HA clusters on UNIX and Linux
We can use IBM MQ with a high availability (HA) cluster on UNIX and Linux platforms: for example, PowerHA for AIX (formerly HACMP ), Veritas Cluster Server, HP Serviceguard, or a Red Hat Enterprise Linux cluster with Red Hat Cluster Suite.
Before IBM WebSphere MQ Version 7.0.1, SupportPac MC91 was provided to assist in configuring HA clusters. IBM WebSphere MQ Version 7.0.1 provided a greater degree of control than previous versions over where queue managers store their data. This makes it easier to configure queue managers in an HA cluster. Most of the scripts provided with SupportPac MC91 are no longer required, and the SupportPac is withdrawn.
This section introduces HA cluster configurations, the relationship of HA clusters to queue manager clusters, IBM MQ clients, and IBM MQ operating in an HA cluster, and guides you through the steps and provides example scripts that we can adapt to configure queue managers with an HA cluster.
Refer to the HA cluster documentation particular to the environment for assistance with the configuration steps described in this section.
HA cluster configurations
In this section the term node is used to refer to the entity that is running an operating system and the HA software; "computer", "system" or "machine" or "partition" or "blade" might be considered synonyms in this usage. We can use IBM MQ to help set up either standby or takeover configurations, including mutual takeover where all cluster nodes are running IBM MQ workload.
A standby configuration is the most basic HA cluster configuration in which one node performs work while the other node acts only as standby. The standby node does not perform work and is referred to as idle; this configuration is sometimes called cold standby. Such a configuration requires a high degree of hardware redundancy. To economize on hardware, it is possible to extend this configuration to have multiple worker nodes with a single standby node. The point of this is that the standby node can take over the work of any other worker node. This configuration is still referred to as a standby configuration and sometimes as an "N+1" configuration.
A takeover configuration is a more advanced configuration in which all nodes perform some work and critical work can be taken over in the event of a node failure.
A one-sided takeover configuration is one in which a standby node performs some additional, noncritical and unmovable work. This configuration is similar to a standby configuration but with (noncritical) work being performed by the standby node.
A mutual takeover configuration is one in which all nodes are performing highly available (movable) work. This type of HA cluster configuration is also sometimes referred to as "Active/Active" to indicate that all nodes are actively processing critical workload.
With the extended standby configuration or either of the takeover configurations it is important to consider the peak load that might be placed on a node that can take over the work of other nodes. Such a node must possess sufficient capacity to maintain an acceptable level of performance.
Relationship of HA clusters to queue manager clusters
Queue manager clusters reduce administration and provide load balancing of messages across instances of queue manager cluster queues. They also offer higher availability than a single queue manager because, following a failure of a queue manager, messaging applications can still access surviving instances of a queue manager cluster queue. However, queue manager clusters alone do not provide automatic detection of queue manager failure and automatic triggering of queue manager restart or failover. HA clusters provide these features. The two types of cluster can be used together to good effect.
IBM MQ clients
IBM MQ clients that are communicating with a queue manager that might be subject to a restart or takeover must be written to tolerate a broken connection and must repeatedly attempt to reconnect. IBM WebSphere MQ Version 7 introduced features in the processing of the Client Channel Definition Table (CCDT) that assist with connection availability and workload balancing; however these are not directly relevant when working with a failover system.
Transactional functionality allows an IBM MQ MQI client to participate in two-phase transactions, as long as the client is connected to the same queue manager. Transactional functionality cannot use techniques, such as an IP load balancer, to select from a list of queue managers. When we use an HA product, a queue manager maintains its identity (name and address) whichever node it is running on, so transactional functionality can be used with queue managers that are under HA control.
IBM MQ operating in an HA cluster
All HA clusters have the concept of a unit of failover. This is a set of definitions that contains all the resources that make up the highly available service. The unit of failover includes the service itself and all other resources upon which it depends.
HA solutions use different terms for a unit of failover:- On PowerHA for AIX the unit of failover is called a resource group.
- On Veritas Cluster Server it is known as a service group.
