Application Best Practices
Best practices for building high performing and resilient eXtreme Scale applications
Data is the central element of all computing systems, which exist to manage, mine, and manipulate data. In the Internet age, applications demand not only immediate access to data, but they also often attempt this access in a crushing wave of near-simultaneous requests. Despite advances in database technology, a centralized datastore proves problematic for applications at this level of demand and responsiveness.
IBM WebSphere eXtreme Scale provides an alternative to centralized data access for high-volume and high-SLA (service level agreement) applications. eXtreme Scale brings data closer to applications via caching technology. Moving the data closer to the applications delivers several potential benefits:
- Local data can improve application performance.
This includes both caching the data close to the application and replicating application logic close to the (partitioned) data for parallel processing.
- Providing a cache for frequently-accessed data might time-shift or reduce contention and overall request volumes to the database.
This in turn reduces hardware and licensing costs at the database layer, and can improve the database responsiveness overall for applications sharing this resource.
- Bringing the data closer to the applications can improve availability.
eXtreme Scale provides features to replicate data throughout the environment, improving resiliency.
- Caching data in the final native application form (objects) reduces path length.
Compared with accessing SQL-based data.
- Caching the results of complex business logic results in faster subsequent calls and a lower overall solution cost
The appropriate use of queries
eXtreme Scale is not a relational database.
eXtreme Scale has two different APIs for defining the ways in which objects are placed into and fetched from the cache:
- Map API
Based on the java.util.Map API. When using the Map API, you effectively treat objects in the grid as if they were objects in a local hashmap. You use methods like insert(), put(), and get() to place objects in the grid and retrieve them from the grid. With the Map API, the most appropriate use of the grid is clear: You simply put objects in at an appropriate key and look objects up by the same key. The database confusion arises when you consider the second available eXtreme Scale API, the EntityManager API.
- EntityManager API
Modeled after the Java Persistence API entity model. When using the EntityManager API, you use annotations to describe entities placed into a eXtreme Scale cache. You store objects into the grid using the EntityManager.persist() method, much as you would with JPA. However, it is the next similarity to JPA that sometimes lead developers to make some poor choices that result in a sub-optimal use of the product. You can look up entities using either a find() method, which retrieves objects by their key, or you can use queries, which look up objects by a combination of attribute values.
First-time eXtreme Scale users might rely too heavily on the query capability of the eXtreme Scale EntityManager API, especially when incorporating eXtreme Scale into an existing application tailored to database access. eXtreme Scale is primarily a caching provider. The query functionality is a valid convenience feature of the product, but it is not backed by all the sophisticated query optimizers found in top-end databases. Therefore, eXtreme Scale is most efficient finding an object by its key rather than locating that same object by a query. Which leads us to another major principle:
The principal access path to any object in a grid should be either through the Map API or through an EntityManager find() using the object's primary key.
That one simple design principle can eliminate many performance headaches in designing eXtreme Scale applications. Again, the application can use the query feature of eXtreme Scale, but for high-performance paths or overall high-performance applications, the recommended access is via the Map API or the find() operation. (A discussion on indices and other optimizations for the query -- if your application must use them . is coming up later.)
In general, you want to use caching to optimize only high volume, high frequency access of data. The best way to realize the performance benefit of a cache and to reduce traffic to the central database is to maximize the hit rate into the cache; in eXtreme Scale, this particularly includes the near cache (which is in the same memory space as the client). Thus, the data in the cache must be commonly accessed in order to gain this benefit. Figure 1 shows the aspects of an object grid solution for high performance access.
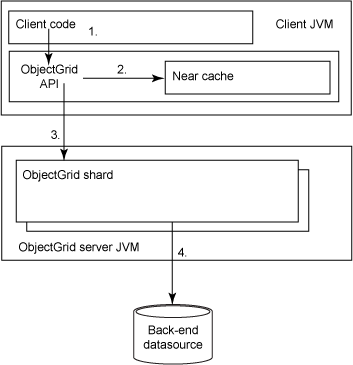
A shard in eXtreme Scale is a partition of data that is placed within a container. There are both primary shards and replica shards. eXtreme Scale makes its data highly available by placing replicated data in separate servers.
