Product overview > Availability overview > Replicas and shards
Shard life cycles
Life cycle events
Shards go through different states and events to support replication. The life cycle of a shard includes coming online, run time, shut down, fail over and error handling. Shards can be promoted from a replicat shard to a primary shard to handle server state changes.
When primary and replica shards are placed and started, they go through a series of events to bring themselves online and into listening mode.
Primary
shard
The catalog service places a primary shard for a partition. The catalog service also does the work of balancing primary shard locations and initiating failover for primary shards.
When a shard becomes a primary shard, it receives a list of replicas from the catalog service. The new primary shard creates a replica group and registers all the replicas.
When the primary is ready, an open for business message displays in the SystemOut.log file for the container on which it is running. The open message, or the CWOBJ1511I message, lists the map name, map set name, and partition number of the primary shard that started.
CWOBJ1511I: mapName:mapSetName:partitionNumber (primary) is open for business.
See Shard placement for more information on how the catalog service places shards.
Replica shard
Replica shards are mainly controlled by the primary shard unless the replicat shard detects a problem. During a normal life cycle, the primary shard places, registers, and de-registers a replica shard.
When the primary shard initializes a replica shard, a message displays the log that describes where the replica runs to indicate that the replicat shard is available. The open message, or the CWOBJ1511I message, lists the map name, map set name, and partition number of the replicat shard. This message follows:
CWOBJ1511I: mapName:mapSetName:partitionNumber (synchronous replica) is open for business.
...or...
CWOBJ1511I: mapName:mapSetName:partitionNumber (asynchronous replica) is open for business.
Asynchronous replicat shard: An asynchronous
replicat shard polls the primary for data. The replica automatically
will adjust the poll timing if it does not receive data from the primary,
which indicates that it is caught up with the primary. It also will
adjust if it receives an error that might indicate that the primary
has failed, or if there is a network problem.
When the asynchronous replica starts replicating, it prints the following message to the SystemOut.log file for the replica. This message might print more than one time per CWOBJ1511 message. It will print again if the replica connects to a different primary or if template maps are added.
CWOBJ1543I: The asynchronous replica objectGridName:mapsetName:partitionNumber started or continued replicating from the primary. Replicating for maps: [mapName]
Synchronous replicat shard:
When the synchronous replica shard first starts, it is not yet in peer mode. When a replicat shard is in peer mode, it receives data from the primary as data comes into the primary. Before entering peer mode, the replica shard needs a copy of all of the existing data on the primary shard.
The synchronous replica copies data from the primary shard similar to an asynchronous replica by polling for data. When it copies the existing data from the primary, it switches to peer mode and begins to receive data as the primary receives the data.
When a replicat shard reaches peer mode, it prints a message to the SystemOut.log file for the replica. The time refers to the amount of time that it took the replica shard to get all of its initial data from the primary shard. The time might display as zero or very low if the primary shard does not have any existing data to replicate. This message may print more than one time per CWOBJ1511 message. It will print again if the replica connects to a different primary or if template maps are added.
CWOBJ1526I: Replica objectGridName:mapsetName:partitionNumber:mapName entering peer mode after X seconds.
When the synchronous replica shard is in peer mode, the primary shard must replicate transactions to all peer mode synchronous replicas. The synchronous replicat shard data remains at the same level as the primary shard data. If a minimum number of synchronous replicas or minSync is set in the deployment policy, that number of synchronous replicas must vote to commit before the transaction can successfully commit on the primary.
Recovery events
Replication is designed to recover from failure and error events. If a primary shard fails, another replica takes over. If errors are on the replica shards, the replicat shard attempts to recover. The catalog service controls the placement and transactions of new primary shards or new replica shards.
Replica shard becomes a primary shard
A replicat shard becomes a primary shard for two reasons. Either the primary shard stopped or failed, or a balance decision was made to move the previous primary shard to a new location.
The catalog service selects a new primary shard from the existing synchronous replica shards. If a primary move needs to take place and there are no replicas, a temporary replica will be placed to complete the transition. The new primary shard registers all of the existing replicas and accepts transactions as the new primary shard. If the existing replica shards have the correct level of data, the current data is preserved as the replica shards register with the new primary shard. Asynchronous replicas will poll against the new primary.
Figure 1. Example placement of an ObjectGrid map set for the partition0 partition. The deployment policy has a minSyncReplicas value of 1, a maxSyncReplicas value of 2, and a maxAsyncReplicas value of 1.
