Work with data handlers, faults and registries
Work with data handlers, faults and registries
Creating your own data handlers provides a way of handling data formats unique to your own organization. The binding registry page lets you register your own data handlers with IBM Integration Designer, allowing them to be reused by yourself or others. Adding faults, lets you handle error conditions related to your application at run time.
Whereas a binding class provided as-is might be thought of as a class with hard-coded values, a binding resource configuration allows you to customize a binding yourself for your particular needs. Moreover, a binding resource configuration you create can often be reused by another type of binding. For example, you might create a binding resource configuration to work with a Flat Files adapter that might be suitable for a service with a JMS binding.
Binding resource configurations can be created for data bindings, data handlers and function selectors, each of which has a section explaining their creation and how these binding resource configurations work together to bring flexibility and reuse to your services. These sections are followed by a look at the registry where these configurations are contained.
Data handlers
Data handlers are reusable transformation logic independent of a specific transport protocol like JMS or HTTP. They can be invoked from data bindings and Java™ components.
The following sections explain the value of data handlers, the data handlers that are included with BPM and how to create your own data handlers.
Overview of data handlers
How to create a data handler, configure a data handler instance and call the data handler from a binding are discussed in this section.
In your service-oriented architecture (SOA) implementation, business data can flow between service providers and service consumers over a variety of protocols (HTTP, JMS, MQ, EIS and so on) in a variety of data formats such as comma separated value, delimited, fixed width, COBOL and so on. Different protocols have different mechanisms for carrying the business data in their protocol envelope. For example, in the case of JMS, as a message body of JMS message; in the case of HTTP, as payload of HTTP message. While the business protocol envelope is different, the business data may or may not be in same format across these protocols. The format in which business data flows on the wire between service provider and service consumer is referred to as the native format.
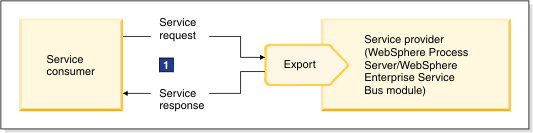
Business process components running on Process Server understand business data as business objects but they do not understand the native format in which the data is flowing. Therefore, an export of an Process Server module needs to de-serialize business data in native format obtained from a protocol message which was received itself in a request from a service consumer, into a business object. The export then invokes the business process component with the business object. For two-way operations (as shown in the diagram) the business object response from business process needs to be serialized into native data format, which then can be packed into the transport protocol message to be returned as a response to service requester. 1 indicates the message protocol carrying business data in native format.
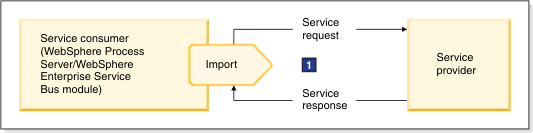
Likewise, to invoke a service, the business process components running on Process Server need to serialize a business object into native data format. Therefore, an import of an Process Server module needs to serialize a business object to business data in a native format, which then is packaged into the transport protocol message used to invoke the target service. For a two-way operation, a business response in native data format obtained from the protocol response message needs to be de-serialized into a business object. 1 indicates the message protocol carrying business data in native format.
Process Server data bindings can be developed to serialize and de-serialize business data. However for scenarios where the same native data format can flow over multiple transport protocols (HTTP, JMS, MQ, EIS), the data transformation logic needs to be repeated for each of the data bindings. For these scenarios Process Server introduces the concept of data handlers.
Data handlers are reusable transformation logic in Process Server which can be invoked from data bindings, flow components and Java™ components. Data handlers can be configured on some bindings and can be used in flow components. Unlike data binding interfaces, the data handler interface is protocol neutral, which enables data handlers to be usable across the bindings. Additionally, if your scenario requires a business object to native data format transformation beyond the normal types of data transformation, you can call a data handler that can support that format from your Java components.
Data handler implementation can call other data handlers. This is referred to as data handler chaining. Data handler chaining is very useful for complex native data formats. For such formats if transformation logic is complex the data handler implementation can call other data handlers. For example if the native protocol message has multiple parts, data handlers can be developed for each part. The complex data handler for this multi-part message can call the data handlers for each of the parts.
This section illustrates how to author data handlers, how to configure them, how to call them and use them with your data bindings or in your Java components.
Prepackaged data format handlers
Several data format handlers are included with BPM.
The following data format handlers are available with BPM.
If you intend to use the standard JMS message class with a body type containing the message then use the business objects provided for these body types. To create these business objects, a predefined resource is available. To add this predefined resource, expand your module and then double-click Dependencies. The Dependencies editor opens. Expand Predefined Resources and select Native Body Schema for Native Body DataHandler. Save your work.
| Data format handler | Description | Simple type supported? |
|---|---|---|
| Atom feed format | This data format handler should be used when you have serialized data in a format an Atom feed format as input into an export or need to generate serialized data in an Atom feed format for an import. It can be used with JMS, MQ JMS, generic JMS, MQ and HTTP bindings. | No |
| Delimited format | This data format handler should be used when you have serialized data in a format using a delimiter as input into an export or need to generate serialized data in a format using a delimiter for an import. It can be used with JMS, MQ JMS, generic JMS, MQ and HTTP bindings. | No |
| Fixed width format | This data format handler should be used when you have serialized data in a fixed width format as input into an export or need to generate serialized data in a fixed width format for an import. It can be used with JMS, MQ JMS, generic JMS, MQ and HTTP bindings. | No |
| JavaScript Object Notation (JSON) format | This data format handler should be used when you have serialized data in a JavaScript Object Notation (JSON) format as input into an export or need to generate serialized data in a JSON format for an import. It can be used with JMS, MQ JMS, generic JMS, MQ and HTTP bindings. | No |
| SOAP data handler | The SOAP data handler parses and serializes both SOAP messages and the header, as well as the SOAP fault details. | Yes |
| WTX Invoker Data Handler | This data format handler invokes WTX to do the transformation. This data handler needs a WTX map name which is provided by the WTX MapSelectionDataHandler. | No |
| WTX MapSelection Data Handler | This data format handler should be used if you are creating a configuration that makes use of the Email, FTP and Flat Files adapters. | No |
| XML Data Handler | This data format handler should be used when you have serialized XML data as input into your export (for inbound processing at run time) or need to generate serialized XML data for an import (for outbound processing at run time). | Yes |
Developing data handlers
You can create your own data handlers in addition to using the data handlers that are included with BPM.
This section shows you how to create your own data handlers specific to your own needs.
- Data handler authoring Creating a data handler requires knowledge of the interfaces, types of transformations and configurations.
- Data handler resource configuration Once you decide either on using a pre-packaged data handler or one that you have created, you need to create a data handler resource configuration with the a wizard in IBM Integration Designer. This section references the instructions to create the data handler resource configuration.
- Calling data handlers from bindings As mentioned earlier, data handlers in Process Server are not callable from exports or imports directly. This section illustrates how to call data handlers from JMS, MQ and HTTP bindings. It assumes you are familiar with data bindings for JMS, MQ JMS, generic JMS, MQ, and HTTP bindings.
Data handler authoring
Creating a data handler requires knowledge of the interfaces, types of transformations and configurations.
Creating a data handler involves knowledge of the following elements.
- Data handler interface
- Binding context interface
- Data handler transformations
- Native data format to DataObject transformations
- DataObject to native data format transformations
- ServiceRuntimeException to native data transformations
- Native data to ServiceRuntimeException transformations
- Data handler configuration
- Specifying configuration properties
- Access configuration properties
- Obtain a business object type
- Binding registry and invoking other data handlers
- Data handler implementation outline
Data handler interface
The data handler provides the transformation function for transforming from one form (source) to another (target). The result of the transformation is mapped into either a provided target type or a new instance of a specified target. All data handlers must implement the DataHandler interface which has methods that map into a provided target type or into a new instance of a specified target.
package commonj.connector.runtime;
public interface DataHandler extends commonj.connector.runtime.BindingContext
{
public Object transform(Object source, Class targetClass,
Object options)
throws DataHandlerException;
public void transformInto(Object source, Object target, Object options)
throws DataHandlerException;}
Let us first explore the transformation that maps into a provided target type.
public Object transform(Object source, Class targetClass, Object options)
throws DataHandlerException;
In the implementation of this method, the data handler is expected to transform data from the source object to a new instance of the targetClass. options provides additional hints for the transformation. The signature of this method is very generic. It allows both the source object to be of any type and the targetClass to be of any type. This method requires the data handler implementation to construct the target object type, which is given by targetClass. If there is any error during the transformation, the data handler implementation is expected to throw a DataHandlerException.
There are scenarios where the target object instance is available to the caller. For such scenarios, the DataHandler interface provides a transformInto method.
public void transformInto(Object, Object target, Object options)
throws DataHandlerException;
In this method implementation the data handler is expected to transform data from the source object to the target object. options provides additional hints for the transformation. The signature of this method is very generic. It allows the source object to be of any type and the target object to be of any type. If there is any error during the transformation data handler implementation is expected to throw a DataHandlerException.
Binding context interface
The binding context contains runtime contextual information passed from the caller to the data handler. The BindingContext interface specifies the runtime context of the data handler. The DataHandler interface extends from BindingContext interface. Therefore, each data handler implementation needs to implement the setBindingContext method of the BindingContext interface.
public void setBindingContext( Map context)
{
this.context = context;
}
The context is a Map. The key gives the name of the context information and the value passed gives its value. Refer to the BindingContext class for the information that bindings can provide in the context. The following table contains the list of some of the relevant information available in the context.
| Key | Value | Description of value |
|---|---|---|
| BindingContext.BINDING_COMMUNICATION | BindingContext.BINDING_COMMUNICATION_INBOUND BindingContext.BINDING_COMMUNICATION_OUTBOUND | Indicates if the native data is coming into the module or going out of the module. |
| BindingContext.BINDING_CONFIGURATION | Configuration properties for a JavaBean. | This JavaBean provided by the data handler implementation contains the values for the properties that are set at design time.
This information is set by the BindingRegistry which instantiated
the data handler.
See Access configuration properties for more details. |
| BindingContext.BINDING_INVOCATION | BindingContext.BINDING_INVOCATION_REQUEST BindingContext.BINDING_ INVOCATION_RESPONSE BindingContext.BINDING_ INVOCATION_FAULT | Indicates whether the invocation to the data handler is in the context of a request, response or fault. |
| BindingContext.BINDING_NAME | String | Name of the export or import |
| BindingContext.EXPECTED_TYPE | Qualified name (QName) of the business object. | The QName of the expected type of business object for native data to business object transformation. This information is set by the caller of the data handler.
See Obtain a business object type for more details. |
| BindingContext .BINDING_REGISTRY | Runtime implementation of the Binding registry. | The Binding registry maintains all the data handler, data binding and function selectors. This information is set by the BindingRegistry which instantiated the data handler.
See Binding registry and invoking other data handlers for more details. |
| WPSBindingContext.FAULT_NAME | String | Name of the business fault in case of export response |
| WPSBindingContext.TRANSFORMED_DATA | Object | This allows context data sharing between the function selector and data handler, and fault selector and data handler. If the data is already parsed or read by the function selector or fault selector then it can be stored in the context and passed onto the data handler so the data handler does not re-read it. |
Data handler transformations
As mentioned previously, data handler interface signatures are very generic. The data handler can allow transformation between source of any type and target of any type. A generic interface enables data handler implementations to support transformations between multiple types of objects. While the interface is generic, there are limited transformations that are relevant from the Process Server perspective; these are the transformations with are described in this section. . If you decide to implement a data handler, you may decide to support some or all of these transformations. Calling data handlers from bindings describes how various transformations can be used from different export and import bindings.
Business processes and mediation flows in Process Server understand business data as a DataObject type. This constrains one side of the transformation to be DataObject. The transformations relevant from Process Server can be grouped into the following categories:
Native data format to DataObject transformations
In Process Server, the binding (HTTP, MQ, JMS and EIS) receives business data in native format inside a protocol envelope. The binding then invokes the data binding to obtain the data object from the transport envelope. Depending on the transport and type of transport envelope, the business data in native transport envelope can be obtained as characters or bytes or as java.lang.Object. Calling data handlers from bindings describes how this can be done. Therefore to be usable across these bindings, it is sufficient for data handlers to support the source object as java.io.InputStream, java.io.Reader and java.lang.Object.
| Source object | Description |
|---|---|
| java.io.InputStream | If the business data in native format is byte stream, then either it is in the form of an input stream which can be passed directly to the data handler or it is in the form of raw
bytes from which an input stream can be constructed. This input stream can be used to invoke the data handler.
dataObject = (DataObject) dh.transform(inputStream, DataObject.class, options); |
| Java.io.Reader | If the business data in native format is characters, then either it is in the form of a reader which can be passed directly to the data handler or it is in the form of raw characters from which a reader can be constructed. This reader can be used to invoke the data handler.
dataObject = (DataObject) dh.transform(reader, DataObject.class, options); |
| Java.lang.Object | If the business data in native format is received as Java™ object, data handlers for such protocols should support Java object to DataObject transformations.
dataObject = (DataObject) dh.transform(object, DataObject.class, options); |
DataObject to native data format transformations
In Process Server, the binding (HTTP, MQ, JMS and EIS) sends business data in native format inside a protocol envelope. The binding then invokes the data binding to obtain the transport envelope from the data object. Depending on the transport and type of transport envelope, the business data in the native transport envelope can be as sent as characters or bytes or as java.lang.Object. Calling data handlers from bindings describes how this can be done. To be usable across these bindings, it is sufficient for data handlers to support target objects as one or more of the following types: java.io.Writer, java.io.OutputStream, java.lang.Object and java.io.InputStream.
| Target object | Description |
|---|---|
| java.io.Writer | If the caller wants the data handler to write native data as character type on the protocol character stream, the caller can invoke the transformInto method with a target object of type java.io.Writer. Some protocols require java.lang.String (for
example, JMS TextMessage). For such protocols, the caller can invoke the data handler with java.io.StringWriter.
dh.transformInto(dataObject, writer, options); |
| java.io.OutputStream | If the caller wants the data handler to write the native data as bytes on the protocol byte stream, the caller can invoke the transformInto method with a target object of type java.io.OutputStream.
