Workload management policies
The plug-in has two options for the load distributing algorithm:
- Round-robin with weighting
- Random
The weighting for the round-robin approach can be turned off by giving all application servers in a cluster equal weights.
The default value is Round Robin. It can be changed by selecting...
Servers | Web servers | WebServer_Name | Plug-in properties | Request Routing
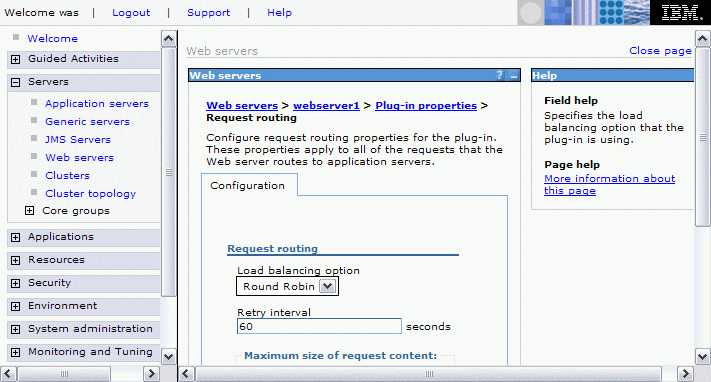
There is also a feature in WebSphere Application Server V6 for the plug-in called ClusterAddress that can be used to suppress load balancing. However, this is normally not desirable. As in the sample topology, a low-level Load Balancer (software-based or hardware-based) normally precedes the Web servers and not the application servers. See "Cluster Address" on page 271, in WebSphere Application Server V6 Scalability and Performance Handbook, SG24-6392, for more details (this setting cannot be made through the administrative console).
Weighted round robin
When using this algorithm, the plug-in selects a cluster member at random from which to start. The first successful browser request is routed to this cluster member and then its weight is decremented by 1. New browser requests are then sent round robin to the other application servers and subsequently the weight for each application server is decremented by 1. The spreading of the load is equal between application servers until one application server reaches a weight of 0. From then on, only application servers with a weight higher than 0 will have requests routed to them. The only exception to this pattern is when a cluster member is added or restarted or when session affinity comes into play.
Random
Requests are passed to cluster members randomly. Weights are not taken into account as with round robin. The only time the application servers are not chosen randomly is when there are requests with sessions associated with them. When the random setting is used, cluster member selection does not take into account where the last request was handled. This means that a new request could be handled by the same cluster member as the last request.