In this scenario, a client call to the ObjectGrid API (1) first results in a search of the Near cache (2). If the result is not found, then ObjectGrid will locate the appropriate ObjectGrid server, and that particular shard in that server that should hold that result (3). In the case where this does not exist, then the result might be a loader being invoked, which will load the value from a back-end datastore (4). In order to quantify what this means, you will next need to examine the contributions of different aspects of a eXtreme Scale caching solution. But before you do that, let's discuss some general principles for cache design.
Finding the right cache freshness
Using a cache is a balancing act between time and memory size. A critical principle of caching is that you trade memory for other things -- better response times, and/or increased resiliency, and/or reduced contention in costs in other systems. Therefore, managing the lifetime of the objects in the cache is important. The lifetime of objects in the cache is determined by the consistency of the data in the cache across a set of accesses to the data.
For each application, there is an acceptable level of "staleness" in the data. Because of its implementation, eXtreme Scale never permits different versions of the same data in its cache. It guarantees everyone's cache sees the same version of each object, except when a near cache is used. This is what makes WXS useful for caching even read/write data. For instance, you would not want to change the set of data used in a batch job while the job is running. However, in an interactive application, changes to data might be more dynamic; if a user is logged on for a long period of time, then he might expect changes in data to be reflected when they occur. Thus in the first case, the minimum lifetime of objects in the cache would be the lifetime of the batch job. In the second, it could vary by how quickly the users expect to see changes in data reflected. In any case, you should prefer simple eviction strategies, like time-to-live, whenever possible. In both of the cases above, this could be easily implemented by simply choosing a time that suits the needs of the type of application being developed; longer in the case of a batch application (for instance, slightly longer than the longest batch job), or shorter in the case of an online application. Of course, elements shared by multiple users or by all batch jobs in a read-only capacity merit a longer cache lifetime. eXtreme Scale also has various ways to make the handling of changed data more intelligent, reacting to the actual changes as they occur.
However, the question of whether or not your data is stale changes when you consider the case of the near cache. Remember that the near cache is unique to each eXtreme Scale client, not shared like the main ObjectGrid cache. Because of this, it is possible for data in the near caches to get out of sync both with each other and the main ObjectGrid cache. Thus, your choices are usually either to set a very short time-to-live for data in the near cache (which reduces its utility), or not use the near cache at all and rely only on the main ObjectGrid cache, (which will not suffer from the staleness problem).
The near cache is also only useful if it has a large enough capacity to obtain a high hit rate. If a eXtreme Scale cache was caching 200 GB of data, then it might not be possible for a near cache to hold a subset of that data to result in a useful hit rate simply because clients wouldn't have enough memory.
Finally, when thinking about your design and your tolerance for staleness, you need to determine what the actual system of record is in your overall application design. If the ObjectGrid is your system of record, then you can use write-behind database updating or make the cache a write-through cache. This has the advantage of never having stale data in the cache, since the cache is the authoritative source for the data. On the other hand, if the database is the system of record, then you could use either optimistic locking or ObjectGrid.s built-in SCN support to detect and handle stale data in the cache.
The ObjectGrid caching equation
Now that you understand the general principles for cache design, you can begin to consider this equation:
Tavg = Nh * Tn + (1-Nh) * (Rh * Tr + (1-Rh) * Td)
Each of the elements in this equation represents a contribution to the average time it takes any request to be processed by a grid. Let's look at each of these in turn and then discuss the effect that you can have on each contribution in your ObjectGrid design:
- Nh represents the near cache hit rate.
The near cache is a small cache that resides within the ObjectGrid client . and is thus the fastest cache to access, because using it does not entail any out of process calls to the cache, including those that might incur network access.
- Tn is the time that it takes to retrieve an object from the near cache.
Effectively, this is very, very low; much less than 1ms in most cases, so you can simplify the math by just calling this a constant value of 1ms. This corresponds to item 2 in Figure 1.
- Rh is the hit rate to the remote cache.
The remote cache is the cache located in your grid. The hit rate represents how often an object will be found in the remote cache.
- Tr is the retrieval time for an object in the remote cache.
This is dependent on:
- Serialization overhead for the out-of-process call.
- Network latency.
- eXtreme Scale processing overhead.
- Clock speed of the processor cores handling the request on both sides.
