Network topologies: Interoperating using the WebSphere MQ messaging provider
Overview
This page describes the main network topologies, clustered and not clustered, that allow WAS to interoperate with WebSphere MQ as an external JMS messaging provider. The topic also explores the suitability of each topology for providing high availability.
The WAS high availability framework eliminates single points of failure and provides peer to peer failover for applications and processes running within WAS. This framework also allows integration of WAS into an environment that uses other high availability frameworks, such as High Availability Cluster Multiprocessing (HACMP), in order to manage non-WAS resources.
- WAS appserver is not clustered and MQ queue manager is not clustered
- WAS appservers are clustered but MQ queue manager is not clustered
- WAS appservers are clustered and MQ queue managers are clustered
WAS appserver is not clustered and MQ queue manager is not clustered
There are two topology options:
- The WAS application server and the MQ queue manager run on different hosts
- The WAS application server and the MQ queue manager run on the same host
- The WAS appserver and the MQ queue manager run on different hosts
- The MQ transport type for the connection is specified as "client", that is, a TCP/IP network connection is used to communicate with the MQ queue manager. Client mode is also known as "socket attach".
The following figure shows a WAS appserver and a MQ queue manager running on different hosts.

This topology is vulnerable because interoperation ceases if any of the following conditions occurs:
- The WAS appserver fails.
- The host on which the WAS appserver is running fails.
- The MQ queue manager fails.
- The host on which the MQ queue manager is running fails.
You could improve the robustness of this topology by using, for example, HACMP to restart the failed component automatically.
- The WAS appserver and the MQ queue manager run on the same host
- The MQ transport type for the connection is specified as "bindings", that is, a cross-memory connection is established to a queue manager running on the same host. Bindings mode is also known as "call attach".
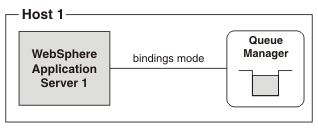
The availability considerations of this topology are similar to the previous one. However, in some configurations bindings mode is faster and more processor efficient than client mode because the potential processing overheads are less.
WAS appservers are clustered but MQ queue manager is not clustered
There are two topology options:
- The MQ queue manager runs on a different host from any of the WAS application servers
- The WAS application servers run on several hosts, one of which hosts a MQ queue manager
- The MQ queue manager runs on a different host from any of the WAS application servers
-
The MQ transport type for each connection is specified as "client". In the following figure:
- WAS appservers 1 and 3 are running on Host 1
- WAS appserver 2 is running on Host 2
- MQ queue manager is running on Host 3
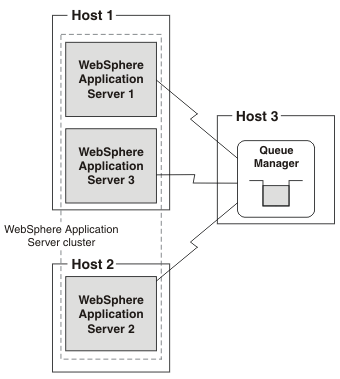
- If any clustered WAS appserver fails, or the host on which it is running fails, the remaining application servers in the cluster can take over its workload.
- If the MQ queue manager fails, or the host on which it is running fails, interoperation ceases.
We can improve the robustness of this topology by using, for example, HACMP to restart the failed queue manager automatically.
- The WAS appservers run on several hosts, one of which hosts a MQ queue manager
-
For WAS appservers that are running on the same host as the MQ queue manager, the MQ transport type for the connection is specified as "bindings then client" mode, that is, if an attempt at a bindings mode connection to the queue manager fails, a client mode connection is made. For WAS appservers that are not running on the same host as the MQ queue manager, the appserver automatically uses client mode.
The following figure shows some WAS appservers that are running on the same host as the MQ queue manager. Other appservers in the same WAS cluster run on a different host.
In the following figure:
- WAS appservers 1 and 3 are running on Host 1.
- WAS appserver 2 is running on Host 2.
- MQ queue manager is running on Host 1.
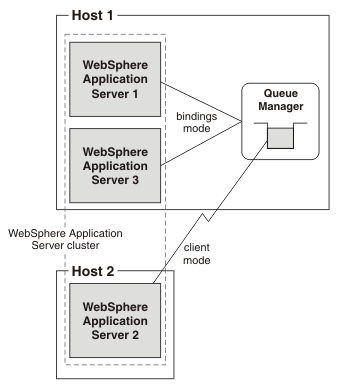
The following options make this a recoverable network topology:
- If any WAS appserver fails, the remaining appservers in the cluster can take over the workload.
- If the queue manager fails, we can restart it on the same host.
- If the host on which the queue manager is running fails, we can restart the queue manager on another host.
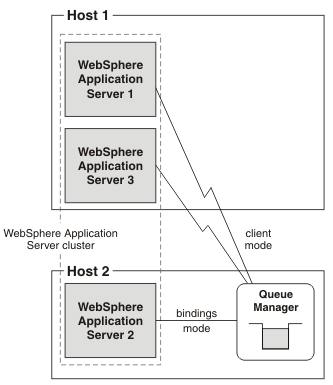
If we restart the queue manager on Host 2, as shown in the following diagram:
- Application server 2 connects to queue manager 2 using bindings mode.
