Java Content Repository FAQ
JCR tables, nodes, and UUIDs
WCM content nodes are modeled through a graph of information stored across multiple tables. Deleting a node is not as simple a matter as removing one row from a table in the database. The interrelated connections between all the tables must be handled. In many cases, the level of logic required is not encoded in any singular SQL command that can be sent to the database. HCL does not publish the JCR database schema. The data in the JCR is separated across several tables in the database. There is no simple correlation between the IBM Lotus Web Content Management objects and database tables or rows. In most cases there is no simple SQL statement that can be constructed to fix an application issue. The context or semantics for functions are encoded in the application and not the database itself.
JCR workspace
A JCR workspace is container for a collection of nodes.
| Repository | Container for workspaces |
| Workspace | Container for nodes |
| Node | Container for properties |
| Property | Attribute of node |
All work in the repository is done by means of a workspace. When a user logs in to the repository, a "ticket" is issued, through which the user requests a workspace. It is through the workspace that all interaction with the nodes, or content, is performed. All modifications to nodes within a workspace is transient until a save operation. The workspace save operation persists all changes made to the nodes within the workspace to permanent storage, the database. JCR workspaces can be traversed using the HCL Support Tools portlet for IBM Web Content Manager
Dynamic workspaces
Changes to a regular workspace are not persisted to the backend data store until save is called on the workspace. A dynamic workspace is a workspace created from a regular workspace. It contains all the nodes that exist in the regular workspace. However, this sandbox is even more specialized because any changes made to nodes can be persisted by way of a save operation called on the workspace to the back end data store. Changes made in the dynamic workspace are NOT made in the stable workspace. The changes made in a dynamic workspace are merged into the backing stable workspace when a merge operation is called.
Workspace user permissions
A workspace itself does not have access/permissions associated with it. All authorization decisions within the repository are made against the nodes in the workspace. Therefore, if an operation is requested within a workspace, the authorization check is made against the nodes involved in the operation. There are no workspace authorization checks.
Does each logged in user get a workspace, or is the workspace shared?
Within the repository there is only one workspace with a given name. However, every user that logs in to the repository and requests a workspace with a given name is given a distinct Java object to represent it. Thus, each user has their own personal playground copy of that workspace. Their changes are persisted only if they call save on the workspace object. Applications above the repository may choose to share or cache the workspace object in their own manner.
How do you back up and restore the database?
Each database provides its own tooling to accomplish a backup or data restore of a database instance. The database administrator should have a regular process of backup for the repository database, along with the other portal databases. In the event of a catastrophic failure, a restore may be the shortest path to recovery of the data in the system. Restore data from backup does not solve the root cause of problems affecting the appserver itself. For Cloudscape, a backup can be as simple as creating a .zip file archive of the directory structure that contains the database. For the other database platforms, use the associated vendor tools. A database administrator should be familiar with how to use them.
How many characters are allowed for a user ID in JCR?
For IBM WebSphere Portal 6.1 and later, the user ID length can be up to 175 characters.
Databases must be created using UNICODE Database and National character sets such as UTF8, AL32UTF8, or AL16UTF16.
JCR Troubleshooting
Lotus WCM Support Tools Portlet
Before starting, install the latest cumulative fix.
Install the HCL Support Tools Portlet.
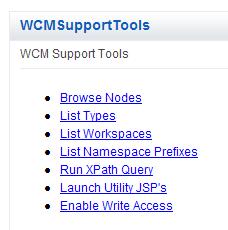
The Support Tools portlet is helpful in understanding the structure of the JCR database and is invaluable in troubleshooting many WCM and JCR issues. Some features of the portlet are not enabled due to the risk of database corruption if misused. HCL Support will provide codes valid for the current week to enable these additional features, if necessary to troubleshoot an issue effectively. It is also possible to run XPath queries that are pulled from a JCR Trace and paste them into the Support Tools Portlet.
| Web Application display name from web.xml: | WCMSupportTools |
| Context Root: | /wps/PA_WCMSupportTools |
| Enterprise Application display name | PA_WCMSupportTools |
Collect a JCR trace
- Delete any trace*.log files in...
6.1.x websphere/wp_profile/logs/WebSphere_Portal/ 6.0.x websphere/Portalserver/log/ - Log in to WebSphere Portal with the portal admin userid.
- Open a second tab in the same browser and copy/paste the URL from the first tab as the URL for the second tab.
- Navigate to the point in the first tab just before the problem is reproduced and stop at that point.
- In the second tab, enable the trace by selecting...