Some protocols require byte[] ( JMS ByteMessage). For such protocols, the caller can invoke the data handler with the in-memory
byte output stream.
dh.transformInto(dataObject, outputStream, options); |
| java.io.InputStream | If the caller wants the data handler to provide a byte stream from which the caller can read the transformed native data, the caller can invoke the transform method requesting a target object of type java.io.InputStream.
InputStream is = (InputStream) dh.transform(dataObject, java.io.InputStream.class, options); |
| java.lang.Object | If the caller wants the data handler to transform the business object into an object, the caller can invoke the transform method requesting a target object of type java.lang.Object.
Object o = dh.transform(dataObject, Object.class, options); |
ServiceRuntimeException to native data transformations
If you are authoring a data handler to transform a ServiceRuntimeException to native data, then there are additional transformations that you have to code in your data handler.
| Source object | Target object | Description |
|---|---|---|
| ServiceRuntimeException | OutputStream | If the caller wants the data handler to convert the ServiceRuntimeException object to the native data as bytes on the protocol byte stream, the caller can invoke the transformInto method with a target object of type java.io.OutputStream. Some protocols require byte[] ( JMS ByteMessage). For such protocols, the caller can invoke the data handler with the in-memory byte output stream: dh.transformInto(serviceRuntimeException, outputStream, options); |
| ServiceRuntimeException | Writer | If the caller wants the data handler to convert the ServiceRuntimeException object to the native data as string on the protocol stream, the caller can invoke the transformInto method with a target object of type java.io.Writer. Some protocols require string ( JMS TextMessage). For such protocols, the caller can invoke the data handler with the in-memory writer: dh.transformInto(serviceRuntimeException, writer, options); |
| ServiceRuntimeException | Object.class | If the caller wants the data handler to convert the ServiceRuntimeException object to the native data as serialized object on the protocol stream, the caller can invoke the transform method with a target class of type java.io.Object. For such protocols, the caller can invoke the data handler as follows: dh.transform(serviceRuntimeException, Object.class, options); |
Native data to ServiceRuntimeException transformations
If you are authoring a data handler to transform native data to ServiceRuntimeException, then there are additional transformations that you have to code.
| Source object | Target class | Description |
|---|---|---|
| InputStream | ServiceRuntimeException.class | If the business data in native format is byte stream, then the data handler gets an input stream which is constructed from the byte stream. The data handler is expected to convert this native data to a ServiceRuntimeException object: dataObject = (DataObject) dh.transform(inputStream, ServiceRuntimeException.class, options); |
| Reader | ServiceRuntimeException.class | If the business data in native format is a string, then the data handler gets a reader which is constructed from the String. The data handler is expected to convert this native data to a ServiceRuntimeException object: dataObject = (DataObject) dh.transform(reader, ServiceRuntimeException.class, options); |
| Object | ServiceRuntimeException.class | If the business data in native format is a simple type object or a seriliazed object, then the data handler gets an object. The data handler is expected to convert this native data to a ServiceRuntimeException object: dataObject = (DataObject) dh.transform(object, ServiceRuntimeException.class, options); |
Data handler configuration
Configure a data handler consists of specifying the configuration properties at authoring time and then accessing the configuration properties at run time. The following sections show you how to work with the configuration properties:
Specifying configuration properties
The data handler implementation can have configuration properties. For example, a delimited data handler can have a configuration for delimiter. Data handlers are configured at authoring time from IBM Integration Designer.
In order for this data handler to be configured from IBM Integration Designer, the following rules apply:
- The data handler implementation provides a JavaBean class for its configuration.
- This class is required to be in the same package as the data handler implementation class.
- This class should implement the java.io.Serializable interface.
- The name of this class should have Properties appended to the data handler implementation class name.
- There has to be a set and get method for every configuration property in this class.
For example if the data handler implementation class is com.example.DelimitedDataHandler, the configuration class is com.example.DelimitedDataHandlerProperties.
1 import java.io.Serializable;
2
3 public class DelimitedDataHandlerProperties
4 implements Serializable
5 {
6 protected String delimiter = ",";
7
8
9 public String getDelimiter(){
10 return delimiter;
11 }
12
13 public void setDelimiter (String delimiter){
14 this.delimiter = delimiter;
15 }
}
In this example, delimiter is a property of String type. The other types that are supported for the properties are boolean, Boolean, byte, Byte, char, Character, double, Double, float, Float, int, Integer, JavaBeans, long, Long, short, Short, String, BindingTypeBeanProperty.
BindingTypeBeanProperty is a type used when the type is a configuration namespace and name. This is used when there is a data handler calling another data handler and the called data handler is configured as a property. Arrays are also supported, but only the default user interface rendering (no configuration) is supported for simple arrays.
Before the data handler can be invoked, the data handler needs to be configured in IBM Integration Designer. There can be multiple configurations for the same data handler. Configuring data handler instances describes how resource configurations are created for data handlers in IBM Integration Designer. In Integration Designer each data handler configuration has a QName. For example, delimited data handler can have following two configurations:
http://configtns:configuration_1: delimiter = ! http://configtns:configuration_2: delimiter = *
Access configuration properties
The values for the configuration properties set at author time are accessed by the data handler implementation at run time from the binding context class. The binding context contains runtime contextual information passed from the caller to the data handler. The BindingContext interface specifies the runtime context of the data handler. The DataHandler interface extends from the BindingContext interface. Therefore each data handler implementation needs to implement the setBindingContext method of the BindingContext interface.
public void setBindingContext( Map context)
{
this.context = context;
// get information from context // ... }
The context is a Map. The key gives the name of the context information and the value for the key gives its value. The properties are accessed from the binding context using BindingContext.BINDING_CONFIGURATION. The following example illustrates how the Delimited data handler can access its properties:
DelimitedDataHandlerProperties properties = null;
if(context != null)
properties =
(DelimitedDataHandlerProperties)context.get(BindingContext.BINDING
_CONFIGURATION);
if(properties != null)
delimiter = properties.getDelimiter();
Obtain a business object type
For native to business object transformations, if the caller has advanced knowledge of the type of business object in the native data, the caller can specify that type in the binding context to the data handler. The key name is BindingContext.EXPECTED_TYPE and the value is the QName of the expected type. The data handler implementation can use BindingContext.EXPECTED_TYPE to construct the business object from the native data. Some data handlers may require BindingContext.EXPECTED_TYPE be supplied to them in the binding context. However, for some formats, type information is available in the native business data. Such data handlers may not require BindingContext.EXPECTED_TYPE in the context. If the caller supplied BindingContext.EXPECTED_TYPE, the data handler implementation may obtain it from the context as follows:
- QName expectedType = (QName) context.get(BindingContext.EXPECTED_TYPE);
Binding registry and invoking other data handlers
The binding registry provides the means of retrieving configured DataBinding, DataHandler or FunctionSelector instances. The binding registry can be obtained from the BindingRegistryFactory class. BindingRegistryFactory provides a static method to get an instance of BindingRegistry. the following code snippet illustrates how the binding registry can be used to obtain configured instances of data handler. This code snippet assumes the user has configured the data handler instance with a QName of "http://ProcessCustomerWPS, DelimitedDataHandlerConfig".
QName config = new QName("http://ProcessCustomerWPS",
"DelimitedDataHandlerConfig");
BindingRegistry bindingRegistry = BindingRegistryFactory.getInstance();
DataHandler dataHandler =
(DataHandler) bindingRegistry.locateBinding( config,
bindingContext);
A data handler implementation, a data binding implementation, and a Java component implementation can use the binding registry to obtain the configured data handler instance. The required transformation method can then be called on the data handler instance.
- dataHandler.transformInto(dataObject, outputStream, options);
The binding registry enables data handler reuse. There are multiple scenarios where the native data needs multiple transformations before the business object can be constructed and, similarly, the business object needs multiple transformations before the required native data can be obtained.
- Multi-layer native format: A native data format can require multiple transformation layers. For example, the business data is delimited, compressed and encrypted. The native data first needs decryption, followed by decompression to obtain delimited data. Delimited data can then be converted into a business object. Similarly, business object to native format can require multiple transformation layers. For example, the first business object needs to be converted to a delimited format, followed by compression and encryption.
- Multi-part native format: In this case, each part of the message is in a different format. An Email message with multiple attachments is one such example. To compose a wrapper business object from native data requires transforming each part with a data handler which can then handle the format for that part. Similarly, to compose a native message requires transforming each child business object of the wrapper business object with a data handler which can transform that child business object into the required native format for that part.
For such scenarios, data handler implementations can invoke other data handlers. This is called the chaining of data handlers. For example let us consider delimited, compressed data format. The compress data handler can be developed to reuse delimited data handler as follows:
- Native data format to DataObject transformation: Compress data handler de-compresses native data and then calls the configured delimited data handler instance to obtain the business object.
- DataObject to native data format transformation: Compress data handler calls the configured delimited data handler instance to transform the business object into delimited data. It then compresses the delimited data.
Data handler implementation outline
Following code snippet provides outline for data handler implementation. It provides outline for all the transformations described in Data handler transformations.
1 public class DataHandlerOutline
2 implements DataHandler
3 {
4
5 private DataHandlerOutlineProperties config;
6 private Map context;
7
8 public void setBindingContext(Map context)
9 {
10 this.context = context;
11 config = (DataHandlerOutlineProperties) context.get(BindingContext.BINDING_CONFIGURATION);
12 }
13
14 public Object transform(Object source, 15 Class target, 16 Object options)
17 throws DataHandlerException 18 {
19 if ((source == null) || (target == null))
20 return null;
21
22 // native data format to DataObject transformations
23 if (target == DataObject.class) {
24 if (source instanceof InputStream) {
25 // TODO: Transform InputStream to DataObject 26 }
27 else if (source instanceof Reader) {
28 // TODO: Transform Reader to DataObject 29 }
30 else {
31 // TODO: Transform Object to DataObject 32 }
33 }
34
35 // DataObject to native data format transformations
36 if (source instanceof DataObject) {
37 if (target == InputStream.class) {
38 // TODO: Transform DataObject to InputStream
39 }
40 else {
41 // TODO: Transform DataObject to Object 42 }
43 }
44 throw new DataHandlerException("Transformation not supported");
45 }
46
47 public void transformInto(Object source, 48 Object target, 49 Object options)
50 throws DataHandlerException 51 {
52 if ((source == null) || (target == null))
53 return;
54
55 if (source instanceof DataObject)
56 if (target instanceof OutputStream) {
57 // TODO: Transform DataObject into given OutputStream
58 }
59 throw new DataHandlerException("Transformation not supported");
60 }
61 }
- Service Message Object (SMO) headers Service Message Object headers provide protocol-specific and protocol-neutral headers to author data handlers.
Service Message Object (SMO) headers
Service Message Object headers provide protocol-specific and protocol-neutral headers to author data handlers.
In order to perform the data transformation, some data handlers need access to protocol headers. These headers could be protocol neutral like DataBindingDescriptor or they can be protocol specific like JMSType. Some examples of protocol neutral headers are JMS user properties, HTTP custom headers, MQRFH2 user properties, and so on. The programming model to access these headers is a Service Message Object (SMO) in the context service which is essentially data object APIs. The protocol neutral headers are stored in the context in a protocol neutral manner such the data handler can access it with a uniform XPath expression independent of whether this information came from a JMS header, a MQ header, and so on.
- Service Message Object (SMO) headers at run time The behavior of the Service Message Object (SMO) headers at run time differ depending on whether they are used by an export or import.
- Binding-specific headers in a Service Message Object (SMO) Where data handlers can find the header information for a binding is described.
- Code to access binding-specific headers Accessing the binding-specific headers from a SMO header in a data handler requires only a few lines of code.
Service Message Object (SMO) headers at run time
The behavior of the Service Message Object (SMO) headers at run time differ depending on whether they are used by an export or import.
Export request and import response
An export will create an SMO header and put the protocol neutral and protocol specific headers in the SMO header. It will then set the SMO header in the binding context and set the binding context on the data handler. Once the data handler returns, it will read the headers from the SMO header (since they could have been modified by the data handler) and populate them in the SCA message.
Import request and export response
An import will read the headers from the SCA message, create a Service message Object and put the headers in the SMO header. The SMO header will then be put in the binding context and set on the data handler. Once the data handler returns, it will read the headers from the Service Message Object and populate them in the outgoing protocol specific message.
Binding-specific headers in a Service Message Object (SMO)
Where data handlers can find the header information for a binding is described.
The sections below list all the header information that is in the system today for each protocol. The highlighted sections indicate the sections that are common and should be available to the data handler in a generic manner.
- JMS header
- MQ header
- HTTP header
- EIS headers in a Service Message Object (SMO)
- EIS Email header
- EIS FTP header
- EIS Flat File header
JMS header
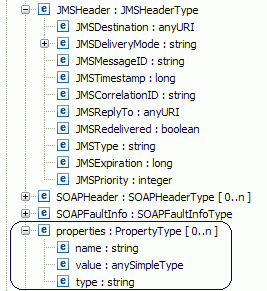
The JMS user properties will be added to the properties section shown below.
MQ header
The MQ rfh2 user folder will be added to the properties section.
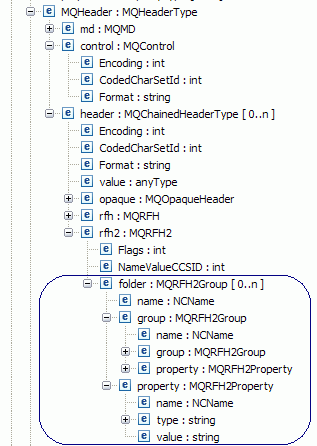
Folder is equal to the usr folder in the diagram.
