Distributed queuing and clusters
Distributed queuing means sending messages from one queue manager to another. The receiving queue manager can be on the same machine or another; nearby or on the other side of the world. It can be running on the same platform as the local queue manager, or can be on any of the platforms supported by IBM MQ . We can manually define all the connections in a distributed queuing environment, or we can create a cluster and let IBM MQ define much of the connection detail for you.
Distributed queuing

- An application uses the MQCONN call to connect to a queue manager. The application then uses the MQOPEN call to open a queue so that it can put messages on the queue.
- Each queue manager has a definition for each of its queues. It can have definitions of local queues (that is, hosted by this queue manager) , and definitions of remote queues (that is, hosted by other queue managers).
- If the messages are destined for a remote queue, the local queue manager holds them on a transmission queue, which persists them in a message store, until they can be forwarded to the remote queue manager.
- Each queue manager contains communications software, known as the moving service, that the queue manager uses to communicate with other queue managers.
- The transport service is independent of the queue manager and can be any one of the following (depending on the platform):
- Systems Network Architecture Advanced Program-to Program Communication (SNA APPC)
- Transmission Control Protocol/Internet Protocol (TCP/IP)
- Network Basic Input/Output System (NetBIOS)
- Sequenced Packet Exchange (SPX)
Components needed to send a message
If a message is to be sent to a remote queue manager, the local queue manager needs definitions for a transmission queue and a channel. A channel is a one-way communication link between two queue managers. It can carry messages destined for any number of queues at the remote queue manager.
Each end of a channel has a separate definition, defining it, for example, as the sending end or the receiving end. A simple channel consists of a sender channel definition at the local queue manager and a receiver channel definition at the remote queue manager. These two definitions must have the same name, and together they constitute one channel.
The software that handles the sending and receiving of messages is called the Message Channel Agent (MCA). There is a message channel agent (MCA) at each end of a channel.
Each queue manager should have a dead-letter queue (also known as the undelivered message queue ). Messages are put on this queue if they cannot be delivered to their destination.
The following figure shows the relationship between queue managers, transmission queues, channels, and MCAs: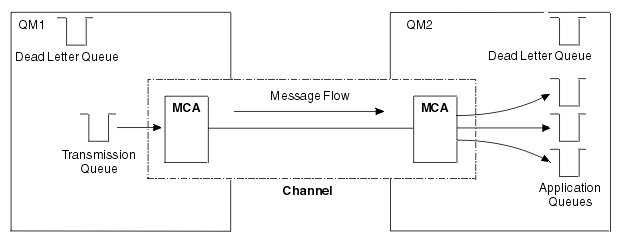
Components needed to return a message
If our application requires messages to be returned from the remote queue manager, you need to define another channel, to run in the opposite direction between the queue managers, as shown in the following figure:
Clusters
Rather than manually defining all the connections in a distributed queuing environment, we can group a set of queue managers in a cluster. When we do this, the queue managers can make the queues that they host available to other queue managers in the cluster without the need for explicit channel definitions, remote-queue definitions, or transmission queues for each destination. Every queue manager in a cluster has a single transmission queue that transmits messages to any other queue manager in the cluster. For each queue manager, you only need to define one cluster-receiver channel and one cluster-sender channel; any additional channels are automatically managed by the cluster.
An IBM MQ client can connect to a queue manager that is part of a cluster, just as it can connect to any other queue manager. As with manually-configured distributed queuing, we use the MQPUT call to put a message to a queue at any queue manager. We use the MQGET call to retrieve messages from a local queue.
Queue managers on platforms that support clusters do not have to be part of a cluster. You can continue to manually configure distributed queuing as well as, or instead of, using clusters.
Benefits of using clusters
Clustering provides two key benefits:- Clusters simplify the administration of IBM MQ networks, which usually require many object definitions for channels, transmit queues, and remote queues to be configured. This situation is especially true in large, potentially changing, networks where many queue managers need to be interconnected. This architecture is particularly hard to configure and actively maintain.
- Clusters can be used to distribute the workload of message traffic across queues and queue managers in the cluster. Such distribution allows the message workload of a single queue to be distributed across equivalent instances of that queue located on multiple queue managers. This distribution of the workload can be used to achieve greater resilience to system failures, and to improve the scaling performance of particularly active message flows in a system. In such an environment, each of the instances of the distributed queues have consuming applications processing the messages. For more information, see Use clusters for workload management.
How messages are routed in a cluster
We can think of a cluster as a network of queue managers maintained by a conscientious systems administrator. Whenever you define a cluster queue, the systems administrator automatically creates corresponding remote-queue definitions as needed on the other queue managers.
You do not need to make transmission queue definitions because IBM MQ provides a transmission queue on each queue manager in the cluster. This single transmission queue can be used to carry messages to any other queue manager in the cluster. You are not limited to using a single transmission queue. A queue manager can use multiple transmission queues to separate the messages going to each queue manager in a cluster. Typically, a queue manager uses a single cluster transmission queue. We can change the queue manager attribute DEFCLXQ, so that a queue manager uses a different cluster transmission queue for each queue manager in a cluster. We can also define cluster transmission queues manually.
All the queue managers that join a cluster agree to work in this way. They send out information about themselves and about the queues they host, and they receive information about the other members of the cluster.
To ensure that no information is lost when a queue manager becomes unavailable, you specify two queue managers in the cluster to act as full repositories. These queue managers store a full set of information about all the queue managers and queues in the cluster. All other queue managers in the cluster only store information about those queue managers and queues with which they exchange messages. These queue managers are known as partial repositories. For more information, see Cluster repository.
In order to become part of a cluster, a queue manager must have two channels; a cluster-sender channel and a cluster-receiver channel:- A cluster-sender channel is a communication channel like a sender channel. You must manually create one cluster-sender channel on a queue manager to connect it to a full repository that is already a member of the cluster.
- A cluster-receiver channel is a communication channel like a receiver channel. You must manually create one cluster-receiver channel. The channel acts as the mechanism for the queue manager to receive cluster communications.
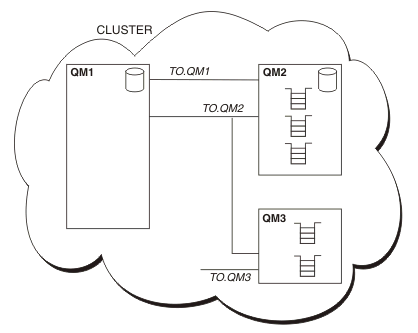
- CLUSTER contains three queue managers, QM1, QM2, and QM3.
- QM1 and QM2 host full repositories of information about the queue managers and queues in the cluster.
- QM2 and QM3 host some cluster queues, that is, queues that are accessible to any other queue manager in the cluster.
- Each queue manager has a cluster-receiver channel called TO.qmgr on which it can receive messages.
- Each queue manager also has a cluster-sender channel on which it can send information to one of the repository queue managers.
- QM1 and QM3 send to the repository at QM2 and QM2 sends to the repository at QM1.