simply take a bit longer. |
WebSphere is a trademark of the IBM Corporation in the United States, other countries, or both.
IBM is a trademark of the IBM Corporation in the United States, other countries, or both.