Using IBM Rational Performance Tester: Application Monitoring Part 2, Enabling real-time monitoring
Real-time application monitoring enables IBM® Rational® Performance Tester to take a preventive approach to isolating bottlenecks in applications during the development and test phases of software development. This approach is advantageous because it can identify problems before the application is deployed into the production environment, which reduces the number of critical problems that could arise soon after the application is released. Alternatively, you can use real-time application monitoring to validate the performance of an application after it has been patched by the development team.
Real-time application monitoring in Rational Performance Tester is enabled by using the data collection infrastructure (DCI). The role of the DCI is to transform and forward to the client the Application Response Measurement (ARM) standard events that are reported to the IBM® Tivoli® ARM engine by an ARM-instrumented application (see Figure 1).

To understand the architecture, it helps to consider the flow of a business transaction through the environment:
- The DCI located on the machine where the root (or edge) transaction will be executed must be started for monitoring. For example, executing an HTTP request for
http://ibm.com/PlantsByWebSphereindicates that the application PlantsByWebSphere has to be instrumented and that a DCI is installed on the machine located at ibm.com. - A client invokes an HTTP transaction involving an application that is ARM-instrumented. We can use either of these clients:
- Rational Performance Tester: Behaves similarly to a browser by executing HTTP requests for each page in the test. When response time breakdown (RTB) is enabled, the Rational Performance Tester client adds the ARM_CORRELATOR header attribute to the request, which enables the DCI to monitor the transaction. This client automatically establishes a connection to the DCI on the machine where the root transaction will be executed.
- Internet browser: Executes HTTP requests for a selected URL. You must manually establish a connection to the DCI on the machine where the root transaction will be executed.
- As the transaction invokes the application that is operating in the execution environment, the instrumentation code (or probes) will execute (read Part 1 for more about probes). These probes initiate ARM transactions that are monitored by the Tivoli ARM engine.
- The IBM® Performance Optimization Toolkit (hereafter, toolkit) agent is a Java™ technology-based application that implements the ARM plug-in interface provided by Tivoli for registering third-party applications with the Tivoli ARM engine. As ARM events are created and reported to the engine, they are also reported to the toolkit agent. The events are collected and organized into a transactional hierarchy, from the root transaction to all of the subtransactions. This hierarchy is then converted into a set of events that are modeled after the Eclipse Test and Performance Tools Platform (TPTP) trace model format. The set of events is then sent to the presentation system.
- The target and presentation systems communicate with each other by using the IBM® Rational® Agent Controller. This component integrates with Eclipse TPTP, which Rational Performance Tester is based on. The component also manages the toolkit agent (starts and stops monitoring).
Each ARM event reported to the DCI contains information about the start time and completion time of the ARM transaction, in addition to metadata. The timing information helps to compute metrics that help an analyst determine whether a performance problem is present. The metadata helps to indicate the context of the transaction in the entire transaction hierarchy and the type of transaction being invoked.
Within the execution environment, there are two agents that implement the Java profiling interface:
- Just-in-Time Instrumentation (JITI), the IBM® Tivoli® Java™ 2 Platform, Enterprise Edition (J2EE™) monitoring component
- The Java™ Virtual Machine (JVM™). API called the JVM Profiling Interface, sometimes referred to as the JVMPI
Part 1 of this series discusses JITI. The JVMPI agent (or Java profiling agent) used in Eclipse TPTP has been enhanced in Rational Performance Tester to include features such as security and support for Citrix and SAP integration.
When you set up a profiling configuration to monitor an application, you choose an analysis type to specify the type of data that you want to collect. Depending on the analysis type that you choose, the data collection infrastructure uses one or both agents to collect the data. The agent is selected automatically to correspond with your profiling settings. These are the two collection agents:
-
The ARM agent is most useful in these scenarios:
- When analyzing J2EE application performance and application failures, especially in distributed applications where event correlation is essential.
- When profiling ARM-instrumented applications. For example, if you ARM-enable a database, you could watch a transaction go from your application into the database, see all of the processing in the database, and then see the response return, all displayed in one sequence diagram.
-
The JVMPI agent is most useful in these situations:
- When performing memory analysis (for example, leak analysis).
- When examining object interactions (for example, for the UML2 Object Interactions view). In most situations, class interaction analysis (available with the ARM agent) is enough to help find problems, but occasionally we will need to do further profiling at the object level.
- When profiling non-J2EE applications, such as Java™ 2 Platform, Standard Edition (J2SE™) or Java™ 2 Platform, Micro Edition (J2ME™) applications.
Each agent offers its own set of data collection features, as Table 1 shows.
Table 1. Comparison of data collection features between ARM and JVMPI agents
Table 1. Table title
| Feature | ARM agent | JVMPI agent |
|---|---|---|
| Provides the ability to correlate remote calls between processes and hosts | Yes | No |
| Affects application performance when the agent runs in profiling mode | Small effect | Large effect |
| Offers filtering mechanisms | By J2EE component type (for example servlet or JDBC), host URL | By package, class, and method |
| Collects memory information and object interactions (for the UML2 Object Interactions view) | No | Yes |
With two agents that can potentially be used in parallel, the load on the execution environment can increase dramatically. As a result, the profiling interface (PI) virtualizer (the virt.dll file on Windows systems) was added. This component is the only agent that the JVM recognizes. When the PI virtualizer receives events from the JVM, it broadcasts those events to every JVMPI-based agent that it detects. In this case, those agents are JITI and the Java profiling agent.
