![]()
|
|
When stopping and restarting appservers, it is important to consider the correlation with the Web server plug-in retry interval. This is especially important in an environment with only a few appservers.
We need to understand the rate between starting and stopping appservers in a cluster and the retry interval so that you do not get HTTP request failures when you stop appservers in a cluster. The retry interval tells the Web server plug-in how long to wait before retrying an HTTP request against a specific appserver. If you stop and start appservers in a cluster faster than the retry rate, then a situation can occur where the plug-in assumes that two or more appserver are down, when in fact they are not.
Here is an example of this situation. Let us assume the following:
The Web server plug-in sends a request to a specific appserver and if that server is unavailable, it marks it as down. The request is then sent to the next appserver in the cluster. The plug-in does not retry the marked down server until the retry interval has passed.
In our example, because the retry interval is longer than the recycle time, there are time slots where one server's retry count has not yet expired. So, the plug-in does not retry that server (even though it might be back up), and the other server is down. Thus, there might be a time slot where the Web server plug-in thinks that both servers are down. Figure 4-3 illustrates this example.
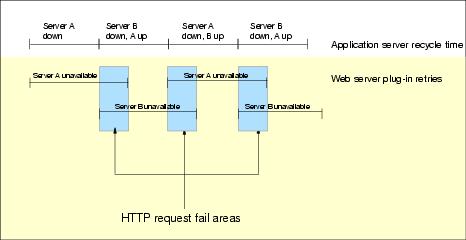
Figure 4-3 Correlation between retry interval and stopping servers
In an environment with two appservers per cluster, the plug-in cannot forward the request to any appserver and, thus, returns an HTTP request failure. If there are more than two appservers in the cluster, the plug-in routes the request to the remaining active servers in the cluster. However, depending on the difference between the retry interval and the appserver recycle time, there might be more than two appservers that are perceived to be unavailable at any given time.
To avoid this problem, increase the recycle rate to be at least as long in duration as the retry interval. If your retry interval is 60 seconds, then delay at least 60 seconds between starting one appserver and stopping another appserver. You can verify the retry interval setting either by using the Administrative Console (Servers | Web servers | WebServer_Name | Plug-in properties | Request Routing) or by looking at the plugin_cfg.xml file.
If it is not possible to add an appropriate delay between recycling servers, then ensure that your remaining appserver environment has the capacity to handle requests for the application assuming that two (or more) of the appservers are unavailable at the same time.
So, there are two maxims to remember:
1. Do not stop an appserver in a shorter duration than the retry interval.
| 2. | If you stop an appserver in a shorter duration than the retry interval, ensure that the set of remaining active servers can handle the capacity of having two appservers unavailable for a period of time equal to the retry interval. |