Back
WebSphere Portal V6 Enterprise Scale Deployment
- WebSphere Portal v6 Overview
- Composite applications and templates
- Personalize the Portal
- WebSphere Portal programming model
- Operations & Deployment
- Planning for the Portal 6.0 High Availability Deployment
- System Requirements
- Typical Deployment Scenarios
- Clustering Considerations for High Availability
- Recommendations and Best Practices: How many environments do I need?
- Introduction to the deployment scenarios used in this Redbook
- Horizontal cluster with single database and single LDAP
- Horizontal cluster with database domain
- Horizontal cluster with database domain and multiple LDAP
- Vertical cluster with single database and single LDAP
- Vertical cluster with database domain
- Vertical cluster with database domain and multiple LDAP
WebSphere Portal v6 Overview
The WebSphere Portal Server provides a personalized experience, which considers the user's identity, role, and personal preferences.
WebSphere Portlet Factory and WebSphere Portlet Factory Designer are bundled with WebSphere Portal v6. Run time and designer licenses are included in all three editions of WebSphere Portal Server.
WebSphere Portlet Factory is a comprehensive portlet development environment that automates the process of creating, deploying, and maintaining SOA-based portlets. Non-programmer employees can use WebSphere Portlet Factory to create portlets which access the company's existing application; these portlets can then be assembled as building blocks into composite applications.
WebSphere Portal v6 therefore includes a workflow builder as a technical preview which enables business users to create and modify departmental workflows which, in a non-portal environment, would typically be implemented as email flows.
Many interactions today involve the creation or completion of forms. When you arrive at an international airport, check into a hotel, provide conference feedback, and many other situations, you are required to fill out forms, which businesses and agencies use to collect and structure data. Forms are a pervasive information exchange vehicle.
We can use IBM Workplace Forms with WebSphere Portal V6.0 to...
- Include electronic forms in a standard portal interface
- Enable users to access information from other applications
- Enable users to collaborate to create, edit, or view electronic forms
Behind the scenes, WebSphere Portal V6 leverages the web development language Ajax (Asynchronous JavaScript and XML) in several places to move UI logic from the server into the browser. For example, contextual menus are implemented based on Ajax. The appropriate choice of menu options is determined on the browser system without request/response roundtrips to the portal server. WebSphere Portlet Factory uses Ajax to implement a “type-ahead” capability and to refresh UI fragments within a page.
Composite applications and templates
WebSphere Portal V6 introduces composite applications. Business analysts and application designers can assemble composite applications which implements business logic from individual components, such as...
- portlets
- processes
- artifacts
Composite applications use two fundamental aspects:
- templates
- applications
Templates
A template describes a composite application in an abstract way, including information which defines how complex business logic is assembled out of a given set of components. The template is an XML file which references all components, such as portlets or Java code artifacts, and specifies applicable meta information, such as specific configuration settings for each individual component. The template describes the composed application behavior by defining the desired interaction between the components, such as wires between portlets, and access control logic to be enforced, such as application specific user roles.
The people who understand the business logic create the templates. The Template Builder is a portlet and is very similar to the page customizer.
Once created, templates are stored in a template library and are made available to be consumed by the user community. Again, templates are XML files which represent the abstract definition of a composite application.
Applications
Because templates are stored in a template library, a user can pick a template and create a new instance of the composite application that is described by the selected template definition. Users can manage their application instances based on their own needs.
An example of templates and applications
Here is an example to show how templates and applications can be used.
A development team designs a company specific teamroom application. First, the team makes sure that they have all the components they will need to assemble the intended functionality. In most cases, they simply pick portlets and logic from a catalog. In some cases, they implement a component from scratch. Once the components have been identified, the application designer assembles the teamroom application by adding and arranging components as desired. The result is stored as an XML file in the template catalog and it is made available to all registered portal users within the company.
In the example, a project manager would create his individual teamroom instance for his project and use this instance together with his colleagues. From the common template definition, there would soon be a growing number of teamrooms within the company.
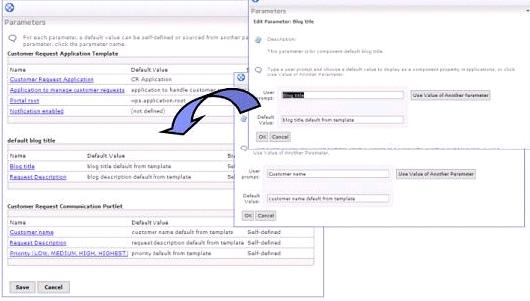
Points of variability (Parameters)
It is not realistic to assume that each instance of the same template is supposed to behave exactly the same. Typically, you want each application to have a unique configuration in certain places. In the teamroom example, the specific title of a teamroom needs to be set. WebSphere Portal V6 lets you define parameters in the template, wherever a point of variability is needed. During instantiation, the creator of the application fills in the specific value for each parameter, and these values are applied to that particular instance only.
In the example, the developer of the teamroom template specifies the teamroom title as a parameter. Later, each project manager enters a meaningful title when he or she creates a specific teamroom instance. This concept of parameterization adds flexibility to the usage of the predefined templates.
Application roles
We can define access control settings through templates. The template developer specifies roles, which are meaningful in the context of this particular composite application.
For example, a teamroom template would have the roles “project lead”, “project member”, “guest”, and “administrator”. Each of these application roles aggregates a set of very specific portal access control roles. A project member might have editor access to the FAQ portlet as well as manager access to the document repository, while a guest would only have user access to the FAQ portlet and no access at all to the document repository. We can hide the complexity of many access control roles to individual components and expose them as few simplified application level roles with well-understood and easy to use names.
Membership
Once a template is instantiated, the resulting application can be used by a community of users. The owner of the application adds members to the community as needed, and assigns each new member to the pre-defined application level roles. End-users can perform the user administration of their applications on their own.
Workflow
We can use workflow capabilities in the composite applications. New in WebSphere Portal V6 is the Workflow Builder portlet, which enables users (such as business analysts or application designers) to define processes. The create process definitions are treated as components within a template and can be used in the context of composite applications. For example, you could add a Workflow called “Document review process” to the Teamroom sample application.
Important: The Workflow Builder is a Tech Preview in WebSphere Portal V6.0.
Personalizing the Portal
WebSphere Portal lets you personalize the portal for different groups of users, and we can enable administration based on attributes. Originally, portal servers let you customize the content that the end user sees based on the user's role. For example, a user in the manager group has access to the portlet displaying the salaries of his or her employees. Now in WebSphere Portal V6, we can define rules to modify the content the end user sees based on the current request and set of rules that apply to this request.
WebSphere Portal V6 enables administrators to provide content based on specific attributes or rules so that each user's experience can be unique. Specifically, we can:
- Filter content using rules, based on meta information attached to a user. For example, provide different content to a gold customer vs. standard customer.
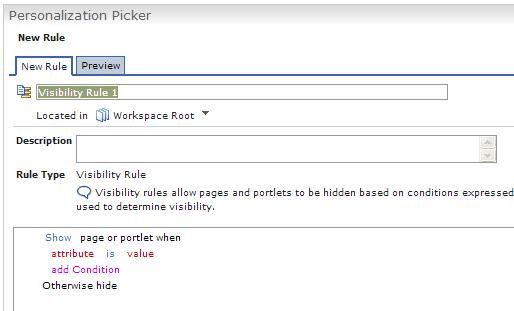
- Use attribute-based administration to define visibility rules that show or hide content based on user meta data. For example, display a specific page or portlet each Monday which shows the goals for this week.
- Set policies and define specific properties that can be queried to influence the behavior of a portal resource or the user experience. For example, set the mail size quota.
We can also combine these different concepts. That is, if a user is a gold customer, you could make that customer's mail size quota larger than for standard users.
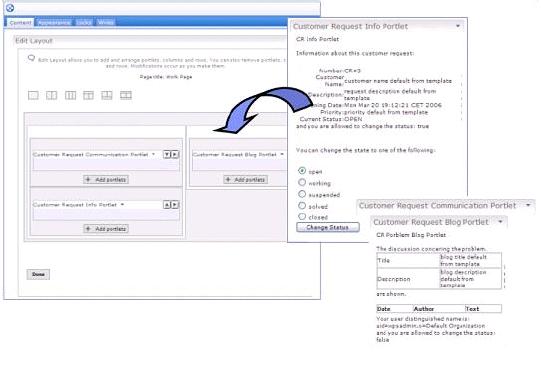
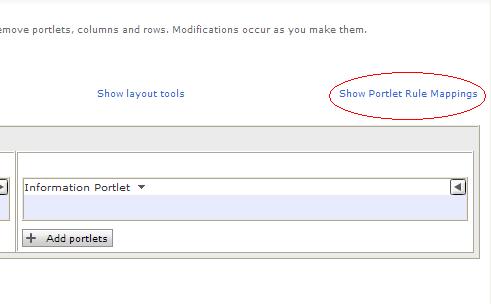
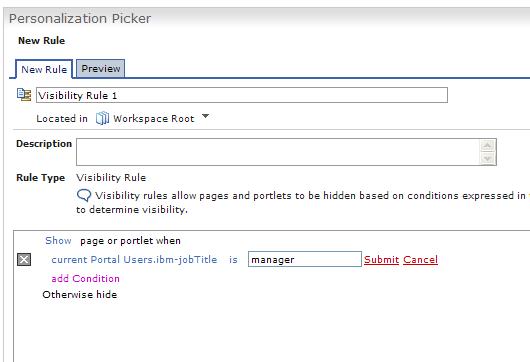
Figure 1-9 shows the Edit Page with Show Portlet Rule Manager enabled (see upper right side, which indicates the opposite toggle option available, Hide Portlet Rule Manager). We can now define a specific rule for each portlet that influences the visibility of that portlet.