To use the Java profiling agent, we need to add this Virtual Machine (VM) argument:
-XrunpiAgent:server=enabled |
When the PI virtualizer is present, use this VM argument:
-Xrunvirt:agent=jvmpi:C:\PROGRA~1\IBM\DCI\rpa_prod\TIVOLI~1\ app\instrument\61\appServers\server1_100\config\jiti.properties,agent= piAgent:server=enabled |
Notice that the argument specifies both agents that are to receive the broadcasted events. This configuration can be found in the same configuration files as the instrumentation, as previously discussed.
Data collection infrastructure
To collect end-to-end transaction information, the DCI must be installed on all systems involved in the path of a transaction, as shown in Figure 2 (for more on end-to-end transactions, see Part 1). This requirement is present because the ARM correlator goes across the physical machine boundary. As a result, when an ARM correlator is sent from one machine to another, the DCI on the machine receiving the ARM correlator has to execute special processing that is known as dynamic discovery.
Figure 2. Data collection infrastructure for a distributed environment
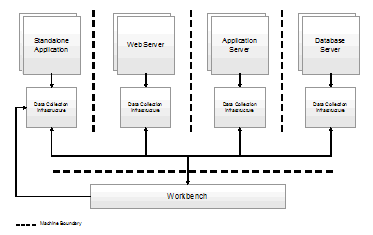
The purpose of the dynamic discovery process is to automatically have the client workbench attach and begin monitoring the DCI located on the machine where the remote method is being invoked. This is required because, when a transaction is first executed, the client is attached only to the first machine in the transaction's path. Therefore, rather than expecting us to know all of the physical machines that would be involved in any given transaction and to manually attach to each one, this process is automated.
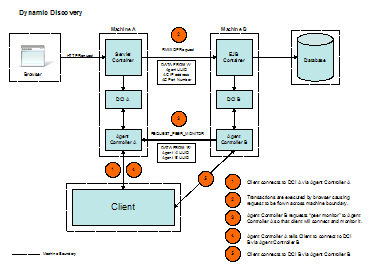
This process is made possible by sending information in the ARM correlator about the Agent Controller on the caller machine. Therefore, when the RMI-IIOP transaction is invoked, an ARM event is sent to the DCI at this newly discovered machine. (RMI-IIOP stands for Remote Method Invocation [RMI] Internet Inter-ORB Protocol [IIOP]). Specifically, this RMI-IIOP transaction is detected by the IBM toolkit agent. At that moment, the toolkit agent invokes a peer request to the Agent Controller at the caller machine by using the Agent Controller at the call-recipient machine. This request asks for the known client attached at the caller machine to also establish a connection to the newly discovered machine (see Figure 3). In turn, transactional information from the call-recipient machine flows to the client for analysis.
Note:
The security feature on the Agent Controller must be disabled for dynamic discovery to work. When this article was initially published (May 2007), the security feature was not yet fully functional across distributed environments. To disable it or verify that it is disabled, execute the SetConfig script located in the bin directory of the Agent Controller installation.
Figure 3. Dynamic discovery process
For the most part, the focus here has been on collecting transactional information from application servers. However, there are a few database systems, such as IBM® DB2®, that include ARM instrumentation in the product. Enabling this ARM instrumentation allows deeper monitoring of end-to-end transaction monitoring. For example, rather than just being able to know that a transaction has used Java DataBase Connectivity™ (JDBC™) to invoke an SQL transaction from a Java™ application, analysts can get the transaction information from within the database for that specific query. This information greatly helps to narrow down whether a problem is caused by a Java application or the software solution's database.
- The first step to enable end-to-end transaction monitoring within the database is simply to following the database product's instructions to enable this ARM instrumentation.
- The second step is to install the DCI on the same machine where the database executes. Starting the DCI in the monitoring mode will allow database transaction information to be sent to the client.
- Furthermore, you can configure the environment to collect the exact SQL query that is running on a database. To enable this configuration, disable database privacy and security for the local DCI. The instructions for enabling the collection of SQL statements are as follows (do this only after you have already instrumented the application server):
- Shut down the application server and DCI.
- Navigate to this directory:
<DCI_INSTALL_DIRECTORY>/rpa_prod/tivoli_comp/app/instrument/61/appServers/<servername>/config - Open the monitoringApplication.properties file.
- Add the following two lines:
tmtp.isPrivacyEnabled=false
tmtp.isSecurityEnabled=false - Start monitoring for the DCI.
- Start the application server.
- Initiate data collection by invoking transactions.
Configuring Rational Performance Tester
We can use the Response Time breakdown feature in Rational Performance Tester to see statistics on any page element that were captured while you were running a performance test or performance schedule. Response time breakdown shows how much time was spent in each part of the system under test. The Response Time Breakdown view is associated with a page element (URL) from a particular execution of a test or schedule. This shows the inside of the system under test, because the data collection mechanisms are on the systems under test, not the load drivers.
You will typically capture the response time breakdown in real time (test) environments during development, rather than in production environments. To capture response time breakdown data, enable it in a test or schedule, and then specify the amount of data to be captured.
To configure a performance test:
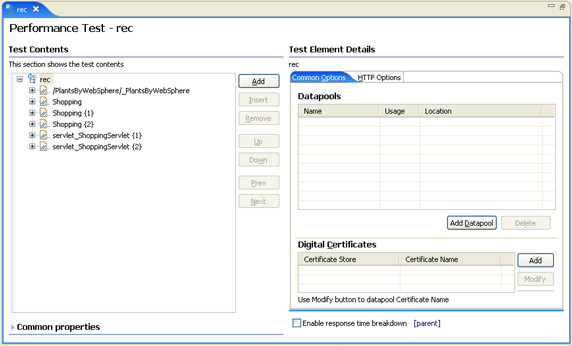
- Use the check box in the Test Element Details section of the Performance Test Editor (see Figure 4).
