Concepts: Relational Databases and Object Orientation
Topics
- Introduction
- Relational Databases and Object Orientation
- Persistence Frameworks
- Essential characteristics of an object-relational framework
- Common Object-Relational
Services
Introduction

This concept document provides an overview of object models and relational data models, and provides a summary description of a persistence framework.
Relational Databases and Object Orientation
Relational databases and object orientation are not entirely compatible. They represent two different views of the world: in an RDBMS, all you see is data; in an Object-Oriented system, all you see is behavior. It is not that one perspective is better than the other: the Object-Oriented model tends to work well for systems with complex behavior and state-specific behavior in which data is secondary, or systems in which data is accessed navigationally in a natural hierarchy (for example, bills of materials). The RDBMS model is well-suited to reporting applications and systems in which the relationships are dynamic or ad-hoc.
The real fact of the matter is that a lot of information is stored in relational databases, and if Object-Oriented applications want access to that data, they need to be able to read and write to an RDBMS. In addition, Object-Oriented systems often need to share data with non-Object-Oriented systems. It is natural, therefore, to use an RDBMS as the sharing mechanism.
While object-oriented and relational design share some common characteristics (an objects attributes is conceptually similar to an entities columns), fundamental differences make seamless integration a challenge. The fundamental difference is that data models expose data (through column values) while object models hide data (encapsulating it behind its public interfaces).
The Relational Data Model
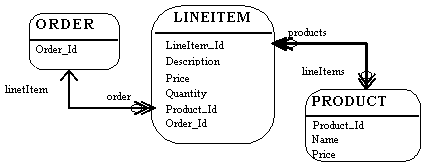
The relational model is composed of entities and relations. An entity may be a physical table or a logical projection of several tables also known as a view. The figure below illustrates LINEITEM, ORDER, and PRODUCT tables and the various relationships between them. A relational model has the following elements:
A Relational Model
An entity has columns. Each column is identified by a name and a type. In the figure above, the LINEITEM entity has the columns LineItem_Id (the primary key), Description, Price, Quantity, Product_Id and Order_Id (the latter two are foreign keys that link the LINEITEM entity to the ORDER and PRODUCT entities).
An entity has records or rows. Each row represents a unique set of information which typically represents an object's persistent data.
Each entity has one or more primary keys. The primary keys uniquely identify each record (for example, Id is the primary key for LINEITEM table).
Support for relations is vendor specific. The example illustrates the logical model and the relation between the PRODUCT and LINEITEM tables. In the physical model, relations are typically implemented using foreign key / primary key references. If one entity relates to another, it will contain columns which are foreign keys. Foreign key columns contain data which can relate specific records in the entity to the related entity.
Relations have multiplicity (also known as cardinality). Common cardinalities are one to one (1:1), one to many (1:m), many to one (m:1), and many to many (m:n). In the example, LINEITEM has a 1:1 relationship with PRODUCT and PRODUCT has a 0:m relationship with LINEITEM.
The Object Model
An object model contains, among other things, classes (see [UML01] for a complete definition of an object model). Classes define the structure and behavior of a set of objects, sometimes called objects instances. The structure is represented as attributes (data values) and associations (relationships between classes). The following figure illustrates a simple class diagram, showing only attributes (data) of the classes.
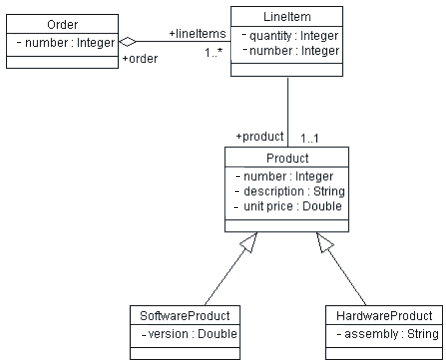
An Object Model (Class Diagram)
An Order has a number (the Order Number), and an association to 1 or more (1..*) Line Items. Each Line Item has a quantity (the quantity ordered).
The object model supports inheritance. A class can inherit data and behavior from another class (for example, SoftwareProduct and HardwareProduct products inherit attributes and methods from Product class).
Persistence Frameworks
The majority of business applications utilize relational technology as a physical data store. The challenge facing object-oriented applications developers is to sufficiently separate and encapsulate the relational database so that changes in the data model do not "break" the object model, and vice versa. Many solutions exist which let applications directly access relational data; the challenge is in achieving a seamless integration between the object model and the data model.
Database application programming interfaces (APIs) come in standard flavors (for example, Microsoft's Open Data Base Connectivity API, or ODBC) and are proprietary (native bindings to specific databases). The APIs provide data manipulation language (DML) pass through services which allow applications to access raw relational data. In object-oriented applications, the data must undergo object-relational translation prior to being used by the application. This requires considerable amount of application code to translate raw database API results into application objects. The purpose of the object-relational framework is to generically encapsulate the physical data store and to provide appropriate object translation services.