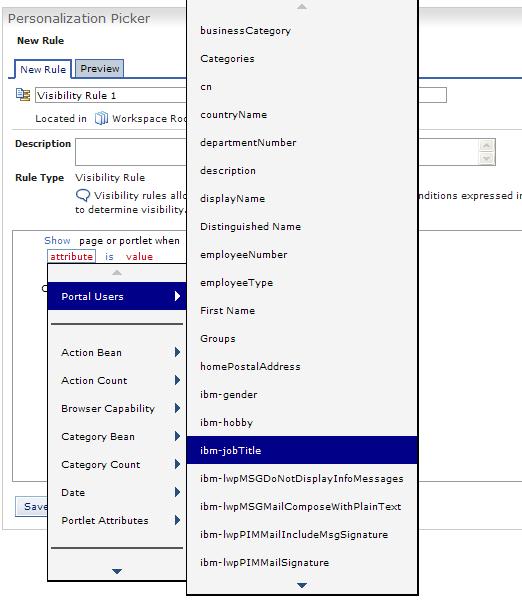
If you click on the Create New Rule button, the Personalization Picker portlet displays. Then, we can enter a specific rule.
In the default rule, click on any of the words which are displayed in some color other than black, and a wizard opens.
Then, we can select attributes to be evaluated for a specific rule. In the example below you want to evaluate one attribute of the user management system; so, you select Portal Users. A popup window displays, listing the available user management properties. You select ibm-jobTitle from this list.
You add a specific value that the selected attribute must have in order to run the rule. For this example, you require that the current user's job title be manager in order to display this portlet to a user.
New in the v6.0 programming model
Let’s take a look at things that WebSphere Portal V6.0 adds on top of the base programming model. You have already discussed some enhancements in the previous sections, such as composite applications, personalization, and rules.
WebSphere Portal V6.0 programming model new features include:
Composite applications Create business applications and templates as described above. Themes and skins extension points We can use defined extension points to customize the default themes and skins. We can separate the customization code from the default themes and skins code; then, we can update the default themes and skins code, without affecting the customizations. Drag and drop Define your own drag sources and drop targets to leverage the new drag and drop functionality in the portlets, themes and skins. Policies Create your own policies and plug into the policy and personalization system. Support for the Edit Default mode Administrators and business users can distinguish between default settings they want to set on a portlet that is shared among users, and the private settings which can be set in Edit mode. Advanced Portlet URL Generation capabilities Use the URL Generation SPIs introduced for themes and skins in V5.1.0.1 in portlets to create URLs pointing to other pages and portlets. WebSphere Portal V6 also provides a simplified version of this SPI as URL Generation API that is easier to use for the most common cases. Additional portal model and state SPIs Get aggregated meta data; also, get and set the current page locale. Search Use a common search API for the various search engines available from IBM. Workflow Create your own data objects that are processed through the workflow builder tool. WebSphere Portal V 6.0 provides additional extensions to APIs which are available already in WebSphere Portal V5.1.0.1, such as..
Another thing to note in WebSphere Portal V6.0 is that the IBM Portlet API is now deprecated in order to show IBM’s commitment to the JSR 168 standard Portlet API. Also, many of the new functions will only be available to standard portlets.
The IBM Portlet API will still be supported in this and at least the next release. However, if you are going to touch one of the IBM Portlets anyway, you recommend that you port it to the standard API.
For more information on how to migrate the IBM portlet to the standard Portlet API see Compare the JSR 168 Java Portlet Specification with the IBM Portlet API and Convert the WorldClock portlet from the IBM Portlet API to the JSR 168 portlet API
Content & Web content management
IWWCM has been re-based on the JSR 170 standard, which is the same repository used for Portal Documents.
Using JSR 170 for the Java Content Repository (JCR) makes it easier to personalize content
IWWCM administration is simpler because its nodes can now share the same repository, allowing full clustering support in both production and authoring environments.
The use of WebSphere logging and WebSphere caching services and WebSphere Portal access control management also help to simplify administration.
The JCR provides a way to better organize content into content libraries. This capability had already been used by Portal Document Manager and is now used by Web Content Manager. Libraries help you to better manage Web content, making it easier to control...
- access rights
- separate test content from production content
- organize multi-language content
- share content between sites
The user experience for content authors has been simplified and enhanced. New data types such as links, numbers and dates, searching, custom help, limit checking, improved navigation, views and better rich text editing have been added. We can now author live content directly within a site by employing a new in-line authoring component.
Both content authors and end users can more searched content. Portal search collections can include Web content, and we can include a new search component into sites designed with IWWCM.
WebSphere Portal Document Manager now lets you access documents directly from the Windows Desktop or from Microsoft Office products. Document libraries appear as network places in the Windows Explorer, giving you easy access to document management functions such as locking, versioning, and editing. The performance of the Portal Document Manager has been improved to save document renditions and streamline document preview.
Multiple LDAP support
In previous versions of WebSphere Portal Server, you could only use one LDAP directory to store user account information.
Users contained in the LDAP directory could however be logically grouped in to one or more “realms” (sometimes referred to as “horizontal partitioning”), and these realms could then be tied to specific portal configurations (referred to as “virtual” portals), serving up different content depending on which realm the authenticating user belonged to.
A single LDAP directory does however represents a potentially significant single point of failure, and in previous versions of WebSphere Portal Server, LDAP directory redundancy was provided by having multiple identical replicas of the LDAP directory in the environment.
Failover to one of these identical replicas had to be taken care of by a third party load balancer product such as IBM Network Dispatcher.
WebSphere Portal Server v6 however overcomes these limitations by
- Extending the concept of realms to introduce support for multiple LDAP directories
- Providing automatic failover to additional LDAP directory replicas without the need for a third party load balancer.
Multiple LDAP directory support therefore reduces infrastructure investment and complexity as there is now less of a need for directory integration or user consolidation approaches.
It also allows us greater flexibility when deploying a WebSphere Portal infrastructure inside and outside of firewalls, especially when using multiple LDAP directories in conjunction with the previously mentioned “virtual portal” capability.
Redundancy and failover can now be catered for much more simply with WebSphere Portal Server v6, by combining the strategy of previous versions of having multiple read-only LDAP replicas or “shadows”, however now you no longer require any additional infrastructure components like an LDAP load balancer.
In the case that one LDAP directory becomes unavailable, Portal will seamlessly connect to any of the other (identically) configured read-only LDAP directories that might be available.
Database Domains
WebSphere Portal V6 provides enhanced flexibility in portal data management. The portal configuration repository now consists of independently manageable database or schema objects (database domains).
By separating the data, we can share domains across multiple portals. With the shared data domains feature, operators can provide continuously available (24x7) portal sites with full Customization support, while keeping operation procedures simple. Operators can create multiple independent lines of production so they can change configurations, apply maintenance, stage solution releases to one line at a time, while keeping other lines completely available to portal users.
Operators can also now spread different data domains across different database types. We can select the most effective data base type for each domain to reduce operation cost and to provide the right level of availability for each domain.
The separation of portal data into multiple domains provides more options for operators to establish a distributed portal operation. With separation of data at the database level, the replication of data has become easier. With database replication per data domain (using database provided replication mechanisms), operators can create globally distributed portal sites that are individually managed and operated. Each portal site will have a dedicated release data domains and shared user customization data domains.
Releases can be staged into sites independently of other sites (for example, using XMLAccess). Staging lets you make identical portal solutions available on multiple sites. While multiple sites within the same location typically might share the same database server for cutomizations, in a global deployment with higher location independence requirements, user customizations can be hosted locally in each site with 2-way replication between the sites. Users can access their customized portal site independently of the site that services their requests.
Database replication scripts are not part of the WebSphere Portal offerings. You need to create scripts to match specific infrastructure needs. We can also consider using database replication mechanisms provided by database vendors.
In WebSphere Portal V5.1 all data is part of a single DB repository. But the type of data existed already it was simply not split into domains. In WebSphere Portal V6, the portal repository consists of the following data domains: Release, Community, Customization, Feedback, LikeMinds, JCR, and Member Manager.
Release data are typically not modified during production (such as administrator defined pages, portlets, and portlet instances). Typically administrators create release data on an integration server and stage it to the production system. Community data are typically modified during production (such as shared documents or application resource). Documents and Web content are stored in the JCR. Customization data are associated with a particular user only. A Typical example of customization data is portlet data. Feedback and LikeMinds data are created and used during productive use of the portal by the Portal Personalization Runtime. Member Manager Data contains user profile data, for example look aside user profile data. More information on data domains and data domain administration is provided in the WebSphere Portal V6 Infocenter, Transferring individual domains section. ( See Appendix , “Related publications” for more information).
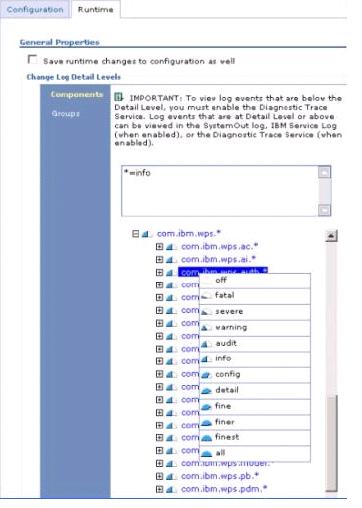
Portal Configuration Management enhancements in WebSphere Portal V6 help operators become more efficient in managing the portal infrastructure. Operators can now configure WebSphere Application Server and WebSphere Portal Server from a single console or command line. We can display and change configurations for stand-alone portal servers as well as entire portal clusters consisting of multiple nodes. We can set runtime configurations and use graphical wizards for problem determination, and then view the results in a single place. See runtime trace setting options in Figure 1-17.
Planning for the Portal 6.0 High Availability Deployment
This chapter provides the planning information for successfully building a Portal 6.0 high availability cluster including system requirements, typical deployment scenarios, clustering considerations, and content management considerations.
For the latest information see...
www.redbooks.ibm.com/redpieces/abstracts/sg247387.html
System Requirements
This section is an overview of the Hardware, Software and Network connectivity requirements for running IBM WebSphere Portal 6 on various supported operating systems. A detailed list of required software and hardware fixes is provided in the Portal Information Center.