-
Administration | Portal analysis | Enable tracing
- Add the tracestring below in the "Append these trace settings" field and click the "+" icon:
-
com.ibm.icm.*=finest
- Reproduce the problem in first tab and remove the tracestring.
JCR performance issues
Identify long-running queries. Work with the application to reduce the size or complexity of the query sent to JCR, or optimize the database server to reduce the time to process the query. One approach that can help with query optimization is to extract the query from the trace and run it from the command line. For some queries all values are populated in the trace, but for other queries the "host variables" are missing and replaced by a "?" in the trace. When this occurs, first check the trace entries below the query to see if the values that should be substituted for the "?" are present. If not, temporarily configure the portal to output the "host variables" in the trace, using this procedure:
- Stop WebSphere Portal Server.
- Edit...
-
PortalServer/jcr/lib/com/ibm/icm/icm.properties
...setting the following property:
-
pls.debug.trackStatementCursorLeakage=+
Note that the value above must be set to "+" and not to "true".
- Set trace to...
-
com.ibm.icm.*=all
.in the WebSphere Application Server Admin console, if trace is required during WebSphere Portal startup.
Otherwise, use the dynamic instructions in the Collect a JCR Trace section above.
- Restart WebSphere Portal.
Once the query is reproduced from the command line, work with the DBA to analyze database performance. In many cases, the DBA can identify a new index that will help reduce the time to process the query.
Could not save item
Error...
Could not save item with id DepRef(id:121212121 type: com.aptrix.pluto.site.SiteArea nonDraft:true draft:false purged:false parentId:919191919 timeStamp:123 stateUpdate: false versions:null moved: false) because it could not find its parent.
...means parent uuid on subscriber does not match parent uuid on syndicator. To verity, in JCR Explorer, run the following queries on both systems...
//element(*, ibmcontentwcm:siteArea)[@jcr:uuid = '121212121']
//element(*, ibmcontentwcm:siteArea)[@jcr:uuid = '919191919']
You will undoubtedly find both uuids on syndicator, but not subscriber. This will be the case even if site areas show as existing on both machines from within the authoring portlet on the subscriber.
One way to fix...
- Delete site area child and parent on subscriber
- Edit site area on syndicator and then save, to give item a fresh time stamp.
- Re-syndicate
AccessDeniedException
An example of this error is...
-
"com.ibm.icm.jcr.access.AccessDeniedException: The requested operation violates one or more lock constraints.: [ErrorCode:7591]"
An AccessDeniedException error from WCM can mean one of the following:
- The logged-in user does not have available WebSphere Portal Access Control for this object
- The JCR node is locked by another workspace
- The JCR node is locked by another user
Find locked library nodes
Use the Support Tools Portlet to locate the node(s) and their locks if you are unsure of the current lock status. The Display Node option of WCM Support Tools will display all the locks for the specified node and its children. Any of the nodes that are locked will be shown in the portlet as either "external" or "internal".
Use the following steps in the Support Tools Portlet to display the node and its locks:
- Launch Utility JSP's.
- Select the Display Node option.
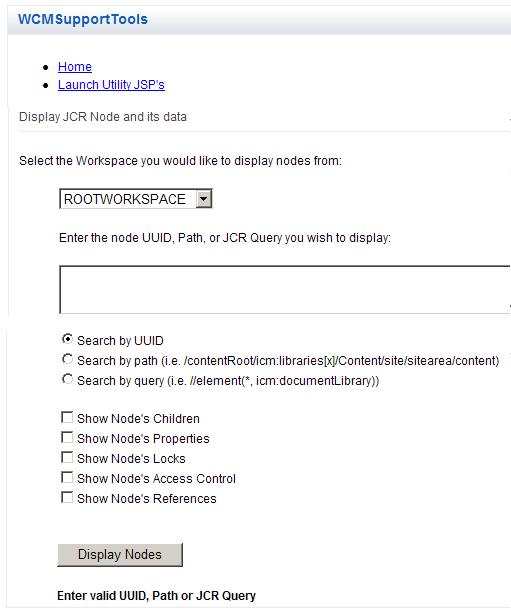
- Enter the following values:
- The node by path or UUID
- Show Node's Children
- Show Node's Locks
We can get UUID for a library node by running Browse Nodes.
External locks indicate that the node is locked by another user, and the lock details shows the lock userId. So the next step in this case is to log in as that user and unlock the node(s).
Internal locks indicate that the node is locked by a draft workspace. This is the common occurrence if the content node has a pending draft. In this case the next step is to remove the content node and its drafts.