- Application servers 1 and 3 restart on Host 1.
- Application servers 1 and 3 connect to queue manager 2 using client mode.
WAS appservers are clustered and MQ queue managers are clustered
MQ queue managers are usually clustered in order to distribute the message workload and because, if one queue manager fails, the others can continue running.
In a MQ cluster, one or more cluster queues are shared by all the queue managers in the cluster, and each cluster queue in a cluster must be given the same name. Other queue managers in the cluster distribute messages between the cluster queues in a way that achieves workload balancing.
There are two topology options:
- The MQ queue managers run on different hosts from the WAS appservers
- The MQ queue managers run on the same hosts as the WAS appservers
- The MQ queue managers run on different hosts from the WAS application servers
- In the following figure:
- WAS appservers 1 and 3 are running on Host 1.
- WAS appservers 1 and 3 attach in client mode to MQ queue manager 1, which is running on Host 3.
- WAS appserver 2 is running on Host 2.
- WAS appserver 2 attaches in client mode to MQ queue manager 2, which is running on Host 4.
Other queue managers that are part of the MQ cluster are not shown.
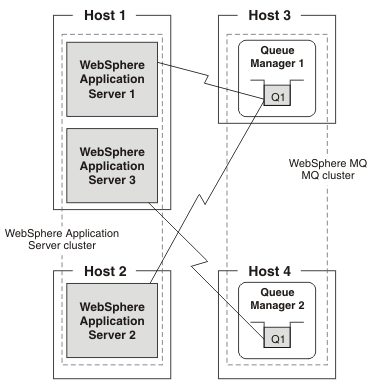
A queue manager that is part of this MQ cluster, but is not shown in the figure, distributes messages between the cluster queues in a way that achieves workload balancing.
- If WAS appserver 1 or 2 fails:
- The other WAS appserver can consume both of their workloads because they are both attached to queue manager 1.
- If WAS appserver 3 fails:
- Restart it as soon as possible for the following reasons:
- Other WAS appservers in the cluster can take over its external workload, but no other appserver can take over its MQ workload, because no other appserver is attached to queue manager 2. The workload that was generated by appserver 3 ceases.
- MQ continues to distribute work between queue manager 1 and queue manager 2, even though the workload arriving at queue manager 2 cannot be consumed by appserver 1 or 2. We can alleviate this situation by specifying a small maximum queue depth.
- If queue manager 1 fails:
-
- Messages that are on queue manager 1 when it fails are not processed until you restart queue manager 1.
- No new messages from MQ applications are sent to queue manager 1, instead new messages are sent to queue manager 2 and consumed by WAS appserver 3.
- Because WAS appservers 1 and 2 are not attached queue manager 2, they cannot consume any of its workload.
- Because WAS appservers 1, 2 and 3 are in the same WAS cluster, their non-MQ workload continues to be distributed between them all, even though appservers 1 and 2 cannot use MQ because queue manager 1 has failed.
- To contain this situation, restart queue manager 1 as soon as possible.
Although this networking topology can provide availability and scalability, the relationship between the workload on different queue managers and the Websphere Application Server appservers to which they are connected is complex. We can contact the IBM representative to obtain expert advice.
- The MQ queue managers run on the same hosts as the WAS application servers
- In the following figure:
- WAS appservers 1 and 3 are running on Host 1, and they attach to MQ queue manager 1 in bindings mode.
- WAS appserver 2 is running on Host 2, and attaches to MQ queue manager 2 in bindings mode.
- Queue managers 1, 2 and 3 are part of the same MQ cluster. Queue manager 1 is running on Host 1, queue manager 2 is running on Host 2, and queue manager 3 is running on Host 3.
Queue manager 3 is responsible for distributing messages between the cluster queues in a way that achieves workload balancing.

- If WAS appserver 1 or 3 fails:
- The other appserver can consume both of their workloads because they are both attached to queue manager 1.
- If WAS appserver 2 fails:
- Restart it as soon as possible for the following reasons:
- Other appservers in the cluster can take over its external workload, but no other appserver can take over its MQ workload, because no other appserver is attached to queue manager 2. The workload that was generated by WAS appserver 2 ceases.
- MQ continues to distribute work between queue manager 1 and queue manager 2, even though the workload arriving at queue manager 2 cannot be consumed by appserver 2. We can alleviate this situation by specifying a small maximum queue depth.
- If queue manager 1 fails:
-
- Messages that are on queue manager 1 when it fails are not processed until you restart queue manager 1.
- No new messages from MQ applications are sent to queue manager 1, instead new messages are sent to queue manager 2 and consumed by WAS appserver 2.
- Because WAS appservers 1 and 3 are not attached to queue manager 2, they cannot consume any of its workload.
- Because WAS appservers 1, 2 and 3 are in the same WAS cluster, their non-MQ workload continues to be distributed between them all, even though WAS appservers 1 and 3 cannot use MQ because queue manager 1 has failed.
- To contain this situation, restart queue manager 1 as soon as possible.
Although this networking topology can provide availability and scalability, the relationship between the workload on different queue managers and the Websphere Application Server appservers with which they are connected is complex. We can contact the IBM representative to obtain expert advice.