IBM WebSphere Portal, v6.0 Information CenterLink:
Check the Portal 6 Information Center for the latest software or hardware fix requirements as this information may be updated periodically in the information center to reflect new supported configurations.
Hardware Requirements
This section provides data for hardware configurations that have been tested by IBM. Use the following information as a guide for the installation of WebSphere Portal.
IBM AIX systems
Processor:
- RS/6000 at 450MHz at a minimum; production environments should consider higher speeds.
- Power5
Physical memory: 4G is an optimal starting point for RAM in a production environment.
Disk space:
Virtual memory/swap space: - This value should be equal to double the physical memory.
- Install directory: 3.5 GB
- Temp directory: 1.5 GB
HP-UX systems
Processor: - HP 9000 on PA-RISC at 440 MHz or faster
Physical memory: 4G is an optimal starting point for RAM in a production environment.
Disk space:
- Install directory: 3.5 GB
- Temp directory: 1.5 GB
Virtual memory/swap space: - This value should be equal to double the physical memory.
Linux Intel systems
Processor: - Production environments should consider the Pentium 4 processor at 1.4GHz or higher.
Physical memory: - 4G is an optimal starting point for RAM in a production environment.
Disk space:
- Install directory: 3.9 GB
- Temp directory: 1.5 GB
Virtual memory/swap space: This value should be equal to double the physical memory.
Linux on POWER
Processor: POWER is a term used to refer to IBM system product lines including...
- iSeries models that support LPAR (64-bit support only) with minimum of 450 CPW in Linux partition
- pSeries models that support Linux (64-bit support only)
- BladeCenter JS20
- OpenPower
- Power5
...that are based on IBM Power Architecture technology and run the same Linux distributions from Red Hat and Novell SUSE.
Physical memory: 4GB is an optimal starting point for RAM in a production environment.
Disk space:
- Install directory: 3.9 GB
- Temp directory: 1.5 GB
Virtual memory/swap space: This value should be equal to double the physical memory.
Important: For any linux operating system, the libstdc++-3.3.3-41 shared object library is required prior to installation of WebSphere Portal.
Linux on System z
Processor: z800, z890, z900, z990, z9
Physical memory: Under minimal load, WebSphere Portal can function with 2GB of RAM. However, 4GB is an optimal starting point for RAM in a production environment.
Disk space:
- Install directory: 3.9 GB
- Temp directory: 1.5 GB
Virtual memory/swap space: Swap space on z/Linux is recommended to be 15% of the virtual machine size.
Sun Solaris systems
Processor: Sun Blade 2000 workstation at 1 GHz or higher is recommended.
Physical memory: 4G is an optimal starting point for RAM in a production environment.
Disk space:
- Install directory: 3.2 GB
- Temp directory: 1.5 GB
Virtual memory/swap space:
- This value should be equal to double the physical memory.
- For Solaris 9, swap space must be double the physical memory, especially if the physical memory is 1024 MB per processor.
Microsoft Windows systems
Processor: Production environments should consider the Pentium 4 processor at 1.4GHz or higher.
Physical memory: 4G is an optimal starting point for RAM in a production environment.
Disk space:
- Install directory: 3.9 GB
- Temp directory: 1.5 GB
Virtual memory/swap space: This value should be equal to double the physical memory.
File system: NTFS file system is recommended.
ID="LinkTarget_54900">Software Requirements
Supported operating systems (required on portal machine)
- Win XP SP1, SP2 - development
- Win 2000 Server SP4 and Advanced Server SP4
- Win 2003 Standard and Enterprise SP1
- Red Hat Enterprise Linux ES, AS, WS, Desktop for (x86) 3.0 U6 & 4.0 (WS & Desktop are only supported as developer platforms)
- Red Hat Enterprise Linux AS for (Power) 3.0 U6 & 4.0
- Red Hat Enterprise Linux AS for (zSeries) 3.0 U6 & 4.0 U1
- SuSE, SuSE SLES 9, 2.6 Kernel (x86) SP1 (SuSE is only supported as a developer platform)
- SuSE SLES 9, 2.6 Kernel (Power) SP1
- SuSE SLES 9, 2.6 Kernel (zSeries) SP1
- AIX 5.2 ML05
- AIX 5.3 5300-02 Maintenance Level
- Solaris 9 with the Recommended Patch Cluster of November 2005 (or later)
- Solaris 10
- HP-UX - V11iV1, V11iV2 (V11iV2 requires a paper certification for V11iv2 support based on V11iV1 testing)
Supported application servers (required on portal machine)
- WebSphere Application Server v6.0.2.9 or later Base + WebSphere Process Server. The install images of the required v6.0.2.9 interim fixes can be found on the WebSphere Portal Setup CD. Example for iSeries is:
- WebSphere Application Server v6.0.2.9 or later Base or WebSphere Application Server v6.0.2.9 or later Network Deployment + WebSphere Process Server Version
6.0.1.1
- WebSphere Application Server v6.0.2.9 or later Base + Certain components of WebSphere Process Server v6.0.1.1
Supported Web servers (optional)
Apache Server 2.0.49 & 2.0.52
– Includes CERT Advisory CA-2002-17
- + IBM HTTP Server 2.0.47.1
– The fix PK13784 is also required.
IBM HTTP Server 6.0, 6.0.1, 6.0.2
– The fix PK13784 is also required.
- Microsoft Internet Information Server 6.0
– Supported on Microsoft Windows Server 2003.
- + IBM Lotus Domino (as Web server) 7.0
- IBM Lotus Domino (as Web server) 6.5.5
- IBM Lotus Domino (as Web server) 6.5.4
- Sun Java System Web Server, Enterprise Edition 6.1 SP3
- Sun Java System Web Server, Enterprise Edition 6.0 SP9
Supported databases (required)
- + IBM Cloudscape Version 5.1.60.41
- + IBM DB2 Universal Database Enterprise Server Edition 8.2 FP5
- IBM DB2 Universal Database Enterprise Server Edition 8.1 FP12
- + IBM DB2 Universal Database Workgroup Server Edition 8.2 FP5
- IBM DB2 Universal Database Workgroup Server Edition 8.1 FP12
- Oracle Enterprise Edition 10g Release 1 and Release 2
- Oracle Standard Edition 10g Release 1 and Release 2
- Oracle Enterprise Edition 9i Release 2
- Oracle Standard Edition 9i Release 2
- Microsoft SQL Server Enterprise Edition 2000 SP4
Supported LDAP directories (optional)
- IBM SecureWay Security Server for z/OS and OS/390 Versions 1.4, 1.5, 1.6, 1.7, or
- IBM Tivoli Directory Server V6.0
- + IBM Tivoli Directory Server V5.2
- + IBM Lotus Domino 7.0.1
- + IBM Lotus Domino 6.5.5l
- +IBM Lotus Domino 6.5.4
- Novell eDirectory 8.7.3
- Sun Java System Directory Server V5.2
- Microsoft Active Directory 2003
- Microsoft Active Directory 2000
- Microsoft Active Directory Application Mode (ADAM) 2003
Supported Web browsers (required)
- Microsoft Internet Explorer V6.0 SP1 (SP2 for Windows XP)
- Microsoft Internet Explorer 6.0 SP1
- FireFox 1.5.0.3
- Mozilla Web Browser 1.7
- Netscape Communicator 8.1
- Apple Safari 2.0
Supported external security software (optional)
- IBM Tivoli Access Manager for e-business v6.0
- IBM Tivoli Access Manager for e-business Version 5.1
- Computer Associates eTrust SiteMinder 6.0
- Computer Associates eTrust SiteMinder 5.5
Network Connectivity Requirements
The following list provides network connectivity requirements for a Portal 6.0 High Availability Deployment
Network adapter and connection to a physical network that can carry IP packets, for example, Ethernet, token ring, ATM, and so on.
- Static IP address with an entry in DNS.
- Configured fully qualified host name. Portal 6.0 High Availability Deployment must be able to resolve an IP address from its fully qualified host name. To ensure that the host name is correctly configured in DNS, type one of these commands at the command line of another server in the network:
- ping hostname.yourco.com
- Windows: nslookup hostname.yourco.com
- Linux: dig hostname.yourco.com
Typical Deployment Scenarios
This section focuses on typical Deployment Scenarios in WebSphere Portal 6 including...
- Simple single server topology
- Vertical scaling topology
- Horizontal scaling topology
- Mixed horizontal and vertical scaling topology
Single Server topology
In a single server installation all of the components are installed on the same machine.
Simplest Portal installation. Often used for a proof of concept or a demo machine. The emphasis of a single server installation is on getting it up and running . At the end of the scenario we can build out the topology to include an external database and/or an LDAP user registry for user authentication or collaboration function as well as an external http server.
Vertical Scaling topology
Vertical scaling topology includes multiple application servers running WebSphere Portal on a single physical machine. We can use vertical scaling to fully use a node within the conceptual node group in the case where resource congestions or locking conditions prevent a single application instance to scale up to the nodes limit. Note that multiple java processes will be instantiate when using vertical scaling.
This clustering approach does not provide additional hardware and capacity
Horizontal Scaling topology
In a Horizontal scaling topology members of a WebSphere Portal cluster exist on multiple physical machines, effectively and efficiently distributing the workload of a single logical WebSphere Portal image. Clustering is most effective in environments that use horizontal scaling because of the ability to build in redundancy and failover, to add new horizontal cluster members to increase capacity, and to improve scalability by adding heterogeneous systems into the cluster.
Mixed horizontal and vertical scaling topology
Mixed horizontal and vertical scaling topology is the best practice approach for large scale deployments.
The use of vertical clustering takes full advantage of the resources of a multiprocessor system. In addition, horizontal cloning allows for upward scalability. To maximize security, horizontal clones should reside in different geographic locations to guard against natural disaster or site outages.
Clustering Considerations for High Availability
This chapter focuses on considerations that allow you to operate the Portal infrastructure 24X7 while providing SOA capabilities. These considerations will allow you to build a system that is architecturally designed for continuous operation.