The logged-in user does not have available Portal Access Control for this object. This is a valid exception if the user does not have the correct access rights for the requested action. The administrator must grant the necessary rights through WebSphere Portal for that object and action.
Examples from trace:
-
[5/17/10 14:52:37:994 EDT] 0000006d NodeImpl 3 com.ibm.icm.jcr.NodeImpl checkPermissions(8) Checking permissions: 8 on node: /contentRoot/icm:taxonomy/.system/com.ibm.portal.policy for user: uid=wpsadmin,o=defaultWIMFileBasedRealm
[5/17/10 14:52:38:146 EDT] 0000006d NodeImpl 3 com.ibm.icm.jcr.NodeImpl checkPermissions(8) Permissions not granted. Current permissions: 0
Permission 8 is READ permission.
The JCR node is locked by another workspace. Here's an example trace for this issue:
-
NodeImpl 3 com.ibm.icm.jcr.NodeImpl save(false, false) Found lock on path: /contentRoot/icm:libraries[8]/Content/mysite/welcome owned by: Workspace 7c2ba800465031b597d5f719fed3c258
SystemErr R com.ibm.icm.jcr.access.AccessDeniedException: The requested operation violates one or more lock constraints.: [ErrorCode:7591]
This is a common occurrence if the content node is being held by another draft. In this case, delete the draft before proceeding. When the draft is deleted, JCR will remove the draft workspace.
Try using the application user interface (for example, the Web Content Management Authoring UI) to clear out draft workspaces.
If unable to unlock the node through the Authoring UI, use the Support Tools Portlet to remove the locks for that node:
- Enable Write Access, using the unlock access code available from HCL Web Content Management Support.
- Select...
-
Home | Launch Utility JSP's | Display Node and Unlock
- Enter the following values:
-
# The node by path or UUID
# Show Node's Children
# Show Node's Locks
# Unlock Node's External Lock
Occasionally a problem will occur after a failed library delete, in which drafts are still left in the library. In this case, use the Support Tools Portlet or manageDrafts.jsp to delete the drafts and their associated workspaces. (Contact HCL Support for a copy of manageDrafts.jsp.)
The JCR node is locked by another user. It is common for another user to be working on the same node, and this is considered normal behavior. The best action for this failure is to log in as the other user and unlock the node.
AccessDeniedExceptions during import-wcm-data. Lock exceptions during import-wcm-data are caused by leftover locks from the export. The solution is to remove the locks during export, using these steps:
- Edit PortalServer/jcr/migration/conf/wcm60_conf.xml, replacing the "serializer" property (at around line 100) with the following:
<!-- The class name for the serializer instance to be used -->
<!-- property name="serializer" value="com.ibm.icm.jcr.serialization.serializer.ext.WPSDocLibNodeSerializerImpl"/ -->
<property name="serializer" value="com.ibm.icm.jcr.serialization.serializer.ext.WPSNoLockDocLibNodeSerializerImpl"/> - Export the library again to an empty directory.
- Retry the import based on the new export directory.
ItemNotFoundException
JCR throws an ItemNotFoundException when the requested node cannot be located, for example:
-
"javax.jcr.ItemNotFoundException: /contentRoot/icm:libraries5/content/site1"
This issue can be due to two causes:
- The requested node does not exist in the repository.
- The current user does not have sufficient access to read the requested node.
First verify that the user has access to the requested nodes in WebSphere Portal, and then contact the application's Support team regarding why the requested node has not been saved in the repository.
StaleValueException
This is a normal exception by JCR and does not indicate a JCR failure. StaleValueException is thrown when the current node being saved is different from the latest version of that node in the database.
To resolve the issue:
- Locate the DBAccessException in the logs, for example:
-
[3/8/10 7:14:17:194 CST] 000000c4 PUpdateNodeIm E PUpdateNodeImpl persistUpdatedContents Error while calling a function updateItems of PLS data manager.
com.ibm.icm.da.DBAccessException: [ErrorCode:10024] Error, item AB001001N10C04B700000C61D9, versionID=1 (userTable=ICMUT01074001) is stale, timestamp mismatch: 2/28/10 12:00 AM, 2/28/10 12:00 AM - Compare the two timestamps in the timestamp mismatch in the exception text:
Exactly one hour apart (for example, 2/28/10 10:00 AM, 2/28/10 11:00 AM). There is a known issue with JCR nodes that have been created or updated within the first hour after the time switch to Daylight Saving Time (DST).
