Mirrored journal configuration for ASP on IBM i
Configure a robust multi-instance queue manager using synchronous replication between mirrored journals.
A mirrored queue manager configuration uses journals that are created in basic or independent auxiliary storage pools (ASP).
On IBM i, queue manager data is written to journals and to a file system. Journals contain the master copy of queue manager data. Journals are shared between systems using either synchronous or asynchronous journal replication. A mix of local and remote journals are required to restart a queue manager instance. Queue manager restart reads journal records from the mix of local and remote journals on the server, and the queue manager data on the shared network file system. The data in the file system speeds up restarting the queue manager. Checkpoints are stored in the file system, marking points of synchronization between the file system and the journals. Journal records stored before the checkpoint are not required for typical queue manager restarts. However, the data in the file system might not be up to date, and journal records after the checkpoint are used to complete the queue manager restart. The data in the journals attached to the instance are kept up to date so that the restart can complete successfully.
But even the journal records might not be up to date, if the remote journal on the standby server was being asynchronously replicated, and the failure occurred before it was synchronized. In the event that you decide to restart a queue manager using a remote journal that is not synchronized, the standby queue manager instance might either reprocess messages that were deleted before the active instance failed, or not process messages that were received before the active instance failed.
Another, rare possibility, is that the file system contains the most recent checkpoint record, and an unsynchronized remote journal on the standby does not. In this case the queue manager does not restart automatically. We have a choice of waiting until the remote journal is synchronized, or cold starting the standby queue manager from the file system. Even though, in this case, the file system contains a more recent checkpoint of the queue manager data than the remote journal, it might not contain all the messages that were processed before the active instance failed. Some messages might be reprocessed, and some not processed, after a cold restart that is out of synchronization with the journals.
With a multi-instance queue manager, the file system is also used to control which instance of a queue manager is active, and which is the standby. The active instance acquires a lock to the queue manager data. The standby waits to acquire the lock, and when it does, it becomes the active instance. The lock is released by the active instance, if it ends normally. The lock is released by the file system if the file system detects the active instance has failed, or cannot access the file system. The file system must meet the requirements for detecting failure; see Requirements for shared file systems.
The architecture of multi-instance queue managers on IBM i provides automatic restart following server or queue manager failure. It also supports restoration of queue manager data following failure of the file system where the queue manager data is stored.
In Figure 1, if ALPHA fails, we can manually restart QM1 on BETA, using the mirrored journal. By adding the multi-instance queue manager capability to QM1, the standby instance of QM1 resumes automatically on BETA if the active instance on ALPHA fails. QM1 can also resume automatically if it is the server ALPHA that fails, not just the active instance of QM1. Once BETA becomes the host of the active queue manager instance, the standby instance can be started on ALPHA.
Figure 1 shows a configuration that mirrors journals between two instances of a queue manager using NetServer to store queue manager data. We might expand the pattern to include more journals, and hence more instances. Follow the journal naming rules explained in the topic, Queue manager journals on IBM i. Currently the number of running instances of a queue manager is limited to two, one is active and one is in standby.
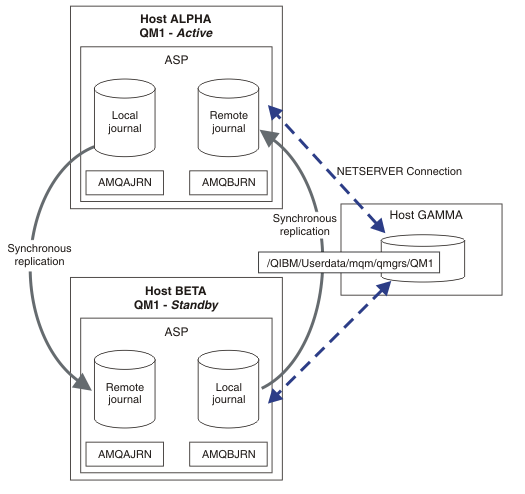
The local journal for QM1 on host ALPHA is called AMQAJRN (or more fully, QMQM1/AMQAJRN) and on BETA the journal is QMQM1/AMQBJRN. Each local journal replicates to remote journals on all other instances of the queue manager. If the queue manager is configured with two instances, a local journal is replicated to one remote journal.
*SYNC or *ASYNC remote journal replication
IBM i journals are mirrored using either synchronous ( *SYNC ) or asynchronous ( *ASYNC ) journaling; see Remote journal management.
