Crawl an external site using a seedlist
Overview
The seedlist HTTP crawler crawls external sites that publish content using the seedlist format.
The seedlist format is an ATOM/XML-based format specifically for publishing application content, including metadata. The format supports publishing only updated content between crawling sessions for more effective crawling.
You can configure the seedlist crawler with general parameters, filters and schedulers, then run the crawler.
Before configuring the seedlist crawler, collect the following information:
- Root URL of the seedlist page.
The seedlist page is an ATOM/XML page containing metadata that directs the crawler to the actual links that should be fetched and indexed to become searchable later.
The seedlist page also contains document level metadata that is stored along with the document in the search index. In order to make seedlist crawler results searchable, provide the crawler with a URL to a page containing a seedlist. The crawler retrieves the seedlist and crawls the pages indicated by the seedlist.
- User ID and Password to be used by the crawler to authenticate the seedlist page.
Create the seedlist crawler
- Click...
-
Manage Search | Search Services | your_portal_search_service
- Click on the name of an existing search collection, or create a new search collection.
- Click New Content Source.
- Click the drop-down menu icon next to Content source type and click Seedlist Feed to indicate that the content source is a seedlist.
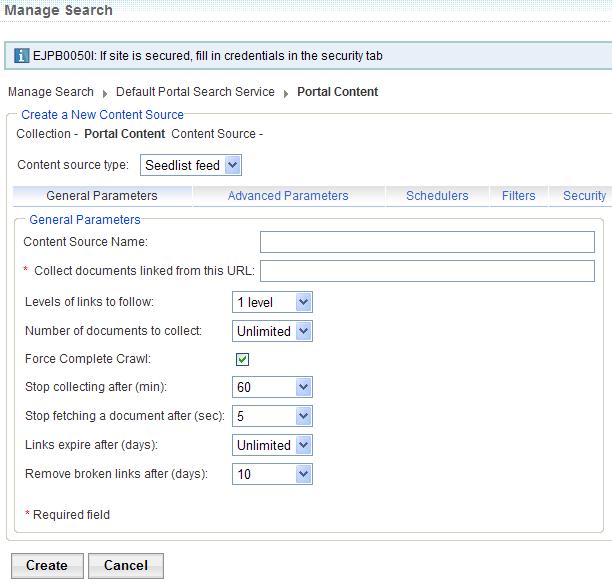
- Under the General Parameters tab, provide required and optional information...
Name Description Required? Content Source Name Enter a name that will help you remember the seedlist source being crawled no Collect documents linked from this URL Root URL, the URL of the seedlist page yes Levels of links to follow Use the drop-down menu to select how many levels of pages the crawler will follow from the seedlist no default value is 1
Number of documents to collect Sets a maximum number of linked documents to collect no default value is unlimited
Force complete crawl Indicates whether the crawler needs to fetch only updates from the Seedlist feed or from the full list of content. When checked, the crawler will request the full list of content items. When unchecked, the crawler will request only the list of updates. no default value is checked
Stop collecting after Indicates in minutes the maximum time interval the crawler should operate no Stop fetching a document after Indicates in seconds how much time the crawler will spend trying to fetch a document no Links expire after Indicates in days when links expire and need to be refreshed by the crawler no default value is unlimited
option is not available if Force complete regathering is not selected
Remove broken links after Indicates in days when broken links should be removed no default value is 10
option is not available if Force complete regathering is not selected
- Under the Schedulers tab, set how often the crawler should run to update the search content.
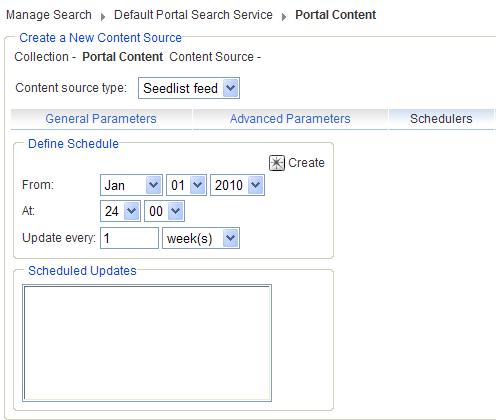
- Set the date when the crawler should start running.
- Set the time of day when the crawler should run.
- Set the update interval.
- Click Create.
- Under the Filters tab, you can define rules that control how the crawler collects documents and adds them to the search index.
You can include or exclude based on the document's URL. The filters are not effective for the links inside the seedlist.

- Under the Security tab, provide required and optional information in the following fields:
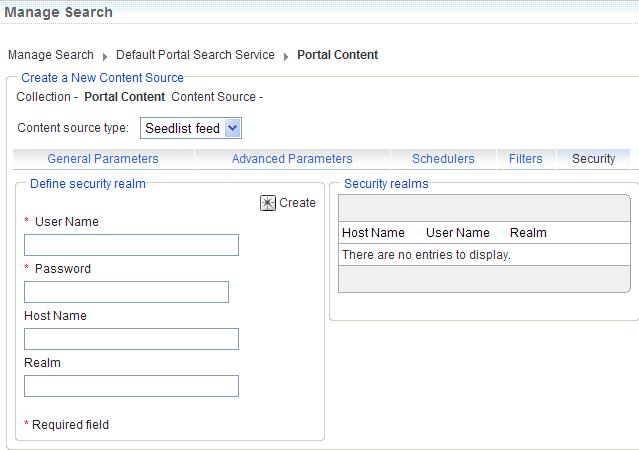
Parameter name Parameter value description Required? User name User ID used by the crawler to authenticate the seedlist page yes Password Password used by the crawler to authenticate the seedlist page yes Host Name The name of the server referenced by the seedlist. This is not required, and if left blank, the host name is inferred from the seedlist root URL. no Realm Realm of the secured content source or repository. no - Click Create.
- To run the crawler, click the start crawler icon (right-pointing arrow) next to the content source name on the Content Sources page.
If you have defined a crawler schedule under the Schedulers tab, the crawler will start at the next possible time specified.
To retrieve seedlist, append...
-
"&userid=wpsadminuser&password=wpsadminpassword&debug=1"
...at the end of the search seed.
Parent topic
Searching and crawling portal and other sites