The cause of this problem is that Java compensates for DST differently than the database. During this hour of overlap, Java advances internal timestamps one hour. However, the database does not advance the timestamp during this period, resulting in an inconsistency between Java timestamps and database timestamps. The end result is that the user encounters a StaleValueException every time they try to update nodes from this hour of overlap.
This DST issue has been addressed by ifixes PK76660 and PK82630, which are now available on all releases as part of the latest JCR Cumulative Fix.
We have also encountered a StaleValueException that is caused by problems in Oracle JDBC drivers prior to version 10.2.0.3. If you receive a StaleValueException related to DST and the above ifixes have been applied, make sure the Oracle driver is at the correct level.
Different values. This is the exception caused by normal processing. Retry the operation and verify no other user is updating the same content at the same time. If the problem persists, contact the application's Support team (Web Content Management, Personalization, Portal Document Manager, etc.).
The same value (for example, 2/28/10 12:00 AM, 2/28/10 12:00 AM). A problem has been observed on Oracle servers in which the Oracle database saves an invalid timestamp. This results in a StaleValueException from JCR because the Java cannot correctly read the invalid timestamp(s).
To avoid the issue, use these steps to force a resave of the data:
- Install the Support Tools Portlet (version 1.0.5 or later).
- Set the access code for update (available from HCL Support).
- Search for the document by IID from the DBAccessException (for example, AB001001N10C04B700000C61D9 in the example in Step 1).
- Edit the node and save it.
- If the node is Web Content Management content, update the node in Web Content Management to verify that the data syndicates correctly.
rollback
A rollback indicates that a previous failure has occurred and the current database transaction is being rolled back. Find and troubleshoot the previous failure.
For DB2 users, also check the db2diag.log file for the previous exception(s).
Database deadlocks
To troubleshoot a database deadlock:
- Ensure the database statistics are current.
- Verify the number of database connections and webcontainer threads. A deadlock in the JRE can occur if there are less database connections than webcontainer threads in the configured WebSphere Portal server. For more information, refer to the Support Technote...
-
Unable to locate Dynamic Workspace
- Verify the deadlock exceptions in the trace, for example,
-
"SQL0913N Unsuccessful execution caused by deadlock or timeout."
.or...
-
COM.ibm.db2.jdbc.DB2Exception: [HCL][CLI Driver][DB2/AIX64] SQL0913N Unsuccessful execution caused by deadlock or timeout. Reason code "68"." The error description can be found in the DB2 InfoCenter. The issue is caused by either a deadlock or a lock timeout:
# Reason Code "2": Deadlock
# Reason Code "68": TimeoutAlso, note that "Server returned XA_RBDEADLOCK" is an example of a deadlock message from an XA Connection.
- Increase the DB2 lock timeout and verify the results. For more information, refer to the DB2 InfoCenter topic...
-
SET CURRENT LOCK TIMEOUT statement
- Obtain deadlock diagnostic information:
- Verify that the deadlock message(s) in the WebSphere Portal logs identify the tables involved.
- with JCR trace enabled (see the JCR Trace section above).
- snapshot of the failure. Note that the snapshot specifics vary based on database platform, so refer to the documentation for the database server (DB2, Oracle) for specific information.
- Verify that the deadlock message(s) in the WebSphere Portal logs identify the tables involved.
invalid
JCR throws this exception when an error has occurred, rendering the current log-in session invalid. For instance:-
"com.ibm.icm.jcr.invalid: Instance of workspace ROOTWORKSPACE has been marked invalid and should be discarded."
To correct the problem, log out and then log in. Note that this exception does not require data in the repository to be deleted.
IMPORTANT: invalid is an indication that a previous problem has left the current log-in session invalid, so be sure to identify and address the original problem.
OutOfMemoryError
There are often cases in which the OutOfMemoryError is caused by the application processing too much data when using a StrongWorkspaceState, which can be identified is you see StrongWorkspaceState holding a lot of memory in the heap dump analysis.The StrongWorkspaceState is an internal cache of all JCR nodes referenced in the current workspace. The OutOfMemoryError here indicates that more nodes are referenced than the current memory can handle; thus the application must be changed to do one of the following:
- Reduce the number of nodes processed per workspace.
- Manually clear the workspace state at an interval that can be handled by the system's memory.
- Use Weak workspace state.