- If the top-most node in the Test Contents tree is selected (that is the performance test itself), then selecting Enable response time breakdown from Test Element Details causes application monitoring on every page and page element in the performance test.
- If only a specific page or page element requires application monitoring, then select it from the Test Contents tree. This action displays the selected item's configuration in Test Element Details, from which you can enable response time breakdown.
Figure 4. Response time breakdown configuration in a performance test
To configure a performance schedule:
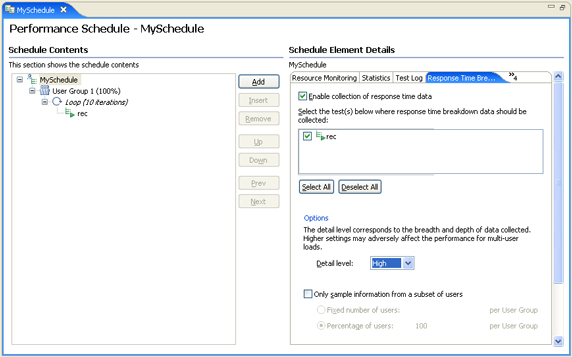
- Under Schedule Element Details, select the Response Time Breakdown tab and select Enable collection of response time data. This activates the test list and Options.
- After enabling response time breakdown data collection, set logging detail levels (see Figure 5).
Figure 5. Response time breakdown configuration in a performance schedule
The Response Time Breakdown page allows us to set the type of data that you see during a run, the sampling rate for that data, and whether data is collected from all users or a representative sample.
- Enable collection of response time data: Select this option to activate response time breakdown collection. This shows you the response time breakdown for each page element.
- Detail level: Select Low or Medium to limit the amount of data collected. The higher the detail level, the deeper the transaction is traced and the more context data is collected. For example, at Low, only surface-level transactions are monitored. In a J2EE-based application, this includes Servlets. As the detail level is increased, collection for enterprise JavaBeans™ (EJBs) and RMI aspects of a J2EE application are collected.
- Only sample information from a subset of users: If you set the detail level to High or Medium, set a sampling rate to prevent the log from getting too large.
- Fixed number of users: The number that you select is sampled from each user group. Unless you have specific reasons to collect data from multiple users, select Fixed number of users and specify one user per user group.
- Percentage of users: The percentage that you select is sampled from each user group, but at least one user is sampled from each user group.
Enabling response time breakdown in a performance test will not affect the response time breakdown in any performance schedule that is referencing that test. The reverse is true, too: Enabling response time breakdown in a performance schedule will not affect the response time breakdown configuration in a performance test. The test and the schedule are separate entities.
After making the appropriate response time breakdown configuration, execute the test or schedule to initiate application monitoring during the load test. This action can be executed by using the Run menu to launch the test or schedule. Response time breakdown can be exploited only when executing a test or schedule from the GUI. If a test or schedule is configured for response time breakdown, and then executed by using the command line, response time breakdown data will not be collected.
Profiling for real-time observation
Within a development environment, you can collect response time breakdown data for analysis several ways:
- We can profile (collect response time breakdown data from) a running distributed J2EE application in a development environment.
- We can also profile applications as they are launched by automated testing tools, which frees us from having to repeatedly run the problem scenario and can simulate the load on the application.
- We can profile a Web service component of an application by using IBM® WebSphere® Application Server.
- We can profile non-J2EE applications or applications in any other language supported by the ARM standard.
To collect real-time response time breakdown data, make sure that you comply with these requirements:
- The data collection infrastructure must be installed, configured, and running on all computers from which data is to be collected. See the installation guide for more information.
- The Agent Controller (part of the data collection infrastructure) port on all involved computers must be set to the default (10002).
- The application system must not involve communication between networks that use internal IP addresses and network address translation.
Before profiling or collecting real-time response time breakdown data from an application system, establish a connection to the data collection infrastructure. First, identify the server that will process the initial transaction request. More specifically, identify the first application server that the transaction request reaches.
Note:
You do not have to explicitly create a connection to every computer involved in the distributed application that you want to monitor. Through the dynamic discovery process, the workbench automatically connects to each computer as the transaction flows to it.
To initiate real-time data collection:
- Select Run > Profile, or use the toolbar button to open the Launch Configuration dialog (see Figure 6).
- This profile action asks us to switch into the Rational Performance Tester Profile and Logging perspective. This perspective enables profiling tools and has a different layout of the views on the workbench.
Figure 6. Profile launch configuration action
The Profile Configuration dialog allows us to create, manage, and run configurations for real-time application monitoring. Use this method for monitoring J2EE, non-J2EE, and Web service applications that do not have automated application monitoring, which is the situation with a performance test or schedule.
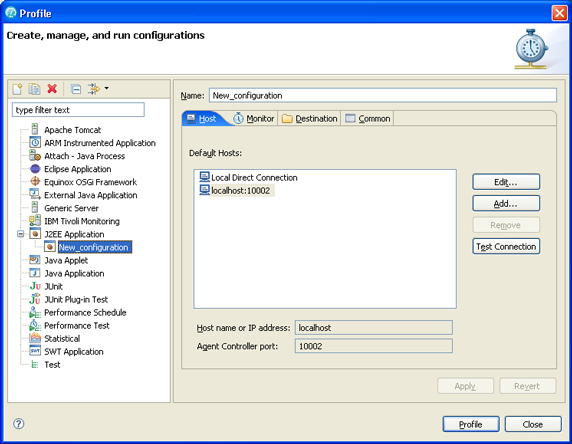
- In the Launch Configuration dialog, select J2EE Application and click New (see Figure 7). If your application is not running on a J2EE application server, but is instrumented manually for the ARM standard, select ARM Instrumented Application instead.