WebSphere Process Server Considerations
WebSphere Portal provides business process integration support through IBM WebSphere Process Server. It also ensures inter operability and flexibility as part of the service oriented architecture (SOA) through adoption of popular standards, such as BPEL, Web services, JMS, XML, and many more. Because a cluster must consist of identical copies of an application server, either every instance of WebSphere Portal must be installed with WebSphere Process Server or every instance of WebSphere Portal must be installed without WebSphere Process Server.
Important: Business process support cannot be federated into a Deployment Manager managed cell after installation.
Process server features and benefits:
Feature Benefit Integrates more out-of-the box Web services, application adapters, and advanced messaging capabilities Maximize value and reuse of all the assets using the right quality of service to meet the business need at that time. WebSphere Process Server can natively integrate with WebSphere ME infrastructures throughout the enterprise, in addition to leveraging the embedded JMS provider, Web services, and a wide range of application and technology adapters. Allows easy-to-use comprehensive human-centric business process management (BPM) scenarios Better management and flexibility of human related tasks including dynamic balancing of staff workloads, assigning work across a team, applying work management policies. reflecting organization structure and change, automated task feeds Integration with IBM WebSphere Service Registry and Repository Deliver a tailored service to each customer (each process instance) with real time dynamic choices at each step of the process based on customer need and service level. Supports service governance with dynamic run-time discovery and invocation of services. WebSphere Service Registry and Repository integration with WebSphere Process Server provides true end-to-end governance for all services, dynamically discovering and invoking services and service metadata information at runtime. This allows real-time process behavior adaptation. Provides run-time administration improvements (dynamic reconfiguration, with no need to rebuild or redeploy) Administer, manage, and change processes without deploying Enables tight integration between information services and business processes Make the right decisions based on the right information at the right time Faster authoring of BPM solutions and easier integration to external services (WebSphere Integration Developer Tools but reflected in WebSphere Process Server runtime) Allows integration developers to focus on creating business value by reducing solution maintenance and debugging
Multiple LDAP Overview
The use of multiple LDAP directories will have a significant bearing on how you deploy and maintain WebSphere Portal, therefore it is important to understand what the advantages are of using more than one LDAP directory.
Advantages
- Greater deployment flexibility for WebSphere Portal.
- Reuse existing directories that may already contain important user data.
- Minimize or negate the need for directory consolidation.
- No need to change administration practices.
- Minimizes the LDAP directory being a single point of failure.
Database Domain (database split) Overview
To maximize availability, data may be distributed across multiple databases and shared between multiple lines of production.
Portal data is can be categorized into four categories:
- Configuration data defines the portal server setup, such as database connection, object factories, and deployment descriptors. This type of data typically is constant over the uptime of a server node. Configuration data is typically kept in property files on the hard disk. This data is either protected by file system security or application server administration rights.
- Release data are all portal content definitions, rules, and rights that are possibly designed externally and then brought into the portal by a staging process, such as...
- Page Hierarchy
- available Portlets and Themes
- Templates
- Credential Slots
- Portal Personalization Rules
- Policies
These resources are typically not modified during production and need administrative rights to do so. Administrators typically create release data on an integration server and stage it to the production system. Release data are protected by PAC and contain only data, not code. In a setup that consists of multiple lines of production, one copy of the release data exists per cluster. Administrators must verify the content of the release databases is consistent across the different lines, in particular after modification of the release data on the production system.
- Customization data are data that is associated with a particular user only and that cannot be shared across users or user groups. Typical examples are Portlet Data or Implicitly Derived Pages. Since this data is scoped to a single user only, PAC protection is simplified to a great extent. In a setup that consists of multiple lines of production, customization data is kept in a database that is shared across the lines of production. Therefore the data is automatically in sync across the lines of production.
- Community data are all resources that are typically modified during production, such as shared documents or application resource.
Typically users and groups are allowed to modify or delete shared resources. Community Resources are protected by PAC. Since documents are a preferred class of shared resources that are supported with its own storage mechanism, this type of resource will have 2 subcategories:
- JCR Data: Comprised of all the documents using this storage mechanism
- Application Data: Comprised of all the other shared application data, which are not documents
In a setup that consists of multiple lines of production, community data is kept in a database that is shared across the lines of production. Therefore the data is automatically in sync across the lines of production.
Separation of the portal data in the described classes allows you to store each class in its own set of database tables or the file system. The set of databases tables for one of these resources are called database domains. These database domains can now be moved into different databases, which may even be shared with other portal installations.
For maintenance and staging purposes you may take a single line of production out of service while the other line is still serving requests with the old data. Once the first production line is updated it is taken into service again, and the second line is now updated using the same approach. Updates of data in the shared domain are critical because they will influence the other production line.
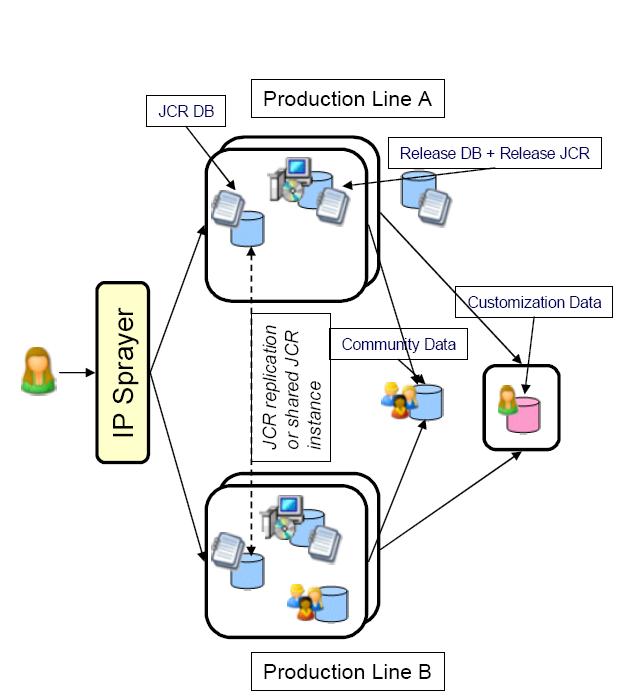
Key Advantages to a configuration split: Why Configuration Split?
There are some key advantages to using a db configuration split that one must consider when building a High Availability cluster
- Enables global deployment -Supports customers who want global deployment at different sites
- Improves staging
- Flexible maintenance and backup
- Reduces the overhead in High Availability systems
- Release DB + Community DB are shared across the cluster nodes
- Customization DB is either external or shared with the other DBs
- Sites can now replicate the customization DB (2-way sync)
- Users get routed to either Production line
- Both lines run on a copy of the same release data and the same shared user data
- Users can modify customization data but not release data or community data.
- JCR replication is optional, the shared JCR DB an also be shared across the lines.
- Working with workplace applications will only modify community data (+ optional external data sources referenced by the applications)
- Non-disruptive maintenance and backups fully supported!
Profiles
WebSphere Application Server V6 introduced the concept of Profiles which is separation of core product files and user data (or run time execution environment). Some key points to remember about profiles:
- Default install path is <was_root>/profiles but can be outside <was_root>
- System admin commands are profile specific.
- Execute from <profile_directory>/bin or <was_root>/bin using -profileName parameter
- Each profile has a unique cell name, unique node name combination. One to one mapping between the node and a profile.
- Ports generated for the node agent are unique for all the profiles in the installation
Master Configuration Repository
Master configuration repository is maintained by the deployment manager. The deployment manager maintains a master repository of the individual node configurations. Master Configuration repository is the bases of what is replicated out to all of the existing members of a cell. Each node has its own representations of the configuration repository
Master Configuration Repository
- Master configuration repository. Master configuration for all nodes. Basis of what is replicated out to all of the individual members of a cell.
<dmgr_profile_root>/config- Configuration repository
<profile_root>/config
- Enterprise Apps (config part)
<config_root>/cells/<cell_name>/applications- Nodes
<config_root>/cells/<cell_name>/nodes- Servers...
<config_root>/cells/<cell_name>/nodes/<node_name>/serversIf you make changes on a local node to configuration the changes will be temporary as the DM is maintaining the master copy. DM will synchronize with the local node and overwrite the changes you made on the individual node.
Important: Permanent configuration changes should be made through the deployment manager console
Web Server Considerations
HTTP Session Failover
Enable HTTP session failover in the cluster to enable multiple cluster members to serve data in the event that one of them fails.
In a clustered environment, all requests for a particular session are directed to the same WebSphere Portal server instance in the cluster. In other words, after a user establishes a session with a portal (for example, by logging in to the portal), the user is served by the same WebSphere Portal server instance for the duration of the session. To verify which server is handling user requests for a session, we can view the global settings portlet in WebSphere Portal, which displays the node name of the WebSphere Portal server handling requests.
If one of the WebSphere Portal servers in the cluster fails, the request is rerouted to another WebSphere Portal server in the cluster. If distributed sessions support is enabled (either by persistent sessions or memory-to-memory session replication), the new server can access session data from the database or another WebSphere Portal server instance.
Distributed session support is not enabled by default and must be configured separately in WebSphere Application Server.
Failover and lost data
Data that is stored within the JVM memory and not managed by the application server or the WebSphere Portal server for replication might be lost in the case of failover. Even with the distributed session support, during a failure, users will not be able to recover any uncommitted information that is not stored in sessions or other replicated data areas (such as a distributed Map or render parameters). In such cases, users might have to restart a transaction after a failover occurs. For example, if you are in the process of working with a portlet and have navigated between several different screens when a failover occurs, you might be placed back at the initial screen, where you would need to repeat the previous steps. Similarly, if you are attempting to deploy a portlet when a failover occurs, the deployment might not be successful, in which case redeploy the portlet. Note, however, that with distributed session support enabled, the validity of user login sessions is maintained despite node failures.
In cases where a portlet does not support failover, a "Portlet Unavailable" message is displayed for the portlet after a failover occurs. If a portlet supports partial or incomplete failover, some data displayed by the portlet before the failover could disappear after the failover occurs, or the portlet might not work as expected. In such extreme cases, the user should log out and log back in to resume normal operation.