- The size of the object
- JVM Garbage collection overhead
These metrics should be measured experimentally in testing, as the timings vary from design to design. They're also influenced by network conditions, eXtreme Scale configuration, and the processing speed of your servers.
This corresponds to line 3 in Figure 1.
- Td is the retrieval time for an object from the database.
This should also be measured experimentally in testing. This corresponds to item 4 in Figure 1.
Assume you have determined...
- The hit rate to the near cache will be approximately 70%.
70% of the time you will be accessing an object that you've very recently pulled from the remote cache in this particular eXtreme Scale client.
- The hit rate you have for the remote cache is 80%.
Objects pulled into the remote cache from the database are then accessed again 80% of the time vs. having to pull a new object into the grid.
- You've experimentally determined Tr to be 20ms, and measured Td to be 200ms.
Plugging in all these numbers gives you:
Tavg = (0.7 * 1ms + (1-0.7) * (0.8 * 20ms + (1-0.8) * 200ms) = 17.5ms
Notice how closely this is dependent on the coefficients from the hit rates; for instance, a small increase in the near cache hit rate to 80% would result in an average response time of 12 ms -- a 30% improvement! However, it's also important to realize that 70% of the time, the response time is 1ms. The larger outliers (200ms) skew the average, so it's very important to make sure that you take all factors into account when you're describing the behavior of the application as a whole; it really comes down to what kind of performance your users will expect and can tolerate, both in terms of average response times and the effect of the caches on the "most of the time" case.
Steps to take based on caching equation results
- Consider both the advantages and disadvantages of using the near cache.
You might have two competing goals in your application.
- Make Nh as close to 100% as it can reasonably be by choosing objects in the cache such that they exhibit good locality of reference.
- Avoid cache staleness or synchronization issues
If your application requirements permit the use of the near cache, then you should use it, but otherwise, you need to move on to the next possibility for improving your overall performance.
- Next, to optimize Rh you can improve the chances that an object will be found in the remote cache by using either a preloading strategy or a predictive loading strategy.
Preloading is the approach by which you have a set of objects that is entirely loaded into the cache at startup time. Predictive loading is a strategy by which when you load an object (say, upon a cache miss) and then guess which other related objects might also need at the same time and load them as well. The next section on preloading vs. load on demand will help you understand the tradeoffs inherent in making this decision.
- Optimize Tr by reducing the amount of information sent on the network.
You can reduce the network serialization/deserialization overhead by using a custom serialization approach.
You can also reduce the size of the objects returned (and thus the network transmission time) simply by optimizing your object design to not include unnecessary fields. You might also be able to use approaches like a two-level cache to improve both the remote cache hit rate and the retrieval rate.
- Td is amenable to optimization by using standard database tuning techniques.
You don't want to forget these as part of your overall application tuning process.
Choosing preloading vs. load-on-demand
eXtreme Scale enables much larger cache capacities than in the past. Memory-based caches of between 70 and 140 GB are routine for eXtreme Scale users. This is achieved by aggregating memory from many JVMs that together form the global cache. This also means that smaller caches can be distributed over many JVMs, reducing the amount of memory per JVM than before when each JVM needed to cache everything. As a rule, eXtreme Scale users are expected to use less memory per JVM than with a conventional cache.
That said, you should only use as much memory as required. A working set is defined as the minimal set of results that will be accessed by the application within a particular period of time so that the application can work efficiently. The size and composition of the working set is determined by the design of the application; in a batch processing application that repeats many operations, the working set might be larger (and longer lived) than in an online application that does not have an easily predictable access pattern.
If you can identify a working set ahead of time and it can fit in the available memory, then the simplest strategy is often to preload the working set. This is especially true if the size of the table brought into the working set is so small that the overall time spent loading the table item-by-item is significantly larger than the time spent loading the table all at once.
If you cannot identify a working set ahead of time, then a lazy load is the next best option for filling a cache. The assumption on a lazy-load strategy is that once a piece of data has been loaded into the cache it will likely be used again. eXtreme Scale supports lazy load directly through its loader facility. A variant of this is employing a predictive loading strategy that loads related data whenever there is a request against a particular piece of data. For example, if a cache receives a request for customer data based on a particular customer number that is not currently in the cache, then you might reasonably predict that the customer account cache might also benefit from pre-population with account data belonging to that customer.