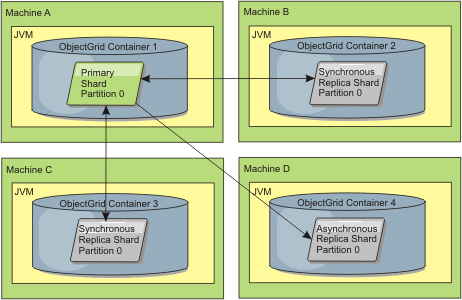 synchronous replica shards. Machine D has an asynchronous replica shard." />
synchronous replica shards. Machine D has an asynchronous replica shard." />
Figure 2. The container for the primary shard fails
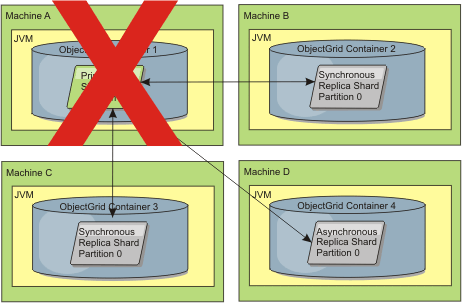
Figure 3. The synchronous replica shard on ObjectGrid container 2 becomes the primary shard
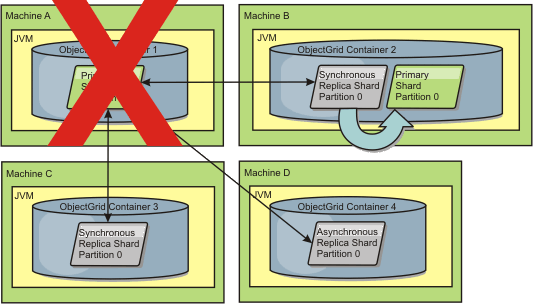 synchronous replica shard becomes the primary shard." />
synchronous replica shard becomes the primary shard." />
Figure 4. Machine B contains the primary shard. Depending on how automatic repair mode is set and the availability of the containers, a new synchronous replica shard might or might not be placed on a machine.
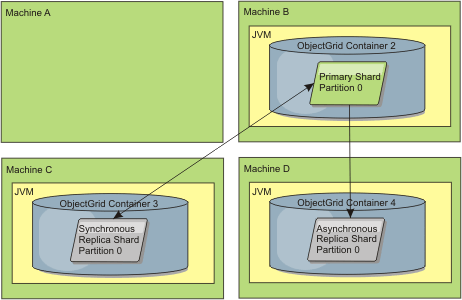 synchronous replica shard, and machine D has an asynchronous replica shard" />
synchronous replica shard, and machine D has an asynchronous replica shard" />
A synchronous replica shard is controlled by the primary shard. However, if a replicat shard detects a problem, it can trigger a reregister event to correct the state of the data. The replica clears the current data and gets a fresh copy from the primary.
When a replica shard initiates a reregister event, the replica prints a log message.
CWOBJ1524I: Replica listener objectGridName:mapSetName:partition must re-register with the primary. Reason: Exception listed
If a transaction causes an error on a replicat shard during processing, then the replicat shard is in an unknown state. The transaction successfully processed on the primary shard, but something went wrong on the replica.
To correct this situation, the replica initiates a reregister event. With a new copy of data from the primary, the replica shard can continue. If the same problem reoccurs, the replicat shard does not continuously reregister. See Failure events for more details.
Failure events
A replica can stop replicating data if it encounters error situations for which the replica cannot recover.
Too many register attempts
If a replica triggers a reregister multiple times without successfully committing data, the replica stops. Stopping prevents a replica from entering an endless reregister loop. By default, a replicat shard tries to reregister three times in a row before stopping.
If a replicat shard reregisters too many times, it prints the following message to the log.
CWOBJ1537E: objectGridName:mapSetName:partition exceeded the maximum number of times to reregister (timesAllowed) without successful transactions..
If the replica is unable to recover by reregistering, a pervasive problem might exist with the transactions that are relative to the replica shard. A possible problem could be missing resources on the classpath if an error occurs while inflating the keys or values from the transaction.
Failure while entering peer mode
If a replica attempts to enter peer mode and experiences an error processing the bulk existing data from the primary (the checkpoint data), the replica shuts down. Shutting down prevents a replica from starting with incorrect initial data. Because it receives the same data from the primary if it reregisters, the replica does not retry.
If a replicat shard fails to enter peer mode, it prints the following message to the log:
CWOBJ1527W Replica objectGridName:mapSetName:partition:mapName failed to enter peer mode after numSeconds seconds.
An additional message displays in the log that explains why the replica failed to enter peer mode.
Recovery after re-register or
peer mode failure
If a replica fails to re-register or enter peer mode, the replica is in an inactive state until a new placement event occurs. A new placement event might be a new server starting or stopping. You can also start a placement event by using the triggerPlacement method on the PlacementServiceMBean Mbean.
Parent topic:
Replicas and shards
Related concepts
Shard placement
Reading from replicas
Load balancing across replicas