HTTP header
The HTTP custom headers will be added to the properties section in the SMO header.
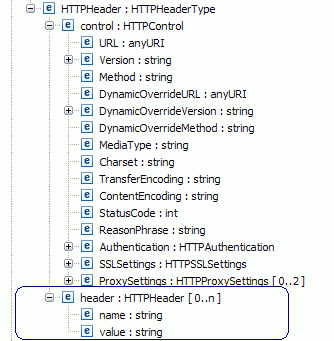
EIS headers in a Service Message Object (SMO)
The data object that will be set in the EISConnectionSpec and EISInterationSpec classes at run time for the Email, FTP and Flat File adapters is shown below.
The data structure is as follows:
EISHeader EISHeaderType EISConnectionSpec anyType EISInteractionSpec anyType
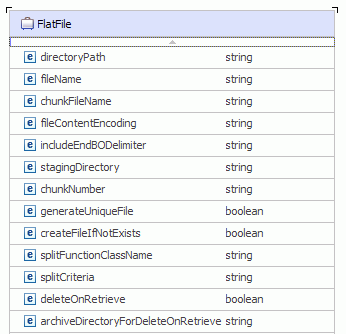
EIS Flat File header
The ConnectionSpec properties are not required. The InteractionSpec properties for inbound and outbound processing are shown.
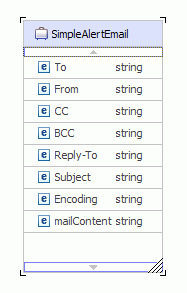
EIS Email header
The ConnectionSpec properties are userid and password. The InteractionSpec properties for inbound and outbound processing are shown.
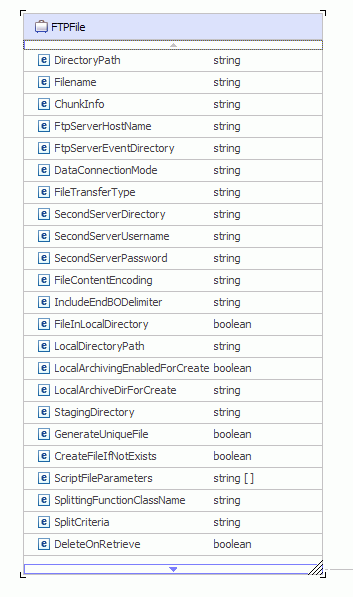
EIS FTP header
The ConnectionSpec properties are userid and password. The InteractionSpec properties for inbound and outbound processing are shown.
Code to access binding-specific headers
Access the binding-specific headers from a SMO header in a data handler requires only a few lines of code.
Access SMO headers in data handlers
The following programming examples show how the header information can be accessed by the data handlers.
Access the properties section of an SMO header
Consider the case where there is a property called businessObjectName in the properties section of the SMO header.
1 DataObject header = (DataObject) ContextService.INSTANCE.getHeaders();
2 List<DataObject> userPropertiesList = header.getList("properties");
3 for (DataObject userProperty : userPropertiesList) {
4 String name = userProperty.getString("name");
5 if (name.equals("businessObjectName")) {
6 String businessObjectName = userProperty.getString("value");
7 }
8 }
Access a JMS header from an SMO header
To access the JMS header from the SMO header, you would use the following code:
9 DataObject header = (DataObject) ContextService.INSTANCE.getHeaders();
10 DataObject jmsHeader = header.getDataObject("JMSHeader");
11 String jmsMessageID = jmsHeader.get("JMSMessageID");
Access an MQ header from an SMO header
To access the MQ header from the SMO header, you would use the following code:
12 DataObject header = (DataObject) ContextService.INSTANCE.getHeaders();
13 DataObject mqHeader = header.getDataObject("MQHeader");
14 DataObject mqmd = mqHeader.get("md");
Access an HTTP header from an SMO header
To access the HTTP header from the SMO header, you would use the following code:
15 DataObject header = (DataObject) ContextService.INSTANCE.getHeaders();
16 DataObject httpHeader = header.getDataObject("HTTPHeader");
17 DataObject httpControl = mqHeader.get("HTTPControl");
Access an EIS Flat File header from an SMO header
To access the EIS Flat File header from the SMO header, you would use the following code:
18 DataObject header = (DataObject) ContextService.INSTANCE.getHeaders();
19 DataObject eisHeader = header.getDataObject("EISHeader");
20 DataObject eisIneractionSpec = mqHeader.get("EISInteractionSpec");
Data handler resource configuration
Once you decide either on using a pre-packaged data handler or one that you have created, you need to create a data handler resource configuration with the a wizard in IBM Integration Designer. This section references the instructions to create the data handler resource configuration.
To create a data handler resource configuration, see Create a data format transformation resource configuration, which you will also find in the Creating resource configurations section.
Calling data handlers from bindings
As mentioned earlier, data handlers in Process Server are not callable from exports or imports directly. This section illustrates how to call data handlers from JMS, MQ and HTTP bindings. It assumes you are familiar with data bindings for JMS, MQ JMS, generic JMS, MQ, and HTTP bindings.
The following sections show how the delimited data handler created previously is invoked from these data bindings.
- JMS, MQ JMS and Generic JMS data bindings
- MQ data binding
- HTTP data binding
- Configure a data binding to call a data handler
- Use data handler instances from multiple threads
JMS, MQ JMS and Generic JMS data bindings
The code snippets that follow show how the delimited data handler whose configuration was created previously is invoked from the JMS data bindings. The JMS data binding implementation uses the configuration QName of the data handler to obtain and create the data handler instance from the binding registry.
- Converting native data to data object
- The String or bytes data is extracted from the JMS Message and a corresponding reader or inputstream is created and passed to the data handler. The data handler converts the input native data to a business object and returns it to the data binding.
1 public void read(Message jmsMessage) 2 throws JMSException 3 { 4 QName configurationName = new QName("http://ProcessCustomerWPS", "DelimitedDataHandlerConfiguration"); 5 DataHandler dataHandler = (DataHandler)bindingRegistry.locateBinding(configurationName, bindingContext); 6 7 if (jmsMessage instanceof TextMessage) { 8 String textMessage = ((TextMessage) jmsMessage).getText(); 9 Reader reader = new StringReader(textMessage); 10 this.dataObject = (DataObject)datahandler.transform(reader,DataObject.class, null); 11 return; 12 } 13 14 if (jmsMessage instanceof BytesMessage) { 15 BytesMessage bytesMessage = (BytesMessage) jmsMessage; 16 byte[] sourceBytes = new byte[(int) bytesMessage.getBodyLength()]; 17 bytesMessage.readBytes(sourceBytes); 18 ByteArrayInputStream InputStream = new ByteArrayInputStream(sourceBytes); 19 this.dataObject = (DataObject)datahandler.transform(inputStream, DataObject.class, null); 20 return; 21 } 22 } - Converting data object to native data
- In case of TextMessage, a Writer is created and passed to the data handler transformInto method. For BytesMessage, an OutputStream
is created and passed into the transformInto method.
24 public void write(Message jmsMessage) 25 throws JMSException 26 { 27 QName configurationName = new QName("http://ProcessCustomerWPS", "DelimitedDataHandlerConfiguration"); 28 BindingRegistry bindingRegistry = BindingRegistryFactory.getInstance(); 29 DataHandler dataHandler = (DataHandler)bindingRegistry.locateBinding(configurationName, bindingContext); 30 if((jmsMessage instanceof TextMessage){ 31 Writer writer = new StringWriter(); 32 datahandler.transformInto(dataObject, Writer, null); 33 String messageString = writer.toString(); 34 ((TextMessage) message).setText(messageString); 35 return; 36 } if((jmsMessage instanceof BytesMessage) 37 ByteArrayOutputStream outputStream = new ByteArrayOutputStream(); 38 datahandler.transformInto(dataObject, outputStream, null); 39 byte[] messageBytes = outputStream.toByteArray(); 40 ((BytesMessage) message).setBytes(messageBytes); 41 return; 42 }
MQ data binding
The following code snippet shows how the delimited data handler is invoked from the MQ data binding. The MQ data binding implementation uses the configuration QName of the data handler to obtain and create the data handler instance from the binding registry.
- Converting native data to data object
- If the format is null, the InputStream is directly passed to the data handler. If the format is MQSTR, then a reader is constructed
from the characters and passed to the data handler. The data handler converts the input native data to a business object and returns it to the data binding.
1 public void read(MQMD md, 2 List headers, 3 MQDataInputStream inputStream) 4 throws IOException 5 // Create the configuration information for the child DataHandler 6 QName configurationName = new QName("http://ProcessCustomerWPS", "DelimitedDataHandlerConfiguration"); 7 BindingRegistry registry = BindingRegistryFactory.getInstance(); 8 DataHandler dataHandler = (DataHandler) bindingRegistry.locateBinding(configurationName, context); 9 10 if(format != null && (format.equals("MQSTR") || format.equals("")) 11 { 12 String textMessage = inputStream.readMQChar(InputStream.available()); 13 Reader reader = new StringReader(textMessage); 14 this.dataObject = (DataObject)datahandler.transform(reader,DataObject.class, null); 15 16 } 17 else 18 { 19 this.dataObject = (DataObject)dataHandler.transform(inputStream, DataObject.class, null); 20 } 21 //deal with business exception 22 } - Converting data object to native data
- If the format is MQSTR, a Writer is created and passed to the data handler transformInto method otherwise the OutputStream is directly passed into the transformInto method of data handler.
1 public void write(MQMD md, 2 List headers, 3 MQDataOutputStream output) 4 throws IOException 5 { 6 // Create the configuration information for the child DataHandler 7 QName configurationName = new QName("http://ProcessCustomerWPS", "DelimitedDataHandlerConfiguration"); 8 9 BindingRegistry registry = BindingRegistryFactory.getInstance(); 10 DataHandler dataHandler = (DataHandler) bindingRegistry.locateBinding(configurationName, context); 11 12 if(format != null && (format.equals("MQSTR") || format.equals("")) 13 { 14 Writer writer = new StringWriter(); 15 datahandler.transformInto(dataObject, writer, null); 16 String messageString = writer.toString(); 17 output.writeMQChar(messageString); 18 } 19 else 20 { 21 22 dataHandler.transformInto(dataObject, output, null); 23 } 24 }
HTTP data binding
The following code snippet shows how the delimited data handler is invoked from the HTTP data binding. The HTTP data binding implementation uses the configuration QName of the data handler to obtain and create the data handler instance from the binding registry.
- Converting native data to data object
- The bytes are read from the HTTPInputStream and an input stream is created from those bytes. The input stream is then passed to the data handler.
25 public void convertFromNativeData(HTTPInputStream inputStream) 26 throws DataBindingException, IOException 27 { 28 // Create the configuration information for the child DataHandler 1 QName configurationName = new QName("http://ProcessCustomerWPS", "DelimitedDataHandlerConfiguration"); 2 BindingRegistry registry = BindingRegistryFactory.getInstance(); 3 DataHandler dataHandler = (DataHandler) registry.locateBinding(configurationName, context); 4 byte[] bytes = httpInputStream.getBytes(); 5 ByteArrayInputStream InputStream = new ByteArrayInputStream(bytes); 6 7 this.dataObject = dataHandler.transform(inputStream, DataObject.class, null); 8 //... 9 } - Converting data object to native data
- An OutputStream is created and passed into the transformInto method.
The result of the transformation is then extracted from the outputstream
and set on the HTTPOutputStream.
10 public void write(HTTPOutputStream output) 11 throws IOException 12 { 13 // Create the configuration information for the child DataHandler 14 QName configurationName = new QName("http://ProcessCustomerWPS", "DelimitedDataHandlerConfiguration"); 15 BindingRegistry registry = BindingRegistryFactory.getInstance(); 16 DataHandler dataHandler = (DataHandler) registry.locateBinding(configurationName, context); 17 18 ByteArrayOutputStream outputStream = new ByteArrayOutputStream(); 19 dataHandler.transformInto(dataObject, outputStream, null); 20 byte[] messageBytes = outputStream.toByteArray(); 21 22 httpControl.setContentLength(bytes.length); 23 output.write(messageBytes); 24 25 // ... 26 }
Configure a data binding to call a data handler
We have shown how to call a data handler from a data binding with example code. You can also configure a data binding to call a data handler using the binding resource configuration wizard, where the data handler is configured as a property (see Create a data format transformation resource configuration).
Use data handler instances from multiple threads
The data handler instance created as described is not thread safe so a data handler instance should not be called from more than one thread. Create a new instance each time you need to apply the data handler.
Data handler formats
The Atom feed, delimited, fixed width, JSON formats and SOAP data handler are discussed in detail.
Understanding the Atom feed, delimited, fixed width, JSON formats and SOAP data handler can be helpful to you especially if you are about to configure your own import or export with these data bindings and are unfamiliar with some of the format details about each one. In this section, we examine the file structure, corresponding business object for that structure, cardinality, and properties of each format.
- Atom feed format The Atom feed format is discussed.
- Delimited format The delimited format used with a CSV file is discussed.
- Fixed width format The fixed width format is discussed.
- JavaScript Object Notation (JSON) format The JavaScript Object Notation (JSON) format is discussed.
- SOAP data handler The SOAP data handler parses and serializes both SOAP messages and the header, as well as the SOAP fault details.
Atom feed format
The Atom feed format is discussed.
The term "Atom" applies to two related standards:
- The Atom Syndication Format is an XML language used for web feeds.
- The Atom Publishing Protocol (AtomPub or APP) is a simple HTTP-based protocol for creating and updating web resources.