The latest JCR Cumulative Fix for WebSphere Portal 6.0.1 and 6.1 contains a fix that helps identify the application that is improperly using the StrongWorkspaceState. It does not resolve the problem; however, if you enable trace to com.ibm.icm.jcr.StrongWorkspaceState=all and recreate the failure, then after the next OutOfMemoryError the trace will contain debug stack traces that can be used by HCL Support to identify the failure.
Otherwise, this error needs more diagnostic information to determine the cause. You'll need to collect Java cores and the heap dump of the failure, which will show the objects that are consuming the memory during the time of failure.
integrity
JCR throws a integrity when the application attempts to remove a node that contains an outstanding reference, for example:
-
"javax.jcr.integrity: Path Add/Rename/Delete operation failed; Deleted item: AB001001N07L28C22602B8A3B7 is still referred by: AB001001N07L28C217029035B7 version: 3"
All references to the node must be removed before removing the node itself. To resolve the issue, locate and remove the outstanding references, following these steps:
- Locate the IID values from the error message (for example, 'AB001001N07L28C22602B8A3B7' and 'AB001001N07L28C217029035B7')
- Install the Support Tools Portlet.
- Browse nodes, and lookup the nodes by IID.
After identifying the nodes involved with the exception, use the application (WCM Authoring) to remove the reference.
Non-atomic batch failure
To troubleshoot a non-atomic batch failure:- Make sure the latest cumulative fix is applied (see above), to ensure diagnostic information for the Non-atomic batch failure is available.
- Enable JCR Trace (see above) and recreate the failure.
- Look in the logs for the database exception; the actual exception is included in the trace immediately before the Non-atomic batch failure.
Database exceptions
To troubleshoot database exceptions:- Ensure that the tables are part of JCR.
JCR tables start with ICM* and TSS*. Note that other applications (including WCM and PAC) store data in the JCR database.
- Get the exception and stack trace from the logs, for example:
-
[4/22/09 9:33:56:592 PDT] 0000005a PGetItemsByCM E Error while calling a function retrieveItemsByCMId of PLS data manager.
com.ibm.db2.jcc.a.SqlException: DB2 SQL error: SQLCODE: -104, SQLSTATE: 42601, SQLERRMC:
In the case of DB2, translate the SQLCODE value using the DB2 InfoCenter.
For example, the DB2 exception above translates to...
-
"com.ibm.db2.jcc.a.SqlException: DB2 SQL error: SQLCODE: -104, SQLSTATE: 42601, SQLERRMC:" translates to the following description:
"SQL0104N An unexpected token was found following text. Expected tokens may include: token-list."
In the case of SQL Server on WebSphere Portal 6.0.1.x, verify lowercase schema issues by confirming that the following fixpack is applied...
-
PK87097 (Portal 6.0x doesn't support lowercase schema name in ms sql)
DB2 Database hangs during WebSphere Portal upgrade.
There have been issues in which a database hang occurs while upgrading WebSphere Portal versions (e.g., upgrading to 6.0.1.4). This can be caused by the database user not having DBADM authority. Note that it is not enough to grant only SYSADM authority to the user; the user must have explicit DBADM authority.
SQLSTATE=54001 - The statement is too long or too complex
Increase the values of the DB2 statement heap (stmtheap), the application heap (applheapsz), and the cache size (pckcachesz), and then restart the database manager for these updates to take effect. If this failure occurs during a one-time operation, such as library delete, it's OK to reduce these values after delete has completed.
In addition, this error can occur if database statistics are not regularly executed. Make sure the database statistics are current. Refer to the Database performance topic in the WebSphere Portal InfoCenter for more information.
The library delete module, com.aptrix.pluto.util.LibraryDeleteModule, is no longer supported in WCM v7
SQLCODE 805 - Missing database package.
For example:
-
"DB2 SQL error: SQLCODE: -443, SQLSTATE: 38553, SQLERRMC:SYSIBM.SQLTABLES;TABLES;SYSIBM:CLI:-805"
This indicates a need to bind the db2schema.bnd file against each database by entering the following commands at a DB2 command prompt:
-
db2 terminate
db2 connect to database-name
db2 bind path\db2schema.bnd blocking all grant public sqlerror
continue
db2 terminate
.where "database-name" is the name of the database to which the utilities must be bound, and "path" is the full path name of the directory where the bind files are located.
SQLCODE 302 (host variable is too large) during query.
For example:
-
"com.ibm.icm.da.portable.query.Query openQueryCursor() com.ibm.db2.jcc.c.SqlException: DB2 SQL error: SQLCODE: -302, SQLSTATE: 22001, SQLERRMC: null"
This exception can occur if the XPath query specifies invalid properties, causing the database to throw this exception when trying to execute the invalid query. If this exception is encountered, obtain a JCR trace and verify that the XPath query does not attempt to query invalid properties.