The replication mode in Figure 1 is *SYNC, not *ASYNC. *ASYNC is faster, but if a failure occurs when the remote journal state is *ASYNCPEND, the local and remote journal are not consistent. The remote journal must catch up with the local journal. If you choose *SYNC, then the local system waits for the remote journal before returning from a call that requires a completed write. The local and remote journals generally remain consistent with one another. Only if the *SYNC operation takes longer than a designated time 1, and remote journaling is deactivated, do the journals get out of synchronization. An error is logged to the journal message queue and to QSYSOPR. The queue manager detects this message, writes an error to the queue manager error log, and deactivates remote replication of the queue manager journal. The active queue manager instance resumes without remote journaling to this journal. When the remote server is available again, we must manually reactivate synchronous remote journal replication. The journals are then resynchronized.
A problem with the *SYNC / *SYNC configuration illustrated in Figure 1 is how the standby queue manager instance on BETA takes control. As soon as the queue manager instance on BETA writes its first persistent message, it attempts to update the remote journal on ALPHA. If the cause of control passing from ALPHA to BETA was the failure of ALPHA, and ALPHA is still down, remote journaling to ALPHA fails. BETA waits for ALPHA to respond, and then deactivates remote journaling and resumes processing messages with only local journaling. BETA has to wait a while to detect that ALPHA is down, causing a period of inactivity.
The choice between setting remote journaling to *SYNC or *ASYNC is a trade-off. Table 1 summarizes the trade-offs between using *SYNC and *ASYNC journaling between a pair of queue managers:| Standby | *SYNC | *ASYNC | |
|---|---|---|---|
| Active | |||
| *SYNC |
|
|
|
| *ASYNC |
|
|
|
- *SYNC / *SYNC
- The active queue manager instance uses *SYNC journaling, and when the standby
queue manager instance starts, it immediately tries to use *SYNC journaling.
- The remote journal is transactionally consistent with the local journal of the active queue manager. If the queue manager is switched over to the standby instance, it can resume immediately. The standby instance normally resumes without any loss or duplication of messages. Messages are only lost or duplicated if remote journaling failed since the last checkpoint, and the previously active queue manager cannot be restarted.
- If the queue manager fails over to the standby instance, it might not be able to start immediately. The standby queue manager instance is activated with *SYNC journaling. The cause of the failover might prevent remote journaling to the server hosting the standby instance. The queue manager waits until the problem is detected before processing any persistent messages. An error is logged to the journal message queue and to QSYSOPR. The queue manager detects this message, writes an error to the queue manager error log, and deactivates remote replication of the queue manager journal. The active queue manager instance resumes without remote journaling to this journal. When the remote server is available again, we must manually reactivate synchronous remote journal replication. The journals are then resynchronized.
- The server to which the remote journal is replicated must always be available to maintain the remote journal. The remote journal is typically replicated to the same server that hosts the standby queue manager. The server might become unavailable. An error is logged to the journal message queue and to QSYSOPR. The queue manager detects this message, writes an error to the queue manager error log, and deactivates remote replication of the queue manager journal. The active queue manager instance resumes without remote journaling to this journal. When the remote server is available again, we must manually reactivate synchronous remote journal replication. The journals are then resynchronized.
- Remote journaling is slower than local journaling, and substantially slower if the servers are separated by a large distance. The queue manager must wait for remote journaling, which reduces queue manager performance.
The *SYNC / *SYNC configuration between a pair of servers has the disadvantage of a delay in resuming the standby instance after failover. The *SYNC / *ASYNC configuration does not have this problem.
*SYNC / *SYNC does guarantee no message loss after switchover or failover, as long as a remote journal is available. To reduce the risk of message loss after failover or switchover you have two choices. Either stop the active instance if the remote journal becomes inactive, or create remote journals on more than one server.
- *SYNC / *ASYNC
- The active queue manager instance uses *SYNC journaling, and when the standby
queue manager instance starts, it uses *ASYNC journaling. Shortly after the server
hosting the new standby instance becomes available, the system operator must switch the remote
journal on the active instance to *SYNC. When the operator switches remote
journaling from *ASYNC to *SYNC the active instance pauses if the
status of the remote journal is *ASYNCPEND. The active queue manager instance waits
until remaining journal entries are transferred to the remote journal. When the remote journal has
synchronized with the local journal, the new standby is transactionally consistent again with the
new active instance. From the perspective of the management of multi-instance queue managers, in an
*SYNC / *ASYNC configuration the IBM i system operator has an additional task. The operator
must switch remote journaling to *SYNC in addition to restarting the failed queue
manager instance.