You should note that a lazily loaded cache is unsuitable for queries because of a necessary fact about caches in general (whether eXtreme Scale or another type): You can execute queries only against a cache that is complete (has the full set of data). If the cache is not complete, you need to go back to the database to perform the query instead.
If you go to the trouble to preload a set of data, it should be replicated to avoid having to re-load it on a failure. eXtreme Scale also supports replication of lazy-load data for resiliency. This is valuable if:
- The data changes infrequently relative to the request volume. For example, in an eCommerce site, popular items might be retrieved thousands of times per hour, but the merchant might update its catalog only once a day.
- If the request volume for the data is high overall, replicating or distributing the data potentially reduces contention.
- If access to the source database is unreliable, striving for resiliency in the cache layer might improve overall stability for read-intensive applications.
Not all eXtreme Scale best practices can be derived from the caching equation, however. There are a number of elements in the development of a eXtreme Scale solution that deal with issues of data retrieval, data placement, and other aspects that also need to be considered.
Choosing the right way to find your data
When designing a grid, you need to choose your partition key carefully. In order to get efficient access to data sizes >~1 GB, partitioning should be done along a reasonable key. If an object will be looked up by two or more keys, the most reasonable key that you partition by would be the most commonly used key. For look-ups using other keys, consider using a global reverse index.
A global reverse index is simply a design where you create a map whose key is the search term, and the value is the list of keys containing an attribute with that search term. Thus, an index lookup results in a Map.get(value) returning the list of keys. The list of keys can then use WXSUtils.getAll (a helper library for eXtreme Scale provided as source code, which includes many helpful routines for common tasks) to bulk fetch the results quickly. You now have a better solution. The throughput of this system is much better than a parallel search implementation. Each index lookup results in one RPC to exactly one server. Therefore, one server can do N of those look ups. M servers can do M * N lookups, and so now you have a better response time as well as linear scaling on index lookups from a throughput point of view.
A final case, which should only be considered when a reverse index cannot be applied for some reason or complicates your design, is to use ObjectGrid queries to locate your data. In this case, you should definitely improve the performance of the queries by using appropriate query indexes (next).
Just as in a relational database, eXtreme Scale supports the use of indices to improve the speed of queries. An index is named the same as the corresponding indexed attribute and is always a MapRangeIndex index type. Each index can be specified using the @index annotation in an Entity class or by using the HashIndex plug-in configuration in an ObjectGrid descriptor XML file. Listing 1 shows how to specify an index configuration in an objectGrid.xml file.
Listing 1. Enabling index in objectgrid.xml
<bean id="MapIndexPlugin"
className="com.ibm.websphere.objectgrid.plugins.index.HashIndex">
<property name="Name" type="java.lang.String" value="SMTRSET"
description="index name" />
<property name="RangeIndex"
type="boolean" value="true" description="true for MapRangeIndex" />
<property name="AttributeName" type="java.lang.String"
value="SMTRSET" description="attribute name" />
</bean>
To show the impact of applying indices, we have performed some tests on non-primary-key query performance with non-indexed queries, indexed queries, and MapRangeIndex queries to a grid containing about 680,000 objects that were stored in single partition with ObjectGrid 6.1.0.3. In this test, the number objects returned in either case is 10. (This test was performed on an Intel Core Duo T7700 (2.40 GHz) with 2GByte memory, JVM Heap set to 768 MB, and an HDD of 100GB, 7200rpm.)
In this test, we created a single entity named OgisCustomer, which has four member attributes including the primary key (SRCSEQ). One of the member attributes (SMTRSET) was specified to have an index as shown in the ObjectGrid.xml above. Listing 2 shows the entity.xml file describing the entity.
Listing 2. entity.xml
<entity class-name="sample.entity.OgisCustomer" name="OgisCustomer" access="FIELD" schemaRoot="true" > <description>OGIS CUSTOMER Class</description> <attributes> <id name="SRECSEQ"/> <basic name="SMTRSET"/> <basic name="SGASSYOKY"/> <basic name="SSHRKY"/> </attributes> </entity>
Our EntityManager query performance experiment demonstrates that, in this case, you can achieve a result that is almost 2000 times faster just by adding an index configuration.
| Query type | Performance result (msec) |
|---|---|
| Non-indexed query | 20414 |
| Indexed query | 10 |
| MapRangeIndex query | 15 |
The best practices presented so far have generally been those that improve the performance of your eXtreme Scale applications. However, there are other best practices that also have to do with resiliency of the resulting application as a whole.