- On the Host page, select the host for the Agent Controller. If the host we need is not on the list, click Add and provide the host name and port number.
- Test the connection before proceeding.
Figure 7. Profile launch configuration for J2EE Application: Host page
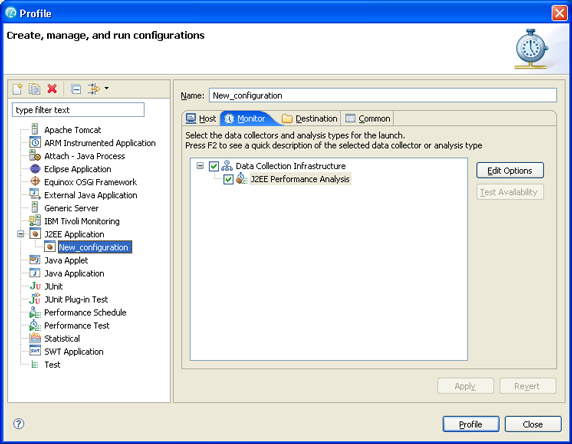
- On the Monitor page, for Analysis type, select either J2EE Performance Analysis or, if you are profiling by using the ARM-instrumented application launch configuration, ARM Performance Analysis (see Figure 8).
- If you want to customize the profiling settings and filters, click Edit Options.
Figure 8. Profile launch configuration for J2EE Application: Monitor page
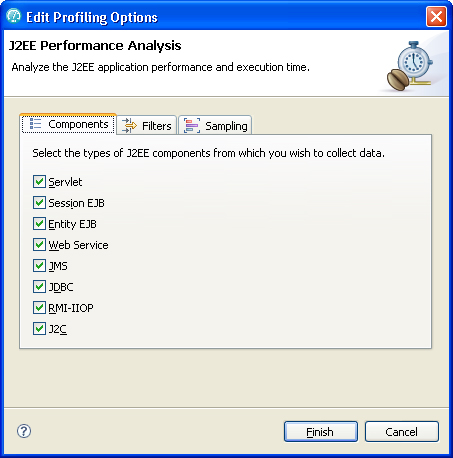
- On the Components page, select the types of J2EE components from which you want to collect data (Figure 9).
Figure 9. J2EE performance analysis components to monitor
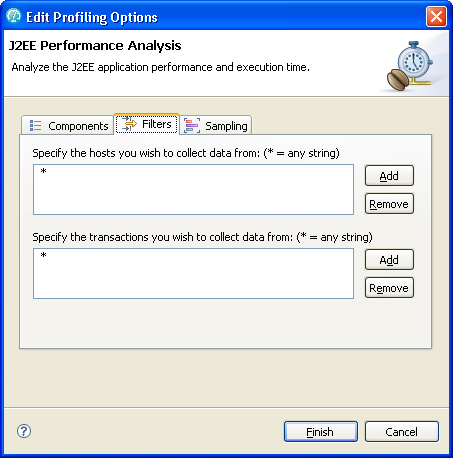
- On the Filters page, specify the hosts and transactions that you want to monitor. The filters indicate the types of data that you do want to collect. That is, they include, rather than exclude (see Figure 10).
Figure 10. J2EE performance analysis filters to apply
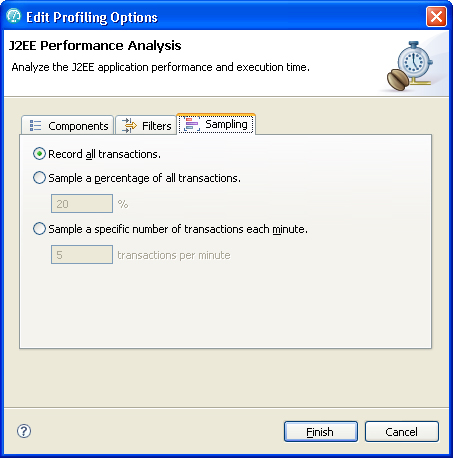
- On the Sampling page, you can limit the amount of data being collected by specifying either a fixed percentage or a fixed rate of all the data to collect (Figure 11).
- Sample a percentage of all transactions: The profiler alternates between collecting and discarding calls. For example, with a setting of 25%, the first call is collected, the next three are not.
- Sample a specific number of transactions each minute: The first n calls (where n is the specified value) are collected, and nothing else will be collected during that minute. Thus, we will never receive data for more than n calls in any given minute.
Figure 11. J2EE Performance Analysis sampling options
We can set up filters and sampling to specify how much data is collected. A filter specifies which transactions you want to collect data from. Sampling specifies what subset percentage or number of transactions that you want to collect data from. Filters and sampling work at the root (or edge) transaction level. A root transaction is one that is not a subtransaction of any other (at least, as far as the data collection is concerned).
Thus, when using a browser to access a Web application, a root transaction is a URL request when it first hits the server. The filtering and sampling apply at this level. That is, if you enter a transaction filter, it acts on the URL; whereas, if you sample, it will collect only some of the URLs and discard others. It is all or nothing; it does not sample parts of the URL transactions.
If the Web application resides on multiple servers, some instrumented and some not, only data about instrumented servers will be included. For example, if the user accesses the application through Server A, which is not instrumented, and Server A uses a method call to contact Server B, which is instrumented, then the method call is the root transaction. Filtering will not work, because it uses URLs, not method names, to filter.