Web feeds allow clients to check for updates published on a web site. To provide a web feed, a web site publishes a list of recent articles or content in a standardized, machine-readable format. This list is known as a feed. The feed can then be downloaded by web sites that syndicate content from the feed or by feed-reader programs.
The Atom feed format has a well defined schema. The feed contains multiple entries and each entry is associated with content. The content can either be inline or the content can be available at the link specified. The content has associated type information which is the mime type of the content.
There are three well-defined types called "text", ""html" and "xhtml". A user can provide his own types complying to the rules of Atom specification.
Inbound data
For inbound data, the Atom data handler converts the Atom feed into a well-defined business object. If the feed contains inline content, then, based on the configuration setup on the data handler, it will call the configured data handler to convert the inline content to a business object and set that business object in the feed. You must provide a schema for the business object corresponding to this inline content.
Consider the following example. There are two entries in the feed. The content type of the first entry is XML and the other entry is JSON. This is what the input data would look like.
287 <?xml version="1.0" encoding="utf-8"?>
288 <feed xmlns="http://www.w3.org/2005/Atom">
289
290 <title>Example Feed</title>
291 <subtitle>A subtitle.</subtitle>
292 <link href="http://example.org/feed/" rel="self"/>
293 <link href="http://example.org/"/>
294 <updated>2003-12-13T18:30:02Z</updated>
295 <author>
296 <name>John Doe</name>
297 <email>johndoe@example.com</email>
298 </author>
299 <id>urn:uuid:60a76c80-d399-11d9-b91C-0003939e0af6</id>
300
301 <entry>
302 <content type="text/xml">
303 <p:Customer xmlns:p="http://www.ibm.com/crm" xmlns="http://www.ibm.com/crm">
304 <id>10</id>
305 </p:Customer>
306 </content>
307 <title>Atom-Powered Robots Run Amok</title>
308 <link href="http://example.org/2003/12/13/atom03"/>
309 <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
310 <updated>2003-12-13T18:30:02Z</updated>
311 <summary>Some text.</summary>
312 </entry>
313 <entry>
314 <content>
315 <content type="text/json">
316 {"firstName"="John","lastName"="Doe","id"="10"}
317 </content>
318 <type>text/json</type>
319 </content>
320 <title>Atom-Powered Robots Run Amok</title>
321 <link href="http://example.org/2003/12/13/atom03"/>
322 <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
323 <updated>2003-12-13T18:30:02Z</updated>
324 <summary>Some text.</summary>
325 </entry>
326
327 </feed>
You would need to provide an XML schema that would correspond to the Customer shown previously. This customer is an inline content entry.
You would also need to provide an XML schema corresponding to the JSON data shown previously. This JSON data is also an inline content entry.
You would then configure the data handler:
- mimeType="text/xml" and data handler = "XMLDataHandlerConfig"
- mimeType="text/json" and data handler = "JSONDataHandlerConfig".
Outbound data
For outbound data, the Atom data handler converts a well-defined business object into an Atom feed. If the feed business object contains an inline content business object, then, depending on the configuration of the data handler, it will call the configured data handler to convert the business object in the content to the inline content entry in the feed. You must provide a schema for the business object corresponding to this inline content.
Consider the following example. There are two business objects corresponding to the content entry. One of the business objects is Customer and the business object is Order. The Customer business object has to be serialized into XML in the Atom feed and the Order has to be serialized as a delimited stream in the Atom feed.
The Customer business object:

The serialized XML for it:
<entry>
<content type="text/xml">
<p:Customer xmlns:p="http://www.ibm.com/crm"
xmlns="http://www.ibm.com/crm">
<id>10</id>
<firstName>John</firstName>
<lastName>Doe</lastName>
</p:Customer>
</content>
</entry>
The Order business object:
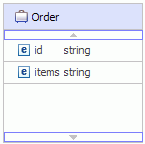
The serialized delimited stream for it:
<entry> <content type="text/delimited"> 10,Television
The output data would be as follows:
328 <?xml version="1.0" encoding="utf-8"?> 329 <feed xmlns="http://www.w3.org/2005/Atom"> 330 331 <title>Example Feed</title> 332 <subtitle>A subtitle.</subtitle> 333 <link href="http://example.org/feed/" rel="self"/> 334 <link href="http://example.org/"/> 335 <updated>2003-12-13T18:30:02Z</updated> 336 <author> 337 <name>John Doe</name> 338 <email>johndoe@example.com</email> 339 </author> 340 <id>urn:uuid:60a76c80-d399-11d9-b91C-0003939e0af6</id> 341 <entry> 342 <content type="text/xml"> 343 <p:Customer xmlns:p="http://www.ibm.com/crm" 344 xmlns="http://www.ibm.com/crm"> 345 <id>10</id> 346 <firstName>John</firstName> 347 <lastName>Doe</lastName> 348 </p:Customer> 349 </content> 350 <title>Atom-Powered Robots Run Amok</title> 351 <link href="http://example.org/2003/12/13/atom03"/> 352 <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> 353 <updated>2003-12-13T18:30:02Z</updated> 354 <summary>Some text.</summary> 355 </entry> 356 <entry> 357 <content type="text/delimited"> 358 10,Television 359 </content> 360 <title>Atom-Powered Robots Run Amok</title> 361 <link href="http://example.org/2003/12/13/atom03"/> 362 <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> 363 <updated>2003-12-13T18:30:02Z</updated> 364 <summary>Some text.</summary> 365 </entry> 366 <entry> 367 <title>Atom-Powered Robots Run Amok</title> 368 <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> 369 <updated>2003-12-13T18:30:02Z</updated> 370 <summary>Some text.</summary> 371 </entry> 372 </feed>
- Atom feed format properties The properties of the Atom feed format are described.
- Interface for Atom feed format The interface and business objects to support the Atom feed format are discussed.
Related reference:
JavaScript Object Notation (JSON) format
Atom feed format properties
The properties of the Atom feed format are described.
You can set properties for the Atom feed data handler on the Data Handler Properties page.
The following properties can be configured on the Atom feed data handler.
| Property name | Explanation | Possible values | Default value |
|---|---|---|---|
| Encode | This is the encoding that will be used in converting bytes to string and string to bytes wherever applicable. | Enum | All encodings |
| Mime Type | This is the mime type of the incoming content. In the case of Atom, this corresponds to the field in content called "type". | None | None |
| Data handler binding | This is the configuration corresponding to a data handler that will be used to transform content in the given mime type. | None | None |
Handling nulls and absence of tags
If a certain tag is not present in the Atom feed, then we consider this as unset in the business object. Conversely, if a certain property in the business object is unset, then the corresponding element does not appear in the Atom feed.
Interface for Atom feed format
The interface and business objects to support the Atom feed format are discussed.
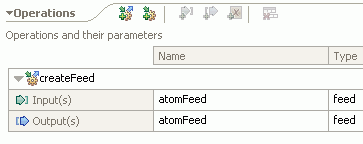
In order to parse and serialize Atom feeds to a business object in a module, the interface on the export or import should be defined with an Atom feed business object, which looks as follows:

This business object can be added to a module by opening the Predefined Resources in the Dependencies of the module and selecting ATOM schemas from the list. This selection will add the required Atom-specific business objects to the module under the Data folder. When creating the interface, select the feed business object that was added in the previous step. A sample interface looks as follows:
Delimited format
The delimited format used with a CSV file is discussed.
This format typically stores tabular data. It uses comma
to separate the fields of data. The last field ends with a new line character. In the case where the comma is part of the field, the field is surrounded by double quotation marks. If there are double quotation marks or new line characters in the field, then the double quote is followed by another double quote and the entire property value is put in double quotation marks. This data handler follows the  RFC4180
specification and Microsoft Excel
CSV format. The CSV data may contain a header line.
RFC4180
specification and Microsoft Excel
CSV format. The CSV data may contain a header line.
The following rules apply when using the delimited CSV format.
- The header is optional.
- The header is always on the first line and takes up only one line.
- The order of the fields in the file is the same as the order of the properties in the business object irrespective of the header.
- The file may contain multiple records. In this case, it will be read into a business object that contains one property which is an array. The multiple records will be read in the array.
CSV file with no header and one record
This is a CSV file with one record and it does not contain a header. In this case, the business object properties have to be in the order of the fields in the data.
- 8A7111,John,Doe,80000
The corresponding business object for the record is as follows. Note the business object property names are in order of the data in the file. Note the lastName and firstName fields.
| CustomerBO | |
|---|---|
id firstName lastName salary |
8A7111 John Doe 80000 |
CSV file with header and one record
This is a CSV file with one record and a header.
id,firstName,lastName,salary 8A7111,John,Doe,80000
The corresponding business object for the first record is as follows. The rest of the records will be similar. Note the business object property names are exactly the same as the header and their order is the same.
| CustomerBO | |
|---|---|
id firstName lastName salary |
8A7111 John Doe 80000 |
CSV file with multiple records and header
This is a CSV file with multiple records and also a header. This file will be read into a business object that contains a single property which is an array. This array will be populated with the records from the incoming data.
id,firstName,lastName,salary 8A7111,John,Doe,80000 8A7112,Mary,Cay,100000 8A7113,Tom,Howard,600000 8A7114,Liz,Taylor,700000
The corresponding business object for this file is as follows:
| CustomerBO | |
|---|---|
| customers[] | |
id firstName lastName salary |
8A7111 John Doe 80000 |
id firstName lastName salary |
8A7112 Mary Cay 100000 |
id firstName lastName salary |
8A7113 Tom Howard 600000 |
id firstName lastName salary |
8A7114 Liz Taylor 700000 |
- Delimited format with hierarchical business objects The hierarchical business objects in a delimited format are described.
- Delimited format properties Properties of the delimited format are described.
Related reference:
JavaScript Object Notation (JSON) format
Delimited format with hierarchical business objects
The hierarchical business objects in a delimited format are described.
Single cardinality
This is a CSV file that contains customer record with an address in it.
- 8A7111,John,Doe,577 Airport Blvd,Burlingame,CA,94010,80000
The corresponding business object for the record is as follows. Note, the business object property names are in order of the data in the file. This is a requirement if the business object is not a flat business object.
| CustomerBO | |
|---|---|
id firstName lastName |
8A7111 John Doe |
address street 577 Airport Blvd city Burlingame state CA zip 94010 | |
|
|
Multiple cardinality contained business object
This scenario is supported only with the caveat the maxOccurs property is not unbounded and the maxOccurs number of elements are present in the stream.
Property value is not set
If a property is unset, then there are two consecutive delimiters.
- 8A7111,,Doe,80000
Property value contains a comma
If the property contains a comma in it, then it is put in double quotation marks.
- 8A7111,John,Doe,"80,000"
Property value contains a double quote
If the property contains a double quote in it, then the double quote is followed by another double quote and the entire property is put in double quotation marks.
- 8A7111,"John-""Junior""",Doe,80000
Delimited format properties
Properties of the delimited format are described.
The following properties can be configured on the Delimited data binding. The default values for the properties are setup for a CSV format.
| Property name | Explanation | Type | Possible values | Default value |
|---|---|---|---|---|
| Header line | This indicates if there is a header in the incoming data or if a header has to be created in the outgoing data. | Enum | True False | False |
| Delimiter | This is the delimiter between any 2 fields of data. If the field of data is not set, then there will be 2 consecutive delimiters. \t is a valid delimiter for TAB. \r, \n is not a valid delimiter since it indicates the default end of record. Unicode values are allowed. | String | Any string | Comma is the default value |
| Encode | This is the encoding that will be used in converting bytes to string and string to bytes wherever applicable. | Enum | All encodings | UTF-8 |
| Text qualifier | If the delimiter appears as part of the field, then the field is enclosed in the text qualifier. | Enum | Double quotation marks ("), Single quote ('), None | Double quotation marks (") |
| Escape character | This is the character that will be used to escape the delimiter when the delimiter appears as part of the field. If the escape character is part of the field, then it is escaped with another escape character. The escape character is applicable only when the Text qualifier property is set to none. Unicode values are allowed. | character | Any character | Not set |
| Record delimiter | This indicates what the separator is between the records. Unicode values can be specified as well. For example:. \u00FF | String | EOL or type your own | EOL (\r, \r\n, \n) |
| Value of null | This property indicates what value should be written out for null and what value should be treated as null when reading data in. | String | Null or type your own | Null |
Fixed width format
The fixed width format is discussed.
This format has data where every field has a fixed width and for those fields where their width is less than the value, it is padded with pad characters. Every record ends with a new line character. The field width and pad character are both user configurable. This format may optionally contain a header at the top which corresponds to the properties of the business object. If the header is absent, then the order of the fields in the input data is the same as the order of properties in the business object. Typically, fixed width format contains data where every field has a different width. To enable this, the field width will be represented as a list property.
Fixedwidth format may be transmitted in several forms. Fixed width format may come in a stream through data bindings such as HTTP, JMS and MQ as well as files.
Fixed width format with no header and one record
This is a fixed width format with one record and does not contain a header. In this case, the business object properties have to be in the order of the fields in the data.
- 8A7111John~~~~~~Doe~~~~~~~80000~
The corresponding business object for the record is as follows. Note the business object property names are in order of the data in the fixedwidth format. Note the lastName and firstName fields.
| CustomerBO | |
|---|---|
id firstName lastName salary |
8A7111 John Doe 80000 |
Fixed width format with header and one record
This is a fixed width format with one record and a header. The field width format id is 6, firstName and lastName are 10 and salary is 6 as well.
id~~~~firstName~lastName~~salary 8A7111John~~~~~~Doe~~~~~~~80000~
The corresponding business object is as follows. Note the business object property names are exactly the same as the header and their order is also the same.
| CustomerBO | |
|---|---|
id firstName lastName salary |
8A7111 John Doe 80000 |
Fixed width format with multiple records and header
This is a fixed width format with multiple records and also a header.
id~~~~firstName~lastName~~salary 8A7111John~~~~~~Doe~~~~~~~80000~ 8A7112Mary~~~~~~Cay~~~~~~~100000 8A7113Tom~~~~~~~Howard~~~~600000 8A7114Liz~~~~~~~Taylor~~~~700000
The corresponding business object for this fixed width format is as follows:
| CustomerWrapperBO | |
|---|---|
| customers[] | |
id firstName lastName salary |
8A7111 John Doe 80000 |
id firstName lastName salary |
8A7112 Mary Cay 100000 |
id firstName lastName salary |
8A7113 Tom Howard 600000 |
id firstName lastName salary |
8A7114 Liz Taylor 700000 |
In this case, the export interface is set up with the CustomerWrapperBO as the business object not customers[ ].
