Configuration for workload sharing or scalability
This configuration consists of multiple messaging engines running in a cluster, with each messaging engine restricted to running on one particular server. A workload sharing configuration achieves greater throughput of messages by spreading the messaging load across multiple servers.
There are two ways to achieve this configuration:
- We can add a cluster to the service integration bus using messaging engine policy assistance, and use the scalability messaging engine policy. This procedure creates a messaging engine for each server in the cluster. Each messaging engine has just one preferred server and cannot fail over or fail back, that is, it is configured to run only on that server. New core group policies are automatically created, configured, and associated with each messaging engine.
- We can add a cluster to the service integration bus without using messaging engine policy assistance. One messaging engine is created automatically, then we add the further messaging engines that you require to the cluster, for example, one messaging engine for each server in the cluster.
We create a core group policy for each messaging engine. Because no failover is required, you configure those policies so that each messaging engine is restricted to a particular server. To restrict a messaging engine to a particular server, we can configure a Static policy for each messaging engine.
After we create the new policies, use the match criteria to associate each policy with the required messaging engine.
This type of deployment provides workload sharing through the partitioning of destinations across multiple messaging engines. This configuration does not enable failover, because each messaging engine can run on only one server. The impact of a failure is lower than in a simple deployment, because if one of the servers or messaging engines in the cluster fails, the remaining messaging engines still have operational destination partitions. However, messages being handled by a messaging engine in a failed server are unavailable until the server can be restarted.
The workload sharing configuration also provides scalability, because it is possible to add new servers to the cluster without affecting existing messaging engines in the cluster.
The following diagram shows a workload sharing or scalability configuration in which there are three messaging engines, ME1, ME2, and ME3, with data stores A, B, and C, respectively. The messaging engines run in a cluster of three servers and share the traffic passing through the destination. Each server is on a separate node, so that if one node fails, the servers on the remaining nodes are still available.
Figure 1. Workload sharing or scalability configuration

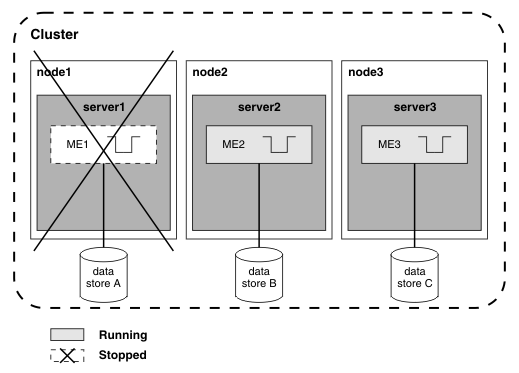
The following diagram shows what happens if server1 fails. ME1 cannot run, and data store A is not accessible. ME1 cannot process messages until server1 recovers. ME2 and ME3 are unaffected and continue to process messages. They will now handle all new traffic through the destination.
Figure 2. Workload sharing or scalability configuration after server1 fails
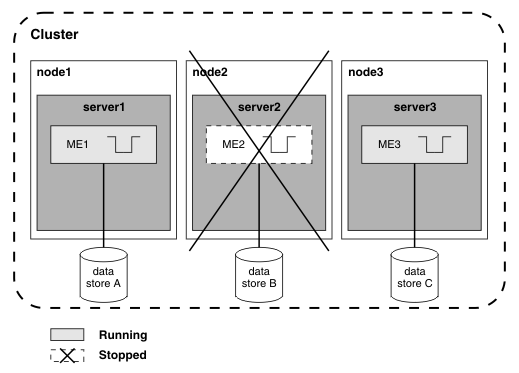
The following diagram shows what happens if server1 recovers and server2 fails. ME2 cannot run, and data store B is not accessible. ME2 cannot process messages until server2 recovers. ME1 and ME3 can process messages and will now handle all new traffic through the destination.
Figure 3. Workload sharing or scalability configuration after server1 recovers and server2 fails
Related concepts
Related tasks