After a failover occurs, the request is redirected to another cluster member by the Web server plug-in. Most browsers will issue a GET request as a response to a redirect after submitting a POST request. This ensures that the browser does not send the same data multiple times without the user's knowledge. However, this means that after failover, users might have to refresh the page in the browser or go back and resubmit the form to recover the POST data.
Note: Document Manager portlets supplied with WebSphere Portal and any other portlets that use POST data are affected by this behavior.
WAS V6 Web Server Changes
With WAS V6 there are some key architectural changes in how web servers are represented. Web Servers have become an architectural component.
- Deployment Manager explicitly manages web server and Applications are explicitly mapped to the web server plus cluster.
- So if you are looking at the enterprise applications target mappings for Portal you will see one entry for the cluster and one entry for the web server so the applications now have to be mapped to the web server.
- Different apps can be mapped to different web servers if desired
- Plugin-cfg.xml can be automatically propagated to Web Server (IHS or web server on a managed node)
Recommended process to configure remote external Web server (Overview)
- Use Plug-in Install wizard to install Plug-in on remote Web server
- Also possible to create Web server instance through DMgr Admin Console or via wsadmin commands in WAS V6
- Copy configure<webServerName>.sh or .bat script to Deployment Manager
- Run script on Deployment Manager
- Use DMgr Admin Console to re-synch with all nodes to push required config updates to each Portal node
- Most Customizations to plugin-cfg.xml can be done through DMgr Admin Console
- Separate process defined for local external Web server (co-residing with DMgr or with a Portal node in the cell)
Hardware requirements for High Availability
Prior to building a portal cluster with full redundancy one must consider how much hardware or servers are needed and plan accordingly. In an ideal world each component (ldap, db2, http, wsas/was/wps, and dm) would be fully redundant and would each have a dedicated server. You realize that this is not always possible and an organization must prioritize.
NODE1 Contains...
- DB client
- WebSphere Process Server
- WebSphere Portal Server
- WebSphere Application Server
NODE2 Contains...
- DB client
- WebSphere Process Server
- WebSphere Portal Server
- WebSphere Application Server
DMGR1 Deployment Manager DMGR2 Deployment Manager (Optional) LDAP1 LDAP Server LDAP2 LDAP Server (Optional) DB21 Database Server DB2 Database Server (Optional) HTTP1 Web Server for Node 1 HTTP 2 Web Server for Node 2 Edge Server 1
Edge Server 2 (Optional)
As Seen above for a fully fault tolerant system with redundancy at each component up to 12 servers are needed. Saying this a cluster can run with as little as 3 servers. One can consider this lightweight configuration for a test, or development environment but not for production. In 2.3.8, “Example architectures in operation”, you go into the detailed architectures in operation as well as answer the questions of how many environments an organization needs.
Example architectures in operation
This section contains examples of architectures that IBM Clients are using today.
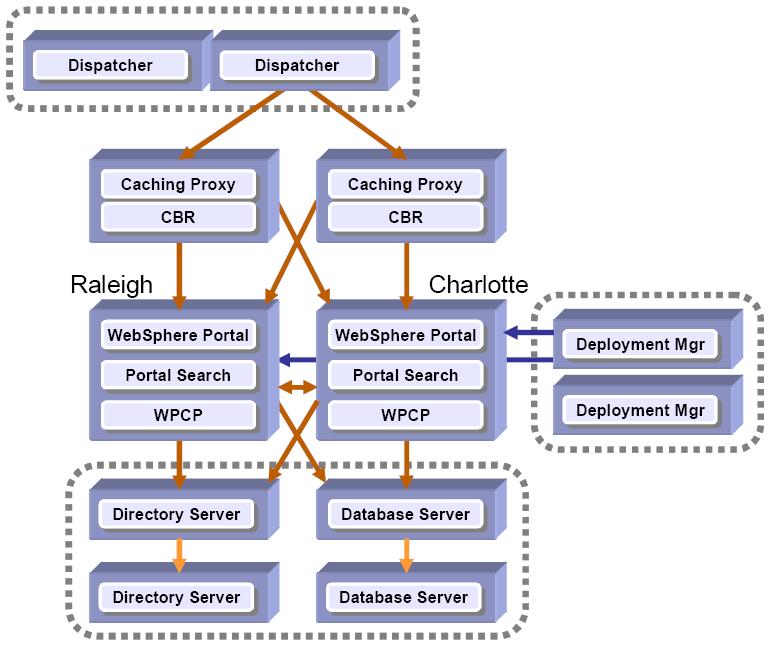
Fault tolerant Portal cluster (with full redundancy)
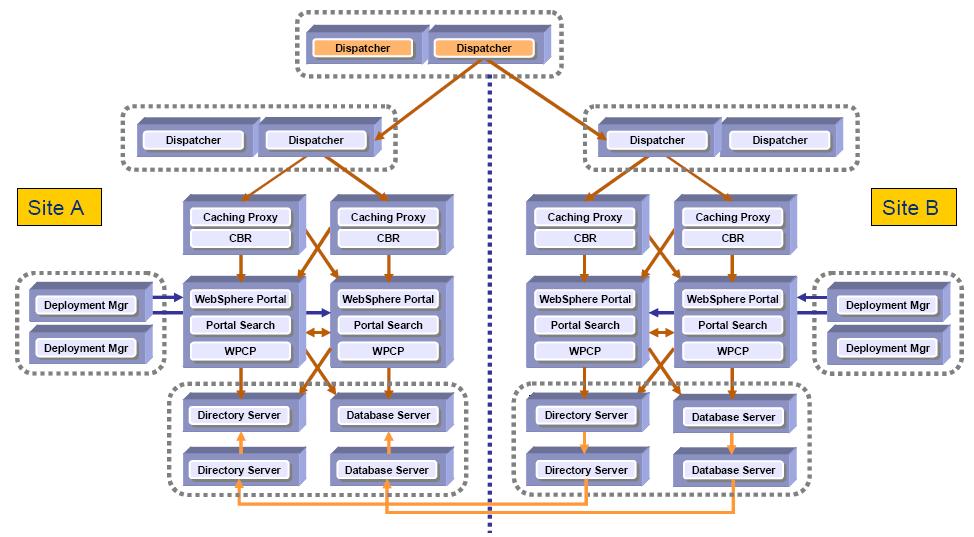
The fault tolerant Portal cluster (with full redundancy) is a typical fault tolerant Portal cluster where caching is typically used. This solution avoids a signal-point-of-failure with redundancy across the board. Each Portal is running in a different physical location (in this example, one in Raleigh and one in Charlotte). Only one directory server and database server is active at one time. Support 24x7 can also be used.
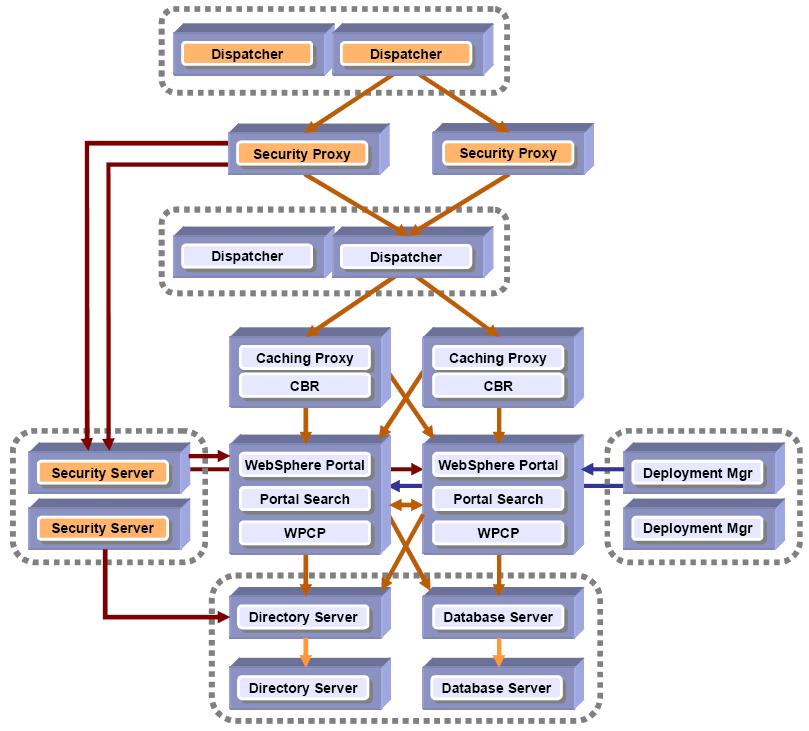
Fault tolerant Portal cluster (with full redundancy and security)
The Fault Tolerant Portal cluster (with full redundancy and security) adds a security server (either Tivoli Access Manager or SiteMinder) providing 24x7 security operation. In addition, a Signal Sign On environment can exist without having to logon more than once. This Portal architecture avoids a single-point-of-failure and makes use of caching and enhanced security. The location of security proxies allows for protection of cached content.
