|
5.5.3 WebSphere Application Server clusteringTo improve performance in the Web servers for cached content, we used FRCA. The same FRCA feature can be used by the Web containers on the appserver tier, but the benefits are less. The appserver tier primarily serves dynamic content from JSPs and servlets, and this dynamic caching is supported with an FRCA implementation on the Windows platform but not on AIX. As before, the FRCA kernel extension is loaded using frcactrl load, usually as part of the AIX startup initiated in /etc/inittab. WebSphere Application Server has its own Web caching mechanism for dynamic content called dynacache. This is called the "Dynamic Cache Service" in the WebSphere Deployment Manager System Console. It is enabled at the Application Server Container level for each appserver instance. It is also worth enabling Servlet Caching for the Web Container for the appserver instance. What is cached by the Dynamic Cache Service is controlled by the cachespec.xml file that is created for each application module and put in the WEB-INF and META-INF directories for the given application module. The contents of the cache can overflow to disk if configured at the appserver container level by enabling disk offload for the Dynamic Cache Service, but a different directory should be used for each appserver instance in a partition to avoid conflicts. Control over what is cached is handled by <cache-entry> entries in the cachespec.xml file. Because this can consist of WebSphere commands, Web services output and servlet output that are mostly application-level content, the configuration and use of this is normally something configured by the application team along with the WebSphere administrators, and is not a task for the AIX administrator. Edge Side Include Caching is another option for caching if the infrastructure is made slightly more complex. If this is the case, then the DynacacheESI application must be installed inside the appserver. Refer to WebSphere Application Server documentation for more information about this subject. When a request is received by the appserver instance, it is first examined by the Web container using an inbound channel that is routed to the appropriate application module using the configured URL mappings for cluster (see Figure 5-21). The request would have come into the given appserver instance using the instance (formerly clone) ID that was appended to the JSESSIONID cookie value or query string when the session was created. Before the Web module gets the request, a servlet filter (which is Java code sitting outside the application) is given access to the chain of the HTTP request to allow it to modify the request, and it gets access to the response that is generated further down the chain. While the request is being handled, a thread is tied up in the container, and any objects that are attached to the Java session object contain the state that represents the session for which that request is a part. To enable that state to be retained when an instance fails, the session can be configured for storage in a session state database, as identified previously in server.xml, or it can be replicated entirely by a fast reliable multicast messaging (RMM) protocol to other instances in the cluster, something known as the Data Replication Service or DRS. The DRS Session Buffer is shared with the HAManager Distribution and Consistency Services, so it should be made larger for high loads. The use of an active-active session database rather than replicating large session objects using DRS is preferred unless the use of only small session objects by applications can be guaranteed. Performance is likely to be higher for DRS at the cost of buffer usage, but the session database does reduce intracluster communications overheads.
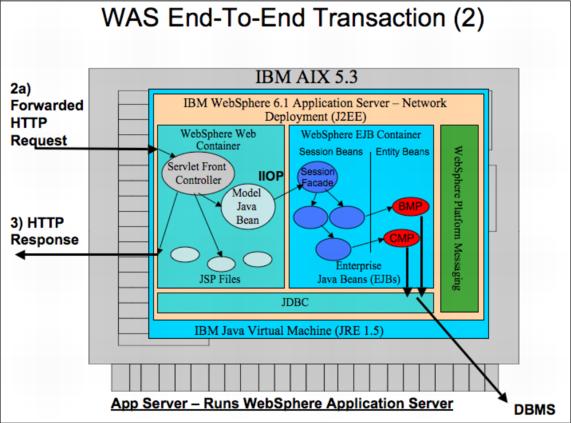
Figure 5-22 WebSphere Application Server end-to-end transaction path, part 2 The Web request is eventually passed on, in an application that fits a standard architecture, to a set of Enterprise Java Beans hosted in the EJB container. Usually a session façade is implemented as a session bean to "front" the application logic and entity beans or some other persistence mechanism. If the appserver environment is configured simply to run within the same Java virtual machine, then the request is merely passed between the two containers as a CORBA/IIOP request. However, if an extra tier has been introduced and the Web container and EJB container are configured on different partitions, then the EJB request is added to a queue of CORBA/IIOP requests. The appserver is designed to handle distributed transactions as an XAResource Coordinator with the use of the Java Transaction Service and the use of transactions within EJBs. Many things will result in an XA distributed transaction, such as EJBs with different configured transaction isolation levels and requirement, or a the use of a transactional write to a database with an entity bean followed by a JMS/MQ message controlled within the same transaction. To support this, the WebSphere Application Server uses transaction logs for commit and rollback, where transactions are only committed to the real environments rather than the logs after a two-phase commit. These logs are in the tranlog directory and there is one per server instance that is managed by the Transaction Manager. In our diagrams we have shown the use of a NAS device, but have yet to explain why. If the WebSphere Application Server instances in a cluster all place their logs on the same shared NAS device using NFSv4 where the other instances can see them, then after a failure, another node can apply those transaction log entries to ensure consistency. This is handled by the Transaction Manager and it is the job of the HAManager and Distributed Consistency Services (DCS) (usually using ports 9352 and 9353) to manage the consequences of the failover. The clusters use the concept of a core group to handle the groupings of instances for HAManager and failover, usually with the JVM ID with the lowest ID acting as the coordinator. The default is for the first process in the core group ordered lexically by name to act as coordinator. This should, however, generally be explicitly configured to prefer a process with low load. To ensure that the transaction logs are always available for recovery, the availability of the NAS device is now important. NFSv4 is required because this version of the NFS standard forces locks to be removed on timeout, which is required for recovery. The IBM N5200 and N5500 NAS devices, derived from the NetApp® FAS3XXX range, support this with the OnTap operating system and metro-cluster clustering. Versioning of changes is performed on these devices when a write occurs to allow rollback and online backup. Note that a third device is placed in a third data center to allow quorum to be maintained if there is a loss of communications between the two main data centers, to avoid split-brain scenarios and having both sites update shared data independently, resulting in inconsistency. However, this would only be used if disk cross-connectivity between sites and network connectivity fails. |