DB2 zOS:
Failure to create database
The prefix must be unique enough to contain only the databases used for the content repository. Always use a prefix that provides unique database name conventions (for example, DPTJCRXXX, or something similar).
-
jcr.ZosDbPrefix=prefixName
Note that this problem can also appear during database transfer, when JCR is attempting to write to the wrong database. This is another case in which the jcr.ZosDbPrefix is not unique.
Pause during database transfer
WebSphere Portal 6.1 has a pause option for the database transfer, allowing the administrator to customize the generated DDL before it is applied to the database. Enable the pause feature by adding "-DTransferPauseEnabled=true" to the database-transfer command.
Oracle:
Error with ordered results
There is a known defect with ordering on Oracle 9.2.0.6, in which an ordered list from JCR may not be returned in the correct order. Upgrade to Oracle 10.0.2.3 or later to resolve the problem. For more information, refer to the Support Technote...
Menu ordering is broken in WCM due to bug in Oracle Trigger failures
Example error:
-
ORA-04098: trigger 'ICMADMIN.TSPEND_IWS2' is invalid and failed re-validation
This issue occurs when the triggers are created in the incorrect schema. This has been fixed with PK48092, but the problem may still occur after a database is transferred to Oracle before applying PK48092.
PK48092 is included in the latest JCR Cumulative Fix for WebSphere Portal 6.0.1.x and is not needed for Portal 6.1.
To resolve the problem, verify:
- the defined JCR schema in PortalServer/jcr/lib/com/ibm/icm/icm.properties
- that the trigger exists:
-
<schema>.TSPEND_IWS2
.where <schema> is the name of the schema that's defined in icm.properties, and replace TSPEND_IWS2 with the name of the missing trigger. that the other JCR tables are in the same schema:
After verification, move the triggers to the same schema as the JCR tables, if they are not already there.
For more details, refer to the Support Technote...
-
DSRA0304E, DSRA0302E, WTRN0037W errors occur during startup after Portal transfer to Oracle
SQL Server
PK87097: Make 6.0x fault tolerant of lowercase schema
This fix allows WebSphere Portal 6.0.1.x to be tolerant of lowercase database schema and is part of the latest JCR Cumulative Fix.
Database constraint failures on ICMSTJCRNODELOCKS.
For example:
-
SQL error : SQL0803N: One or more values in the INSERT statement, UPDATE statement, or foreign key update caused by a DELETE statement are not valid because the primary key, unique constraint or unique index identified by "1" constrains table "JCR.ICMSTJCRNODELOCKS" from having duplicate values for the index key.
This exception can be seen in the ffdc logs. It's part of normal processing and does not indicate a failure.
Unable to extend index ICMADMIN.xxxx by nnn in tablespace yyyy ORA-06512: at line 1.
Here the DBA needs to increases the size of tablespace yyyy.
DuplicateKeyException
For example:
-
"Caused by: com.ibm.websphere.ce.cm.DuplicateKeyException: DB2 SQL Error: SQLCODE=-803, SQLSTATE=23505,SQLERRMC=6;JCR.PROT_RES, DRIVER=3.57.110"
This is expected behavior when trying to create the same node (e.g. /.personalization) in more than one workspace (e.g. ROOTWORKSPACE and RULESWORKSPACE). Please ensure that this node (/.personalization) has been completely removed from all workspaces before continuing.
Database connection issues:
Oracle StaleConnectionException
For example:
-
"com.ibm.websphere.ce.cm.StaleConnectionException: No more data to read from socket"
This problem has been seen on Oracle 10.2.0.2 and is an Oracle problem. Oracle Support recommends upgrading to version 10.2.0.3.0.
-
com.ibm.db2.jcc.c.SqlException: Invalid operation: result set closed
This problem can occur when another process closes all database connections. It's often accompanied by NullPointerException messages within JCR, as JCR has now lost the database connection in mid-process. Instances of this problem have been resolved with PK60501 from WCM.
-
com.ibm.websphere.ce.cm.ObjectClosedException: DSRA9110E: Connection is closed
This error indicates that the Java Database Connectivity (JDBC) connection to the database has been closed elsewhere. Applying the latest JCR Cumulative Fix may help with the issue.
SQL30081N Failure
For example:
Connection Manager received a fatal connection error from the Resource Adaptor for resource jdbc/wpdbDS. The exception which was received is...
