Guideline: Implementing Classes
- Implementing Operations
- Implementing States
- Using Delegation to Reuse Implementation
- Implementing Associations
- Implementing Attributes
Implementing Operations

To implement operations, do the following:
- Choose an algorithm.
- Choose data structures appropriate to the algorithms.
- Define new classes and operations as necessary.
- Code the operation.
Choose an Algorithm
Many operations are simple enough to be implemented from the operation and its specification.
Nontrivial algorithms are primarily needed for two reasons: to implement complex operations for which a specification is given, and to optimize operations for which a simple but inefficient algorithm serves as definition.
Choose Data Structures Appropriate To the Algorithms
Choosing algorithms involves choosing the data structure they work on. Many implementation data structures are container classes, such as, arrays, lists, queues, stacks, sets, bags, and variations of these. Most object-oriented languages, and programming environments provide class libraries with these kinds of reusable components.
Define New Classes and Operations as Necessary
New classes may be found to hold intermediate results, for example. New low-level operations may be added on the class to decompose a complex operation. These operations are often private to the class, that is, not visible outside the class itself.
Code the Operation
Write the code for the operation starting with its interface statement. Follow applicable programming guidelines.
Implementing States
The state of an object may be implemented by reference to the values of its attributes, with no special representation. The state transitions for such an object will be implicit in the changing values of the attributes, and the varying behaviors are programmed through conditional statements. This solution is not satisfactory for complex behavior because it usually leads to complex structures which are difficult to change as more states are added or the behavior changes.
If the design element (or its constituents') behavior is state-dependent, there will typically be one or more statechart diagrams that describe the behavior of the model elements in the design element. These statechart diagrams serve as an important input during implementation.
The state machines shown in statechart diagrams make an object's state explicit, and the transitions and required behavior are clearly delineated. A state machine may be implemented in several ways:
- for simple state machines, by defining an attribute which enumerates the possible states, and using the attribute to select the behavior for incoming messages. For example, in a switch statement in Java or C++. This solution does not scale very well for complex state machines and may lead to poor run-time performance. See [DOUG98], Chapter 4, 4.4.3 for an example of this method
- for more complex state machines, the State pattern may be used. See [GAM94] for a description of the State pattern. [DOUG98], Chapter 6, 6.2.3, State Pattern, also describes this approach
- a table-driven approach works well for very complex state machines where ease of change is a criterion. In this approach, there are entries for each state in a table where each entry maps inputs to succeeding states and associated transition actions. See [DOUG98], Chapter 6, 6.2.3, State Table Pattern, for an example of this method.
State machines with concurrent substates may be implemented by delegating state management to active objects, one for each concurrent substate, because concurrent substates represent independent computations (which may, nevertheless, interact). Each substate may be managed using one of the techniques described above.
Using Delegation to Reuse
Implementation
If a class or parts of a class can be implemented by reusing an existing class, use delegation rather than inheritance.
Delegation means that the class is implemented with the help of other classes. The class references an object of the other class by using a variable. When an operation is called, it calls an operation in the referenced object (of the reused class) for actual execution. Thus, it delegates responsibility to the other class.
Implementing Associations
A one-way association is implemented as a pointer - an attribute which contains an object reference. If the multiplicity is one, then it is implemented as a simple pointer. If the multiplicity is many, then it is a set of pointers. If the many end is ordered then a list can be used instead of a set.
A two-way association is implemented as attributes in both directions, using techniques for one-way associations.
A qualified association is implemented as a lookup table (for example, a Smalltalk Dictionary class) in the qualifying object. The selector values in the lookup table are the qualifiers, and the target values are the objects of the other class.
If the qualifier values must be accessed in order, then the qualifiers can be arranged into a sorted array or a tree. In this case, access time will be proportional to log N where N is the number of qualifier values.
If the qualifiers are drawn from a compact finite set, then the qualifier values can be mapped into an integer range and the association can be efficiently implemented as an array. This approach is more attractive if the association is mostly full rather than sparsely populated, and it is ideal for fully populated finite sets.
Most object-oriented languages and programming environments provide class libraries with reusable components to implement different kinds of associations.
Implementing Attributes
Implement attributes in one of three ways: use built-in primitive types, use an existing class, or define a new class. Defining a new class is often more flexible, but introduces unnecessary indirection. For example, an employee's Social Security number can either be implemented as an attribute of type String or as a new class.
![]()
Alternative implementations of an attribute.
It may also be the case that groups of attributes are combined into new classes, as the following example shows. Both implementations are correct.
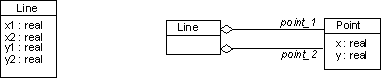
The attributes in Line are implemented as associations
to a Point class.
