![]()
|
|
Our HACMP configuration was a typical configuration of HACMP's cascading resource group. Resources move through an ordered list of nodes from the highest to lowest priority in the group. In our configuration, all resources in the group are moved from the primary machine to its standby machine when the primary machine fails. During a failure, such as a network or hardware failure, HACMP on the primary machine notifies its peer services on the standby machine through the heartbeat communication. HACMP on the standby machine recognizes the failure event. It takes over the service IP address of the primary machine, mounts the shared file system and starts all registered servers, such as WAS. For our tests, IBM HACMP/ES 4.5.0.3 was installed on two systems with AIX V5.1 (note that the latest HACMP version is V5.2). All tests described in this chapter were performed using the same HACMP configuration.
We show the HACMP failover flow in Figure 11-1 and Figure 11-2. Before the failure (Figure 11-1), the disk array is attached to the primary machine, called Machine1. WebSphere services run on the primary machine. Clients make requests to the primary machine using the virtual network interface called hacmp1.
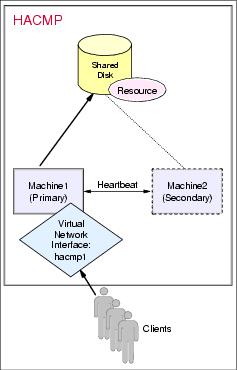
Figure 11-1 Before failover
When a hardware or software failure happens, the HACMP system detects the failure and executes the failover procedure. After the failover, as shown in Figure 11-2, the disk array and the virtual network interface are attached to the secondary machine, Machine2. The WebSphere services now run on the secondary machine.
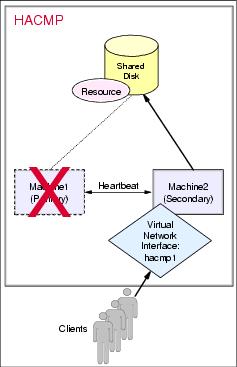
Figure 11-2 After failover