-
com.ibm.websphere.ce.cm.StaleConnectionException: IBM CLI Driver SQL30081N A communication error has been detected. Communication protocol being used: "TCP/IP". Communication API being used: "SOCKETS"
-
Location where the error was detected: "10.3.42.30". Communication function detecting the error: "send". Protocol specific error code(s): "32", "*", "0". SQLSTATE=08001
"SQL30081N RC 32" signifies a broken pipe between the DB2 client driver and DB2 server. In the case of one user, the issue was due to a network error and required an AIX patch.
Import Issue
Install Portal NOW. Import goes up to 70% and then fails with...
00000063 ImportStatusC I com.ibm.icm.jcr.command.ImportStatusCommand importNode
Imported 360 files (67%)
00000063 ImportStatusC I com.ibm.icm.jcr.command.ImportStatusCommand importNode
Imported 380 files (71%)
00000063 ServletWrappe E SRVE0068E: Uncaught exception thrown in one of the service methods of the servlet: ImportNodeCommandServlet. Exception thrown : javax.servlet.ServletException: responseCode=500
at com.ibm.icm.jcr.command.AbstractCommandServlet.doPost(AbstractCommandServlet.java:147)
at com.ibm.icm.jcr.command.AbstractCommandServlet.doGet(AbstractCommandServlet.java:81)
Fix
IWKMU1062X
Caused by: com.ibm.workplace.wcm.services.repository.RepositoryException: IWKMU1062X: Message: An External Lock could not be applied to {290f16004e1014fd9df8bd55e5d01204, com.aptrix.pluto.content.Content}., Cause: com.ibm.workplace.wcm.services.repository.LockNodeFailedException: An External Lock could not be applied to {290f16004e1014fd9df8bd55e5d01204, com.aptrix.pluto.content.Content}.
Check: http://www-01.ibm.com/support/docview.wss?uid=swg21322145
PM13808 solves issues related to the "LOCKING OF SITEAREAS AND CATEGORIES MAKES THEM UNAVAILABLE VIA WEBDAV"
Rebuild Search Index
Title: How to rebuild the WebSphere Portal Document Manager search index (Doc #: 1296931)
The SystemOut.log displays the following lines when rebuilding the search index:
-
* Start: START rebuilding juru index:
* End: DONE rebuilding juru index:
Stellent Conversion Errors
There is a database fix for Stellent Conversion Errors with htmlElement.elementData. contact HCL Support for more information
If you encounter other Stellant Conversion Errors while rebuilding the search index, contact HCL Support to involve the ODC/DCS team to help resolve the issues with running the conversion.
ParentIDNotFoundException
Example: com.ibm.icm.ts.path.ParentIDNotFoundException: Original parent not found for id: 120337072591476.
This error can occur if search indexing attempts to index an item which has been deleted. This is normal processing, and is not an error. The failed event is logged in the ICMJCRSTERRORS table.
Note that PK56104 will remove a lot of these messages. The former APAR, PK56033, has been replaced by PK56104.
After PK56104 has been applied, if search indexing encounters a deleted item, it will process that item only once and log the exception. The next time it will not attempt to process the deleted item again.
NOTE: PK56104 has been part of the JCR Cumulative fix since PK60132 (JCR Cumulative Fix #3).
This exception can cause the ICMJCRSTERRORS to grow very large. It is safe to remove the contents of this table after the JCR Cumulative Fix has been applied. Contact HCL Support to review the issue and provide the required SQL if indicated. It is recommended to make a full database backup before directly modifying the database.
Exception during Search
If there is an exception starting a WebSphere service, this may lead to search problems later on. For example:
-
* java.lang.IllegalStateException: I18N0012I: The Internationalization service is not started on WebSphere_Portal
Duplicate exceptions during search
Example: COM.ibm.db2.jdbc.DB2Exception: SQL0601N The name of the object to be created is identical to the existing name "JCR.TSSTBL_2" of type "TABLE".
You should clean up the temporary search tables to resolve this error. To clean up the temporary search tables, contact HCL Support to review the issue and provide the required SQL if indicated. It is recommended to make a full database backup before directly modifying the database.
unique constraint violated
Example: java.sql.BatchUpdateException: ORA-00001: unique constraint (WCMICMADMIN.SYS_C0036649) violated
This error has been fixed in 6.0.1.1, but can occur if the search index has not been rebuilt since upgrading to 6.0.1.1. Solution: Rebuild the search index.