Also, if you are using performance tests or schedules to generate profiling data, then the root transaction takes place on the first application response measurement (ARM) instrumented test element to be run. If the entire test or schedule is ARM-instrumented (that is, Enable response time breakdown is selected for the top-level test or schedule element), there will only be one root transaction; therefore, filtering and sampling will be ineffective.
- Before you start monitoring, bring the application to the state that it was in immediately before the performance problem trigger. For example, if an action on a particular Web page is slow, navigate to that page.
- Click Profile. The connected agent and its host and process will be shown in the Profiling Monitor view (Figure 9). Depending on your profiling configuration, more than one agent may be shown if operating in a distributed environment.
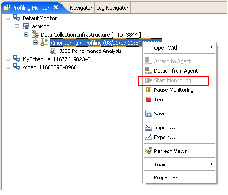
- Start the monitoring agent by selecting the agent and Start Monitoring (Figure 12). If there is more than one agent for this profile configuration, start monitoring each of the agents. Any activity in the application that fits the profiling settings that you specified earlier will now be recorded. The agent state will change from <attached> to <monitoring>, and then to <monitoring...collecting> whenever data is being received from the agent.
Figure 12. Profiling monitor for J2EE performance analysis
- In the application, perform the steps required to trigger the performance problem.
- Stop monitoring the agent by selecting Stop Monitoring from the pop-up menu. For best results, detach from the agent so that other users can profile the system. Select the agent and Detach in its pop-up menu. Repeat this step for each agent involved in collecting the data.
Finding the causes of performance problems
Application failures can be caused by a number of coding problems, each of which investigate by using the data collection and analysis techniques and tools available. Typical application failures include stoppages, when the application unexpectedly terminates, and lockups, when the application becomes unresponsive as it, for example, enters an infinite loop or waits for an event that will never happen.
In the case of a lockup, you might not see any actual errors logged. Use interaction diagrams, statistical views, and thread analysis tools to find the problem. For example, if the problem is an endless loop, the UML sequence diagrams show you repeating sequences of calls, and statistical tables show methods that take a long time. If the problem is a deadlock, thread analysis tools will show that threads that you expect to be working are actually waiting for something that is never going to happen.
After you have collected response time breakdown data, you can analyze the results in the profiling tools to identify exactly what part of the code is causing the problem. Generally, you first narrow it down to which component is causing the problem (which application on which server). Then you can continue narrowing down to determine which package, class, and, finally, which method is causing the problem. When you know which method the problem is in, you can go directly to the source code to fix it.
We can view response time breakdown data in the Test perspective or in the Profiling and Logging perspective if a performance test or performance schedule is executed with response time breakdown. Otherwise, if you manually launched the J2EE application or ARM-instrumented application launch configuration, then the data collected is viewable only in the Profile and Logging perspective.
Tracking such problems can involve trial-and-error as you collect and analyze data in various ways. You might find your own way that works best.
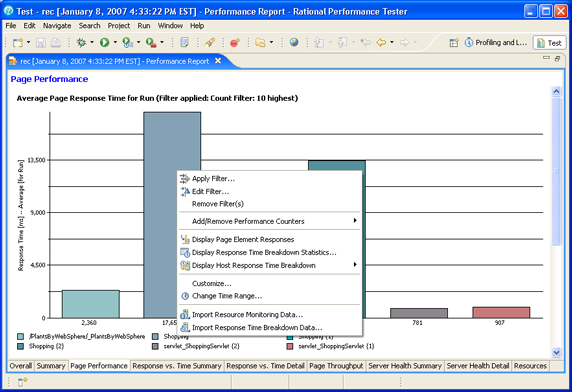
Rational Performance Tester report analysis
After a performance test or performance schedule has completed execution, the default Rational Performance Tester report will be displayed to the user. There are two mechanisms that can be used to analyze response time breakdown data (Figure 13).
- Response time breakdown statistics: A tabular format of a transaction and its subtransaction response time for a particular page or page element.
- Interactive reports: A graphical drill-down process for decomposing a transaction.
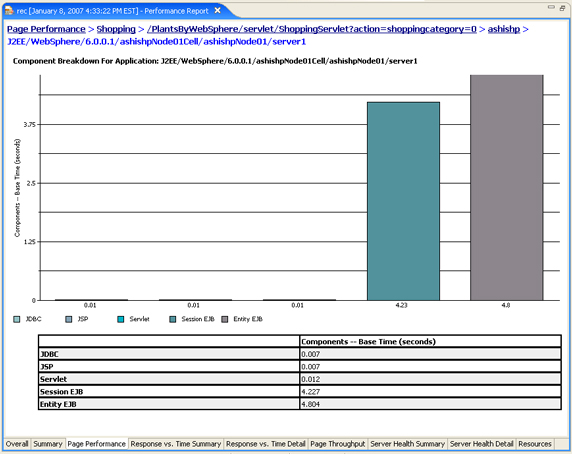
Figure 13. Sample of a Page Performance report
In these two reporting mechanisms, this hierarchy provides a structure for organizing and categorizing a transaction and its subtransactions:
- Host: The physical machine where the application is executing the method invocation, in context.
- Application: The containing application where the method invocation was observed. Typically, for J2EE applications, this is an application server.
- Application component: A categorization label, or metadata, given to the method invocation, in context. For J2EE applications, a method invocation may be labeled as Session EJB, which is also the application component.
- Package: The package where the class and method invocation, in context, belong to.