- Fixed width format cardinality and properties Cardinality and properties of the fixed width format are described.
Related reference:
JavaScript Object Notation (JSON) format
Fixed width format cardinality and properties
Cardinality and properties of the fixed width format are described.
Single cardinality
This is a fixed width format that contains a customer record with an address in it.
- 8A7111John~~~~~~Doe~~~~~~~577 Airport Blvd~~~~BurlingameCA~~~94010180000~
The corresponding business object for the record is as follows. Note the business object property names are in order of the data in the fixedwidth format. This is a requirement if the business object is not a flat business object.
| CustomerBO | |
|---|---|
id firstName lastName |
8A7111 John Doe |
address street 577 Airport Blvd city Burlingame state CA zip 94010 | |
|
|
Multiple cardinality contained business object
This scenario is supported only with the caveat the maxOccurs property is not unbounded and the maxOccurs property's number of elements are present in the stream.
Property value is not set
If a property is unset, pad characters equal to the field width are added.
- 8A7111~~~~~~~~~~Cay~~~~~~~100000
Property value is empty
This occurs in the case of writing out fixed width data. If a property is empty (""), pad characters equal to the field width are added.
- 8A7111~~~~~~~~~~Cay~~~~~~~100000
Configurable properties
The following properties can be configured on the Fixed Width data binding or fixed width data handler.
| Property name | Explanation | Type | Possible values | Default value |
|---|---|---|---|---|
| Header line | This indicates if there is a header in the incoming data or if a header has to be created in the outgoing data. | Enum | True or false | False |
| Fixed width | This is a list which contains the width of every property value in the stream in the order that it appears in the stream. | List | None | |
| Pad character for non-numeric types | If the property value size is less than the field width then the pad characters are added to it so the size is equal to the field width. \u is the pad character for Unicode characters. This property is applicable for non-numeric types in the data like string, boolean, date and so on. | Character | An empty character such as " " or type your own | An empty character such as " " |
| Pad character for numeric types | If the property value size is less than the field width then the pad characters are added to it so the size is equals to the field width. \u is the pad character for Unicode characters. This property is applicable for numeric types like int, float, double, long and so on. | Character | An empty character such as " " or type your own | An empty character such as " " |
| Alignment for non-numeric types | This indicates whether the padding is left, right or both left and right. This alignment is for non-numeric types | Enum | LEFT_ALIGNMENT, RIGHT_ALIGNMENT, BOTH_ALIGNMENT | RIGHT_ALIGNMENT |
| Alignment for numeric types | This indicates whether the padding is left, right or both left and right. This alignment is applicable for numeric types | Enum | LEFT_ALIGNMENT, RIGHT_ALIGNMENT, BOTH_ALIGNMENT | RIGHT_ALIGNMENT |
| Truncation | When writing the values out, if the field width is less than the property value, then a true value indicates the value should be truncated and a false value indicates that an exception should be thrown. | boolean | True or False | True |
| Encode | This is the encoding that will be used in converting bytes to string and string to bytes wherever applicable. | Enum | All encodings | UTF-8 |
| Record delimiter type | This can be based either on a delimiter or size of record. | Enum | By delimiter or by size | By delimiter |
| End of line delimiter | This indicates what the separator is between the records. | String | EOL or type your own | End of line (either /n or /r/n or /r) |
| Value of null | This property indicates what value should be written out for null and what value should be treated as null when reading data in. | String | NULL or type your own | NULL |
JavaScript Object Notation (JSON) format
The JavaScript Object Notation (JSON) format is discussed.
JavaScript Object Notation
(JSON) is a lightweight data-interchange format. JSON is easy for humans to read and write. JSON is easy for machines to parse and generate.
JSON is based on a subset of the JavaScript Programming
Language, Standard ECMA-262 3rd Edition - December 1999. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java™, JavaScript,
Perl, Python, and many others. These properties make JSON an ideal
data-interchange language. More details on the JSON format can be found at Introducing
JSON.
The property name in the JSON data should match exactly with the property name in the business object.
Single cardinality contained business object
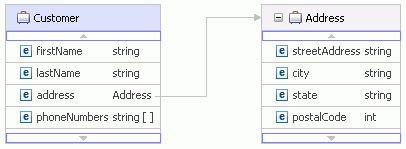
Given the following business object:
And given the following values for the business object properties:
| Business Object | Property | Value |
|---|---|---|
Customer Address |
firstName lastName streetAddress city state postalCode phoneNumbers[0] phoneNumbers[1] |
John Smith 21 2nd Street New York NY 10121 212-732-1234 646-123-4567 |
The JSON format is the following:
1 {
2 "firstName": "John",
3 "lastName": "Smith",
4 "address": {
5 "streetAddress": "21 2nd Street",
6 "city": "New York",
7 "state": "NY",
8 "postalCode": 10021
9 },
10 "phoneNumbers": [
11 "212-732-1234",
12 "646-123-4567"
13 ]
14 }
Multiple cardinality contained business object
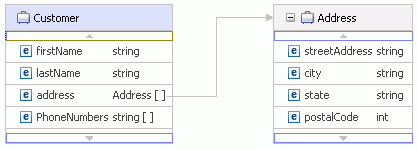
Given the following business object:
And given the following values for the business object properties:
| Business Object | Property | Value |
|---|---|---|
Customer Address[0] Address[1] |
firstName lastName streetAddress city state postalCode streetAddress city state postalCode phoneNumbers[0] phoneNumbers[1] |
John Smith 21 2nd Street New York NY 10121 577 Airport Blvd Burlingame CA 94010 212-732-1234 646-123-4567 |
The JSON format is the following:
15 {
16 "firstName": "John",
17 "lastName": "Smith",
18 "address": [{
19 "streetAddress": "21 2nd Street",
20 "city": "New York",
21 "state": "NY",
22 "postalCode": 10021
23 },{
24 "streetAddress": "577 Airport Blvd",
25 "city": "Burlingame",
26 "state": "CA",
27 "postalCode": 94010
28 }],
29 "phoneNumbers": [
30 "212-732-1234",
31 "646-123-4567"
32 ]
33 }
- JSON format properties and data type conversions Properties and data type conversions of the JSON format are described.
- Handling JSON null and empty arrays and objects Handling null and empty arrays and objects used in JSON data is described.
Related reference:
JSON format properties and data type conversions
Properties and data type conversions of the JSON format are described.
Configurable properties
The following properties can be configured.
| Property name | Explanation | Possible values | Default value |
|---|---|---|---|
| Encode | This is the encoding that will be used in converting bytes to string and string to bytes wherever applicable. | Enum | All encodings |
Data type conversions
JSON type system is more constrained than the XSD type system. JSON supports a value of type String, Number and Boolean. It does not support octal and hexdecimal values. The data handler will delegate all type conversions to the business object. Hence, all conversions that are supported by the business object will be supported by the data handler. We recommend the type should match between the JSON data and the corresponding data objects but we are tolerant with certain formats as shown in the tables below.
JSON to DataObject conversions
| JSON/DataObject | String | Long | Double | boolean | Date, datetime |
|---|---|---|---|---|---|
| String | Valid | Valid if value is long | Valid if value is double | Valid if value is true or false | Valid if the value is a date |
| Long | Valid | Valid | Valid | Invalid | Valid if the value is a date |
| Double | Valid | Valid if value is long | Valid | Invalid | Invalid |
| Boolean | Valid | Invalid | Invalid | Valid | Invalid |
For simple type lists, the types between the JSON data and the schema have to match.
For the base64Binary and hexBinary types, the business object will be converted to byte[], however this is not a JSON data supported type. JSONDataHandler will automatically convert the byte[] to a string based on the encoding information configured on the JSON format properties.
DataObject to JSON conversions
| DataObject | JSON |
|---|---|
| String | String |
| Long | Long |
| Integer | Long |
| Double | Double |
| Float | Double |
| Boolean | Boolean |
| Date | String |
| Datetime | String |
Handling JSON null and empty arrays and objects
Handling null and empty arrays and objects used in JSON data is described.
JSON data has the concept of null and empty arrays and objects. This section explains how each of these concepts is mapped to the data object concepts of null and unset.
Null values
JSON has a special value called null which can be set on any type of data including arrays, objects, number and boolean types.
34 { Schema types 35 "id":null, (integer)
36 "firstName": null, (string)
37 "address": null, (Address complex type with maxOccurs = 1)
38 "homeAddresses":null (Address complex type with maxOccurs > 1)
39 "phoneNumbers": null (string with maxOccurs > 1)
40 }
Considering the previous example where JSON data with a null value is parsed into a data object, the following is true:
- id - If the property is defined as nillable in the schema, then it will be set to null. If the property is not defined as nillable, it will throw an exception.
- firstName - The null value is set on the property.
- address - If the property is defined as nillable in the schema, then it will be set to null. If the property is not defined as nillable, it will throw an exception.
- homeAddresses - Schema does not allow nillable for this property hence it will be unset.
- phoneNumbers - This property has to be defined as nillable in the schema or else it will throw an exception.
When serializing to JSON, if a value of a property in the data object is null, then it will be serialized as a JSON null.
Unset property
Non-existence of a property from the JSON data maps to an unset attribute in the data object space. If the property in the data object is not set (unset), then the property will not appear in the JSON data.
Empty property
The JSON empty concept applies for arrays and objects as shown below.
41 {
42 "address":{}
43 "homeAddresses":[]
44 "phoneNumbers":[]
45 }
In the case of address, an empty address data object is created. Data object does not have a concept of empty lists. Hence, no action is taken on the data object for those two properties.
SOAP data handler
The SOAP data handler parses and serializes both SOAP messages and the header, as well as the SOAP fault details.
Export behavior
The SOAP data handler looks at the binding context to determine if this message is a normal response or a fault. If a normal response, it converts the data object to XML and adds it to the SOAP body. If a fault, it creates a SOAP fault, converts the data object to XML and adds it to the SOAP details. It gets the fault name from the binding context and adds a custom SOAP header as follows:
<ibmSoap:BusinessFaultName xmlns:ibmSoap="http://www.ibm.com/soap">CustomerAlreadyExists</ibmSoap:BusinessFaultName>where CustomerAlreadyExists is the fault name.
If the SOAP data handler is called for a service runtime exception (SRE), then the SOAP data handler creates a custom SOAP header as follows: <ibmSoap:RuntimeFault xmlns:ibmSoap="http://www.ibm.com/soap"/>, create the SOAP fault, set the status code to "Server" and set the fault string from the message of the ServiceRuntimeException.
Import behavior
The SOAP data handler converts the InputStream or Reader to a data object in the case of a normal response and service business exception. In the case of a service runtime exception (SRE), it reads the fault string from the SOAP fault, creates a ServiceRuntimeException and sets the fault string as the message of the ServiceRuntimeException
Limitations
The following limitations apply to the SOAP data handler currently:
- The SOAP 1.2 message format is not supported.
- Multiple-part messages are not supported.
Related reference:
JavaScript Object Notation (JSON) format
WTX data handler
The WTX data handler invokes the Websphere Transformation Extender to perform transformations from formats like Electronic Data Interchange (EDI) and many others to data object and vice versa. WebSphere Transformation Extender is a separately licensed product and is not included as part of IBM Integration Designer, IBM Business Process Manager or WebSphere Enterprise Service Bus. The product has to be installed with the WTX installer for these servers.
The WTX data handler can be used in JMS, generic JMS, MQ-JMS, MQ and HTTP exports and imports.
The WTX map selection data handler can be used in an EIS context for FlatFile, FTP and Email imports and exports.
WTX is used in a disconnected pattern. It does not connect to the client (JMS queues, for example) directly to get the incoming message or send the outgoing message. The incoming message is sent to an export/import which then hands off the data to the WTX data handler which converts the data by calling WTX and then hands it back to the export/import.
- WTX data handler concepts Several WTX concepts should be known to you.
- Designing the WTX map and related artifacts Understanding the relationship between the complex type and its corresponding element is important.
- Configure the WTX map selection data handler Configuring the WTX map selection data handler with the binding configuration resource wizard is shown.
- Configure the WTX map selection data handler properties The properties for the WTX map selection data handler need to be set.
- Deploy the WTX map Deploying the WTX map requires an understanding of the WTX directory in the module.
WTX data handler concepts
Several WTX concepts should be known to you.
WTX data handler and IBM Integration Designer servers
The WTX data handler communicates with Websphere Transformation Extender over JNI since Websphere Transformation Extender is a C++ product. As a result, the WTX data handler runs in the same process space as Websphere BPM or WebSphere Enterprise Service Bus.
WTX maps
The WebSphere Transformation Extender Data Binding invokes a WebSphere Transformation Extender map in order to perform the transformation. The map provides the system with the details of conversion from one format to another. The WTX data handler determines what map to call based on the configuration properties on the data binding or the data binding descriptor which is described in the runtime documentation. When converting native data like Electronic Data Interchange (EDI), for example, to data object, the map must be built with the input card from EDI and the output card based on XML Schema. When converting data object to native data, the map must be built with the input card based on XML Schema and output card based on native data.
Designing the WTX map and related artifacts
Understanding the relationship between the complex type and its corresponding element is important.
