Queue manager journal usage on IBM i
Use this information to understand how IBM MQ for IBM i uses journals in its operation to control updates to local objects.
Persistent updates to message queues happen in two stages. The records representing the update are first written to the journal, then the queue file is updated.
The journal receivers can therefore become more up to date than the queue files. To ensure that restart processing begins from a consistent point, IBM MQ uses checkpoints.
A checkpoint is a point in time when the record described in the journal is the same as the record in the queue. The checkpoint itself consists of the series of journal records needed to restart the queue manager. For example, the state of all transactions (that is, units of work) active at the time of the checkpoint.
Checkpoints are generated automatically by IBM MQ. They are taken when the queue manager starts and shuts down, and after a certain number of operations are logged.
We can force a queue manager to take a checkpoint by issuing the RCDMQMIMG command against all objects on a queue manager and displaying the results, as follows:RCDMQMIMG OBJ(*ALL) OBJTYPE(*ALL) MQMNAME(Q_MGR_NAME) DSPJRNDTA(*YES)
As the queues handle further messages, the checkpoint record becomes inconsistent with the current state of the queues.
When IBM MQ is restarted, it locates the latest checkpoint record in the log. This information is held in the checkpoint file that is updated at the end of every checkpoint. The checkpoint record represents the most recent point of consistency between the log and the data. The data from this checkpoint is used to rebuild the queues as they existed at the checkpoint time. When the queues are re-created, the log is then played forward to bring the queues back to the state they were in before system failure or close down.
To understand how IBM MQ uses the journal, consider the case of a local queue called TESTQ in the queue manager TEST. This is represented by the IFS file:/QIBM/UserData/mqm/qmgrs/TEST/queuesIf a specified message is put on this queue, and then retrieved from the queue, the actions that take place are shown in Figure Figure 1.
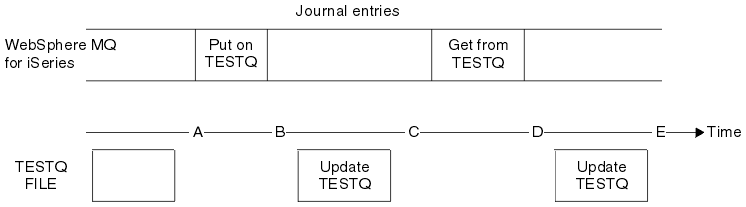
- A
- The IFS file representation of the queue is consistent with the information contained in the journal.
- B
- A journal entry is written to the journal defining a Put operation on the queue.
- C
- The appropriate update is made to the queue.
- D
- A journal entry is written to the journal defining a Get operation from the queue.
- E
- The appropriate update is made to the queue.
The key to the recovery capabilities of IBM MQ for IBM i is that the user can save the IFS file representation of TESTQ as at time A, and subsequently recover the IFS file representation of TESTQ as at time E, by restoring the saved object and replaying the entries in the journal from time A onwards.
This strategy is used by IBM MQ for IBM i to recover persistent messages after system failure. IBM MQ remembers a particular entry in the journal receivers, and ensures that on startup it replays the entries in the journals from this point onwards. This startup entry is periodically recalculated so that IBM MQ only has to perform the minimum necessary replay on the next startup.
IBM MQ provides individual recovery of objects. All persistent information relating to an object is recorded in the local IBM MQ for IBM i journals. Any IBM MQ object that becomes damaged or corrupt can be completely rebuilt from the information held in the journal.
For more information on how the system manages receivers, see Availability, backup, recovery, and restart on IBM i.