- Class: The class where the method invocation, in context, belong to.
- Method: An invocation of a specific method
Analysis using the Statistics view
Selecting the Display Response Time Breakdown Statistics option from the Page Performance report displays a tabular format of a transaction and its subtransaction response time for a particular page or page element.
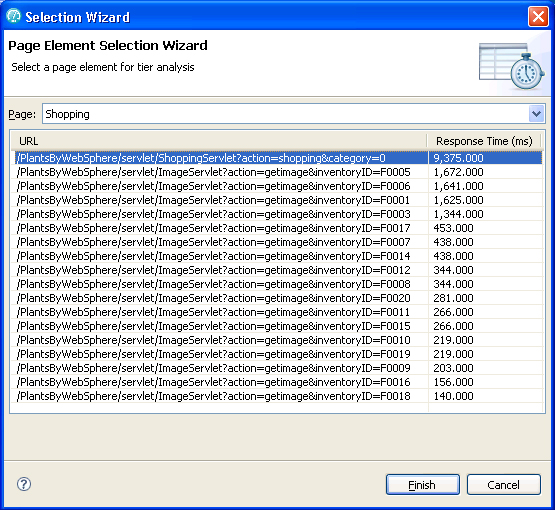
First, a Page Element Selection Wizard (Figure 14) is presented so that you can pick a particular page element to view its transaction decomposition. All page elements are listed in descending order from the amount of response time for each element.
Figure 14. Page Element Selection Wizard
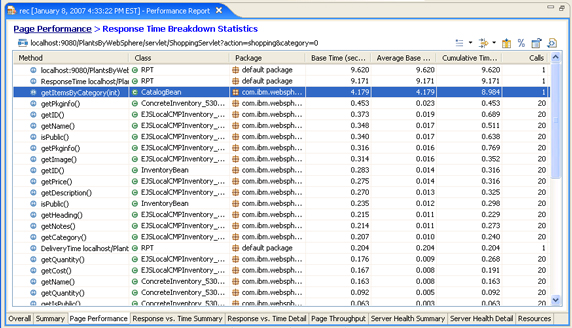
The top view of the Response Time Breakdown Statistics view displays an aggregation of all of the subtransactions for the selected page element (Figure 15). There are various tools available in this view that can be helpful when analyzing a performance problem.
- Use the navigation information in the upper-left corner to navigate back to previous views.
- Use the toolbar in the upper-right corner to toggle between tree and simple layouts, add filters, select which columns are displayed, jump to source code, toggle between percentages and absolute values, and export the table to CSV, HTML, or XML format.
Figure 15. Response Time Breakdown Statistics view
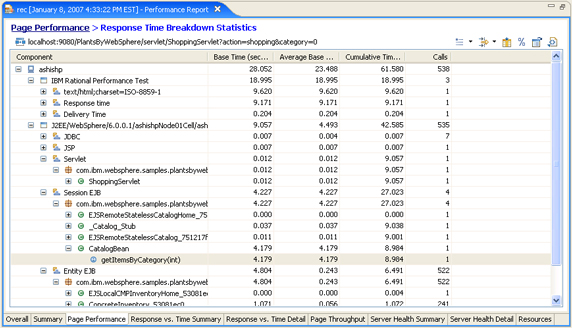
The directory (tree) layout also shows this hierarchy (Figure 16):
- Host
- Application
- Component
- Package
- Class
- Method
Each host is a tier in your enterprise environment. Within each host, there are tiers of applications. Within each application, there are tiers of components, and so on.
The tree layout (Figure 16) helps you identify which tier has the slowest response time.
Figure 16. Response Time Breakdown Statistics: Tree layout
Use the first icon in the toolbar in the upper-right corner to toggle between tree and simple layouts. The default layout is the simple layout.
The simple layout is a flattened version of the tree layout. Use this layout if you want to see all of the methods without seeing the relationships shown in the tree layout. The simple layout provides a quick and easy way to see the slowest or fastest methods.
Click a column heading to sort the table by that column. Drag the columns to change the order in which they are displayed. Except for the first column in the tree layout, all of the columns are moveable. The exact URL of the selected page element is displayed above the table.
Four results are displayed for each object: Base Time, Average Base Time, Cumulative Time, and Calls. All times are in seconds. The following list defines the times that you can view:
- Base Time is the time spent inside this object, excluding time spent in other objects that the selected object invokes.
- Average Base Time is the time spent inside this object, excluding time spent in other objects that the selected object invokes, divided by the number of calls.
- Cumulative Time is the time spent inside this object and in other objects that the selected object invokes.
- Calls are the number of times the selected object was invoked by any other object.
Figure 17 shows the toolbar buttons (also shown in Figure 16) that are associated with the following actions:
Figure 17. toolbar buttons
![]()
- Click the Filter icon (second from left in the toolbar) to open the Filters window. There, you can add, edit, or remove filters applied to the displayed results.
- Click the Columns icon (third) to open the Select Columns page. There, you can select which columns are displayed in the table. These settings are saved with the current workspace and are applied to all response time breakdown tables in the workspace.
- Click the Percentage icon (fourth) to toggle the display between percentages and absolute values. In the percentage format, the table shows percentages instead of absolute values. The percentage figure represents the percentage of the total of all values for that column.
- Click the Source icon (fifth) to jump to the source code (if available) in your workspace. You must first select a method before clicking the Source button.
- Click the Export icon (last) to open the New Report window. There, you can export the response time breakdown table to CSV, HTML, or XML formats.
