Use checkpointing to ensure complete recovery
Both circular logging and linear logging queue managers support restart recovery. Regardless of how abruptly the previous instance of the queue manager terminates (for example a power outage) upon restart the queue manager restores its persistent state to the correct transactional state at the point of termination.
Restart recovery depends upon disk integrity being maintained. Similarly, the operating system should ensure disk integrity regardless of how abruptly an operating system termination might occur.
In the highly unusual event that disk integrity is not maintained then linear logging (and media recovery) provides some further redundancy and recoverability options. With increasingly common technology, such as RAID, it is increasingly rare to suffer disk integrity issues and many enterprises configure circular logging and use only restart recovery.
IBM MQ is designed as a classic Write Ahead Logging resource manager. Persistent updates to message queues happen in two stages:- Log records representing the update are written reliably to the recovery log
- The queue file or buffers are updated in a manner that is the most efficient for your system, but not necessarily consistently.
If this situation was allowed to continue unabated, then a very large volume of log replay would be required to make the queue state consistent following a crash recovery.
IBM MQ uses checkpoints in order to limit the volume of log replay required following a crash recovery. The key event that controls whether a log file is termed active or not is a checkpoint.
An IBM MQ checkpoint is a point:- Of consistency between the recovery log and object files.
- That identifies a place in the log, from which forward replay of subsequent log records is guaranteed to restore the queue to the correct logical state at the time the queue manager might have ended.
During a checkpoint, IBM MQ flushes older updates to the queues files, as required, in order to limit the volume of log records that need to be replayed to bring the queues back to a consistent state following a crash recovery.
The most recent complete checkpoint marks a point in the log from which replay must be performed during crash recovery. The frequency of checkpoint is thus a trade-off between the overhead of recording checkpoints, and the improvement in potential recovery time implied by those checkpoints.
The position in the log of the start of the most recent complete checkpoint is one of the key factors in determining whether a log file is active or inactive. The other key factor is the position in the log of the first log record relating to the first persistent update made by a current active transaction.
If a new checkpoint is recorded in the second, or later, log file and no current transaction refers to a log record in the first log file, the first log file become inactive. In the case of circular logging the first log file is now ready to be reused. In the case of linear logging the first log file will typically still be required for media recovery.
If you configure either circular logging or automatic log management the queue manager will manage the inactive log files. If you configure linear logging with manual log management it becomes an administrative task to manage the inactive files according to the requirements of your operation.
IBM MQ generates checkpoints automatically. They are taken at the following times:- When the queue manager starts
- At shutdown
- When logging space is running low
- After 50,000 operations have been logged since the previous checkpoint was taken
- After number_of_operations have been logged since the previous checkpoint was taken, where number_of_operations is the number of operation set in the LOGLOAD property.
When IBM MQ restarts, it finds the latest checkpoint record in the log. This information is held in the checkpoint file that is updated at the end of every checkpoint. All the operations that have taken place since the checkpoint are replayed forward. This is known as the replay phase.
The replay phase brings the queues back to the logical state they were in before the system failure or shutdown. During the replay phase a list is created of the transactions that were in-flight when the system failure or shutdown occurred.
Messages AMQ7229 and AMQ7230 are issued to indicate the progression of the replay phase.
In order to know which operations to back out or commit, IBM MQ accesses each active log record associated with an in-flight transaction. This is known as the recovery phase.
Messages AMQ7231, AMQ7232 and AMQ7234 are issued to indicate the progression of the recovery phase.
Once all the necessary log records have been accessed during the recovery phase, each active transaction is in turn resolved and each operation associated with the transaction will be either backed out or committed. This is known as the resolution phase.
Message AMQ7233 is issued to indicate the progression of the resolution phase.
On z/OS®, restart processing is made up of various phases.- The recovery log range is established, based on the media recovery required for the page sets and the oldest log record that is required for backing out units of work and obtaining locks for in-doubt units of work.
- Once the log range has been determined, forward log reading is carried out to bring the page sets up to the latest state, and also to lock any messages that are related to in-doubt or in-flight units of work.
- When forward log reading has been completed the logs are read backwards to backout any units of work that were in-flight or in-backout at the time of failure.
CSQR001I +MQOX RESTART INITIATED CSQR003I +MQOX RESTART - PRIOR CHECKPOINT RBA=00000001E48C0A5E CSQR004I +MQOX RESTART - UR COUNTS - 806 IN COMMIT=0, INDOUBT=0, INFLIGHT=0, IN BACKOUT=0 CSQR030I +MQOX Forward recovery log range 815 from RBA=00000001E45FF7AD to RBA=00000001E48C1882 CSQR005I +MQOX RESTART - FORWARD RECOVERY COMPLETE - 816 IN COMMIT=0, INDOUBT=0 CSQR032I +MQOX Backward recovery log range 817 from RBA=00000001E48C1882 to RBA=00000001E48C1882 CSQR006I +MQOX RESTART - BACKWARD RECOVERY COMPLETE - 818 INFLIGHT=0, IN BACKOUT=0 CSQR002I +MQOX RESTART COMPLETEDNote: If there is a large amount of log to be read, messages CSQR031I (forward recovery) and CSQR033I (backwards recovery) are issued periodically to show the progression.
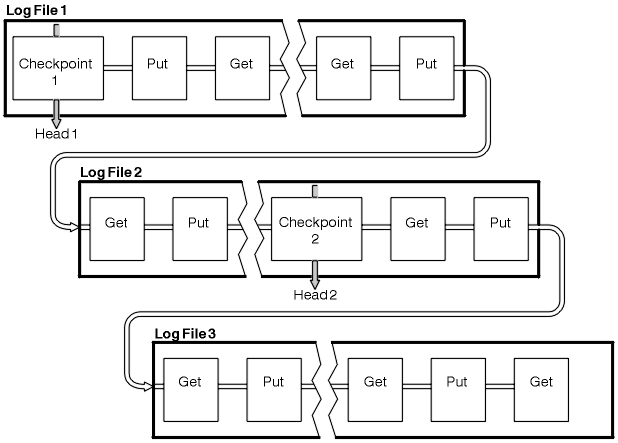
In Figure 1, all records before the latest checkpoint, Checkpoint 2, are no longer needed by IBM MQ. The queues can be recovered from the checkpoint information and any later log entries. For circular logging, any freed files before the checkpoint can be reused. For a linear log, the freed log files no longer need to be accessed for normal operation and become inactive. In the example, the queue head pointer is moved to point at the latest checkpoint, Checkpoint 2, which then becomes the new queue head, Head 2. Log File 1 can now be reused.