The Availability Gold Standard in Portal 5.1
In Portal 5.1 the Availability Gold Standard allows WebSphere Portal to run on two sets of clustered machines. This Portal architecture allows you to operate in a 24x7 environment while maintaining easy configuration and maintenance procedures. This is both an active and a passive configuration. The other side is used as a warm backup. 7387ch_planning_for_deployment.fm Draft Document for Review February 8, 2007 3:04 pm
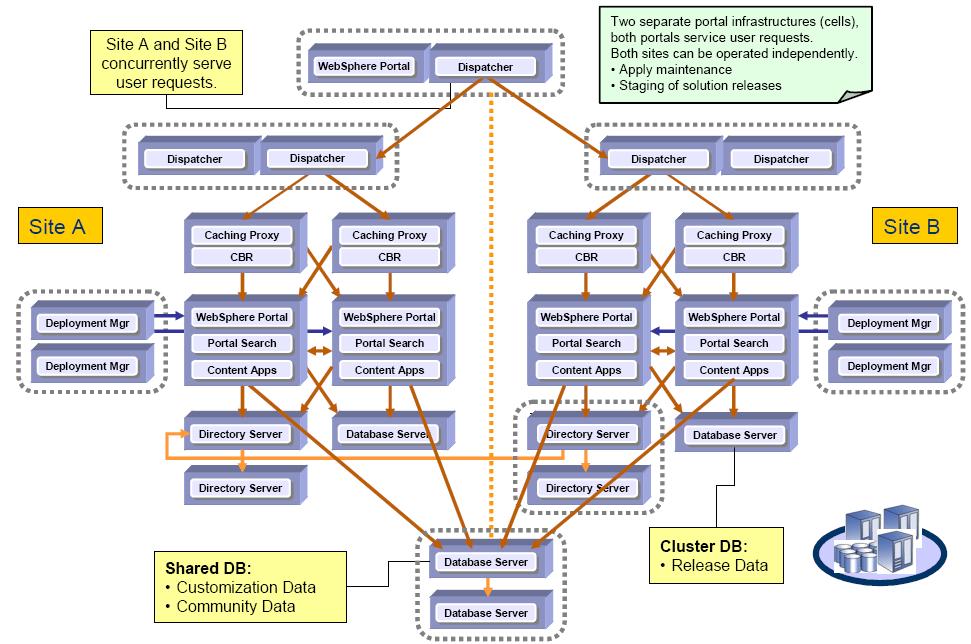
The New Availability Gold Standard in Portal 6.0
In Portal 6.0 the Availability Gold Standard allows WebSphere Portal to run on two sets of clustered machines independently. This Portal architecture allows you to operate in a 24x7 environment while maintaining easy configuration and maintenance procedures. This is an active configuration where two separate portal infrastructures (cells) service user requests.
Continuous Operation:
The following statement speaks to the high availability of components operating in a 24x7 environment.
Glossary of Telecommunications Standard [1037C - 1997]
Operation in which certain components, such as...
- nodes
- facilities
- circuits
- equipment
...are in an operational state at all times. (188)
Continuous operation usually requires that there be fully redundant configuration, or at least a sufficient X out of Y degree of redundancy for compatible equipment, where X is the number of spare components and Y is the number of operational components.
In data transmission, operation in which the master station need not stop for a reply from a slave station after transmitting each message or transmission block.
Recommendations and Best Practices: How many environments do I need?
The following section is intended to provide an overview of typical environments which are used for developing, testing, and staging the WebSphere Portal Infrastructure. Ultimately, the decision about exactly how many environments do we need is based upon architecture of the production environment. There is not necessarily a single answer which applies to each but instead, there are several factors which determine the extent to which we need seperate pre-production environments.
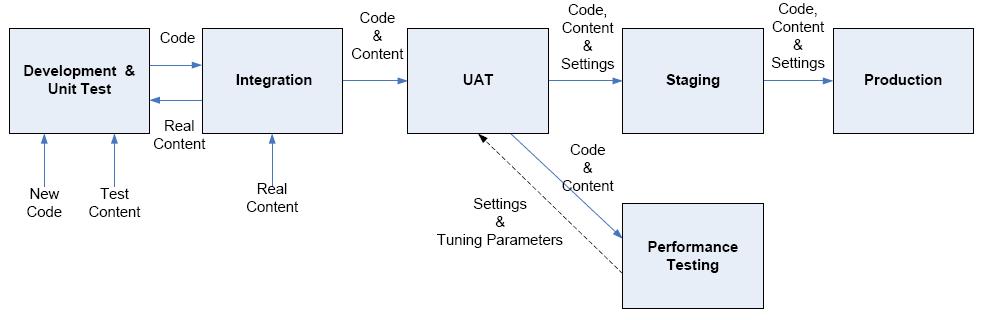
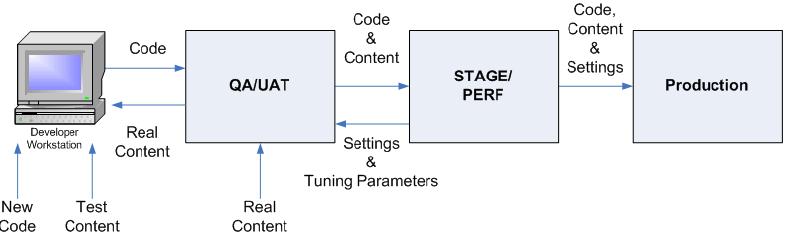
Figure 2-9 on page 40 illustrates an overview of commonly used environments to support development, integration, testing, staging and ultimately production of the WebSphere Portal environment. As you describe in the upcoming sections, you may not need this many distinct environments.
Figure 2-9 Commonly used Environments
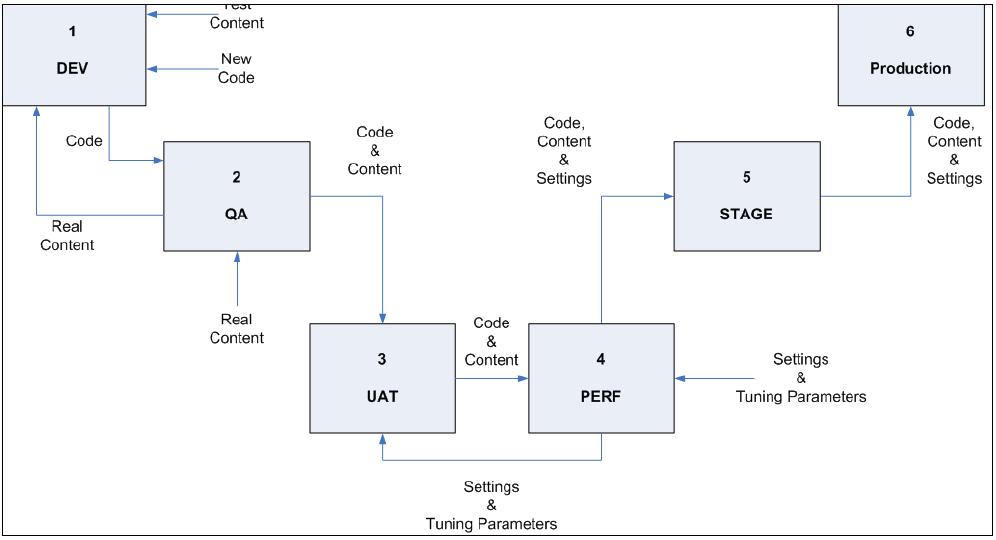
The two most important factors in determining the number of environments we need are the development scope and cycle, and the budget. Figure 2-10 illustrates the ideal set of environments, assuming that you are going to have at least one dedicated development team and at least one dedicated testing team, and an unlimited budget.
Remember - one of these environments must be dedicated as the starting point of full control over the configuration of the system. The earlier in the release cycle this enviroment is (for example, Dev or QA) the easier configuration management will be for the administrators to move releases through the environments, but the more restrictions this will place on the developers.
Purposes of each environment
Every organization has its own naming for these environments; following are the names and purposes you will use throughout this book.
Development/Unit Test (DEV)
Your developers will have their own Test Environments on their desktops. DEV is the first integrated environment where they can first run their code in a real portal environment. This environment will become a clutter of tests, placeholders, strange abortions and forgotten experiments – probably nothing that you would want to even possibly migrate to production. But the developers will need and appreciate the freedom of having this “sandbox” environment in which to play. You should consider having a scheduled cleanup of this environment, perhaps concurrent with a production rollout, to delete everything and reset to the current production build.
Testing (QA)
This would be the first environment that will actually resemble production. Once developers have unit tested their code, it will be deployed to the QA environment for evaluation by the testing team for functionality and determination that it meets the requirements. This environment will have the back-end connections necessary to test code, but not necessarily all of the ones that will be in the production environments. Your development team will often use this environment.
Integration Testing (UAT)
This might be the first environment that has all connections to back-end environments with realistic or real data. This is where end-to-end testing occurs between portal and all other systems you integrate with. These systems could include...
- SSO (SiteMinder/TAM)
- SAP
- PeopleSoft
- SameTime
- content management systems
- custom applications
Your testing team will be interacting with this environment the most.
Performance Testing (PERF)
Environment where you run the performance tests.
The hardware in this environment should be identical to production in every way for the results to be meaningful. This is probably the most important environment you will build. This is where you play with JVM tuning parameters, caching options, database tuning, capacity planning. We can also use this environment for disaster recovery testing, as its usage and availability schedule will be known and controlled.
Staging (STAGE)
Last environment before Production.
Should be an exact replica of production in its configurations and content. It may be connected to an exact replica of the production LDAP server, or frequently to the same LDAP server. This is where you do final testing and evaluation of both the code, content and the deployment process before you do the production deployment.
Production (PROD)
Production environment that the end users will access.
All the other environments exist to support this one and ensure that anything that goes into the PROD environment has been completely and thoroughly tested and is ready for the customers.
Recommendations
In an ideal world, you would have all of these environments, and they would all be identical in configuration and identical in hardware. But you understand that it may not always be feasible, so where do you cut back or collapse environments?
As many environments as we can manage should at least be federated nodes managed by Deployment Manager, if not actually clustered. This will minimize differences in administrative tasks, reducing the burden on the administrators. All environments should be on similar hardware, operating system and release levels - for example, all on Windows 2003 servers, all on RS/6000 servers running AIX 5.3, or all on SunFire servers running Solaris 10, though not necessarily with the same memory or CPU profiles. This will minimize runtime and administrative differences, reducing the likelihood of problems surfacing only late in the release cycle.
Your development environment doesn’t necessarily need to be clustered. It should be configured with security enabled and connected to an LDAP with a structure that looks like production. It can be as simple as a laptop sitting on an empty desk somewhere, or it could be an exact replica of the production hardware. If you have a large number of custom portlet development projects, or multiple development teams (for example, a development team for each department contributing content to the portal), you could have multiple development environments, one for each team, which all contribute content and code into the QA environment. Alternately, you could dispense with a dedicated DEV environment entirely, and have the developers use test environments on their PCs, and deploy directly from version control into the integration or pre-prod environment.