When defining the business object, the complex type definition needs to have a corresponding element. Without an element, WTX creates an XML structure which does not contain a document root. This XML is not valid and not deserializable by the WTXDataBinding. Hence, when creating a business object, a corresponding element definition needs to be created. Create the element based on the guidelines as follows:
- The element name has to be the same as the business object name
- The element namespace is the business object namespace + "wtx"
- List the target namespace and a prefix for the element namespace in the schema.
For the given complex type, Customer.xsd, as follows:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" 3 targetNamespace="http://www.ibm.com/crm" 4 xmlns:bons="http://www.ibm.com/crm"> 5 <xsd:complexType name="Customer"> 6 <xsd:sequence> 7 <xsd:element minOccurs="0" name="id" type="xsd:string"/> 8 <xsd:element minOccurs="0" name="firstName" type="xsd:string"/> 9 <xsd:element minOccurs="0" name="lastName" type="xsd:string"/> 10 </xsd:sequence> 11 </xsd:complexType> 12 </xsd:schema>
The element is CustomerElement.xsd, as follows:
13 <?xml version="1.0" encoding="UTF-8"?> 14 <schema xmlns="http://www.w3.org/2001/XMLSchema" 15 xmlns:bons="http://www.ibm.com/crm" 16 targetNamespace="http://www.ibm.com/crm/wtx" 17 elementFormDefault="qualified" 18 xmlns:p="http://www.ibm.com/crm/wtx" > 19 20 <import namespace="http://www.ibm.com/crm" schemaLocation="Customer.xsd"/> 21 <element name="Customer" type="bons:Customer"/> 22 </schema>
When creating the maps in the WTX map designer, check that you create the default extension for that platform. The WTX data binding determines the map extension based on the defaults.
Configure the WTX map selection data handler
Configure the WTX map selection data handler with the binding configuration resource wizard is shown.
To configure the WTX map selection data handler, follow these steps:
- Right-click the module and from the menu select New > Binding Resource Configuration. The Binding Resource Configuration window opens. Select Data transformation and click Next.
- In the Select data format transformation page, select Handled
by WTX and click Next.
- Enter the content type. For example, delimited. At run time, the map names will be constructed from the BusinessObject used when calling the map and the content type you entered during this configuration. If you are only mapping a one-way interaction from XML to a native data format then you do not need to create a NativeToXML map. Click Next.
- In the final page optionally create your own name for the configuration and add a folder. Click Finish and a configuration for this data handler is created. Now create a configuration for the custom data binding where this data handler is being used. At a minimum the custom data binding needs to have a property to chain this data handler configuration. When specifying the data handler property for the custom data binding, select the configuration you created.
- In your export or import, select the custom data binding configuration.
To write your own WTX MapSelectionDataHandler, the source data type, target class and options for an import and export are as follows:
Import
- Source: DataObject
- Target: byte[].class
- Options: A HashMap with a key "WTXMapName" and a value equal to the WTX map name to be called. For example:
- map.put("WTXMapName", "WTX\CustomerDelimited.mmc");
Export
- Source: byte[]
- Target: DataObject.class
- Options: A HashMap with a key "WTXMapName" and a value equal to the WTX map name to be called. For example:
- map.put("WTXMapName", "WTX\CustomerDelimited.mmc");
Configure the WTX map selection data handler properties
The properties for the WTX map selection data handler need to be set.
This table lists the properties that can be configured on the WTX map selection data handler you created previously when you made the predefined WTX Map Selection Data Handler selection. These properties are used in conjunction to determine the WTX map name invoked at run time. This allows the client and server implementation to be loosely coupled and highly reusable.
| Property name | Explanation | Default value | Explanation of default value |
|---|---|---|---|
| BusinessObject | This is the data type of the incoming data such as Customer, Order and so on. The value of this property is used in the regular expression defined by XMLToNative Map Name and NativeToXML Map Name properties to derive the map name. | Implicit | Implicit as the default value implies the value of this property is the parameter type on the operation. For example: operation = create(Customer customerBO) then the value is Customer. This enables the user to specify the data binding at only one level on the export/import instead of on every operation. |
| ContentType | This is the content type of the incoming data. For example, EDI, SWIFT, HL7 and so on.. The value of this property is used in the regular expression defined by properties XMLToNative Map Name and NativeToXML Map Name to derive the map name. | None | |
| XMLToNative Map Name | This property is the qualified map name for the map that converts data object to native data. The value of this property is a regular expression that is constructed with the properties BusinessObject and ContentType. The map directory is with respect to the SCA module. This value can also be hard coded to a map namealthough it is not recommended. | WTX/$(BusinessObject)XMLTo$(ContentType) | WTX is the default directory. If the BusinessObject = "Customer" and ContentType = "EDI", the map name would be WTX/CustomerXMLToEDI |
| NativeToXML Map Name | This property is the qualified map name for the map that converts native data to data object. The value of this property is a regular expression that is constructed with the properties BusinessObject and ContentType. The map directory is with respect to the SCA module. This value can also be hard coded to a map namealthough it is not recommended. | WTX/$(BusinessObject)$(ContentType)ToXML | WTX is the default directory. If the BusinessObject = "Customer" and ContentType = "EDI", the map name would be WTX/CustomerEDIToXML |
To have the choice of map to be a runtime decision, then you must instead configure the data binding descriptor as described in the runtime documentation.
Deploy the WTX map
Deploy the WTX map requires an understanding of the WTX directory in the module.
The WTX map is deployed with the application module that uses the WTX data binding. The default location to add the map is in a directory called WTX located at the top level in the module.

This location can be overridden by setting the XMLToNative Map Name and NativeToXML Map Name properties in the resource configuration of the WTX data binding.
Create a custom data handler
A custom data handler is useful when the data formats requiring transformation are unique and the prepackaged data handlers are not sufficient for your needs.
Occasionally the prepackaged data handlers will not meet your special requirements. In this case, you can develop your own data handler using custom code. This sample shows you how to implement a custom data handler.
The following list shows you what you can and cannot do with a custom data handler:
- You can create a custom data handler by implementing an interface of the DataHandler class.
- You can create a custom data handler by invoking an existing data handler and adding extended transformation logic.
- You cannot create a custom data handler by extending an existing data handler.
As an example of a custom data handler, the following code handles undefined elements in the input XML. The prepackaged XML data handler would not be able to convert these undefined elements from the input into a business object. The sample code snippet removes the undefined elements from the input and then invokes the prepackaged XML data handler to complete the transformation.
package com.ibm.websphere.example;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.Reader;
import java.util.Map;
import com.ibm.wbiserver.datahandler.xml.*;
import commonj.connector.runtime.DataHandler;
import commonj.connector.runtime.DataHandlerException;
public class CustomDHExample implements DataHandler {
XMLDataHandler xmlDH = new XMLDataHandler();
@Override
public Object transform(Object source, Class arg1, Object arg2)
throws DataHandlerException {
// TODO Auto-generated method stub
/*
* Set the buffer size for the input */
int bufferSize = 2000 * 4;
String inputStr = null;
if (source instanceof InputStream) {
InputStream is = (InputStream)source;
try {
byte[] inputs = new byte[is.available()];
is.read(inputs);
inputStr = new String(inputs);
is.reset();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} else if (source instanceof byte[]) {
inputStr = new String((byte[])source);
} else if (source instanceof Reader) {
try {
char[] chbf = new char[bufferSize];
((Reader)source).read(chbf);
inputStr = new String(chbf);
((Reader)source).reset();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} else if (source instanceof String) {
inputStr = (String)source;
}
/*
* Do needed modification here for the input string. For example:
*/
if(inputStr != null && inputStr.indexOf("<role>")!=-1)
{
int start = inputStr.indexOf("<role>", 0);
int end = inputStr.indexOf("</role>",start)+7;
inputStr = inputStr.substring(0, start) + inputStr.substring(end);
/*
* load XML data handler to do the transform from inputStr to DataObject */
return xmlDH.transform(inputStr, arg1, arg2);
}
else {
Object returnedObject = xmlDH.transform(source, arg1, arg2);
return returnedObject;
}
}
@Override
public void transformInto(Object source, Object target, Object options)
throws DataHandlerException {
// TODO Auto-generated method stub
xmlDH.transformInto(source, target, options);
}
@Override
public void setBindingContext(Map context) {
// TODO Auto-generated method stub
xmlDH.setBindingContext(context);
}
}
Handling faults in bindings
A fault or error that occurs at run time needs to be handled in some way by an application.
You can configure your import and export bindings to handle faults ( business exceptions) that occur during processing. You can set up a fault handler at three levels: you can associate a fault handler with a fault, with an operation, or with a binding. For import bindings, you can also set up a fault selector to determine whether a response is a fault and, if so, the name of the fault.
A fault data handler processes fault data and transforms it into the correct format to be sent by the export or import binding. For an export binding, the fault data handler transforms the exception business object sent from the component to a response message that can be used by the client application. For an import binding, the fault data handler transforms the fault data or response message sent from a service into an exception business object that can be used by the SCA component. For import bindings, the fault data handler calls the fault selector, which determines the name of the fault.
You can specify a fault data handler for a particular fault, for an operation, and for a binding. If the fault data handler is set at all three levels, the data handler associated with a particular fault is called. No further fault processing occurs. If fault data handlers are set at the operation and binding levels, the data handler associated with the operation is called. No further fault processing occurs.
- Faults overview Errors issued at run time in a Service Oriented Architecture (SOA) application can either be from a Service Component Architecture (SCA) application to another non-SCA application or from a non-SCA application to the SCA one.
- Prepackaged fault components Some prepackaged fault components are provided for the bindings you work with.
- Developing a custom fault selector To develop your own custom fault selector, you must implement the FaultSelector interface, implement a method in the BindingContext interface and understand Service Message Object (SMO) headers.
Faults overview
Errors issued at run time in a Service Oriented Architecture (SOA) application can either be from a Service Component Architecture (SCA) application to another non-SCA application or from a non-SCA application to the SCA one.
The following sections provide an overview of how faults can be handled by your application, beginning with the types of faults.
- Business faults
- Runtime exceptions
- Fault handling on imports and exports
- Data format considerations
- Wizard for configuring faults
- Fault selectors
- Fault data handlers
Business faults
Business faults are business errors or exceptions that occur during processing. Consider the following interface which has a createCustomer operation on it. This operation has two business faults defined on it: CustomerAlreadyExists and MissingCustomerId.
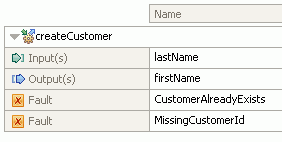
In this example, if the client sends a request to create a customer to this SCA application and that customer already exists, the component throws a CustomerAlreadyExists fault to the export. The export now needs to propagate this business fault back to the calling client.
This is achieved by the fault data handler that is setup on the export binding. When a business exception is received by the export binding, the binding calls the fault data handler with the data object from the service business exception.
- The binding calls the appropriate data handler with the data object.
- The fault data handler transforms the fault data object to a response message and returns it to the export binding.
- The export returns the response message to the client.
If the service business exception contains the name of the fault, then the data handler setup on the fault will be called. If the service business exception does not contain the name of the fault, then the fault name will be derived by matching the fault types.
Runtime exceptions
Runtime exceptions are classified as all the exceptions that occur in the SCA application due to processing of the request and do not correspond to a business fault. Runtime exceptions are not defined on the interface as business faults are. In certain scenarios, you may want to propagate these runtime exceptions to the client application so the client application can take the appropriate action.
For example, if a client sends a request to create a customer to the SCA application and an authorization error occurs during processing of this request, the component throws a runtime exception. This runtime exception has to be propagated back to the calling client so it can take the appropriate action regarding the authorization. This is achieved by the runtime exception data handler configured on the export binding. The processing of a runtime exception is similar to the processing of a business fault.
If a runtime exception data handler was set up, the following processing occurs:
- The export binding calls the appropriate data handler with the service runtime exception.
- The data handler transforms the fault data object to a response message and returns it to the export binding.
- The export returns the response message to the client.
Fault handling on imports and exports
To handle both business faults and runtime exceptions, you can set up fault handling on imports and exports. Handling faults on either imports or exports is optional. You would likely create fault handlers for the most common errors that could occur at run time in your application.
You can create fault handlers on imports and exports for the following bindings: JMS, MQ JMS, generic JMS, MQ and HTTP. You can also add them to your imports and exports created with EIS bindings for services using adapters, except for those services that use CICS and IMS adapters.
In the following diagram of an import, a fault occurs on the external service the import is calling. The numbers refer to the numbers in the diagram.
- The fault is transformed into the data format expected by the component either as a business fault or a runtime exception.
- The fault originally is passed as a native response message. This fault could be passed in to any JMS-type binding (JMS, MQ JMS and generic JMS), MQ or HTTP binding, or as an exception from an EIS system.
Returning a fault in the expected format is discussed in Data format considerations.

In the following diagram of an export, a business fault or a runtime exception occurs in the SCA environment. The numbers refer to the numbers in the diagram.
- The fault is passed back to the client by the export in a response message. The transport can be any JMS-type binding, an MQ binding or an HTTP binding. It is transformed into the native data format expected by the client.
- The fault originally occurs in the SCA environment resulting in either a business fault or a runtime exception.
Returning a fault in the expected format is discussed in Data format considerations.

You can create a fault handler for your import or export on three levels. You can associate a fault handler with a binding, with an operation or with a specific fault.
Data format considerations
As with transforming data formats on bindings, so to there must be a way of transforming data formats for a fault handler since a fault in one environment must be expressed in the data format of another as the result of a request-response operation. For example, suppose a fault is issued in a non-SCA environment as the result of a call made to an application in this environment by an import. The fault in that non-SCA environment might be returned as text in a response message to the import. The import, on receiving the text in a message, must transform this text to the expected XML format in the SCA environment.