- The remote journal is transactionally consistent with the local journal of the active queue manager. If the active queue manager instance is switched over, or fails over to the standby instance, the standby instance can then resume immediately. The standby instance normally resumes without any loss or duplication of messages. Messages are only lost or duplicated if remote journaling failed since the last checkpoint, and the previously active queue manager cannot be restarted.
- The system operator must switch remote journal from *ASYNC to *SYNC shortly after the system hosting the active instance becomes available again. The operator might wait for the remote journal to catch up before switching the remote journal to *SYNC. Alternatively the operator might switch the remote instance to *SYNC immediately, and force the active instance to wait until the standby instance journal has caught up. When remote journaling is set to *SYNC, the standby instance is generally transactionally consistent with the active instance. Messages are only lost or duplicated if remote journaling failed since the last checkpoint, and the previously active queue manager cannot be restarted.
- When the configuration has been restored from a switchover or failover, the server on which the remote journal is hosted must be available all the time.
Choose *SYNC / *ASYNC when we want the standby queue manager to resume quickly after a failover. We must restore the remote journal setting to *SYNC on the new active instance manually. The *SYNC / *ASYNC configuration matches the normal pattern of administering a pair of multi-instance queue managers. After one instance has failed, there is a time before the standby instance is restarted, during which the active instance cannot fail over.
- *ASYNC / *ASYNC
- Both the servers hosting the active and standby queue managers are configured to use
*ASYNC remote journaling.
- When switchover or failover take place, the queue manager continues with the journal on the new server. The journal might not be synchronized when the switchover or failover takes place. Consequently messages might be lost or duplicated.
- The active instance runs, even if the server hosting the standby queue manager is not be available. The local journal is replicated asynchronously with the standby server when it is available.
- The performance of the local queue manager is unaffected by remote journaling.
Choose *ASYNC / *ASYNC if performance is your principal requirement, and we are prepared to loose or duplicate some messages after failover or switchover.
- *ASYNC / *SYNC
- There is no reason to use this combination of options.
Queue manager activation from a remote journal
Journals are either replicated synchronously or asynchronously. The remote journal might not be active, or it might be catching up with the local journal. The remote journal might be catching up, even if it is synchronously replicated, because it might have been recently activated. The rules that the queue manager applies to the state of the remote journal it uses during start-up are as follows.- Standby startup fails if it must replay from the remote journal on the standby and the journal status is *FAILED or *INACTPEND.
-
When activation of the standby begins, the remote journal status on the standby must be either *ACTIVE or *INACTIVE. If the state is *INACTIVE, it is possible for activation to fail, if not all the journal data has been replicated.
The failure occurs if the queue manager data on the network file system has a more recent checkpoint record than present in the remote journal. The failure is unlikely to happen, as long as the remote journal is activated well within the default 30 minute maximum interval between checkpoints. If the standby queue manager does read a more recent checkpoint record from the file system, it does not start.
We have a choice: Wait until the local journal on the active server can be restored, or cold start the standby queue manager. If you choose to cold start, the queue manager starts with no journal data, and relies on the consistency and completeness of the queue manager data in the file system. Note: If you cold start a queue manager, we run the risk of losing or duplicating messages after the last checkpoint. The message transactions were written to the journal, but some of the transactions might not have been written to the queue manager data in the file system. When you cold start a queue manager, a fresh journal is started, and transactions not written to the queue manager data in the file system are lost. - The standby queue manager activation waits for the remote journal status on the standby to change from *ASYNCPEND or *SYNCPEND to *ASYNC or *SYNC. Messages are written to the job log of the execution controller periodically. Note: In this case activation is waiting on the remote journal local to the standby queue manager that is being activated. The queue manager also waits for a time before continuing without a remote journal. It waits when it tries to write synchronously to its remote journal (or journals) and the journal is not available.
- Activation stops if the journal status changes to *FAILED or *INACTPEND.
The names and states of the local and remote journals to be used in the activation are written to the queue manager error log.
- Create a multi-instance queue manager using journal mirroring and NetServer on IBM i
Create a multi-instance queue manager to run on two IBM i servers. The queue manager data is stored on a third IBM i server using NetServer. The queue manager journal is mirrored between the two servers using remote journaling. The ADDMQMJRN command is used to simplify creating the remote journals. - Convert a single instance queue manager to a multi-instance queue manager using NetServer and journal mirroring on IBM i
Convert a single instance queue manager to a multi-instance queue manager. Move the queue manager data to a network share connected by NetServer. Mirror the queue manager journal to a second IBM i server using remote journaling.
Parent topic: Multi-instance queue managers on IBM i 1 The designated time is 60 seconds on IBM i Version 5 and in the range 1 - 3600 seconds on IBM i 6.1 onwards.