QA and UAT testing could be combined into a single test environment. With this configuration, designate the QA/UAT “Test” environment as the first environment under full Configuration Management administrative control. Your developers will not be able to “try things out” at will except on their own workstations, which may not have all of the connectivity of a “real” environment.
A dedicated Performance testing environment is highly desirable, but if you are severely hardware constrained, we can do the performance testing on the production servers before you go live. Be aware, however, that once you do the initial launch, it becomes very difficult to do additional performance tuning. If you are lucky enough to have a “slow” time like 2am to do performance testing, we can make changes then, but you would most likely be in violation of a 24x7 SLA at these times. If the hardware profiles of the Staging environment is the same as production, you could use that environment to perform performance testing in that environment before moving the next release into Production, as illustrated in Figure 2-11, but if the hardware in those environments is scaled down, then the only option for Performance testing is to do it in Production after going live, during a time of low utilization by the customers. Alternatively, if you have a four-node cluster in Production, the Performance environment may consist of one or two nodes, as long as the hardware is the same, extrapolating the load by a factor of 1:4 or 1:2.
If you are really tight on hardware, you may even combine staging on the same server as the testing environment, as illustrated in Figure 2-12. This might be advisable if you have a very small or no dedicated testing team, but it will limit the concurrent testing cycles and force longer turnaround times for production rollouts. It also effectively limits the amount of concurrent development that can be supported, as every developer is going to be on their own schedule for writing and testing code, and server restarts must be coordinated with the entire development and testing teams. Again, unless the hardware profile of that environment is identical to that of the Production server, you will have to do performance testing in the production environment.
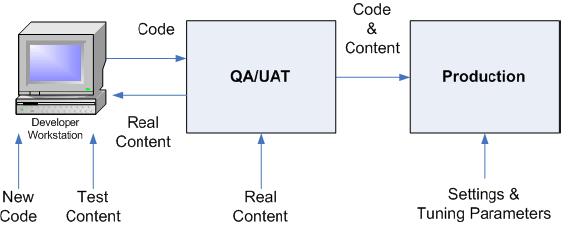
Therefore, at a minimum, we need two environments - Integration and Production. Much better would be to have three - Test, Stage/Performance, and Production. The ideal, however, would be to have all 6 environments. The more environments you have available, the less contention for environment availability the developers, testers, and administrators will have to deal with, and the shorter release cycles you will be able to support.
Introduction to the deployment scenarios used in this Redbook
The following section illustrates the various clustered environments built during the writing of this book. The section is written in order of how the environment was built so one can see the progression in the deployment.
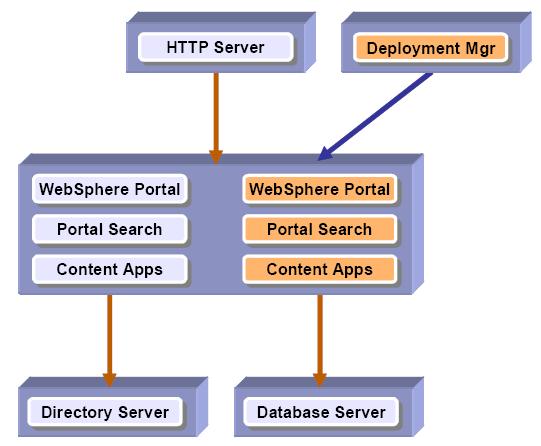
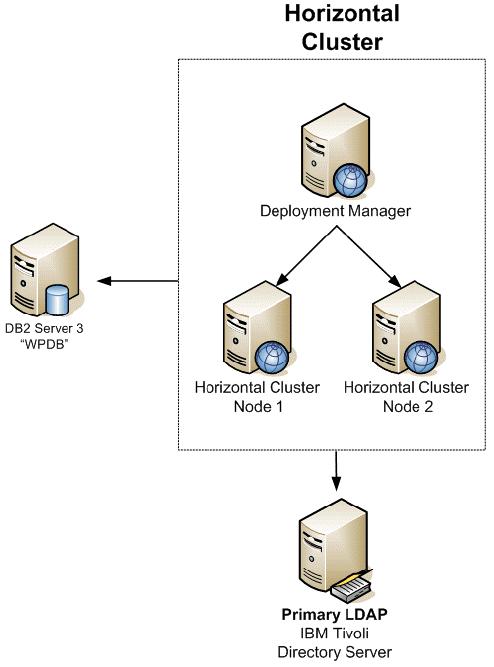
Horizontal cluster with single database and single LDAP
The following diagram illustrates a horizontal cluster with a single database and single LDAP.
For WebSphere Process Server considerations refer to 2.3.1, “WebSphere Process Server Considerations”.
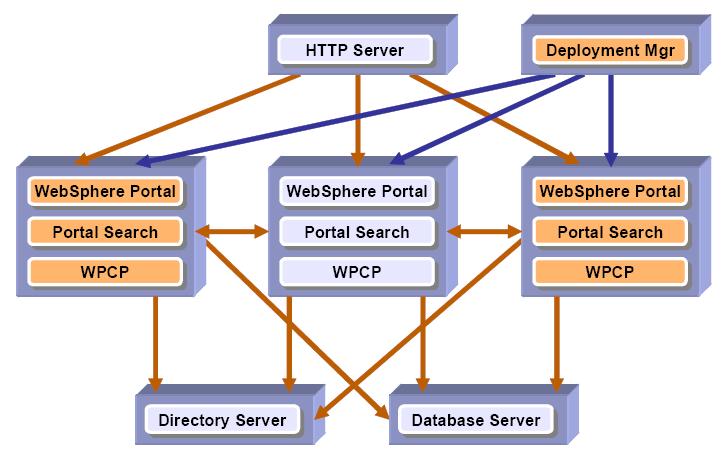
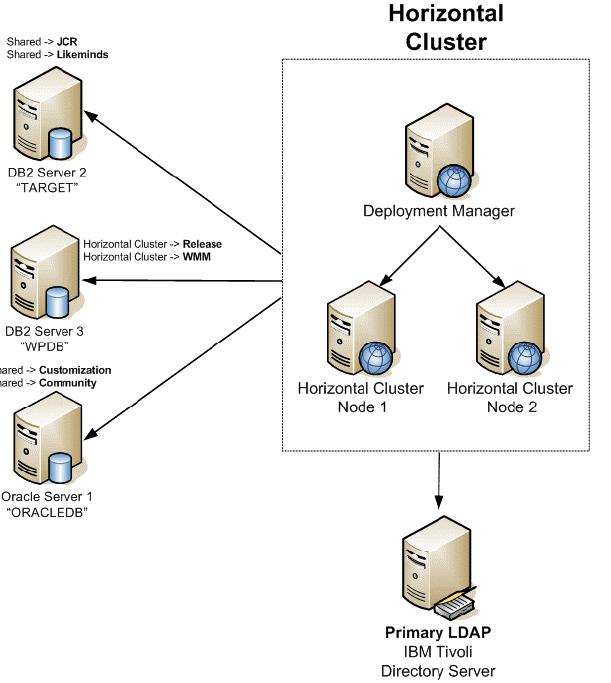
Horizontal cluster with database domain
The following diagram illustrates a horizontal cluster with database domains. Note that there are 3 physical database servers each with 2 schemes serving the horizontal cluster. One DB server contains the Release and WMM schemes, one DB server contains JCR and Likeminds schemes, and one contains Customization and Community schemes. Benefits of database domain configuration is described in detail in 2.3.3, “Database Domain (database split)Overview”
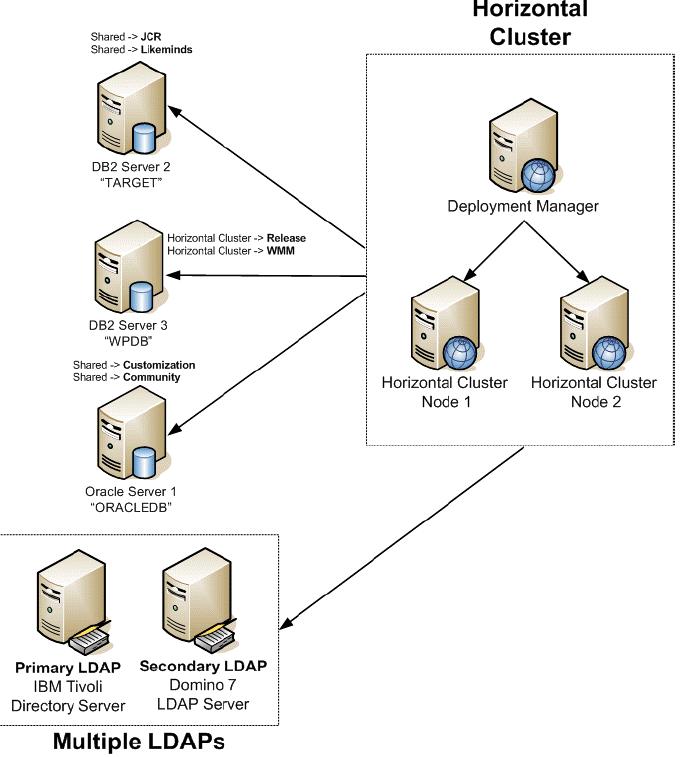
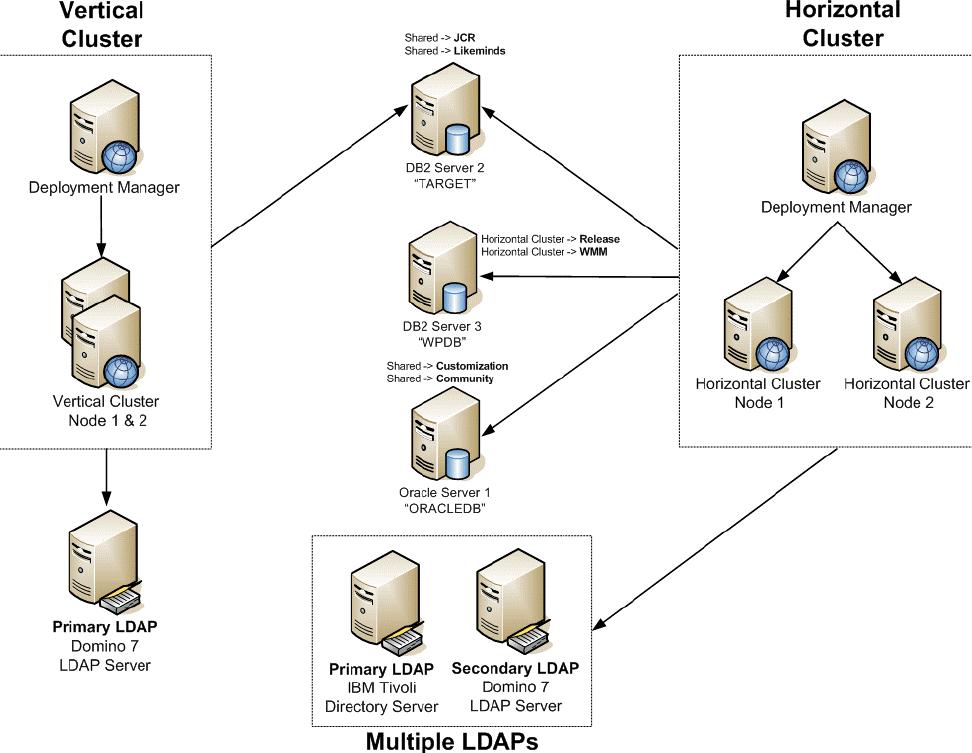
Horizontal cluster with database domain and multiple LDAP
The following diagram illustrates a horizontal cluster with database domain and multiple LDAP. You utilize IBM Tivoli Directory Server as the primary LDAP and Lotus Domino 7.0.2 as the secondary LDAP. Users registered in both LDAP servers have access to the Portal environment in this type of configuration. An overview of multiple LDAP is described in 2.3.2, “Multiple LDAP Overview”.