When you create a fault handler you are required to also specify how the data will be transformed between the two environments. Specifying the data format transformation for fault handlers is similar to specifying the data format transformation for bindings.
Wizard for configuring faults
Faults are initially defined in the interface editor where you add faults to the operations on the interface. For example, in the screen capture that follows the getInventory operation has two faults, one to handle a timeout condition and one to handle a system failure.
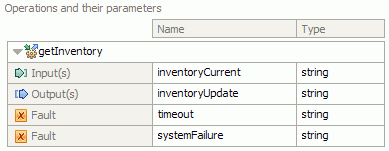
When you add a binding to and import or export, these faults are detected by the generate binding wizard.
Once you have generated a binding, you can find and modify the fault information in the properties view of the import or export. For example, in the following screen capture of a JMS binding on an import, the fault selector, fault data format and runtime exception data format are shown. Since implementing fault handling is optional, none of these elements have been implemented. If you wanted to add fault handling, you would begin by implementing the fault selector, the fault data format and, if you wanted to handle runtime exceptions, the runtime exception data format.

Fault selectors
For bindings on imports, you can configure a fault selector to determine whether a response is a fault and, if so, the name of the fault. The fault selector determines whether the import response is an actual response, a business exception, or a runtime fault. It also determines, from the response body or header, the native fault name.
The fault selector is called by a binding whenever the binding interacts with the native consumer ( a queue or an adapter) and receives a normal response or an exception (business or runtime) in the process.
The fault selector is optional. If you do not specify a fault selector, the binding calls the response data binding or data handler.
Fault data handlers
A fault data handler is nothing but a data handler. It has the same interface as a data handler.
The use of fault data handlers with respect to faults is similar to the use of data handlers with respect to bindings. Though IBM Integration Designer provides pre-packaged fault handlers, you may have a need to create your own type of fault handler for your particular application. A fault data handler transforms fault data into a data object that can be returned in a service business exception object. A fault data handler can be used by both import and export bindings.
You can specify a fault data handler for a binding, an operation or a particular fault.
- If the fault data handler is set at all three levels, the data handler associated with a particular fault is called. No further fault processing occurs.
- If fault data handlers are set at the operation and binding levels, the data handler associated with the operation is called. No further fault processing occurs.
You can configure a data handler to handle runtime exceptions that are received from external applications or send runtime exceptions that have occurred in your module to the external applications. If your module does not want to send or receive runtime exceptions to external applications or modules, then you should not define the data handler for runtime exceptions and leave it blank.
Prepackaged fault components
Some prepackaged fault components are provided for the bindings you work with.
The following list of bindings have a set of prepackaged fault components. Click the binding and it will open the appropriate list of fault components. This list is found in the information on each binding.
You may also create your own fault selector as a resource configuration. See Create a fault selector resource configuration.
- Header-based fault selector A header-based fault selector determines whether a response message is a business fault, a runtime exception or a normal message based on the headers in the incoming response message.
- SOAP fault selector The SOAP fault selector determines if the response SOAP message is a normal response, business fault or runtime exception.
Header-based fault selector
A header-based fault selector determines whether a response message is a business fault, a runtime exception or a normal message based on the headers in the incoming response message.
This fault selector can be used with JMS, MQ JMS, MQ, generic JMS and HTTP imports.
The section below explains the behavior of the header-based fault selector when default configuration is used.
Business faults
If an application wants to indicate the incoming message is a business fault, then there must be two headers in the incoming message for business faults, which is shown as follows:
- Header name = FaultType, Header value = Business Header name = FaultName, Header value = <user defined native fault name>
Runtime exceptions
If an application wants to indicate the incoming response message is a runtime exception, then there must be one header in the incoming message, which is shown as follows:
- Header name = FaultType, Header value = Runtime
Normal message
If an application wants to indicate the incoming message is a normal message, then none of these headers should be present in the incoming response message or the header value for FaultType should be something other than "Business" or "Runtime".
SOAP fault selector
The SOAP fault selector determines if the response SOAP message is a normal response, business fault or runtime exception.
Since SOAP has a first class representation of faults, the fault selector can easily determine if the response message is a normal message or a fault. There is no standard way to further classify the fault to a business fault or runtime fault hence the soap header is used to indicate whether the fault is business or runtime.
A business fault can be sent as part of the SOAP message with the following custom SOAP header. "CustomerAlreadyExists" is the name of the fault in this case.
- <ibmSoap:BusinessFaultName xmlns:ibmSoap="http://www.ibm.com/soap">CustomerAlreadyExists</ibmSoap:BusinessFaultName>
The data will be in the details part of the SOAP fault.
If the fault name returned in the business fault case does not match to any native faults on the operation, then the binding will throw this as a service runtime exception.
A runtime fault can be sent as part of the SOAP message with the following custom SOAP header <ibmSoap:RuntimeFault xmlns:ibmSoap="http://www.ibm.com/soap"/> and the data in the details part of the SOAP fault.
If no custom business or runtime fault header is present and the fault code has a "Server" in it, then it is considered a runtime exception.
If the SOAP body is a fault and there is no business fault or runtime exception header present, then it is considered a business fault.
This fault selector can be used with JMS, MQ JMS, MQ, generic JMS and HTTP imports.
Developing a custom fault selector
To develop your own custom fault selector, you must implement the FaultSelector interface, implement a method in the BindingContext interface and understand Service Message Object (SMO) headers.
Implementing the FaultSelector interface
The custom fault selector must implement the com.ibm.websphere.dhframework.faults.FaultSelector interface.
package com.ibm.websphere.dhframework.faults;
import commonj.connector.runtime.BindingContext;
/**
* A Fault Selector that determines if the input data is a business fault,
* runtime fault or a normal response. It also determines the native fault name.
*/
public interface FaultSelector
extends BindingContext
{
public static enum ResponseType {
RESPONSE, BUSINESS_FAULT, RUNTIME_EXCEPTION };
/**
* This method looks at the source object or headers from the context service to
* determine if the response is fault or not. If the source data is read from the * input stream or reader, then this method should put this read data in the binding
* context so it can be accessed by the data handler.
* @param source
* This can be of type InputStream, Reader or Java Object like an
* Exception Object or the serialized object in case of JMS ObjectMessage.
* @return Whether the response is a normal response, business fault or
* runtime exception.
*/
ResponseType getResponseType(Object source);
/**
* Gets the native fault name from the headers from the context service or from the * source object.
*
* @param source
* This can be either InputStream, Reader or Java Object like an
* Exception Object or the serialized object in case of JMS ObjectMessage.
* @return The native fault name.
*/
String getFaultName(Object source); }
The source data is shared between the fault selector and the data handler. If the fault selector has read the data from the input stream or reader, then the data handler will not be able to read this data again. The fault selector has to put the read data in the binding context so it can be used by the data handler.
Binding context interface
The binding context contains runtime contextual information passed from the caller to the data handler. The BindingContext interface specifies the runtime context of the data handler. The DataHandler interface extends from BindingContext interface. Therefore, each data handler implementation needs to implement the setBindingContext method of the BindingContext interface.
public void setBindingContext( Map context)
{
this.context = context;
}
The context is a Map. The key gives the name of the context information and the value passed gives its value. Refer to the BindingContext class for the information that bindings can provide in the context. The following table contains the list of some of the relevant information available in the context.
| Key | Value | Description of value |
|---|---|---|
| BindingContext.BINDING_COMMUNICATION | BindingContext.BINDING_COMMUNICATION_INBOUND BindingContext.BINDING_COMMUNICATION_OUTBOUND | Indicates if the native data is coming into the module or going out of the module. |
| BindingContext.BINDING_CONFIGURATION | Configuration properties of the Java™ code. | This Java code provided by the data handler implementation contains the values for the properties that are set at design time. This information is set by the BindingRegistry which instantiated the data handler.
See Access configuration properties for more details. |
| BindingContext.BINDING_INVOCATION | BindingContext.BINDING_INVOCATION_REQUEST BindingContext.BINDING_ INVOCATION_RESPONSE BindingContext.BINDING_ INVOCATION_FAULT | Indicates whether the invocation to the data handler is in the context of a request, response or fault. |
| BindingContext.BINDING_NAME | String | Name of the export or import |
| BindingContext.EXPECTED_TYPE | Qualified name (QName) of the business object. | The QName of the expected type of business object for native data to business object transformation. This information is set by the caller of the data handler.
See Obtain a business object type for more details. |
| BindingContext .BINDING_REGISTRY | Runtime implementation of the Binding registry. | The Binding registry maintains all the data handler, data binding and function selectors. This information is set by the BindingRegistry which instantiated the data handler.
See Binding registry and invoking other data handlers for more details. |
| WPSBindingContext.FAULT_NAME | String | Name of the business fault in case of export response |
| WPSBindingContext.TRANSFORMED_DATA | Object | This allows context data sharing between the function selector and data handler, and fault selector and data handler. If the data is already parsed or read by the function selector or fault selector then it can be stored in the context and passed onto the data handler so the data handler does not re-read it. |
- Service Message Object (SMO) headers Service Message Object headers provide protocol-specific and protocol-neutral headers to author data handlers.
- Example of a custom fault selector This code sample shows how you might develop a custom fault selector.
Example of a custom fault selector
This code sample shows how you might develop a custom fault selector.
In this incomplete code sample, a framework of code selects a fault from the payload in the body of a SOAP message. The sample finds the correct fault by examining details, which your implementation would provide (see faultName = "deduce from fault detail";).
package com.ibm.wbiserver.faults;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.Reader;
import java.util.Map;
import javax.xml.soap.Detail;
import javax.xml.soap.MessageFactory;
import javax.xml.soap.SOAPBody;
import javax.xml.soap.SOAPException;
import javax.xml.soap.SOAPFault;
import javax.xml.soap.SOAPMessage;
import com.ibm.websphere.dhframework.faults.FaultSelector;
import com.ibm.websphere.sca.bindingcore.WPSBindingContext;
/**
* This is only a sample. This is not IBM supported code as is.
*/
@SuppressWarnings("unchecked")
public class SOAPFaultDetailFaultSelectorSample implements FaultSelector {
private static final long serialVersionUID = 6799865355976712457L;
String faultName = null;
Map context = null;
public String getFaultName(Object source) {
return faultName;
}
public ResponseType getResponseType(Object source) {
ResponseType LocalResponseType = null;
InputStream inputStream = null;
if (source instanceof InputStream) {
inputStream = (InputStream) source;
} else {
try {
inputStream = convertReader((Reader) source, "UTF-8");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
MessageFactory factory;
try {
factory = MessageFactory.newInstance();
SOAPMessage msg = factory.createMessage(null, inputStream);
context.put(WPSBindingContext.TRANSFORMED_DATA, msg);
LocalResponseType = setResponseAndFault(msg);
} catch (SOAPException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return LocalResponseType;
}
public static InputStream convertReader(Reader source, String encoding)
throws IOException {
Reader sourceReader = (Reader) source;
char[] ch = new char[2];
StringBuffer buffer = new StringBuffer();
int len = sourceReader.read(ch);
while (len != -1) {
buffer.append(ch, 0, len);
len = sourceReader.read(ch);
}
String sourceString = buffer.toString();
byte[] sourceBytes = null;
if (encoding != null) {
sourceBytes = sourceString.getBytes(encoding);
} else {
sourceBytes = sourceString.getBytes();
}
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(
sourceBytes);
return byteArrayInputStream;
}
/**
*
*/
protected FaultSelector.ResponseType setResponseAndFault(SOAPMessage msg)
throws SOAPException {
ResponseType theResponse = null;
SOAPBody body = msg.getSOAPBody();
SOAPFault soapFault = body.getFault();
String faultCode = soapFault.getFaultCode();
Detail faultDetail = soapFault.getDetail();
// TODO not complete - look at faultDetail and set values if (ok) {
faultName = "deduce from fault detail";
theResponse = FaultSelector.ResponseType.BUSINESS_FAULT;
} else {
faultName = null;
theResponse = FaultSelector.ResponseType.RUNTIME_EXCEPTION;
}
return theResponse;
}
public void setBindingContext(Map context) {
this.context = context;
}
}
Resource configurations for imports and exports
Resource configurations can be used with imports and exports to provide reusable configurations for your services. In this section, you are shown how to create these resource configurations with the tools in IBM Integration Designer.
- Create a data format transformation resource configuration In order to invoke a data handler from a data format transformation, create a binding resource configuration for it. This example creates a binding resource configuration for a delimited data handler.
- Create a function selector resource configuration The configuration of a function selector, which determines which operation to call on an export interface, is discussed.
- Create a fault selector resource configuration The configuration of a fault selector, which can handle errors at run time, is discussed.
- Editing a binding resource configuration Binding resource configurations are listed in the Binding Resources folder of the Business Integration navigation and can be edited.
- Limitations of binding resource configurations A limitation of binding resource configurations is discussed.
Create a data format transformation resource configuration
In order to invoke a data handler from a data format transformation, create a binding resource configuration for it. This example creates a binding resource configuration for a delimited data handler.
To create the configuration, follow these steps:
- Right-click the module and from the menu select New > Configure Binding Resource. The Binding Resource Configuration window opens. On the Select a Configuration Type page, select Data transformation. Click Next.
- By default, the existing data format transformations, that is, the existing data format handlers, in the binding registry are shown. These prepackaged data handlers are described in Prepackaged data format handlers.
You may also select a custom data format transformation from your workspace on the class path. Note that only classes on the class path with a name following this pattern <class name>Properties are selectable.
Selecting Show the deprecated data format transformations adds previous transformations that have been deprecated.
In this example, we chose the Delimited data format. Click Next.
Note that if you chose another popular format, the SOAP data format, and clicked Next you would have the following selections on the next page.