- Use the navigation information in the upper-left corner to navigate back to previous views. The navigation is presented in the form of a breadcrumb trail, which make it easy to drill down and drill up from various reports.
In the past, there has been some confusion about the terminology and values computed for delivery time and response time. If you are familiar with performance resting, response time here does not equate to a Rational Performance Tester definition of the term. These definitions apply here, instead:
- Delivery time: Last_Received_Timestamp - First_Received_Timestamp
- Response time: First_Received_Timestamp - First_Sent_Timestamp
When viewing the transaction decomposition for a Graphics Interchange Format (GIF) file, you normally see a very small delivery time (often zero). because the entire data stream for the file arrives in a single packet. However, in a primary request of a page, if the server is taking a long time to respond, you typically see that the server responds with the header relatively quickly, as compared to the remainder of the response. In that case, the response may be broken down across several packets.
Note:
You will always see a delivery time and response time. You may also see transactions marked with the words DNS Lookup and Connect for requests that are of this nature.
Interactive Graphical Analysis
The interactive graphical analysis method involves a graphical drill-down process for decomposing a transaction using the existing Rational Performance Tester reports. If you choose to proceed toward response time breakdown analysis by
selecting Display Page Element Responses (Figure 13), you are presented with a bar chart that shows all of the page element responses for the selected page (Figure 18).
Figure 18. Graphical drill-down reports for Response Time Breakdown
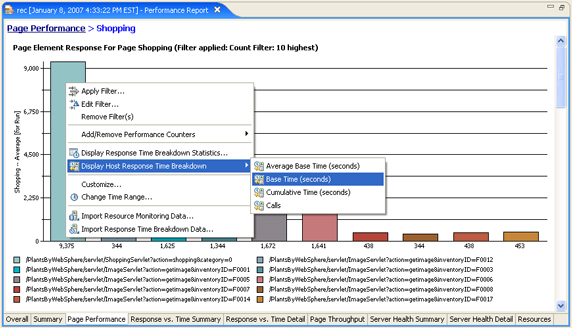
From this page element drill-down report, you can choose to drill down farther into individual host responses, application and application component responses, and package, class, or method invocation responses for a particular element. The right-click context menu on the bar graph displays which drill-down action is available from the current report. For example, if you are viewing the application response time breakdown for a particular transaction, the context menu will display a response time breakdown item for viewing the application components of the selected application (see Figure 19).
At each level in the drill-down process, the breadcrumb path becomes more detailed. This behavior provides an easy way to jump between reports during the analysis process. We can also choose to jump directly to the Response Time Breakdown
Statistics view from any drill-down graph.
Figure 19. Component level drill-down report
Profiling for real-time observation analysis
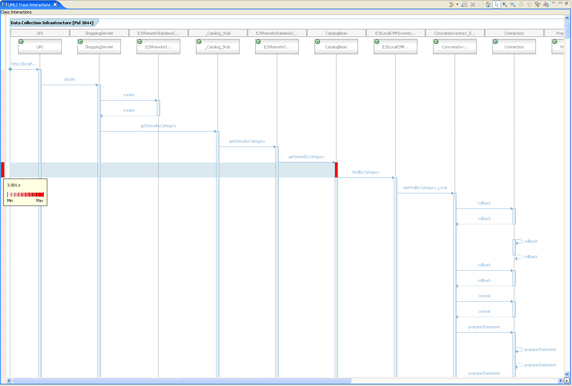
The UML Sequence Diagram view presents a sequence of causal dependent events, where events are defined as method entries and exits, as well as outbound calls and return calls (see Figure 20). Specifically, it presents interactions
between class instances. Those interactions have the form of method calls and call returns. The implementation of the Trace Interaction tool extends that definition to one that generalizes actors of interactions, as well as their means. In other words, the views provided by the tool are able to present not only the interactions of classes and class instances, but also interactions
among threads, processes, and hosts. This extended use of the execution flow notation is motivated by the need to provide a hierarchy of data representation, which is necessary for large-scale, distributed traces.
Figure 20. UML Sequence Diagram view
A view-linking service is available for assisting in correlating application trace events, as shown in the UML Sequence Diagram view and the statistical and log views (see Figure 21). Correlation is computed using timestamps of two events. If an exact match is not found during correlation, the next event with the closest timestamp to the event being correlated is selected, within acceptable
range.
Figure 21. View-linking service between UML Sequence Diagram and statistical or log views
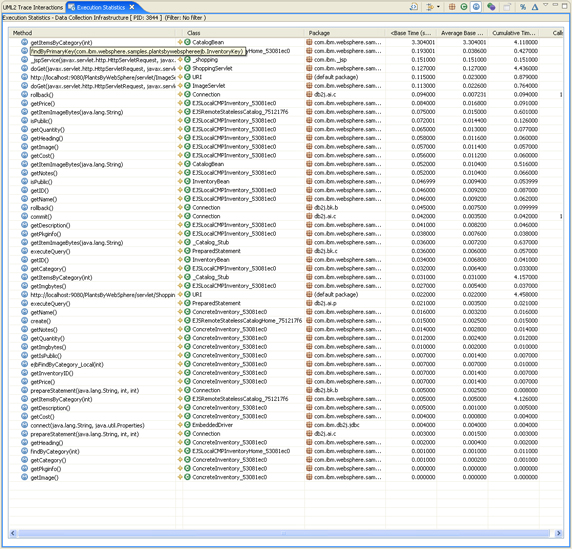
The Execution Statistics view displays statistics about the application execution time (Figure 22). It provides data such as the number of methods called and the amount of time taken to execute every method. Execution statistics are available at the package, class, method, and instance levels.