Vertical cluster with single database and single LDAP
The following diagram illustrates a vertical cluster with a single database and single LDAP. Note that the horizontal cluster is still part of the diagram as you will be reusing the LDAP and Database servers while building the vertical cluster to utilize multiple LDAP and database domains features
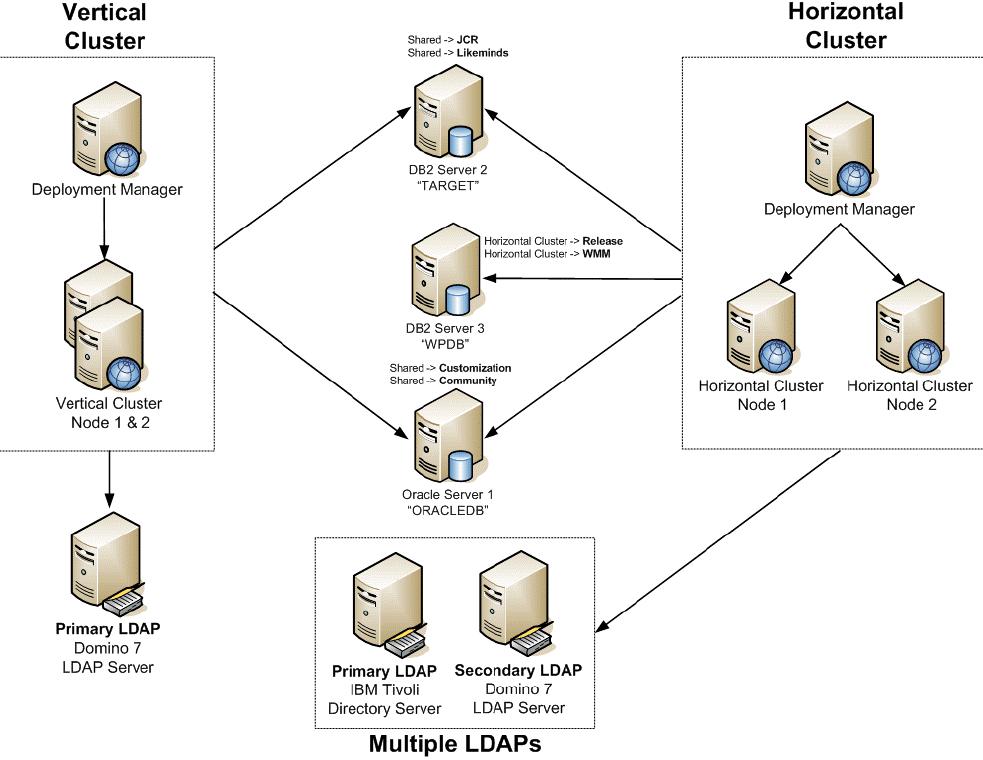
Vertical cluster with database domain
The following diagram illustrates a vertical cluster with a database domain in which the database server is shared between the horizontal cluster. Note that the schemes from the vertical clusters are split between DB Server 1 and DB Server 2 as part of the database domain configuration. Benefits of database domain configuration is described in detail in 2.3.3, “Database Domain (database split)Overview”.
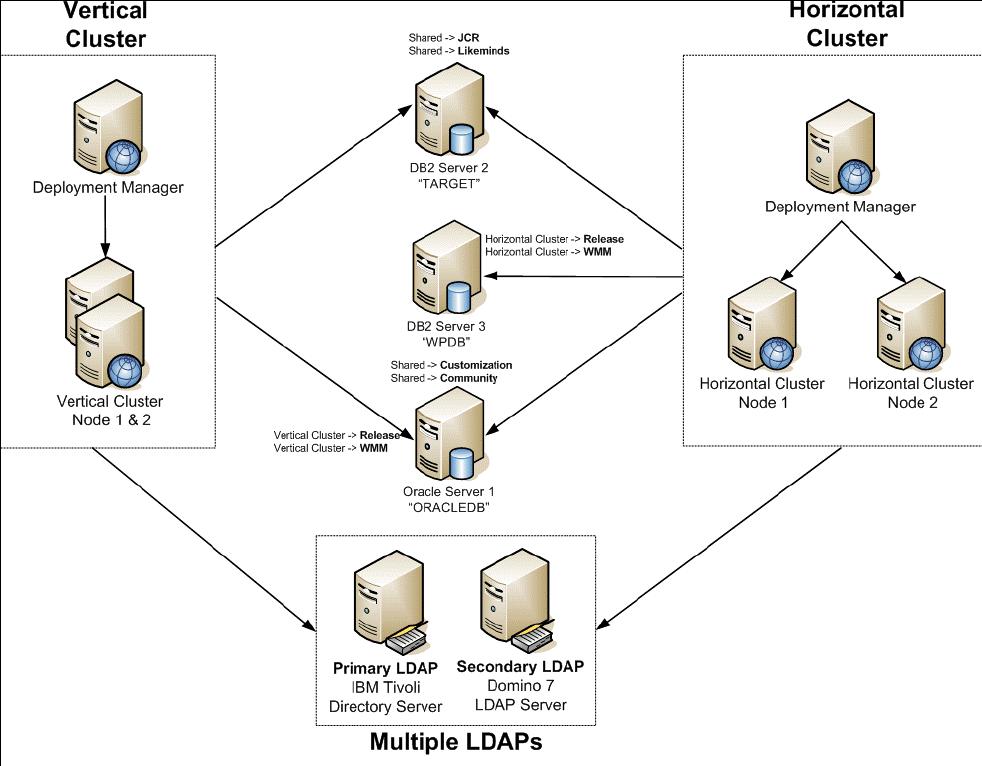
Vertical cluster with database domain and multiple LDAP
This environment includes vertical and horizontal clusters with database domains and multiple LDAPs. Both Oracle and DB2 are used for the database servers and multiple LDAPs are represented with Domino 7.0.2 and IBM Directory Server.
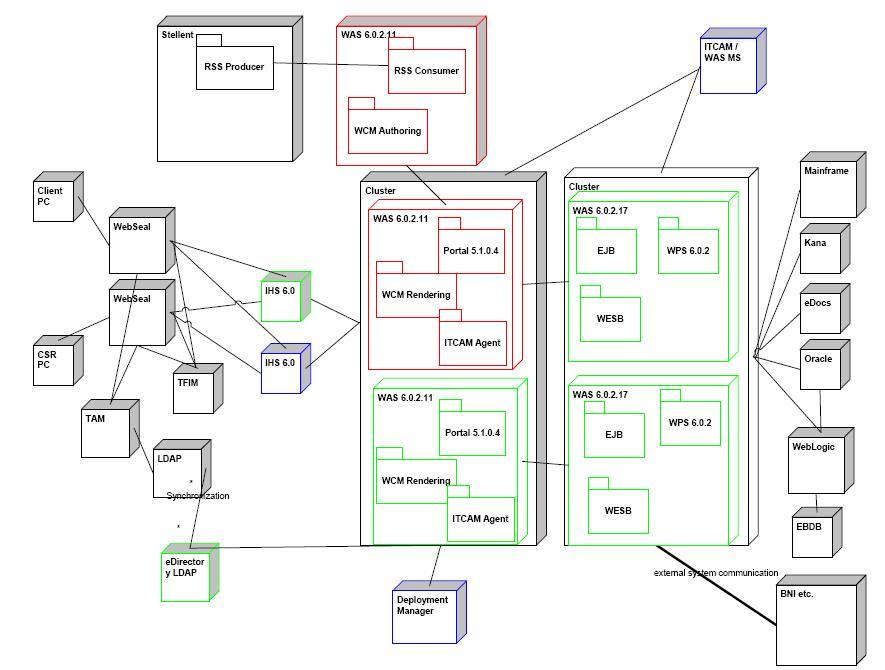
Clustered architecture with WebSEAL