WebSphere eXtreme Scale Product Overview > Cache concepts
|
| |
Local in-memory cache
In the simplest case, eXtreme Scale can be used as a local (non-distributed) in-memory data grid cache. The local case can especially benefit high-concurrency applications where multiple threads need to access and modify transient data. The data kept in a local eXtreme Scale grid can be indexed and retrieved using WebSphere eXtreme Scale's query support. The ability to query the data can help developers greatly when working with large in memory data sets versus the limited data structure support provided with the Javaâ„¢ virtual machine (JVM), which is ready to use as is.
The local in-memory cache topology for eXtreme Scale is used to provide consistent, transactional access to temporary data within a single Java virtual machine.
Figure 1. Local in-memory cache scenario
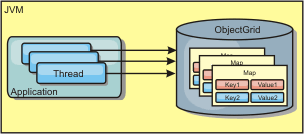
Advantages
- Simple setup: An ObjectGrid can be created programmatically or declaratively with the ObjectGrid deployment descriptor XML file or with other frameworks such as Spring.
- Fast: Each BackingMap can be independently tuned for optimal memory utilization and concurrency.
- Ideal for single-Java virtual machine topologies with small dataset or for caching frequently accessed data.
- Transactional. BackingMap updates can be grouped into a single unit of work and can be integrated as a last participant in 2-phase transactions such as Java Transaction Architecture (JTA) transactions.
Disadvantages
- Not fault tolerant.
- The data is not replicated. In-memory caches are best for read-only reference data.
- Not scalable. The amount of memory required by the database might overwhelm the Java virtual machine.
- Problems occur when adding Java virtual machines:
- Data cannot be partitioned
- Must manually replicate state between Java virtual machines or each cache instance could have different versions of the same data.
- Invalidation is expensive.
- Each cache must be warmed up independently. The warm-up is the period of loading a set of data so that the cache gets populated with valid data.
When to use
The local, in-memory cache deployment topology should only be used when the amount of data to be cached is small (can fit into a single Java virtual machine) and is relatively stable. Stale data must be tolerated with this approach. Using evictors to keep most frequently or recently used data in the cache can help keep the cache size low and increase relevance of the data.
- Peer-replicated local in-memory cache
For a local WebSphere eXtreme Scale cache, ensure the cache is synchronized if there are multiple processes with independent cache instances. To do so, enable a peer-replicated cache with JMS.