Define test data
An important step in testing your software is developing useful and comprehensive test data. One proven way to achieve this is to use data partitioning techniques (also called domain analysis).
Data partitioning is an effective way to select useful test values and achieve the best possible test coverage. This topic focuses on the use of data partitioning techniques as they apply to object-oriented systems, specifically those systems that contain complex object-type parameters and external or context-based inputs.
Generally speaking, you can take the following steps to partition your test data:
- Identify the inputs for the software you are testing.
- Define the data partitions.
- Define the equivalence classes that can be used with those data partitions and the actual values used in the equivalence classes.
The examples that are used in this topic are drawn from the JUnit Money application and focus specifically on the equals method in the Money class. The code for this method is shown in the following code listing:
public class Money implements IMoney { private int fAmount private String fCurrency; public boolean equals(Object anObject) { if (isZero()) if (anObject instanceof IMoney) return ((IMoney)anObject).isZero(); if (anObject instanceof Money) { Money aMoney= (Money)anObject; return aMoney.currency().equals(currency()) && amount() == aMoney.amount(); } return false; }
Related concepts
Data sets
Test data tables
Identify the test inputs
The first step in defining test data is to understand what data is used by the component-under-test (CUT). Using the equals method as an example, you can see that this method takes a single argument (anObject) of type Object:
public boolean equals(Object anObject) {
The equals method is an instance method because it is not defined as static. Therefore, in addition to the anObject parameter, the CUT may also use data from the object instance on which the method is invoked.
As such, there are two test parameters that can affect what happens when you invoke the equals method: the object on which the method is invoked (this) and the method argument (anObject). If we call the first parameter a and the method argument (anObject) b, it would be represented in code as a.equals(b). Here you can see that to test the equals method you would vary the data associated with both a and b.
Both of these possible inputs (a and b) are object data types. The first input (a) is always of type Money and can be defined in terms of the fCurrency and fAmount attributes. These defining attributes are the parameters of a public constructor for the Money class. Thus, to vary the first input, you would vary the object's defining attributes (fCurrency and fAmount). You would supply a range of integers, probably trying negative, zero, and positive numbers. Then, you would vary the currency types using valid and invalid currency identifiers.
Because the second input (b) is of the Object data type, virtually any class instance can be passed in as a valid value. You can perform a meaningful comparison if you pass in a Money object; but you can also try passing in data of other data types that make no sense to compare and see how the method responds.
Define data partitions for the input parameters
Data partitions should be defined in such a way as to reveal the greatest number of potential defects. In this example, there are two input parameters, and they are both object data types. The best way to define partitions for an object's parameters is to consider their abstract states. The abstract state of an object is generally defined as a constraint on the values of its attributes. For example, some possible abstract states for the first input parameter (a), would be:
- Positive amount Money
- Negative amount Money
- Currency in USD
- Currency in euros
However, in this case, based on your understanding of what the equals method does, one partition should suffice for the first parameter (a). This is because the return value for this method is probably not directly related to any particular value for this parameter. As a result, you can choose any test values and just create one data partition. Later on, when you define your equivalence classes, you can create diversity in your testing by trying out different values for this parameter.
In the case of the second input parameter (b), it is difficult to define an abstract state because the parameter type of Object is the superclass of all types, and thus virtually any class could be used. In this case, you need to first define data partitions in terms of parameter types. (This would also be true for any parameter whose type is an abstract class or an interface.) For this parameter, you could identify types such as:
- An object of the same type (Money)
- An object of an incompatible type (all other types)
- A null object
Thus, some possible data partitions for input parameter b are Same Type, Other, and Null.
Next, you could subdivide the data partitions for the second input parameter (b). For incompatible types or null objects, there is probably no need to subdivide further: equals should systematically return false.
For Same Type, there are several possible subdivided partitions:
- One with the same attribute values as the first input parameter (equals returns true)
- One with a different amount but the same currency (equals returns false)
- One with a different currency but the same amount (equals returns false)
- One with a different currency and amount (equals returns false)
Define equivalence classes (data sets) and values
The next step would be to define the equivalence classes and values. An equivalence class is a set of input values that are all expected to invoke the same behavior. If any single value from the equivalence class produces a test that fails, then all other values from the equivalence class should produce tests that fail. Likewise, if any single value from the equivalence class produces a test that passes, all other values from the equivalence class should produce tests that pass.
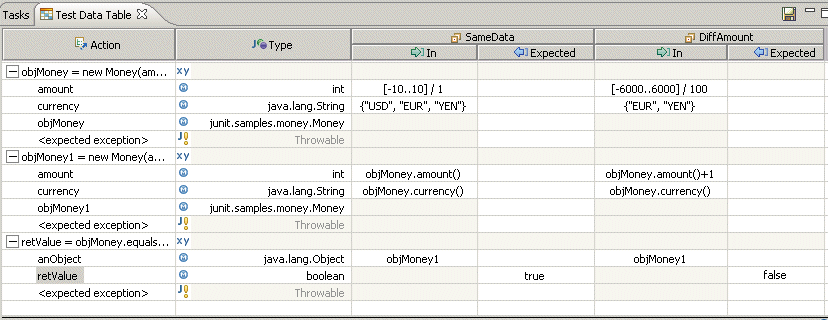
With the Rational Developer products, you define equivalence classes in the test data tables, where they are referred to as data sets. Using the data partitions that were just defined, you could first create equivalence classes that handle the comparison between the four "Same Type" partitions and the "Any Attribute Value" partition. The following screen capture shows a test data table with two of these four equivalence classes:

Each equivalence class reuses the same data partition ("any attribute value") for the first input parameter. However, to create diversity in this test, each equivalence class uses different values from this same data partition.
Next, you could create equivalence classes for the null data and incompatible data type partitions, as shown in the following screen capture:

Finally, you can use sets and ranges to provide many more combinations of data for your test, as shown in the following screen capture. For the amount, you could supply a range of integers, using negative, zero, and positive numbers. For the currency, you could try using a set of valid and invalid currency identifiers. By doing this, you greatly increase the number of data combinations in the test and as a result, you may increase your test coverage and the probability of discovering defects.
Note, however, that using sets and ranges can create a large number of individual tests that can take a long time to run.
Complex scenarios
This example has discussed ways to define data partitions and equivalence classes to test a method. When defining a scenario that invokes many methods, or when methods use objects, you can follow the same procedures. However, in these cases, you need to reduce the number of input parameters to break the problem down into something manageable.
In these cases, it becomes very important that you use abstract states to manage objects. You should always define abstract states before you try to partition an object's defining attributes. Even when you consider an object as a single input parameter, you can easily end up with dozens of input parameters.
This means that when you deal with complex scenarios, be very careful about choosing the input parameters. In general, to manage this complexity, try to reduce the problem to fewer than 10 variables.