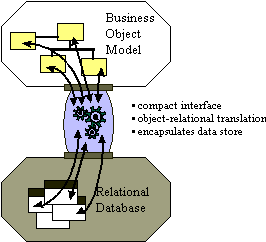
The Purpose of a Persistence Framework
Application developers spend over 30% of their time implementing relational database access in object-oriented applications. If the object-relational interface is not correctly implemented, the investment is lost. Implementing an object-relational framework captures this investment. The object-relational framework can be reused in subsequent applications reducing the object-relational implementation cost to less than 10% of the total implementation costs. The most important cost to consider when implementing any system is maintenance. Over 60% percent of the total costs of a system over its entire life-cycle can be attributed to maintenance. A poorly implemented object relational system is both a technical and financial maintenance nightmare.
Essential characteristics of an object-relational framework
- Performance. Close consideration must be given towards decomposing objects into data and composing objects from data. In systems where data through-put is high and critical, this is often an Achilles heel of an inadequately designed access layer.
- Minimize design compromises. A familiar pattern to object technologists who have built systems, which utilize relational databases, is to adjust the object model to facilitate storage into relational systems, and to alter the relational model for easier storage of objects. While minor adjustments are often needed, a well designed access layer minimizes both object and relational model design degradation.
- Extensibility. The access layer is a white-box framework which allows application developers to extend the framework if certain functionality is desired in the framework. Typically, an access layer will support, without extension, 65-85% of an application's data storage requirements. If the access layer is not designed as an extensible framework, achieving the last 35-15% of an application's data storage requirements can be very difficult and costly.
- Documentation. The access layer is a both a black-box component, and a white-box framework. The API of the black-box component must be clearly defined, well documented, and easily understood. As previously mentioned, the access layer is designed to be extended. An extensible framework must be very thoroughly documented. Classes which are intended to be subclassed must be identified. The characteristics of each relevant class's protocol must be specified (for example, public, private, protected, final, ...). Moreover, a substantial portion of the access layer framework's design must be exposed and documented to facilitate extensibility.
- Support for common object-relational mappings. An access layer should provide support for some basic object-relational mappings without the need for extension. These object-relational mappings are discussed further in a subsequent section of this document.
- Persistence Interfaces: In an object oriented application, the business model for an object application captures semantic knowledge of the problem domain. Developers should manipulate and interact with objects without having to worry too much about the data storage and retrieval details. A well-defined subset of persistent interfaces (save, delete, find) should be provided to application developers.
Common Object-Relational
Services
Common patterns are emerging for object-relational applications. IT
professionals who have repeatedly crossed the chasm are beginning to understand
and recognize certain structures and behaviors which successful
object-relational applications exhibit. These structures and behaviors have been
formalized by the high-level CORBA Services specifications (which apply equally
well to COM/DCOM-based systems).
The CORBA service specifications which are applicable and useful to consider for
object-relational mapping are:
The following sections will use these categories to structure a discussion of common object-relational services. The reader is encouraged to reference the appropriate CORBA specifications for further details.
Persistence
Persistence is a term used to describe how objects utilize a secondary storage medium to maintain their state across discrete sessions. Persistence provides the ability for a user to save objects in one session and access them in a later session. When they are subsequently accessed, their state (for example, attributes) will be exactly the same as it was the previous session. In multi-user systems, this may not be the case since other users may access and modify the same objects. Persistence is interrelated with other services discussed in this section. The consideration of relationship, concurrency and others is intentional (and consistent with CORBA's decomposition of the services).
Examples of specific services provided by persistence are:
- Data source connection management: Object-relational applications must initiate connection to the physical data source. Relational database systems typically require identification of the server and database. The specifics of connection management tends to be database vendor specific and the framework must accordingly be designed in a flexible accommodating manner.
- Object retrieval: When objects are restored from the database, data is retrieved from the database and translated into objects. This process involves extracting data from database specific structures retrieved from the data source, marshaling the data from database types into the appropriate object types and/or classes, creation of the appropriate object, and setting the specific object attributes.
- Object storage: The process of object storage mirrors object retrieval. The values of the appropriate attributes are extracted from the object, a database specific structure is created with the attribute values (this may be a SQL string, stored procedure, or special remote procedure call), and the structure is submitted to the database.