Incorrect Results from Search
Search index failures
If the search is not yielding correct results, verify the search index was created with no errors.
We can verify if a single document was reindexed successfully by the following steps:
- Change the index maintenance interval to 2 minutes
- Enable JCR trace at com.ibm.icm.*=finest
- Edit the document
- Allow 2 minutes (the index maintenance interval) for the document to be reindexed
Trace search results
Collect the following information:
- Search criteria
- Portal page from where search was invoked
- Any other search options (if advanced search)
- The user's locale
- Expected results
- Actual results
- JCR trace of the failure: com.ibm.icm.*=finest
Trace information:
- Look for the entry to JCR query:
This will show the actual query that is being executed (including the text search):
Search string: QueryImpl execute includeLocks
Example:
-
[3/16/08 7:28:05:161 PDT] 0000009c QueryImpl 2 com.ibm.icm.jcr.query.QueryImpl execute includeLocks=false includeReferences=false includePaths=true statement=//element(, icm:documentLibrary)[@jcr:uuid = 'e8b5dc8046f1eb03a15db108d7e720a9']//(element(, ibmcontentwcm:authoringTemplate)|element(, ibmcontentwcm:webCategory))[@ibmcontentwcm:workflowStatus and @icm:authors = 'cn=userid,o=all users'][text-contains(.,'board')] order by text-score(.,'board*') descending propertiesToRetrieve=null
- Look for the entry to text search (Juru):
This will show what is being sent to text search, and if any truncation has occurred:
Search string: executing search:
Example:
-
[3/16/08 7:28:05:416 PDT] 000000b6 JCRCFLLoggerI 3 com.ibm.icm.ts.tss.JCRCFLLoggerImpl com.ibm.icm.ts.tss.JuruIndexImpl.result [java.lang.ThreadGroup[name=icmciWorkManager: icmjcrear,maxpri=10]] com.ibm.icm.ts.tss.JuruIndexImpl.result [java.lang.ThreadGroup[name=icmciWorkManager: icmjcrear,maxpri=10]]: executing search: 'board*' with language: en wildcard expansion size: 20
Wildcard term expansion truncated for search: 'board*
- Look for exit from text search:
This will identify how many results were found from text search (Juru).
Search string: num results:
Example:
-
[3/16/08 7:28:05:416 PDT] 000000b6 JCRCFLLoggerI 3 com.ibm.icm.ts.tss.JCRCFLLoggerImpl com.ibm.icm.ts.tss.JuruIndexImpl.result [java.lang.ThreadGroup[name=icmciWorkManager: icmjcrear,maxpri=10]] com.ibm.icm.ts.tss.JuruIndexImpl.result [java.lang.ThreadGroup[name=icmciWorkManager: icmjcrear,maxpri=10]]: num results: 4
- Look for exit from query:
This will identify how many of the search results are returned after JCR has performed a query based on the results from text search.
Search string: query result size
Example:
-
[3/16/08 7:28:16:216 PDT] 0000009c QueryResultIt 2 com.ibm.icm.jcr.query.QueryResultIteratorImpl QueryResultIteratorImpl query result size=0
If the number of results returned from Juru is different than what is expected, then we must pursue the incorrect search with Juru.
If the number of results returned from Juru is what is expected, then we must pursue the incorrect search with HCL JCR Support, to find out if/where JCR has changed the result list.
If trace indicates "expansion truncated" as above, it indicates that Juru search is working as designed, but the search terms yield more results than are allowed, and so they are truncated by Juru. Note that we can increase the number of search terms with the jcr.textsearch.wildcardTermExpansionSize property in icm.properties. However, note that a larger wildcard expansion size will impact search performance.
Number of search results returned
At present, JCR cannot retrieve more than 100 results from a Juru search. Note that this number may be further reduced by JCR based on either access control, or additional query criteria. The best way to identify if the incorrect number of search results is being limited by the maximum number of results returned from Juru is to look at the search trace (see above). If the number of results returned from Juru is 100, it is very likely that the current search exceeds this maximum of 100.
Search Across Locales
Nodes which are indexed in one language are not guaranteed to be searchable from another language. For example, a Turkish language node "fulya" is not searchable from English. This is working as designed.
To verify the search index language, compare the language from the search trace with the workspace language in icm.properties: jcr.workspace.defaultLanguage
Reorganize search index
If a lot of PDM or WCM content has been removed but the search index continues to grow, we may need to perform the administrator function to reorganize the search index. This capability is provided with PK61534. See the readme for PK61534 for instructions.