- Base Time: For any invocation, the base time is the time taken to execute the invocation, excluding the time spent in other methods that were called during the invocation.
- Average Base Time: The base time divided by the number of calls.
- Cumulative Time: For any invocation, the cumulative time is the time taken to execute all methods called from an invocation. If an invocation has no additional method calls, then the cumulative time will be equal to the base time.
- Calls: The number of calls made by a selected method.
Figure 22. Execution Statistics view
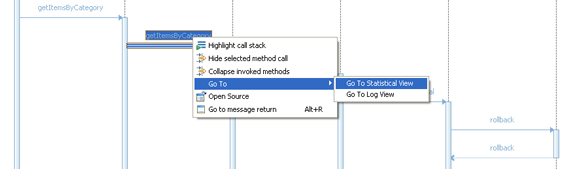
Tip:
Sort the entire list of methods by the Base Time metric. This action forces the method that consumes the most processing time to appear at the top of the list. From there, select the item and use the right-click menu to explore various analysis options. Select an item from the Execution Statistics view, and display the right-click context menu (Figure 23).
Figure 23. Execution Statistics view right-click context menu
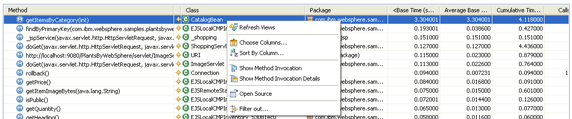
In this menu, there are various actions that you can execute, notably:
- Open Source: Allows us to automatically open the source code associated with the selected package, class, and method combination if the source code is imported into the current workspace.
- Method Invocation Details: Provides statistical data about a selected method, including information about the invoker method and the methods invoked by the selected method. We can open this view on a selected method in any of the profiling views, such as the Method Invocation, Execution Flow, or Execution Statistics views.

The Method Invocation Details view displays:
- Selected method: Shows details, including the number of times that the selected method is called, the class and package information, and the time taken by this method.
- Selected method invoked by: Shows details of each method that calls the selected method, including the number of calls to the selected method and the number of times that the selected method is invoked by the caller.
- Selected method invokes: Shows details of each method invoked by the selected method, including the method name invoked, the number of times the method is invoked, the number of calls from the selected method to the invoked method, package and class information for the invoked method, and the time spent on the invoked method.
This concludes the second of three articles about using Rational Performance Tester for application monitoring. See Resources for links to the other parts of the series and other useful information.
Learn
- See also this author's series of articles on Resource monitoring using IBM Rational Performance Tester on developerWorks Rational.
-
Get an Introduction to IBM Rational Performance Tester V7.0 (IBM developerWorks, January 2007). Along with an overview of what's new, you'll record and execute a basic test to learn more about some of the features.
-
Learn about the IBM Rational software quality management process, best practices, and integrated tools.
-
Work through Hello World: Learn how to discover and analyze performance issues using Rational Performance Tester. Get an overview of Rational Performance Tester in this basic tutorial, which includes practical, hands-on exercises that teach you how to record automated performance tests, use data-driven techniques to ensure randomization, play-back tests, and evaluate real-time performance reports. You'll need to download the free trial version of Rational Performance Tester.
-
Enroll in RT523: Essentials of IBM Rational Performance Tester V7.0 This introductory course focuses on getting started with Rational Performance Tester and practical application of the tool to resolve common performance testing challenges. Testers can build, enhance, and run scripts in a full-function Java Integrated Development Environment (IDE) that integrates with other IBM Rational Software Delivery Platform products. This live instructor-led course takes place online, with hands-on labs and real-time interactions.
-
Read the IBM Tivoli Monitoring V6.1.0 Installation and Setup Guide (First Edition, November 2005), GC32-9407/
-
Read "Administering OMEGAMON Products:" CandleNet Portal, V195, July 2004, Candle Corporation.
-
Consult RSTAT - RFCs 1831, 1832, and 1833 when implementing the RSTAT monitoring component.
-
Learn more about RSTAT on the HP-UX reference page.
-
Study the Eclipse Test and Performance Tools Platform (TPTP) documentation.
-
Visit the IBM Rational Performance Tester area on IBM developerWorks, where we will find technical documentation, how-to articles, product information, and more.
-
Visit the Rational software area on developerWorks for technical resources and best practices for Rational Software Delivery Platform products.
-
Visit the Microsoft Developer Network (MSDN) Performance Monitoring page.
-
Subscribe to the developerWorks Rational zone newsletter. Keep up with developerWorks Rational content. Every other week, you'll receive updates on the latest technical resources and best practices for the Rational Software Delivery Platform.
-
Subscribe to The Rational Edge newsletter for articles on the concepts behind effective software development.
-
Subscribe to the IBM developerWorks newsletter, a weekly update on the best of developerWorks tutorials, articles, downloads, community activities, webcasts and events.
Get products and technologies
-
Get a trial download of Rational Performance Tester.
-
Download a trial version of IBM Rational Performance Tester V7. Choose your language and operating system preferences.
-
Get the
IBM Performance Optimization Toolkit.
-
Download evaluation versions of IBM products, and get your hands on application development tools and middleware products from DB2®, Lotus®, Rational®, Tivoli®, and WebSphere®.
Discuss
-
Participate in the Performance Testing forum on IBM developerWorks.
-
Get involved in developerWorks forums about IBM software.
-
Check out developerWorks
blogs and get involved in the developerWorks community.
With laptop running RPT, heap size is set via Java command-line. Default is 1900M. Default approx max users you can run is around 450. More users than that, we need to set up agent controllers to spread the load.