Administration guide > Configure the deployment environment > Configuring cache integration > JPA cache configuration properties
|
| |
|
|
JPA cache plug-in
WebSphere eXtreme Scale includes level 2 (L2) cache plug-ins for both OpenJPA and Hibernate Java™ Persistence API (JPA) providers.
Use eXtreme Scale as an L2 cache provider increases performance when you are reading and querying data and reduces load to the database. WebSphere eXtreme Scale has advantages over built-in cache implementations because the cache is automatically replicated between all processes. When one client caches a value, all other clients are able to use the cached value that is locally in-memory.
With the OpenJPA and Hibernate ObjectGrid cache plug-ins, you can create three topology types: embedded, embedded-partitioned, and remote.
Embedded topology
An embedded topology creates an eXtreme Scale server within the process space of each application. OpenJPA and Hibernate read the in-memory copy of the cache directly and write to all of the other copies. You can improve the write performance by using asynchronous replication. This default topology performs best when the amount of cached data is small enough to fit in a single process.
Figure 1. JPA embedded topology
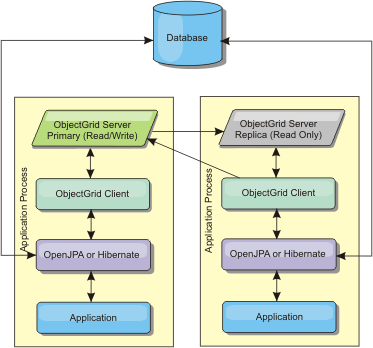
Advantages:
- All cache reads are very fast, local accesses.
- Simple to configure.
Limitations:
- Amount of data is limited to the size of the process.
- All cache updates are sent to one process.
Embedded, partitioned topology
When the cached data is too large to fit in a single process, the embedded, partitioned topology uses ObjectGrid partitions to divide the data over multiple processes. Performance is not as high as the embedded topology because most cache reads are remote. However, you can still use this option when database latency is high.
Figure 2. JPA embedded, partitioned topology
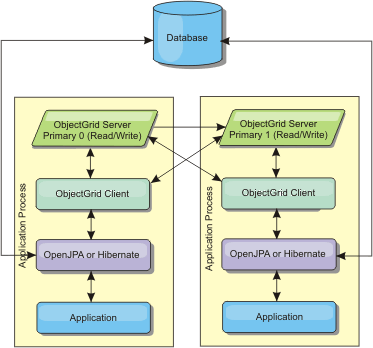
Advantages:
- Stores large amounts of data.
- Simple to configure
- Cache updates are spread over multiple processes.
Limitation:
- Most cache reads and updates are remote.
For example, to cache 10 GB of data with a maximum of 1 GB per JVM, ten JVMs are required. The number of partitions must therefore be set to 10 or more. Ideally, the number of partitions should be set to a prime number where each shard stores a reasonable amount of memory. Usually, the numberOfPartitions setting is equal to the number of JVMs. With this setting, each JVM stores one partition. If you enable replication, increase the number of JVMs in the system. Otherwise, each JVM also stores one replica partition, which consumes as much memory as a primary partition.
Read about sizing memory and partition count calculation to maximize the performance of the chosen configuration.
For example, in a system with 4 JVMs, and the numberOfPartitions setting value of 4, each JVM hosts a primary partition. A read operation has a 25 percent chance of fetching data from a locally available partition, which is much faster compared to getting data from a remote JVM. If a read operation, such as running a query, needs to fetch a collection of data that involves 4 partitions evenly, 75 percent of the calls are remote and 25 percent of the calls are local. If the ReplicaMode setting is set to either SYNC or ASYNC and the ReplicaReadEnabled setting is set to true, then four replica partitions are created and spread across four JVMs. Each JVM hosts one primary partition and one replica partition. The chance that the read operation runs locally increases to 50 percent. The read operation that fetches a collection of data that involves four partitions evenly has 50 percent remote calls and 50 percent local calls. Local calls are much faster than remote calls. Whenever remote calls occur, the performance drops.
Remote topology
A remote topology stores all of the cached data in one or more separate processes, reducing memory use of the application processes. You can take advantage of distributing the data over separate processes by deploying a partitioned, replicated eXtreme Scale data grid. As opposed to the embedded and embedded partitioned configurations described in the previous sections, to manage the remote data grid, do so independent of the application and JPA provider. Read about monitoring the deployment environment for more information on managing an eXtreme Scale data grid deployment.
Figure 3. JPA remote topology
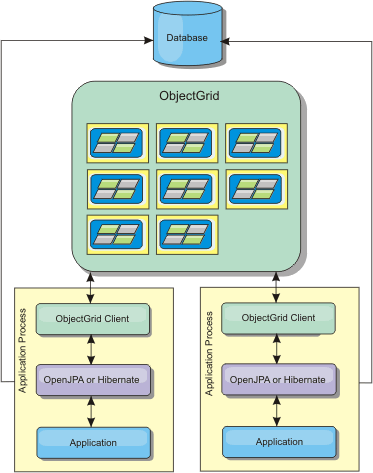
Advantages:
- Stores large amounts of data.
- Application process is free of cached data.
- Cache updates are spread over multiple processes.
- Very flexible configuration options.
Limitation:
- All cache reads and updates are remote.
Parent topic:
JPA cache configuration properties
Related concepts
Hibernate cache plug-in configuration
OpenJPA cache plug-in configuration