- Propagate SOAP headers: Selecting this option propagates the SOAP header information at run time
- Construct the faultcode of SOAP Fault as QName format: Selecting this option means your faults will use the qualified name (QName) for a namespace; that is you intend to use the SOAP with Attachments API for Java (SAAJ) 1.3 standard. If you do not select this option, which is the default, then your faults will contain the unqualified name of a namespace; that is, you intend to use the SOAP with Attachments API for Java (SAAJ) 1.2 standard.
- Once you have selected your data format transformation,
the wizard allows you to proceed to the Data Transformation
Properties page where you can add or modify properties such as, in this case, the delimiter for the data.
The delimited format property fields are discussed in Delimited format properties. Other format property fields are discussed in Data handler formats.
- In the New Data Transformation Configuration page, you can change or create a new module for the data format transformation, add a folder to contain the generated files and name and describe your configuration. Click Finish and the data format transformation resource configuration is completed and shown in the editor.
- The data format handler configuration is completed and shown in the editor along with the bindings it can be used with. It also is listed in the navigation under Binding Resources.
If you had chosen a SOAP data format then you will see the options discussed earlier in the Properties view.
Create a function selector resource configuration
The configuration of a function selector, which determines which operation to call on an export interface, is discussed.
In this example, the module and the WebSphere Adapter for Flat Files had been previously set up. Creating a function selector resource configuration with the binding resource configuration wizard is shown.
- Right-click the module and from the menu select New > Binding Resource Configuration. The Binding Resource Configuration window opens. Select Function Selector and click Next.
- Select either an existing function selector or create your own custom function selector that is available in your workspace on the class path.
In the second case, the Function selector class name field lets you select a class from an existing collection of custom function selectors you have created previously. Note that only classes on the class path with a name following this pattern <class name>Properties are selectable.
Click Next.
- Once you have selected your function selector, the wizard allows you to proceed to the Function Selector Properties page, where you can add properties such as, in this case, the incoming text file with the customer data.
The properties you are configuring are rules on how to map from the name of a file to an object name. The rule is a regular expression for a file name. In the following example, if a file named Customer.txt is placed in the event directory, which is used by the WebSphere Adapter for Flat Files as the point where files are read, the function selector will map the file to an operation named emit<object name>, so emitCustomer. For the object name, you would specify the name of your input type. When you construct your input operation, you would select the input type. Click Next.
- In the final page you specify the name of your function selector and click Finish to generate it. The function selector resource configuration is completed and shown in the editor. The function selector is listed in the navigation under Binding Resources. In the editor, you can choose to expose this function selector resource configuration to other bindings beside a binding chosen by the wizard by selecting the binding in the Select bindings table.
Create a fault selector resource configuration
The configuration of a fault selector, which can handle errors at run time, is discussed.
In this example, the module for the fault selector had been previously set up. You can alternately create the module when you launch the Binding Resource Configuration wizard.
To create a fault selector resource configuration, follow these steps:
- Right-click the module and from the menu select New > Configure Binding Resource. The Binding Resource Configuration window opens. Select Fault Selector and click Next.
- In the Select fault selector page, select an existing fault selector or choose a custom fault selector from your workspace.
The Fault selector class name field lets you select a class from an existing list of fault selectors. The list is contextual; that is, depending on how you create your configuration, you may find a list of fault selectors that is supplied with BPM or you may not find a list at all. For example, if you had created an import with a JMS binding and then in the Faults Configuration section of the Properties view launched the Select button, you would find some existing fault selectors provided by the product because the product can determine the context for the fault selector.
To create your own fault selectors, you would read Developing a custom fault selector. Once you had created one or more fault selectors, you would add them to the product's fault selectors by adding them through the Binding Registry section of the Preferences page as discussed in Binding registry preferences page.
Note that only classes on the class path with a name following this pattern <class name>Properties are selectable.
Click Next.
- In the Fault Selector Properties page, add the properties. Since we selected the header-based fault selector, the names for the headers were required. Click Next.
- In the New Binding Resource Configuration page, enter a name for your fault and, optionally, a folder. Click Finish.
- The fault selector resource configuration is completed and shown in the editor. The fault selector is listed in the navigation under Binding Resources. In the editor, you can choose to expose this fault selector resource configuration to other bindings besides the bindings chosen by the wizard by selecting the binding in the Select bindings table.
Editing a binding resource configuration
Binding resource configurations are listed in the Binding Resources folder of the Business Integration navigation and can be edited.
To edit a binding resource configuration, follow these steps:
- Expand Binding Resources in the Business Integration navigation.
- Double-click the configuration you want to edit.
- Edit the Name and Namespace fields, to edit them.
- Use the Browse button to select a different class name for the Class name field.
- In the Select bindings field, change or add different bindings by selecting them.
You can configure your binding in the Properties view by selecting a data handler, if one or more have been created, or creating a new data handler.
Limitations of binding resource configurations
A limitation of binding resource configurations is discussed.
Class does not implement correct interface message
A message the class does not implement the correct interface may be issued after you create a resource configuration for a data binding, data handler or function selector. The messages you may see are as follows:
- Implementation class cannot be found: This message usually means that all of the required classes for the class are not on the classpath of the project the implementation class is contained in. For example, if the implementation comes as a binary format in a JAR file, compilation errors will not show up in the IDE, but the classes needed to load the implementation class cannot be found.
- The class does not implement the data binding, data handler or function selector interface: This message usually means the classpath for the tools and the classpath for the user project have the same JAR file or classes on the classpath, but they are from two physically different JAR files. For example, the module has the Process Server stub and the user project has the commonj.connector.jar explicitly on the classpath.
To resolve these errors, you must place your code in one of the following locations:
- Place your code in a Java EE utility project that has the same target runtime as the module targeted for the resource configuration. Set the utility project as a dependency on the module.
- Place your code in the same module targeted for the resource configuration.
If you have a JAR file containing your classes, you can create a utility project by following these steps:
- From the menu, select File > Import > General > File System. The Import window opens.
- In the From directory field, enter the JAR file location. In the Into folder field, enter the module location.
- Click Finish. A message asks to create a project and set it as a dependency on the module. Click Yes.
- A utility project is created with the correct classpath.
Alternately, if you are developing your classes in the IDE, you can either create your classes in the same module or create a Java EE utility project that specifies the same target runtime as the module. Then you should set the utility project as a dependency on the IBM Integration Designer module.
Configurations with non-configurable data bindings
In some cases, non-configurable data bindings may be used within the context of a configuration. In these cases, the normal sequence of pages in a wizard may differ.
Binding registry preferences page
The binding registry preferences page is a list of registered bindings available in IBM Integration Designer.
The following sections provide a comprehensive look at the binding registry:
- Binding registry overview
- Binding registry preference page overview
- Import and exporting user-specified entries
- Binding registry entry edit window
- Binding registry export window
- Binding registry import window
Binding registry overview
When working with a resource adapter, we need to capture the information required by the adapter to marshal the EIS-neutral data objects to the native objects used to interact with the Enterprise Information System (EIS). There are several artifacts involved with the process of data conversion, formatting, and generation. The data binding generator, for example, generates a data binding implementation that is responsible for marshalling a request business object to an EIS-internal data format; it is also responsible for unmarshalling a response from an EIS-internal data format into a business object. Generic, that is, non-generated data bindings are common too. A function selector converts an inbound message to the correct function on a target service.
A data binding and function selector object can use data handlers that provide data transformation functions from one form to another.
The binding registry component provides a global point of access to the repository for data binding, data binding generator, data handler and function selector objects information. When a particular binding is selected for a service component that is being created, the registry information is accessed and the right level of the binding information is provided to the user.
Binding registry preference page overview
You can register your own binding implementations through the binding registry preference page available. To access the binding registry preference page, from the menu select Window > Preferences. In the Preferences window, expand Business Integration and click Binding Registry.
The preference page is divided into a Registry Entries view where all registry entries are shown and a Details view where properties of a selected entry are shown. You can add a new entry to the User specified entries section by using an Add button or edit an existing user specified entry by using an Edit button. These buttons launch windows that you complete. You can also remove a user specified entry by using a Delete button. The plug-in specified entries and the adapter specified entries are treated as system entries and cannot be changed.
Import and exporting user-specified entries
You may decide to remove your entries from the binding registry but do not want to lose the entries information itself. You can store selected entries from the user-specified entries section into a file by using the export function which is activated by clicking the Advanced button. Subsequently, the entries stored in the file can be added back into the binding registry by using the import function, which is also activated by the Advanced button. This feature lets you share binding registry content among workbenches.
Binding registry entry edit window
Each binding object is described by a set of properties that make it unique and thus allows it to be registered in the binding registry. The Add and Edit Binding Registry Entry window lets you contribute new or modify exiting binding object properties. The following properties describe a binding object:
- Display name: Contains a short name that identifies the binding object and is intended to be displayed by tools.
- Description: Provides the detailed description of the binding object.
- Class name: Specifies the fully-qualified name of the binding object implementation class.
- Type: A constant that identifies the binding object. A type from the list (DataBinding, DataHandler, FunctionSelector) is prepopulated based on the top-level interface the binding object class implements.
- Supported type (optional): A list of fully-qualified names for the Java™ interface or class that provides the bindings contract. For example, with CICS this would be the javax.resource.cci.Streamable class and with JMS it would be the com.ibm.websphere.sca.jms.data.JMSDataBinding class.
- Supported service type: A list of service binding types that use the binding object. The following service types are supported: JMS, MQ, HTTP, FTP, Email, Flat File.
- ASI namespace URI (optional): A list of the namespaces of the Application Specific Information (ASI) Schemas that are supported by the binding object. To indicate the binding object can handle a business object that does not have or does not need ASI information specified, you can use special form of URI - urn:commonj.connector.asi:nil - as a value for the ASI namespace URI property.
- Tag: A list of tags. A tag value specifies an additional context for the binding object usage.
Binding registry export window
The Export Binding Registry User Specified Entries window lets you copy user-defined entries to an external file so the entries can be shared among other workbenches. In the window you need to specify the name of the file including a .bindings file extension, and the location in the workspace where the file should be saved. Typically you would save the file to a folder under your Business Integration module and then export the module as an Integration module or a Project Interchange file.
Important: Only files with a .bindings file extension will be processed by the import function at the time when you retrieve the entries stored in the file back into binding registry. Therefore, DO NOT CHANGE this file extension.
Binding registry import window
The Import Binding Registry User Specified Entries window lets you load user-defined entries from an external file back into the binding registry. In the window you need to specify the location in the workspace where the file with the .bindings file extension is stored. If you do not have the file in the workspace, you can import it from the file system into workspace folder using the Import function and specifying an import from the File System.
Application Specific Information (ASI) registry preferences page
The application specific information (ASI) registry preferences page is a registered list for your ASI schemas created by IBM Integration Designer generations or by yourself.
When working with a resource adapter we need to capture the information required by the adapter to marshal the Enterprise Information Systems (EIS)-neutral data objects to the native objects used to interact with the EIS. The information that describes the data conversions is stored in XML schema files in the form of annotations. The XML schema provides an appInfo tag for providers to describe application-specific information. This schema is called the ASI schema. Application Specific Information (ASI) is metadata related to data wire formatting and schema editing that is encapsulated as annotations within a schema. This information describes a request message to an EIS or a response message from an EIS. In general, ASI schemas are provided by a resource adapter.
The Application Specific Schemas Registry (ASI registry) component provides a global point of access to the repository of XML Schema documents (ASI Schemas) that specify application-specific information used by an application to map a business object into its corresponding enterprise entity. Ultimately, all XML schemas are stored into an XML catalog component. Therefore, one of the main functions of the ASI registry is to create XML catalog entries for ASI Schemas. These entries are then used by an XML processor when resolving entity references.
To see the available ASI registry entries, from the menu select Window > Preferences. In the Preferences window, expand Business Integration and click Application Specific Schemas Registry.
The preference page is divided into a Registry Entries view where all registry entries are shown and a Details view where properties of a selected entry are shown. You can add a new entry to the User specified entries section using the Add button or edit an existing user specified entry buy using the Edit button. You can also remove a user-specified entry using the Delete button. The Plug-in specified entries and Adapter-specified entries are treated as system entries and cannot be changed.
- Add application-specific entries
- Each ASI schema is described by a set of properties that make it unique. This allows an ASI schema to be registered in the ASI registry.
The add and edit windows allow you to contribute new ASI schema information or modify existing ASI schema information. The following properties, shown when use the add and edit buttons, describe the ASI schema.
- Display name - Contains a short name that identifies the ASI schema that will be displayed by the IBM Integration Designer tools.
- Description - Provides the detailed description of the ASI schema.
- XSD file location -URL that specifies the ASI schema unique location.
- Namespace URI - Identifies the namespace of the ASI schema.
You can browse for the ASI schema location in either the workspace or the file system using the button next to the XSD file location field. The namespace URI field will be completed automatically after the ASI schema is specified.
- Import and exporting user-specified entries to and from the workbench
- You may decide to remove your entries from the registry but do not want to lose the entries' information. In that case you can store selected entries from the user-specified entries tree into a file using the export function. The function is available by clicking the Advanced button.
The entries stored in the file can be added back into the registry by again using the same button but using the import function. This feature means you can share user-defined content among workbenches.
- Export Application Specific Schemas Registry User Specified Entries
- This window lets you copy user-defined entries to an external file so the entries can be shared among other workbenches. In the window, you need to specify the name of the file with an .asi file extension. You also need to specify the location in the workspace where the file should be saved. Typically, you would save the file to a folder under your Business Integration module and then export the module as an Integration module or Project Interchange file.
-
Only files with .asi file extensions will be processed by the import function when you want the entries stored in the file to be added back into the ASI registry. DO NOT change this file extension.
- Import Application Specific Schemas Registry User Specified Entries
- This window lets you load user-defined entries from an external file back into the ASI registry. In the window, you need to specify the location in the workspace where the file with .asi file extension is stored. If you do not have the file in the workspace, you can import it from the file system into workspace folder using Import Files function.