Highly available Web server cluster on HTTP Server
In the IBM HTTP Server for i5/OS, you can use highly available Web server clusters.
Information for this topic supports the latest PTF levels for HTTP Server for iSeries . IBM recommends that you install the latest PTFs to upgrade to the latest level of the HTTP Server for i5/OS. Some of the topics documented here are not available prior to this update. See IBM Service for more information.
If Web serving is a critical aspect of your business, you may want high availability and scalability of your Web server environment. High availability and scalability of the Web server environment can be achieved through the use of iSeries™ clustering.
The Web server cluster solution can provide:
- Planned downtime: If a Web server requires planned maintenance,
it is possible to transfer the work to another node without visible service interruptions to the client.
- No unplanned downtime: If a machine fails, the work is transferred to another node with no human involvement and without visible service interruptions to the client.
- Scalability: When employing multiple nodes, it is possible to distribute the Web site workload over the cluster nodes.
Clusters are a collection of complete systems that work together to provide a single, unified computing capability. For more information on clusters, see Clusters in the iSeries Information Center.
A liveness monitor checks the state of the Web server and interacts with the Web server and the clustering resource services in the event that a Web server fails (failover), or a manual switchover takes place (ensures no interruption of Web server services). The clustered hash table (part of the state replication mechanism) can be used to replicate highly available CGI program state data across the cluster nodes so that the state data is available to all nodes in the event that a Web server fails (failover) or is switched-over manually (switchover). To take advantage of this capability, an existing CGI program must be enabled in a highly available Web Server environment. CGI programs write to the CGI APIs to indicate what data is replicated.
There are three Web server cluster models that are supported:
- Primary/backup with takeover IP model
- Primary/backup with a network dispatcher model
- Peer model
Parent topic:
Concepts of functions of HTTP Server
Primary/backup with takeover IP model
In this model, the Web server runs on the primary and all backup nodes. The backup node or nodes are in a idle state, ready to become the primary Web server should the primary Web server fail (failover), or a switchover takes place. All client requests are always served by the primary node.
The following diagram illustrates a Primary/backup with takeover IP model.
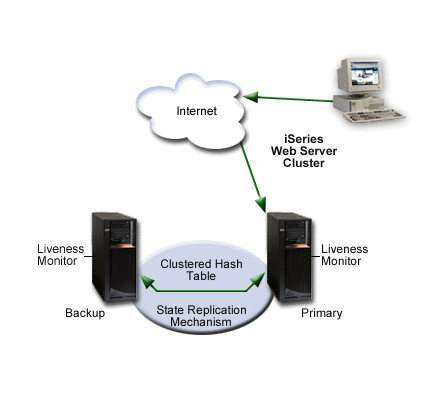
When the primary node fails (failover), or is brought down by the administrator, the failover/switchover process begins. The following steps are performed during failover/switchover:
- One of the backup servers becomes the primary (the first backup in the switchover order).
- The client requests are redirected to the new primary node.
- If the new primary receives a user request that belongs to a long-running-session (a CGI program that has been updated to be a highly available CGI program),
the server will restore the request's state. The new primary retrieves that highly available CGI program's state information from the clustered hash table.
The clustered hash table is part of the state replication mechanism.
- After the failed node recovers, the highly available Web server instance can be restarted and it will become the backup system. If the system administrator wants the failed node to become primary again, a manual switchover must be performed (this can be accomplished with the IBM Simple Cluster Management interface available through iSeries Navigator or a business partner tool).
Primary/backup with a network dispatcher model
In this model, just like the primary/backup with takeover IP model, the Web server runs on the primary and all backup nodes. The backup nodes are in an idle state and all client requests are served by the primary node. A network dispatcher (for example the IBM WebSphere® Edge Server) sends client requests to the Web server.
The following diagram illustrates a Primary/backup with a network dispatcher model.
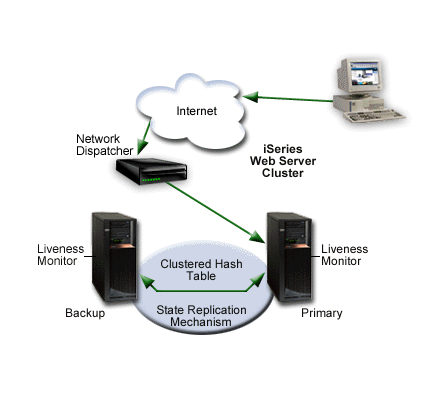
When the primary node fails (failover), or a switchover takes place, the failover/switchover process begins. The following steps are performed during failover/switchover:
- One of the backup servers becomes the primary (the first backup in the switchover order).
- The client requests are sent to the new primary node by the network dispatcher.
- If the new primary receives a user request that belongs to a long-running-session,
the server needs to restore the request's state. The new primary searches for the state either locally or in the clustered hash table. The clustered hash table is part of the state replication mechanism.
- After the failed node recovers, the system administrator can restart the Web server instance and it will become a backup Web server. If the system administrator wants the failed node to become primary again, a manual switchover must be performed.
A node can join a recovery domain as primary only if the cluster resource group is in inactive mode.
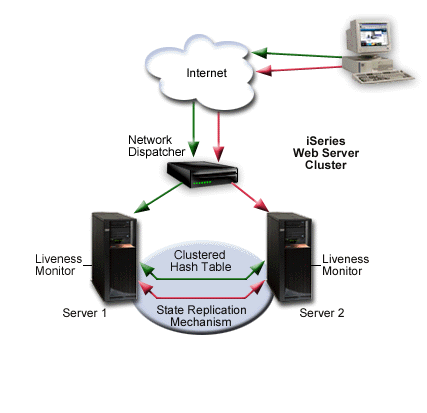
Peer model
In this model, there is no declared primary node. All nodes are in an active state and serve client requests. A network dispatcher (for example the IBM WebSphere Edge Server) evenly distributes requests to different cluster nodes. This guarantees distribution of resources in case of heavy load. Linear scalability is not guaranteed beyond a small number of nodes. After some number of nodes are added, scalability can disappear, and the cluster performance can deteriorate.
The following diagram illustrates the peer model.
For more information on Clusters, see Clustering troubleshooting. For instructions on how to set up a highly available Web server, see Setting up and administration of a highly available Web server cluster on HTTP Server (powered by Apache) or Set up a highly available Web server using clustering CL commands for HTTP Server.