Product overview > Tutorials, examples, and samples > REST data services sample and tutorial > Enable the REST data service
|
| |
|
|
Scalable data model in eXtreme Scale
The Microsoft Northwind sample uses the Order Detail table to establish a many-to-many association between Orders and Products.
Object to relational mapping specifications (ORMs) such as the ADO.NET Entity Framework and Java™ Persistence API (JPA) can map the tables and relationships using entities. However, this architecture does not scale. Everything must be located on the same machine, or an expensive cluster of machines to perform well.
Figure 1. Microsoft SQL Server Northwind sample schema diagram
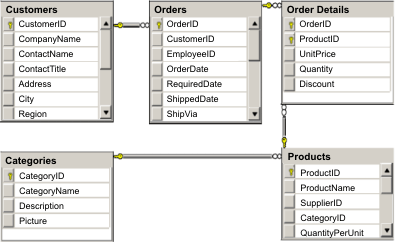
To create a scalable version of the sample, the entities must be modeled so each entity or group of related entities can be partitioned based off a single key. By creating partitions on a single key, requests can be spread out among multiple, independent servers. To achieve this configuration, the entities have been divided into two trees: the Customer and Order tree and the Product and Category tree. In this model, each tree can be partitioned independently and therefore can grow at different rates, increasing scalability.
Figure 2. Customer and Order entity schema diagram
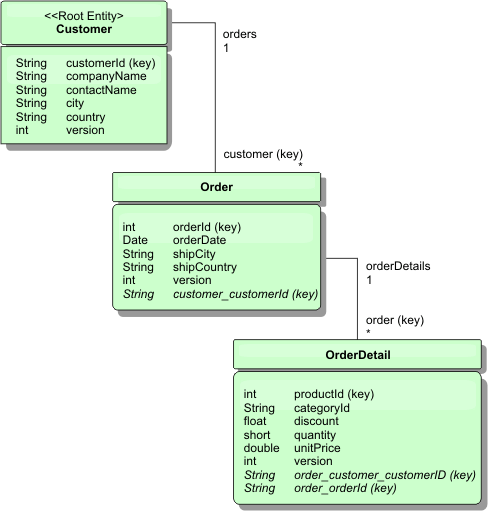
For example, both Order and Product have unique, separate integers as keys. In fact, the Order and Product tables are really independent of each other. For example, consider the effect of the size of a catalog, the number of products you sell, with the total number of orders. Intuitively, it might seem that having many products implies also having many orders, but this is not necessarily the case. If this were true, you could increase sales by just adding more products to the catalog. Orders and products have their own independent tables. You can further extend this concept so that orders and products each have their own separate, data grids. With independent data grids, you can control the number of partitions and servers, in addition to the size of each data grid separately so that the application can scale. If you double the size of the catalog, double the products data grid, but the order grid might be unchanged. The converse is true for an order surge, or expected order surge.
In the schema, a Customer has zero or more Orders, and an Order has line items (OrderDetail), each with one specific product. A Product is identified by ID (the Product key) in each OrderDetail. A single data grid stores Customers, Orders, and OrderDetails with Customer as the root entity of the data grid. You can retrieve Customers by ID, but get Orders starting with the Customer ID. So customer ID is added to Order as part of its key. Likewise, the customer ID and order ID are part of the OrderDetail ID.
Figure 3. Category and Product entity schema diagram
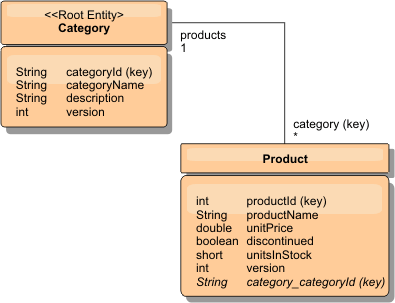
In the Category and Product schema, the Category is the schema root. With this schema, customers can query products by category. See Retrive and updating data with REST for additional details on key associations and their importance.
Parent topic:
Enable the REST data service
Related concepts
Retrive and updating data with REST
Related tasks
Start a stand-alone data grid for REST data services
Start a data grid for REST data services in WAS