- Object deletion: Objects that are deleted from within a system, must have their associated data deleted from the relational database. Object deletion requires that appropriate information be extracted from the object, a deletion request be constructed (this may be a SQL string, stored procedure, or special remote procedure call), and the request submitted to the database. Note that in some languages (for example, Smalltalk and Java), explicit deletion is not supported; instead, a strategy called garbage collection is supported. Persistence frameworks supporting these languages must provide an alternative way to remove data from the database once applications no longer reference the data. One common way is for the database to maintain reference-counts of the number of times an object is referenced by other objects. When the reference count for an object drops to zero, no other objects reference it, and it may be possible to delete it. It may be acceptable to delete objects with a reference count of zero, since even when an object is no longer referenced, it may still be queried. A database-wide policy on when object deletion is allowed is still needed.
Query
Persistent object storage is of little use without a mechanism to search for and retrieve specific objects. Query facilities allow applications to interrogate and retrieve objects based on a variety of criteria. The basic query operations provided by an object-relational mapping framework are find and find unique. The find unique operation will retrieve a specific object and find will return a collection of objects based on a query criteria.
Data store query facilities vary significantly. Simple file-based data stores may implement rigid home-grown query operations, while relational systems provide a flexible data manipulation language. Object-relational mapping frameworks extend the relational query model to make it object-centric rather than data centric. Pass-through mechanisms are also implemented to leverage relational query flexibility and vendor-specific extensions (for example, stored-procedures).
Note that there is some potential conflict between database-based query mechanisms and the object paradigm: database query mechanisms are driven by values of attributes (columns) in a table. In the corresponding objects, the principle of encapsulation prevents us from seeing the values of attributes; they are encapsulated by the operations of the class. The reason for encapsulation is that it makes applications easier to change: we can alter the internal structure of a class without concern for dependent classes as long as the publicly-visible operations of the class do not change. A query mechanism based on the database is dependent on the internal representation of a class, effectively breaking encapsulation. The challenge for the framework is to prevent queries from making applications brittle to change.
Transactions
Transactional support enables the application developer to define an atomic unit of work. In database terminology, it means that the system must be able to apply a set of changes to the database, or it must ensure that none of the changes are applied. The operations within a transaction either all execute successfully or the transaction fails as whole. Object-relational frameworks at a minimum should provide a relational database-like commit/rollback transaction facility. Designing object-relational frameworks in a multi-user environment can present many challenges and careful thought should be given to it.
In addition to the facilities provided by the persistence framework, the application must understand how to handle errors. When a transaction fails or is aborted, the system must be able to restore its state to a stable prior state, usually by reading the prior state information from the database. Thus, there is a close interaction between the persistence framework and the error handling framework.
Concurrency
Multi-user object-oriented systems must control concurrent access to objects. When an object is accessed simultaneously by many users, the system must provide a mechanism to insure modifications to the object in the persistent store occur in a predictable and controlled manner. Object-relational frameworks may implement pessimistic and/or optimistic concurrency controls.
- Pessimistic concurrency control requires that the application developer specify their intent when the object is retrieved from the data store (for example, read only, write lock, ...). If objects are locked, other users may block when accessing the object and wait for the lock to be relinquished. Pessimistic concurrency should be used and implemented with caution as it is possible to create dead-lock situations.
- Optimistic concurrency control assumes that it is unlikely that the same object will be simultaneously accessed. Concurrency conflicts are detected when the modifications are saved to the database. Typically, if the object has been modified by another user since its retrieval, an error will be returned to the application indicating failure of the modify operation. It is the application's responsibility to detect and handle the error. This calls for the framework to cache the concurrent values of objects and compare them against the database. Optimistic concurrency is less costly if there are few concurrency conflicts, but more expensive if the number of conflicts is fairly large (because of the need to re-do work when conflicts occur).
All applications using shared data must use the same concurrency strategy; you cannot mix optimistic and pessimistic concurrency control in the same shared data or corruption may occur. The need for a consistent concurrency strategy is best handled through a persistence framework.
Relationships
Objects have relationships to other objects. An Order object has many Line
Item objects. A Book object has many Chapter objects. An Employee object belongs
to exactly one Company object. In relational systems, relations between entities
are implemented using foreign key / primary key references. In object-oriented
systems, relations are usually explicitly implemented through attributes. If an
Order object has LineItems, then Order will contain an attribute named
lineItems. The lineItems attribute of Order will contain many LineItem objects.
The relationship aspects of an object-relational framework are interdependent
with the persistence, transaction, and query services. When an object is stored,
retrieved, transacted, or queried, consideration must be given to its related
objects:
- When an object is retrieved, should associated objects be retrieved as well? Simplistically, yes, but doing so when the associated objects are not needed is very expensive. A good framework will allow a mix of strategies.
- When an object is stored, should associated objects be stored as well if they have been changed? Again, the answer depends on the context.
While it is conceptually advantageous to consider common object-relational services separately, their object-relational framework implementations will be codependent. The services must be implemented consistently across not only individual organizations, but all applications which share the same data. A framework is the only economical way to achieve this.