The simplest question to consider in your application is if grid resiliency is even an issue in your application. To understand this, you have to consider the value of the data in your grid. After all, in most grids, the grid is a cache, and not the "system of record." Thus, it is always possible to restore the values in a cache if the cache lost. The problem comes when the cost of recreating the cache (in time or CPU) is so high that the application cannot meet its service level agreements when the cache fails. This leads to our next principle:
If data in the cache is worth preloading, then it is also worth creating a replica of the data in the cache.
While this isn't the only case when it is worth creating a replica, this is certainly a primary case. Saving yourself the time and effort in trying to recreate the cache should be a design goal when preloading is being considered.
The other factor here is that many users use a grid because the database cannot keep up with the load. If the parts of the grid were cycled for routine maintenance, then this would result in some cached data being lost if there was no replication. The loss of this data might cause the database to become overloaded, as the cache is no longer acting as a buffer for that subset of the data. Thus, systems in which the cache buffers the database from excessive load typically require replication to avoid these scenarios.
In general, eXtreme Scale will not place a primary and replica shard on JVMs with the same IP address. But this does not necessarily mean it will ensure high available in every case, especially in blade environments. If you have two different blade chassis, eXtreme Scale.s zone capability enables you to place the primary and replica shards in different chassis. You can start a eXtreme Scale server with the zone feature enabled in either an IBM WebSphere Virtual Enterprise or a non-WebSphere Virtual Enterprise environment. In addition to that, if your eXtreme Scale application is running on IBM WAS Network Deployment, you can make it more highly available by specifying zone metadata in the objectGridDeployment configuration file.
There are several ways of enabling zones that are described in the eXtreme Scale wiki, but in any case you will have to explicitly specify <zone name>. The association between physical nodes and zone is required to conform to the naming convention ReplicationZoneZONENAME. If your eXtreme Scale is installed in a WAS or WebSphere Virtual Enterprise cell, ZONENAME has to be exactly the same name as the NodeGroup specified in the cell.
In Listing 3, primary and replica shards are placed in two node groups, XNodeG and YNodeG, respectively. In the case of two blade chassis, each node group should be specified on each blade. (This rule is fully applicable to WebSphere Virtual Enterprise as well.)
Listing 3. Shard placement using zones
<?xml version="1.0" encoding="UTF-8"?>
<deploymentPolicy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://ibm.com/ws/objectgrid/deploymentPolicy
../deploymentPolicy.xsd"
xmlns="http://ibm.com/ws/objectgrid/deploymentPolicy">
<objectgridDeployment objectgridName="LDAP_OBJECT_GRID" >
<mapSet name="mapSet1" numberOfPartitions="10" minSyncReplicas="0"
maxSyncReplicas="0" maxAsyncReplicas="1" developmentMode="false"
numInitialContainers="2"
> <map ref="PEOPLE_USER_TYPE_MAP" />
<map ref="SPECIAL_USER_TYPE_MAP" /> <map ref="ORG_GROUP_TYPE_MAP" />
<map ref="BIZ_GROUP_TYPE_MAP" />
<zoneMetadata> <shardMapping shard="P" zoneRuleRef="stripeZone"/>
<shardMapping shard="A" zoneRuleRef="stripeZone"/>
<zoneRule name="stripeZone" exclusivePlacement="true" >
<zone name="ReplicationZoneXNodeG" />
<zone name="ReplicationZoneYNodeG" />
</zoneRule> </zoneMetadata>
</mapSet>
</objectgridDeployment>
</deploymentPolicy
This article examined a number of different best practices for improving
the performance and resiliency of your IBM WebSphere Extreme Scale
applications, and principles to help you better understand the WebSphere
eXtreme Scale product. This information should help you in developing and optimizing your own
eXtreme Scale applications, and help you avoid headaches and
missteps in adopting the product in your environment.
- eXtreme Scale product information
- ObjectGrid cache scenarios
- eXtreme Scale wiki
- eXtreme Scale Information Center
- IBM developerWorks WebSphere
- eXtreme Scale trial download