- On Serviceguard it is called a package.
This topic uses the term resource group to mean a unit of failover.
The smallest unit of failover for IBM MQ is a queue manager. Typically, the resource group containing the queue manager also contains shared disks in a volume group or disk group that is reserved exclusively for use by the resource group, and the IP address that is used to connect to the queue manager. It is also possible to include other IBM MQ resources, such as a listener or a trigger monitor in the same resource group, either as separate resources, or under the control of the queue manager itself.
A queue manager that is to be used in an HA cluster must have its data and logs on disks that are shared between the nodes in the cluster. The HA cluster ensures that only one node in the cluster at a time can write to the disks. The HA cluster can use a monitor script to monitor the state of the queue manager.
It is possible to use a single shared disk for both the data and logs that are related to the queue manager. However, it is normal practice to use separate shared file systems so that they can be independently sized and tuned.
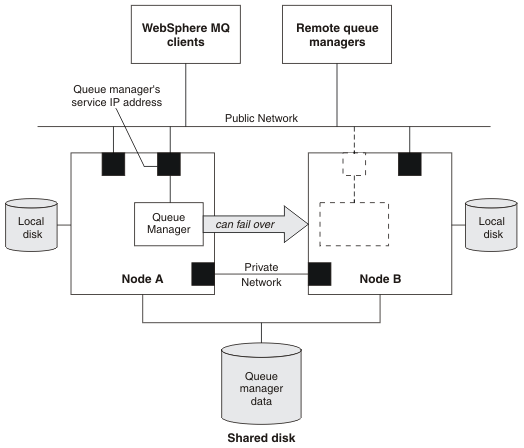
If the HA cluster contains more than one queue manager, your HA cluster configuration might result in two or more queue managers running on the same node after a failover. Each queue manager in the HA cluster must be assigned its own port number, which it uses on whichever cluster node it happens to be active at any particular time.
Generally, the HA cluster runs as the root user. IBM MQ runs as the mqm user. Administration of IBM MQ is granted to members of the mqm group. Ensure that the mqm user and group both exist on all HA cluster nodes. The user ID and group ID must be consistent across the cluster. Administration of IBM MQ by the root user is not allowed; scripts that start, stop, or monitor scripts must switch to the mqm user.
Note: IBM MQ must be installed correctly on all nodes; you cannot share the product executable files.- Configure shared disks on UNIX and Linux
An IBM MQ queue manager in an HA cluster requires data files and log files to be in common named remote file systems on a shared disk. - Create an HA cluster queue manager on UNIX and Linux
The first step towards using a queue manager in a high availability cluster is to create the queue manager on one of the nodes. - Adding queue manager configuration to other HA cluster nodes on UNIX and Linux
We must add the queue manager configuration information to the other nodes in the HA cluster. - Example shell scripts for starting an HA cluster queue manager on UNIX and Linux
The queue manager is represented in the HA cluster as a resource. The HA cluster must be able to start and stop the queue manager. In most cases we can use a shell script to start the queue manager. We must make these scripts available at the same location on all nodes in the cluster, either using a network filesystem or by copying them to each of the local disks. - Example shell script for stopping an HA cluster queue manager on UNIX and Linux
In most cases, we can use a shell script to stop a queue manager. Examples of suitable shell scripts are given here. We can tailor these to your needs and use them to stop the queue manager under control of our HA cluster. - Monitor an HA cluster queue manager on UNIX and Linux
It is usual to provide a way for the high availability (HA) cluster to monitor the state of the queue manager periodically. In most cases, we can use a shell script for this. Examples of suitable shell scripts are given here. We can tailor these scripts to your needs and use them to make additional monitoring checks specific to the environment. - Put the queue manager under HA cluster control on UNIX and Linux
We must configure the queue manager, under control of the HA cluster, with the queue manager's IP address and shared disks. - Delete an HA cluster queue manager on UNIX and Linux
We might want to remove a queue manager from a node that is no longer required to run the queue manager.
Parent topic: High availability configurations